WRF(Weather Research Forecast)模式是由美国国家大气研究中心(NCAR)、国家环境预报中心(NCEP)等机构自1997年起联合开发的新一代高分辨率中尺度天气研究预报模式,重点解决分辨率为1~10Km、时效60h以内的有限区域天气预报和模拟问题。
WRF模式开发的目标是建立一个具有可移植、易维护、可扩充、高效、用户友好的模式。WRF模式结合先进的数值方法和资料同化技术,采用改进的物理过程,同时具有多重嵌套及定位不同地理位置的能力,很好的适应了从理想化研究到业务预报的需要,已发展成为目前最流行的气象数值预报系统之一。
我们在之前的文章中介绍过WRF的基本安装部署过程,具体查看
WRF新手村
本次以WRF为例进行应用优化实践。
WRF模式-IO优化
WRF模式定期输出结果文件和重启文件,输出结果数组时,分别支持四种IO模式:串行netcdf格式、并行pnetcdf格式、异步I/O模式和异步I/O+pnetcdf模式。
串行读写
WRF模式默认采用MPI Gatherv调用将所有数据汇集到主进程(0号进程),重构数组,然后使用标准的串行NetCDF库将其写入磁盘。在此期间,其他MPI进程阻塞等待,直到主进程完成写操作。串行netcdf格式需要在编译时采用预编译参数-DNETCDF,并在namelist.input中设置。
io_form_history = 2
io_form_restart = 2
io_form_input = 2
io_form_boundary = 2串行读写的时间会被写入rsl.out.0000文件中,本例串行读写时间如下:
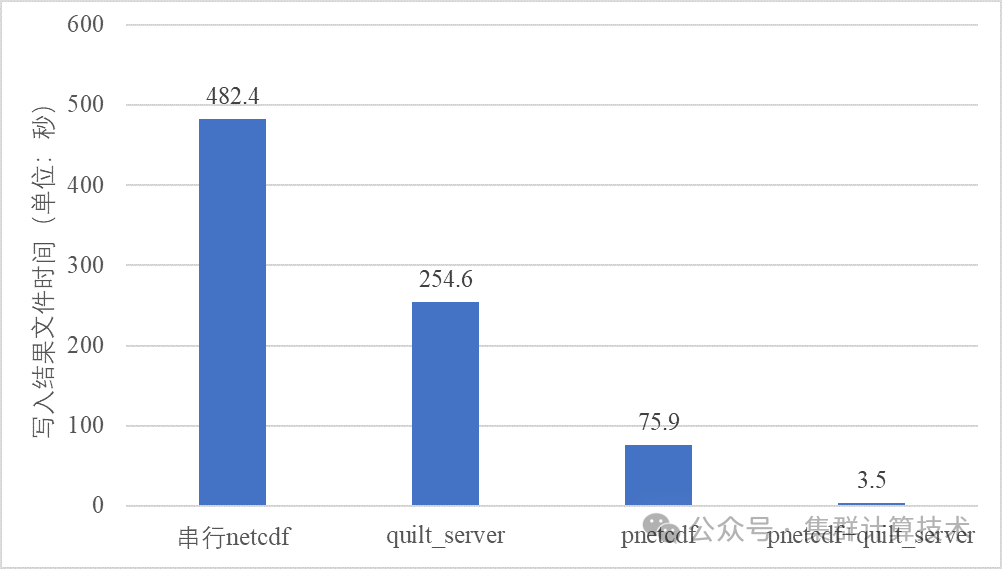
Timing for Writing wrfout_d01_2023-10-25_01:00:00 for domain 1: 482.42148 elapsed seconds该时间包含调用MPI Gatherv和NetCDF格式化的时间,被称为有效I/O时间,并不严格等于数据写入磁盘所需要的时间,仅代表生成输出的墙钟时间。
对于模拟区域较小或者MPI进程数较少的情景,串行NetCDF方式是一个合理的选项。但串行方式依赖MPI_Gatherv及NetCDF的串行特性,随着MPI进程数和模拟区域的增大,默认方式会成为主要的性能瓶颈。该算例中,串行方式写单个文件需要482.42s,耗时较高,瓶颈明显。此外,全局数组都通过MPI_Gatherv传输,主进程会迅速耗尽内存,导致节点内存溢出。降低MPI_Gatherv影响的一种方法是使用MPI/OpenMP混合运行模式,减少每个节点的MPI进程数,增加使用的节点数。然而,OpenMP方式只是降低了串行方式的瓶颈点,并不能彻底消除该方法的弊端。
