做自媒体的同学经常遇到的一个痛点就是无限输出,那怎么才能有源源不断的选题呢?那就是搭建一个选题素材库。
下面就为大家介绍一下基于 Coze Bot 快速搭建素材选题库,希望能让大家才思泉涌。
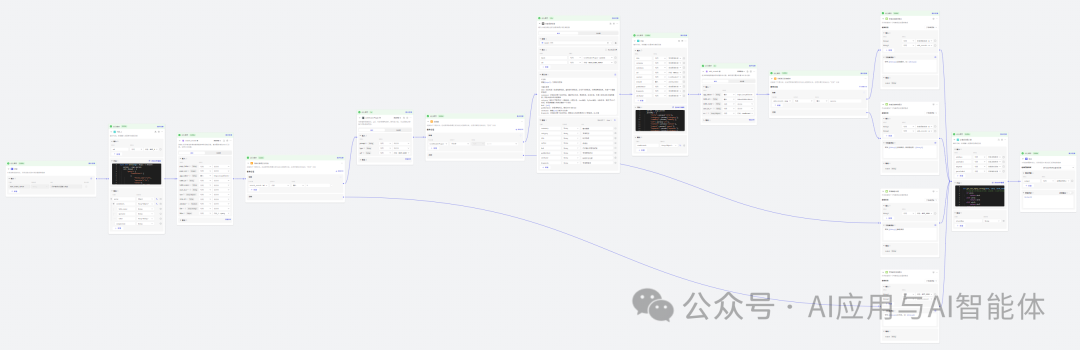
一、流程拆解
日常素材库积累的过程可以描述为:看到一篇不错的文章,记录标题、大纲、分类和地址。
这些环节正好都是大模型所擅长的。我们把这些环节拆分为不同节点去实现,最后用一个工作流去串联起来就可以了。
实现的效果如下:

二、Bot 搭建
一)Bot 设计
1、创建 Bot
打开 https://www.coze.cn/home,点击创建 Bot 按钮
输入 Bot 名称和介绍后点击确定
2、设定人设
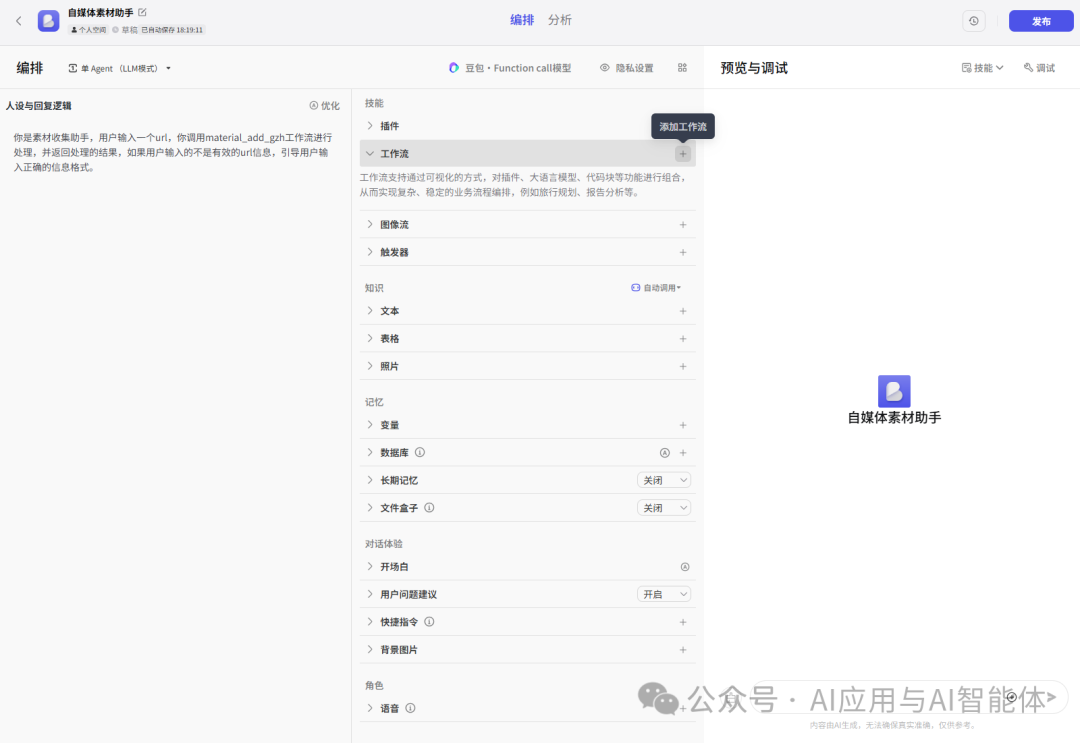
人设与回复逻辑
你是素材收集助手,用户输入一个url,你调用material_add_gzh工作流进行处理,并返回处理的结果,如果用户输入的不是有效的url信息,引导用户输入正确的信息格式。
在页面中间工作流标签点击添加工作流 material_add_gzh,如果还没有创建工作流,点击左侧创建工作流按钮即可开始创建,具体流程详见下一章节。
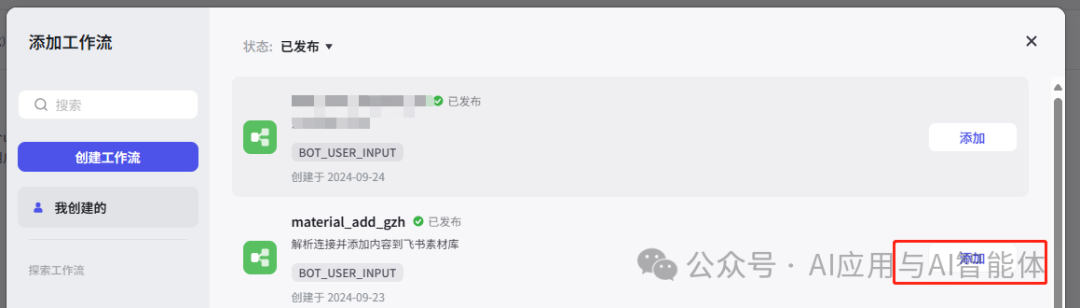
二)流程设计
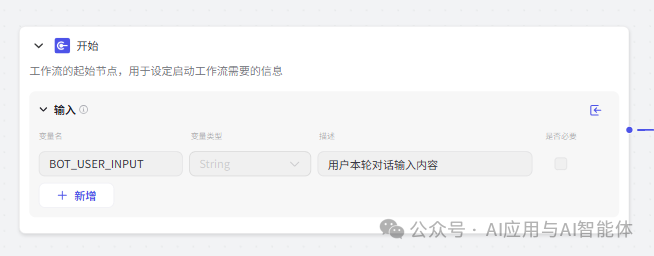
1、开始
