更多优质内容,请关注公众号:智驾机器人技术前线
1.论文信息
-
论文标题:Module-wise Adaptive Adversarial Training for End-to-end Autonomous Driving
-
作者:Tianyuan Zhang, Lu Wang, Jiaqi Kang, Xinwei Zhang, Siyuan Liang, Yuwei Chen, Aishan Liu, Xianglong Liu
-
作者单位:北京航空航天大学, 新加坡国立大学, 中国航空工业发展研究中心
-
论文链接:https://arxiv.org/pdf/2409.07321
2.摘要
深度学习的最新进展显著提高了自动驾驶(AD)模型的性能,特别是将感知、预测和规划阶段整合在一起的端到端系统,实现了最先进的性能。然而,这些模型仍然容易受到对抗性攻击的影响,其中人类难以察觉的扰动可以破坏决策过程。虽然对抗性训练是提高模型对此类攻击的鲁棒性的有效方法,但之前没有研究关注将其应用于端到端的AD模型。在本文中,我们采取了端到端AD模型对抗性训练的第一步,并提出了一种新颖的模块化自适应对抗训练(MA2T)。然而,将传统的对抗性训练扩展到这一领域是非常复杂的,因为模型内的不同阶段具有不同的目标且彼此之间紧密相连。为了应对这些挑战,MA2T首先引入了模块化噪声注入,它在不同模块的输入前注入噪声,以整体目标而非每个独立模块损失的指导下训练模型。此外,我们引入了动态权重累积自适应,它结合累积的权重变化,根据它们的贡献(累积降低率)自适应地学习和调整每个模块的损失权重,以实现更好的平衡和鲁棒训练。为了证明我们防御的有效性,我们在广泛使用的nuScenes数据集上对几种端到端AD模型进行了广泛的实验,无论是在白盒还是黑盒攻击下,我们的方法都以较大的优势超越了其他算法(+5-10%)。此外,我们通过在CARLA模拟环境中进行闭环评估,验证了我们防御的鲁棒性,即使在自然腐败面前也显示出了更强的弹性。