并行读写
除串行方式外,WRF还支持基于PNetCDF实现的I/O,PNetCDF是NetCDF库的扩展,支持并行I/O。PNetCDF将MPI进程聚合为多个进程组,每个进程组中的聚合器执行文件写入操作,这在很大程度上减少了聚合时间和写入竞争。进一步地,对特定文件系统,如lustre,PNetCDF可与文件系统MPI-IO层结合,用户基于MPI-IO提示设置MPI进程组的数量或者默认采用lustre的条带计数。运行时,MPI-IO库会检查输出文件的lustre条带,然后为该文件分配相同数量的MPI-IO聚合器。MPI-IO会尽可能均匀地将聚合器分布到包含计算进程的节点上。
使用PNetCDF时,需要编译时指定预编译选项-DNETCDF -DPNETCDF,并在namelist.input中设置
io_form_history = 11
io_form_restart = 2
io_form_input = 11
io_form_boundary = 11并行读写的时间同样会被写入rsl.out.0000文件,本例并行读写时间如下:
Timing for Writing wrfout_d01_2023-10-25_01:00:00 for domain 1: 75.91977 elapsed secondsPNetCDF可以作为串行NetCDF的替代方案,表现出良好的性能。然而,随着mpi进程数增加,PNetCDF占总运行时间的比重也会增加。
异步IO(quilt server)
如上所述,无论是串行NetCDF还是并行PNetCDF,其他MPI进程都必须等待主进程将数据写入磁盘,计算过程阻塞。当计算进程阻塞的时间占总计算时间比重较高时,将一个或多个进程专门用于I/O是必要的(I/O进程)。异步IO时,计算进程将数据发送给I/O进程,I/O进程在后台进行数据格式化和写入磁盘操作,计算进程继续计算(异步,图9.1所示)。
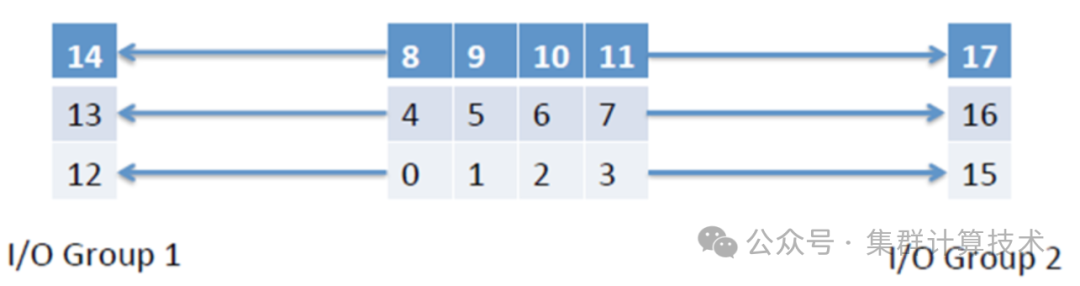
每行的计算进程将数据发送给I/O进程,如进程0-3将数据发送给12或15号I/O进程
使用异步IO,需要在编译时采用预定义参数-DNETCDF,并设置namelist.input中namelist_quilt字段
&namelist_quilt
nio_tasks_per_group = 32,
nio_groups = 2,其中nio_groups表示要使用的I/O进程组数量,nio_tasks_per_group表示每I/O进程组中的进程数。I/O进程总数由nio_groups*nio_tasks_per_group计算得出,计算过程总进程数nprocs=nproc_x*nproc_y,nproc_x和nproc_y分别给出了沿x和y轴方向的进程数。其中nio_tasks_per_group不能超过nproc_y,理想情况下,nio_tasks_per_group应该是nproc_y的倍数。