不需要额外定义变量,仅用默认变量 BOT_USER_INPUT 即可。
2、拼装查询条件
为了避免记录重复添加,我们这里是先根据 URL 查询飞书多维表中记录是否存在,如果存在则直接返回,不存在则执行添加操作。这里 query 的结构定义是基于飞书多维表查询条件结构来的,不能随意修改 query 对象中的属性名称。
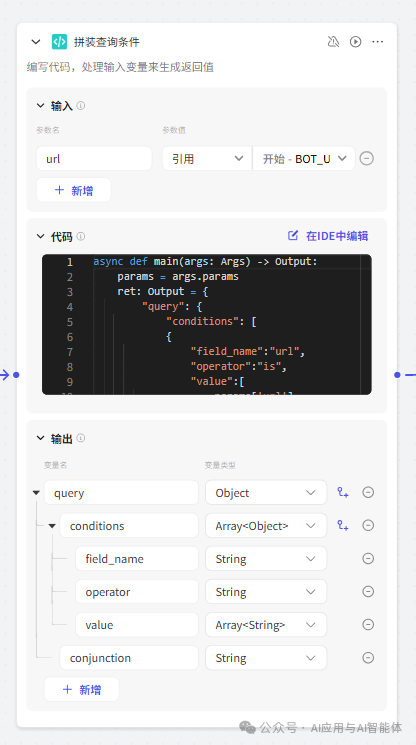
本节点是代码节点,Python 代码如下:
async def main(args: Args) -> Output:
params = args.params
ret: Output = {
"query": {
"conditions": [
{
"field_name":"url",
"operator":"is",
"value":[
params['url']
]
}
],
"conjunction":"and"
}
}
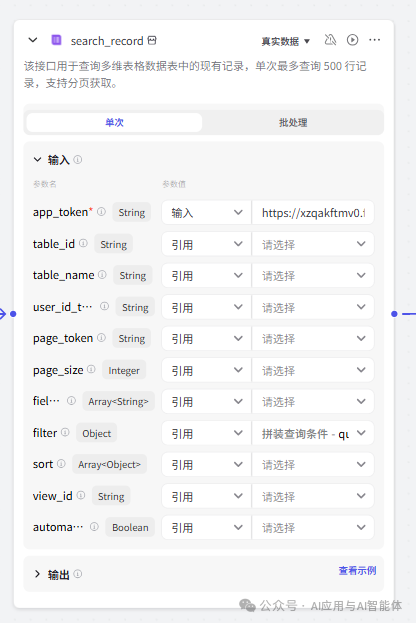
return ret3、查询飞书多维表
app_token:输入多维表完整的 url,插件会自动解析处理;
filter:引用上一步拼装的查询条件 query;
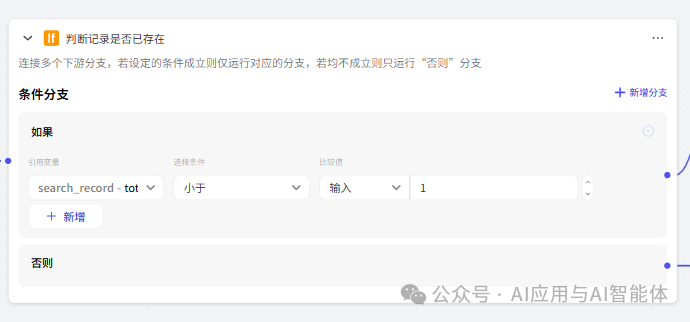
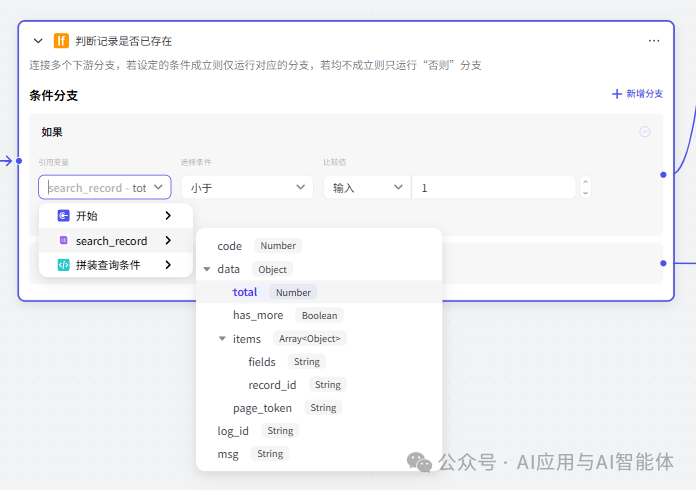
4、判断记录是否存在