3.主要贡献
-
据我们所知,本文是第一个在端到端自动驾驶(AD)的背景下研究对抗性训练;
-
提出了MA2T,它整合了模块化噪声注入和动态权重累积自适应,有效地应对了多样化训练目标和不同模块贡献的挑战;
-
进行了大量的实验,全面评估了MA2T,证明它在不同的对抗性攻击方法中显著优于基准方法,实现了5-10%的绝对提升。
4.主要思想与方法
Module-wise Adaptive Adversarial Training (MA2T) 是一种为端到端自动驾驶模型设计的对抗训练方法,旨在提高模型对于对抗性攻击的鲁棒性。MA2T 包含两个主要组件:
-
模块级噪声注入(Module-wise Noise Injection):这一过程在不同模块的输入前注入噪声,而不是仅在图像级别。这样做是为了确保模型以整体目标为导向进行训练,而不是仅依赖于各个独立模块的损失。通过使用整体损失进行反向传播,而不是关注可能导致对整体决策鲁棒性产生负面影响的单个模块损失,从而确保噪声的生成考虑到了整个模型。
-
动态权重累积自适应(Dynamic Weight Accumulation Adaptation):这一过程通过考虑模块在噪声注入期间的贡献(累积降低率)来自适应地调整每个模块的损失权重。具体来说,该方法利用一个权重累积因子来调整下降速率,以保持平衡的训练过程,能够自适应地控制每个模块的权重,防止任何一个模块在训练过程中过于激进地下降。
通过结合这两种方法,MA2T 能够在端到端自动驾驶模型的各个阶段进行全面的训练,同时保持训练的平衡性和有效性。在广泛的实验中,MA2T 在多个端到端自动驾驶模型上,无论是在白盒还是黑盒攻击下,都显示出比现有对抗训练方法更好的性能,实现了显著的改进(提高了5-10%)。此外,通过在CARLA模拟环境中进行闭环评估,验证了MA2T在提高模型对自然干扰的鲁棒性方面的有效性。