异步I/O+PNetCDF
编译时采用预编译参数-DNETCDF -DPNETCDF -DPNETCDF_QUILT,并在namelist中使用
io_form_history = 11
io_form_restart = 2
io_form_input = 11
io_form_boundary = 11设置异步I/O进程设置,那么写入磁盘的操作将使用MPI-IO并行处理,从而将两种技术的优势结合。本例中使用异步I/O+PNetCDF,写入文件耗时如下:
Timing for Writing wrfout_d01_2023-10-25_02:00:00 for domain 1: 3.45529 elapsed seconds
极大降低了文件写耗时。
添加图片注释,不超过 140 字(可选)
WRF模式-运行时优化
压缩对IO的性能影响
WRF输出文件常用两种输出格式,分别为经典netcdf格式(classic)及压缩格式(NETCDF4 with HDF5 compression)。使用两种格式输出文件各有利弊,如果追求读写性能,建议采用classic格式;若要节约存储空间,则建议使用压缩格式(NETCDF4 with HDF5 compression)
此处单独使用相同的算例,对比测试支持两种输出格式时,对应的输出文件大小及输出文件的耗时情况,通过测试结果对比分析,使用HDF5格式相比经典netcdf格式,输出文件大小为原来的0.37,输出文件耗时为经典netcdf的3.2倍。

添加图片注释,不超过 140 字(可选)
进程数设置
运行时使用如下命令启动作业,NP为总进程数。
mpirun -np $NP ./wrf.exenamelist.input参数文件中的domains部分进行如下设置,表示由WRF自动进行进程分解:NP=nproc_x*nproc_y,分解原则是nproc_x与nproc_y尽量接近,且nproc_x<=nproc_y。nproc_x小一些,使得patch在X方向长一些,会有利于向量化运行。
&domains
nproc_x = -1,
nproc_y = -1,在5632个计算核心上运行WRF,测试结果如下表:
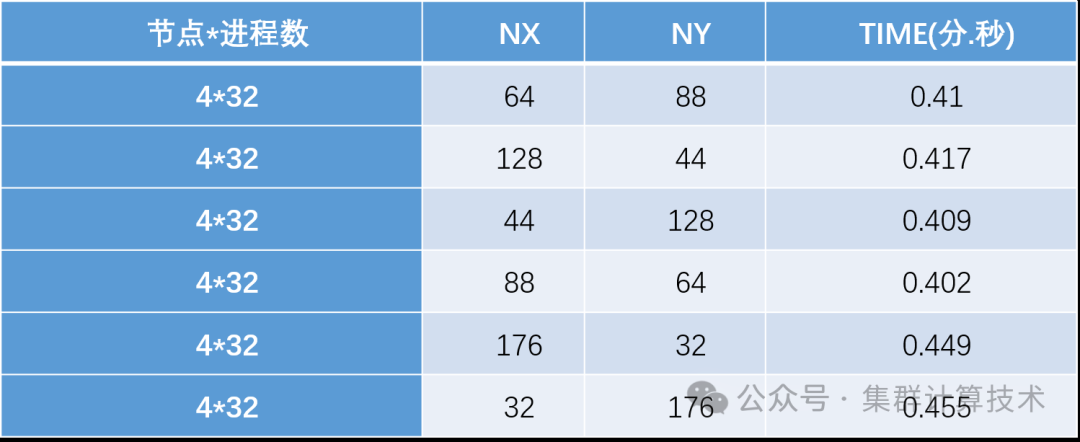
添加图片注释,不超过 140 字(可选)
由以上测试结果分析,该算例运行时Nproc_x=88,Nproc_y=64时测试结果最优。运行其他WRF case时,需要具体进行性能测试判断Nproc_x及Nproc_y的最优值。