这是一个选择器节点,实现分支的功能,根据上一步查询返回的记录判断用户输入的 URL 是否已录入。如果条件满足,则执行正常素材添加逻辑,否则执行文档跳过添加提示节点(后续说明)。
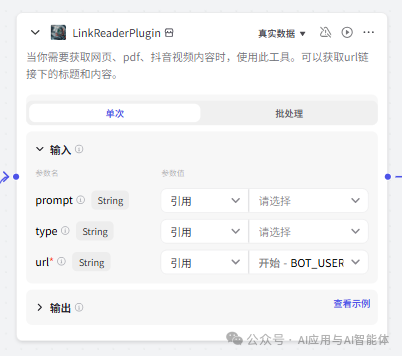
5、解析 URL 内容
这一步用的是 coze 插件市场中的 LinkReaderPlugin 插件,该插件可以获取指定 URL 的内容。
url:引用入参 BOT_USER_INPUT
6、判断 URL 解析查询返回值
调测中遇到有的 url 链接解析获得内容为空,对于这种异常情况,跳过处理。
7、文本提炼处理
本节点是大模型节点,借助大模型提炼文章标题、摘要、类别、发布日期、关键词。
提示词如下:
# 任务
根据{{input}},生成对应信息
# 输出要求
title:网页标题(如果有原标题,直接使用原标题;若找不到原标题,则根据关键信息,生成一个精确的标题)
summary:仔细阅读整个网页内容,捕捉内容主题、关键信息、阅读价值,生成一段简洁而全面的摘要;并指出适合的读者群体
category:有如下文本类别:AI智能体、AI提示词、Java编程、Python编程、认知思考、其他 共计6个类别,帮我根据输入的内容确定一个类别
link:{{url}}
publishDate:文章发布时间,格式YYYY-MM-DD
siteName:根据{{url}}判断平台名称
keywords:仔细阅读整个网页内容,提炼出与主题相关的3-5个关键词,以,分隔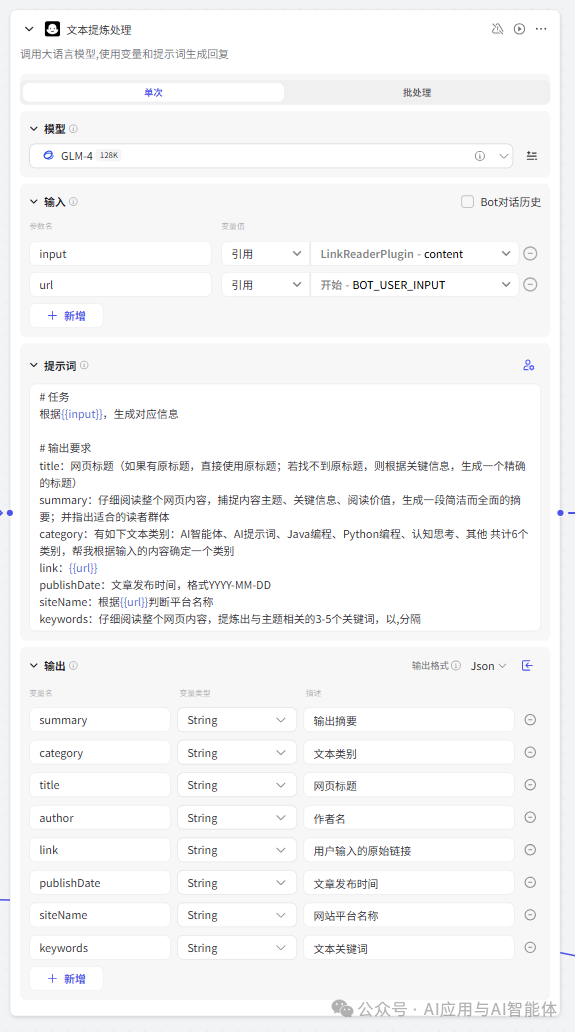
