目录
1.代码实现
2.知识点
1.代码实现
#导包
import math
import torch
from torch import nn
import dltools#加载PTB数据集 ,需要把PTB数据集的文件夹放在代码上一级目录的data文件中,不用解压
#批次大小、窗口大小、噪声词大小
batch_size, max_window_size, num_noise_words = 512, 5, 5
#获取数据集迭代器、词汇表
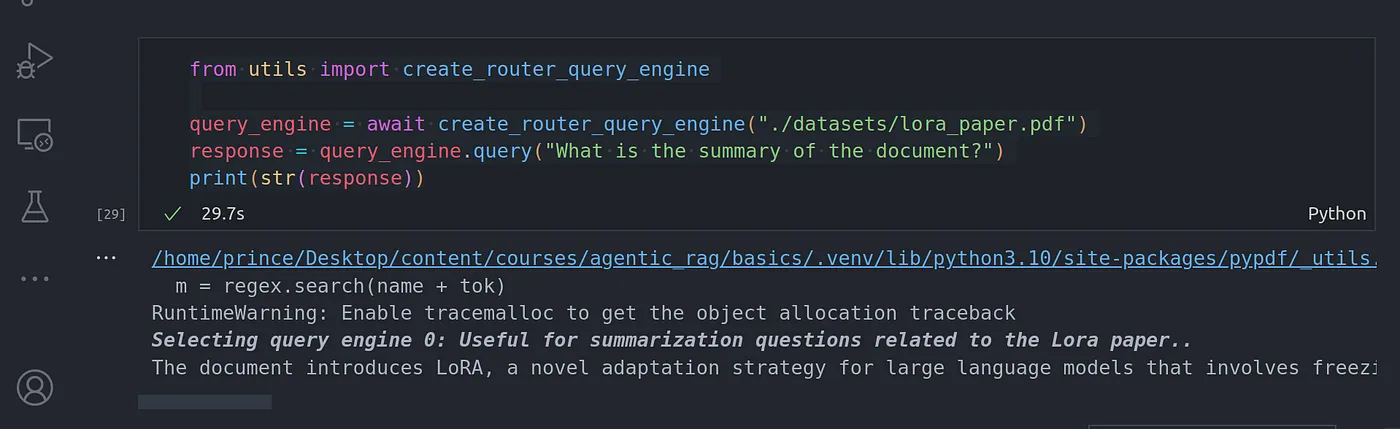
data_iter, vocab = dltools.load_data_ptb(batch_size, max_window_size, num_noise_words)#讲解嵌入层embedding的用法(此行代码无用)
#嵌入层
#通过嵌入层来获取skip—gram的中心词向量和上下文词向量
embed = nn.Embedding(num_embeddings=20, embedding_dim=4)
# num_embeddings就是词表大小
# X的shape=(batch_size, num_steps)
# --one_hot编码--->(batch_size, num_steps, num_embedding(vocab_size))
# --点乘中心词矩阵-->(batch_size, num_steps, embed_size)embed.weight.shape #讲解嵌入层embedding的用法(此行代码无用)torch.Size([20, 4])
embedding层先one_hot编码,再进行与embedding层的矩阵(num_embeddings,embedding_dim)乘法
#构造skip_gram的前向传播
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
"""
embed_v:表示对中心词进行embedding层
embed_u:对上下文词进行embedding层
"""
v = embed_v(center) #中心词的词向量表达
u = embed_u(contexts_and_negatives) #上下文词的词向量表达
#用中心词来预测上下文词
#u_shape = (batch_size, num_steps, embed_size)---->(batch_size, embed_size, num_steps)进行矩阵乘法
pred = torch.bmm(v, u.permute(0, 2, 1)) #矩阵乘法(bmm三维乘法),不用管batch_size维度
return pred#假设数据
skip_gram(torch.ones((2, 1), dtype=torch.long), torch.ones((2, 4), dtype=torch.long), embed, embed)
tensor([[[3.1980, 3.1980, 3.1980, 3.1980]],
[[3.1980, 3.1980, 3.1980, 3.1980]]], grad_fn=<BmmBackward0>)
#假设数据
skip_gram(torch.ones((2, 1), dtype=torch.long), torch.ones((2, 4), dtype=torch.long), embed, embed).shapetorch.Size([2, 1, 4])
#带掩码的二元交叉熵损失
class SigmoidBCELoss(nn.Module):
def __init__(self):
super().__init__() #直接继承父类的初始化属性和方法
def forward(self, inputs, target, mask=None):
#nn.functional.binary_cross_entropy_with_logits表示返回的不是转化后的概率,是原始计算的数据结果
#weight=mask权重将掩码带上
#reduction='none'表示不将计算结果聚合,算损失时(默认聚合)
out = nn.functional.binary_cross_entropy_with_logits(inputs, target, weight=mask, reduction='none')
return out.mean(dim=1) #计算结果是二维的,在索引1维度上聚合求平均
loss = SigmoidBCELoss()[[1.1, -2.2, 3.3, -4.4]] * 2[[1.1, -2.2, 3.3, -4.4], [1.1, -2.2, 3.3, -4.4]]
torch.tensor([[1.1, -2.2, 3.3, -4.4]] * 2).shapetorch.Size([2, 4])
#假设数据测试
pred = torch.tensor([[1.1, -2.2, 3.3, -4.4]] * 2)
label = torch.tensor([[1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0]])
mask = torch.tensor([[1, 1, 1, 1], [1, 1, 0, 0]])
#mask每一行都有4个数值,所以* mask.shape[1]=4
#但是mask中的数值0表示权重,是补充步长的,不重要,需要计算有效序列的损失平均值,所以 / mask.sum(axis=1)
loss(pred, label, mask) * mask.shape[1] / mask.sum(axis=1)tensor([0.9352, 1.8462])
#初始化模型参数,定义两个嵌入层
#一开始,embed_weights会标准正态分布的数据初始化
#两个embedding层的参数不一样,不能重复使用,需要初始化定义两个