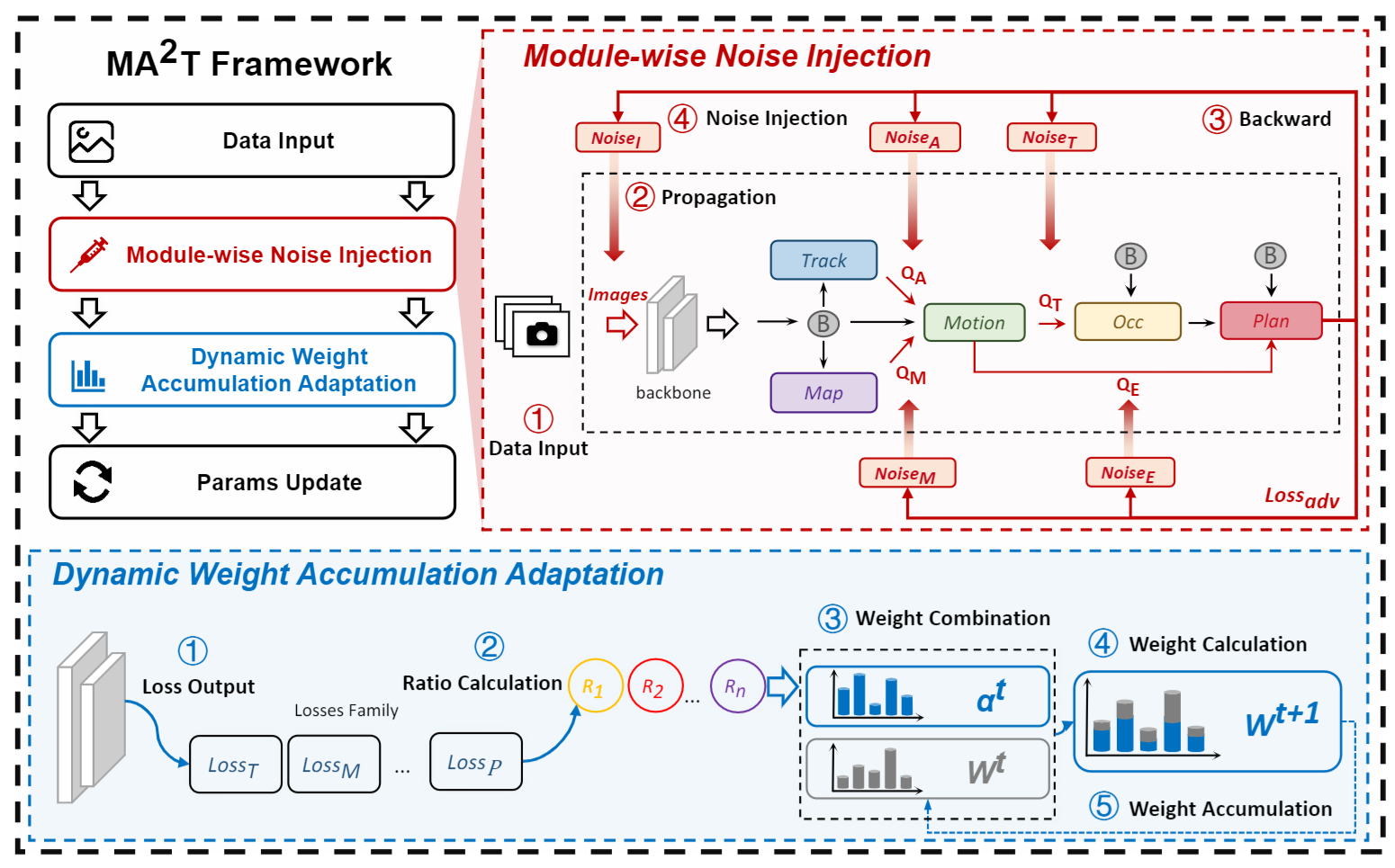
算法架构
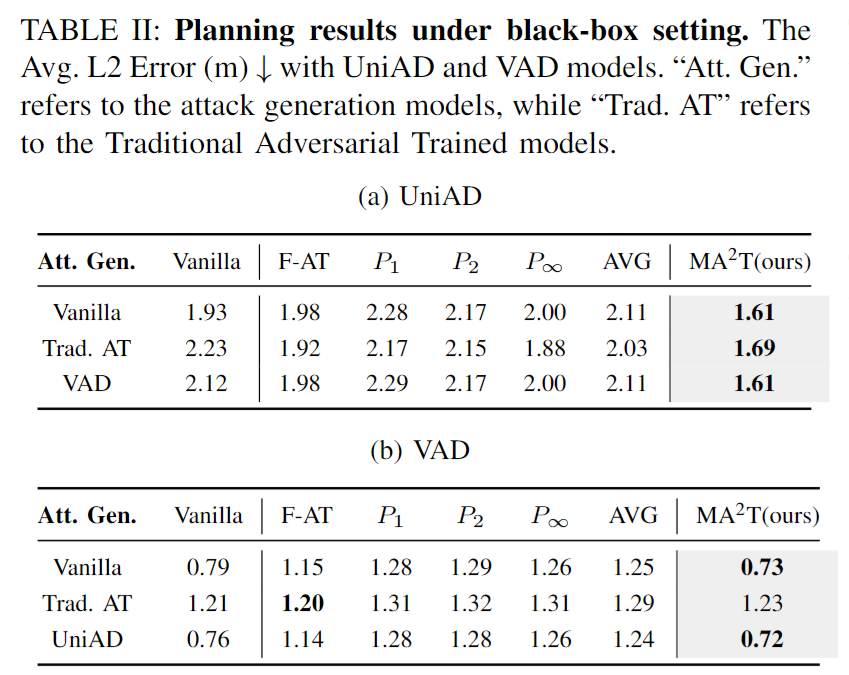
5.实验验证仿真

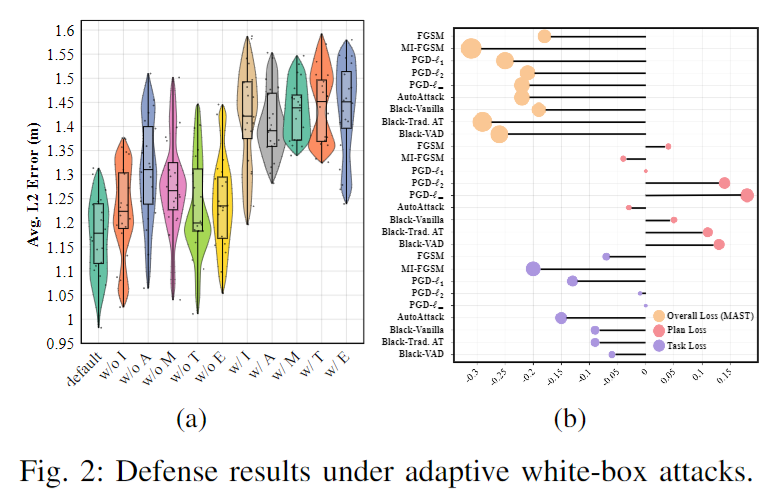
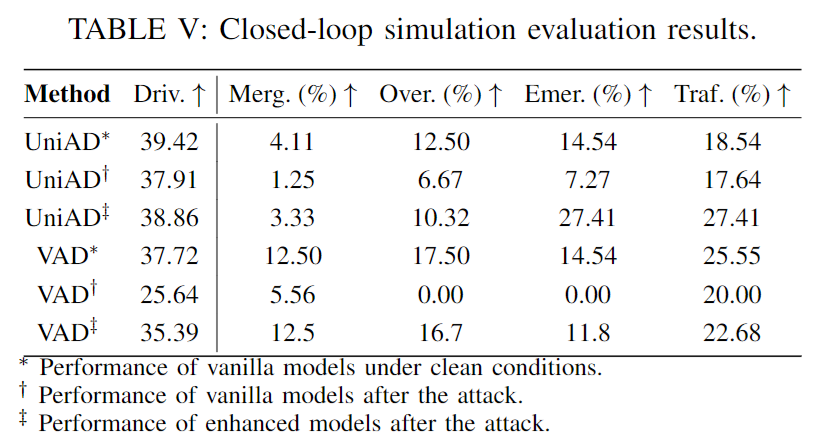
6.总结 & 局限
端到端自动驾驶(AD)模型通过将感知、预测和规划整合到一个统一框架中,大大简化了决策过程。然而,它们紧密耦合的特性也使它们特别容易受到对抗性扰动的影响,而且缺乏全面的对抗训练方法使得这些模型容易受到攻击。现有的防御措施通常只关注自动驾驶pipeline中的个别任务,并且往往仅限于特定类型的扰动,未能解决端到端AD系统的复杂性和相互关联性。
本文介绍了一种新颖的方法——模块化自适应对抗训练(MA2T),专门设计用来增强端到端AD模型对广泛对抗性攻击的鲁棒性。MA2T通过引入模块级噪声注入和动态权重累积自适应机制,解决了这些模型的独特挑战,确保了在AD管道的所有阶段进行平衡而有效的训练。
通过在nuScenes数据集上进行广泛的实验,我们证明了MA2T的有效性,它在多项任务中显著优于现有的对抗训练方法。此外,在CARLA模拟器中进行的闭环评估证实了MA2T提高了端到端AD模型在闭环评估中的鲁棒性。
尽管取得了有希望的结果,但仍有几个领域需要进一步探索:❶ 在真实世界的车辆上评估MA2T,以评估其在实际自动驾驶场景中的有效性;❷ 开发更先进的对抗训练策略,以进一步提高对更广泛攻击的鲁棒性;以及❸ 降低模型的复杂性并加速训练过程,使MA2T更适用于实时系统的部署。

更多优质内容,请关注公众号:智驾机器人技术前线
本文仅做学术分享,如有侵权,请联系删文!





![[笔记]数据结构](https://i-blog.csdnimg.cn/direct/5660b22f11324ed38cf19e38e5706726.png)