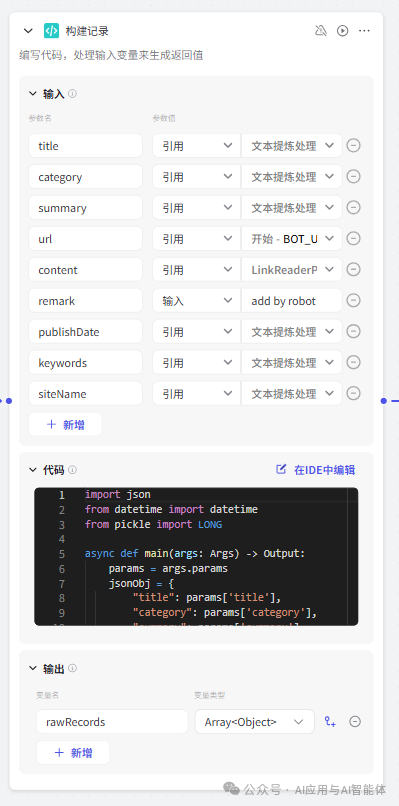
8、构建飞书字段记录
此处是基于飞书的添加多维表记录的报文结构构建的数组对象。title、category...publishDate 等都是多维表中定义的字段名称,根据需要调整即可。此处需要注意的是如果飞书中定义的字段为日期格式,那么存入的时候需要转换成时间戳,具体转换方法也在下面代码中。
import json
from datetime import datetime
from pickle import LONG
async def main(args: Args) -> Output:
params = args.params
jsonObj = {
"title": params['title'],
"category": params['category'],
"summary": params['summary'],
"url": params['url'],
"content": params['content'],
"remark": params['remark'],
"keywords": params['keywords'],
"siteName": params['siteName'],
"publishDate": date_to_timestamp(params["publishDate"])
}
record = {