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab), embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab), embedding_dim=embed_size))
#定义训练过程
def train(net, data_iter, lr, num_epochs, device=dltools.try_gpu()):
#修改embedding层的初始化方法,使用nn.init.xavier_uniform_初始化embed.weight权重,在NLP中不使用标准正态分布的额数据初始化权重
def init_weights(m):
if type(m) == nn.Embedding:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
#设置梯度下降的优化器
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
#设置绘制可视化的动图(epoch——loss)
animator = dltools.Animator(xlabel='epoch', ylabel='loss', xlim=[1, num_epochs])
#设置累加
metric = dltools.Accumulator(2) #2种数据需要累加
for epoch in range(num_epochs): #遍历训练次数
#设置计时器, 赋值批次数量
timer, num_batches = dltools.Timer(), len(data_iter) #data_iter是分好批次的数据集,长度就是批次数量num_batches
for i, batch in enumerate(data_iter): #i是索引, batch是取出的一批批数据
#梯度清零
optimizer.zero_grad()
#接收中心词, 上下文词_噪声词, 掩码, 标记目标值
center, context_negative, mask, label = [data.to(device) for data in batch]
#调用skip_gram模型预测
pred = skip_gram(center, context_negative, embed_v=net[0], embed_u=net[1])
#计算损失
l = loss(pred.reshape(label.shape).float(), label.float(), mask) / mask.shape[1] * mask.sum(dim=1)
#用loss反向传播 ,loss先sum()聚合变成标量(合并成一个数值), 只有标量才能反向传播
l.sum().backward()
#梯度更新
optimizer.step()
#累加
metric.add(l.sum(), l.numel()) #l.sum()数值求和累加, l.numel()数量累加
# % 取余数
# // 商向下取整
#迭代到总数据量的5%的倍数时 或者 处理到最后一批数据时,执行下面操作
# i+1是因为i是从0开始遍历的
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
#epoch + (i+1) / num_batches当前迭代次数占整个数据集的比例
animator.add(epoch + (i+1) / num_batches, (metric[0] / metric[1]))
print(f'loss {metric[0] / metric[1]:.3f}', f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}') lr, num_epochs = 0.002, 50
train(net, data_iter, lr, num_epochs)
#如果能够找到词的近义词, 就说明训练的不错
def get_similar_tokens(query_token, k, embed):
"""
query_token:需要预测的词
k:最高相似度的词数量
embed:embedding层的哪一层
"""
#获取词向量权重 (词向量权重*词的one_hot编码,就是词向量)
W = embed.weight.data
print(f'W的shape:{W.shape}')
x = W[vocab[query_token]] #embedding层是按照索引查表查词对应的权重-->优点
print(f'x的shape:{x.shape}')
#计算余弦相似度
#torch.mv两个向量的点乘
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) * torch.sum(x * x) + 1e-9)
print(f'cos的shape:{cos.shape}')
#排序选择前k个对应的索引
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: #排除query_token他本身,自己与自己余弦相似度最高
print(f'cosine sim={float(cos[i]):.3f}:{vocab.to_tokens(i)}')
get_similar_tokens('food', 3, net[0])
W的shape:torch.Size([6719, 100]) x的shape:torch.Size([100]) cos的shape:torch.Size([6719]) cosine sim=0.430:feed cosine sim=0.418:precious cosine sim=0.412:drink
2.知识点


















![灵当CRM index.php接口SQL注入漏洞复现 [附POC]](https://i-blog.csdnimg.cn/direct/079763a4ee7c4281be9214b25bf9e402.png)

