目录
一、哈希取余分区
二、一致性哈希算法分区
三、哈希槽分区
在学习通过Docker进行Redis集群部署之前,简单聊一点Redis分布式集群存储相关的哈希算法问题:
一、哈希取余分区
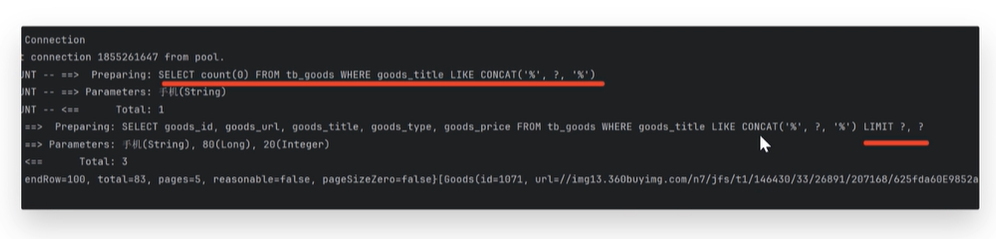
2亿条记录就是2亿个KV,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key)%N个机器台数,计算出哈希值,用来决定数据映射到哪一台节点上。
优点:
1. 简单且易于理解和实现。
2. 在节点数量变化时(节点增加或减少),只需重新分配少数键。
缺点:
如果节点数量变化较大,某些个节点挂了,则可能会导致数据分布不均、数据倾斜,即一个节点负责过多的键,最终造成系统故障。

二、一致性哈希算法分区
3大步骤:
1. 算法构建一致性哈希环
2. 服务器IP节点或主机名映射
3. key落到服务器的落键规则
优点:
1. 一致性哈希算法的容错性
2. 一致性哈希算法的扩展性
即加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点:
1. 一致性哈希算法的数据倾斜性
即数据的分布和节点的位置有关,因为这些节点不是均匀分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果,同时对于节点数量特别少的分布式集群非常不实用。

从下图这个哈希环可以看出,数据分布到A的概率比B的概率大的多:


三、哈希槽分区
哈希槽分区是在一致性哈希算法分区上进行了优化,Redis 集群采用了一致性哈希算法来分配数据到不同的节点,保证了数据分布的均匀性。每个 key 通过计算哈希值后被映射到对应的节点。在 Redis 集群中,每个节点负责维护自己哈希槽的信息。每个节点负责维护一部分哈希槽,当集群中的节点增加或减少时,节点间的哈希槽也会相应地调整。












![[数据结构] 二叉树题目(一)](https://i-blog.csdnimg.cn/direct/31d50c17f6c446d4878d60f27e621ff0.png)