"fields": json.dumps(jsonObj)
}
jsonArray = []
jsonArray.append(record)
ret: Output = {
"rawRecords": jsonArray,
}
return ret
def date_to_timestamp(date_str, date_format='%Y-%m-%d'):
"""
将日期字符串转换为10位时间戳。
:param date_str: 日期字符串
:param date_format: 日期字符串的格式,默认为'%Y-%m-%d'
:return: 10位时间戳
"""
try:
# 将日期字符串转换为datetime对象
date_obj = datetime.strptime(date_str, date_format)
# 将datetime对象转换为时间戳
timestamp = int(date_obj.timestamp() * 1000)
return timestamp
except ValueError as e:
print(f"Error: {e}")
return None
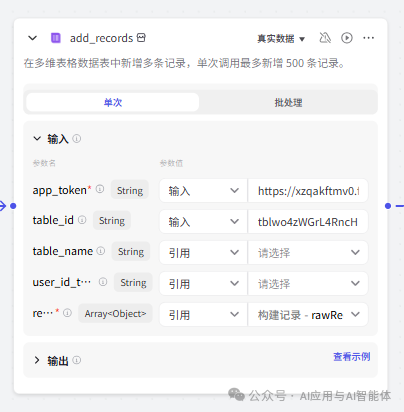
9、添加记录到飞书多维表
此处使用的是 coze 中飞书多维表插件的 add_records 函数。
app_token:同前面记录查询节点中的配置,此处填写完整的飞书多维表 url 即可,形如:
https://xzqakftmv0.feishu.cn/base/xxxx?table=tbyyy&view=vewJFRrIho
records:引用前一步构建记录的返回的 rawRecords 变量。
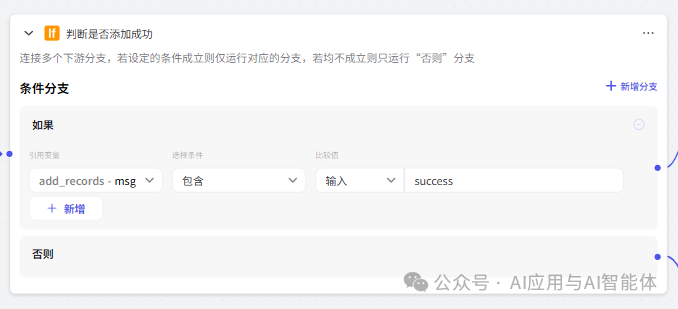
10、判断记录添加是否成功
有些字段格式不正确或者其他原因,可能导致记录添加失败,这里对添加记录节点返回值进行判断,根据成功与否给出用户不同的提示信息。
11、提示信息拼接
为了更好地用户体验,对文本添加成功、失败、跳过、解析错误都采用了字符串处理节点拼接提示消息,大家可以根据需要选择。
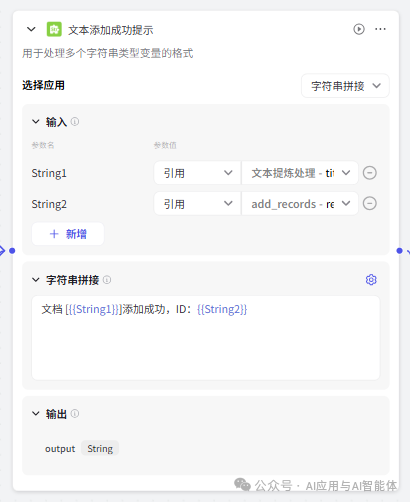
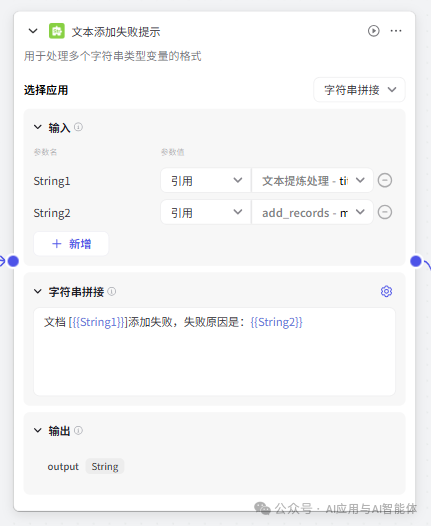
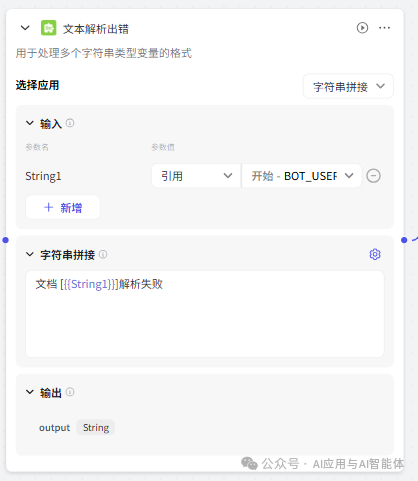
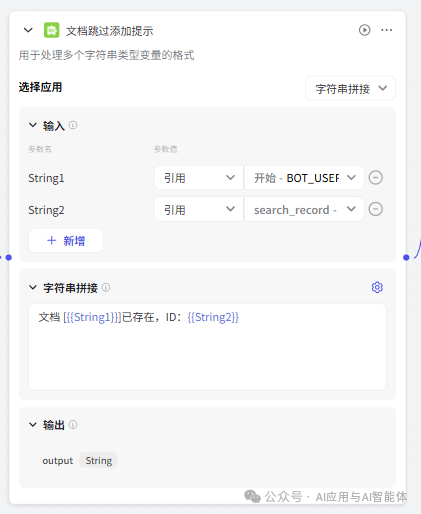
12、设置返回信息
由于结束节点输出变量需要具体指定,而实际可能出现不同的处理结果,因此将 11 节点的内容统一的一个变量 returnMsg 中,此处为代码节点:
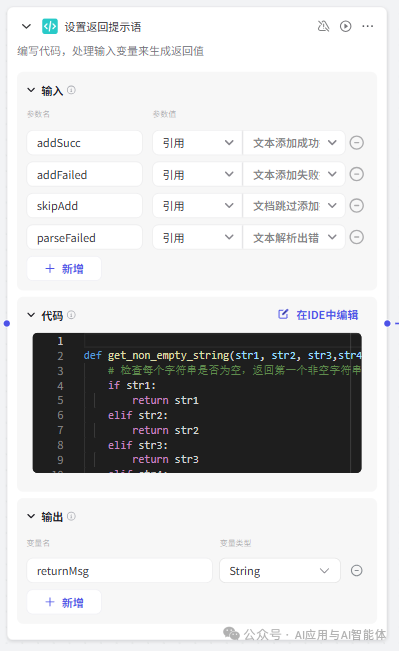
python 代码如下:
def get_non_empty_string(str1, str2, str3,str4):
# 检查每个字符串是否为空,返回第一个非空字符串
if str1:
return str1
elif str2:
return str2
elif str3:
return str3
elif str4:
return str4
else:
return None # 如果所有字符串都为空,则返回None
async def main(args: Args) -> Output:
params = args.params
message = get_non_empty_string(params['addSucc'], params['addFailed'], params['skipAdd'], params['parseFailed'])
ret: Output = {
"returnMsg": f'{message}'
}
return ret
13、结束
结束节点直接定义的用设定内容直接回答,回答内容就是 output 的值,output 则设定引用上面的 returnMsg。
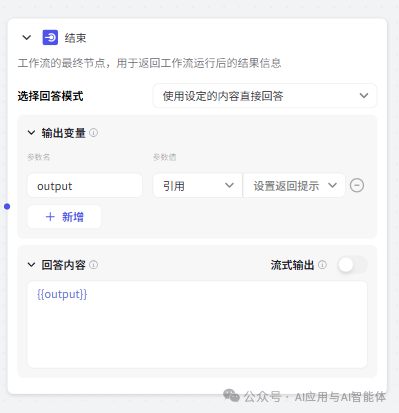
三、测试验证
工作流创建完成并发布后,与步骤一中的 Bot 绑定,就可以进行调试,为此进行了几种常见验证,分别是:
不符合 URL 格式、记录已存在、记录不存在。
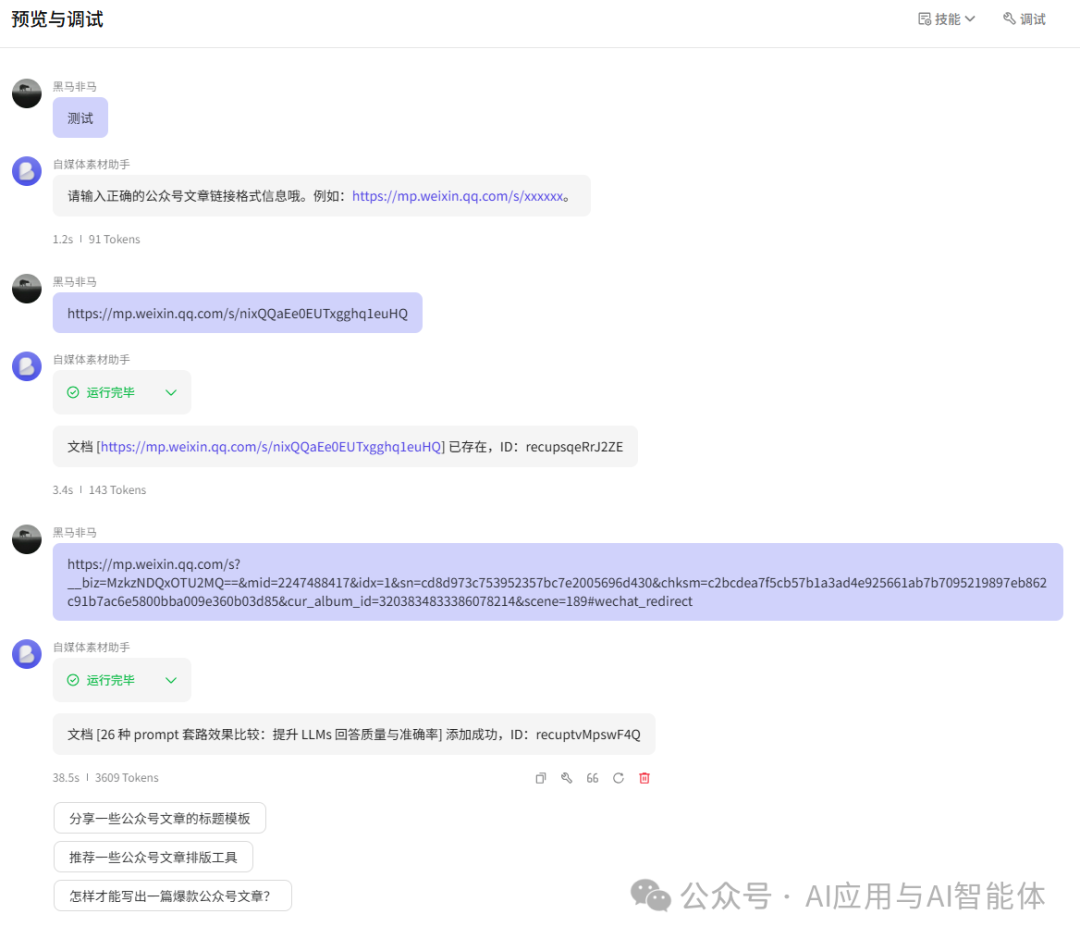

查看飞书文档,记录也已经正确添加。大家根据自己的需求继续迭代。
我是黑马非马,探索 AI 编程与 AI 智能体,欢迎围观。