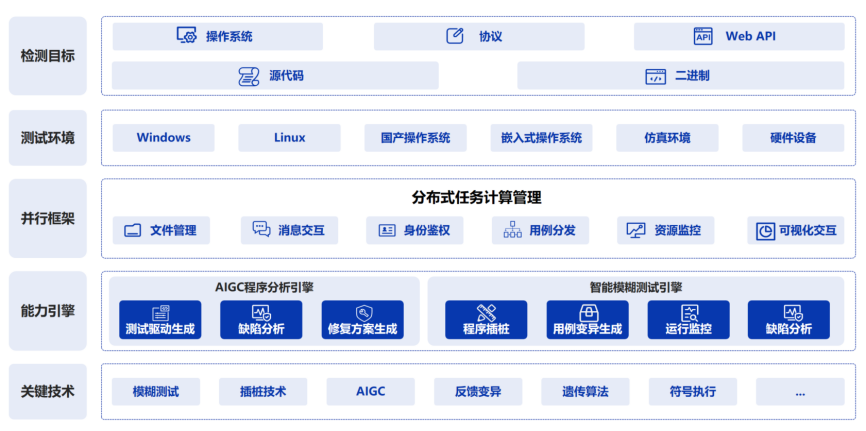
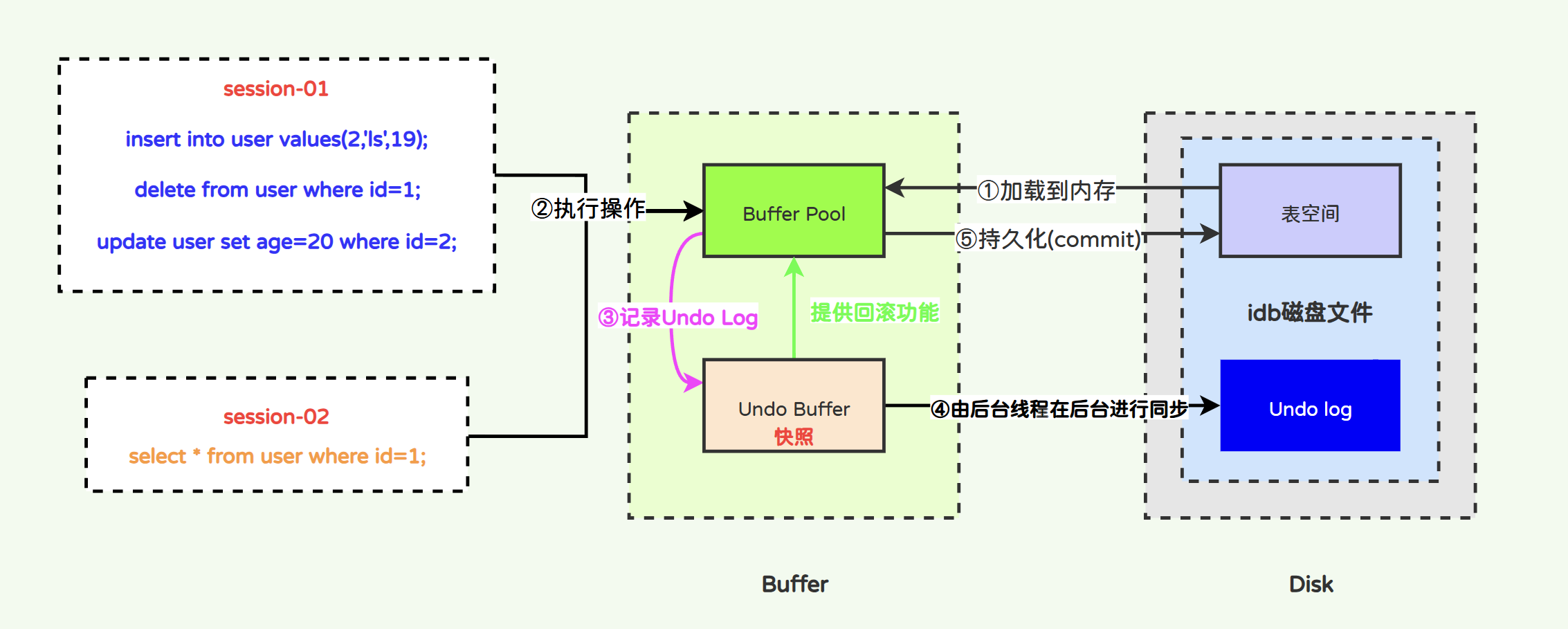
GOT-OCR2.0是一款新一代的光学字符识别(OCR)技术,标志着人工智能在文本识别领域的重大进步。作为一款开源模型,GOT-OCR2.0不仅支持传统的文本和文档识别,还能够处理乐谱、图表以及复杂的数学公式,为用户提供了更加全面和高效的解决方案。
产品功能及特点
- 多语言支持:GOT-OCR2.0主要支持中文和英文字符识别,并能够通过进一步的微调扩展到更多语言。这种灵活性使其适用于国际化应用,满足不同用户的需求。
- 场景文本识别:该系统能够处理自然场景中的文本识别任务,例如街道标志、广告牌上的文字等。这一功能使得GOT-OCR2.0在各种实际应用中表现出色。
- 文档OCR:GOT-OCR2.0能够处理文档中完整页面的文字识别,无论是纯文本文档,还是含有表格、公式等复杂内容的文档。这一功能极大地方便了文档数字化和信息管理。
- 格式化文本OCR:该系统支持将光学文档中的文本直接转换为Markdown、LaTeX等格式,保持复杂文档的原始排版和格式。这使得后续编辑和排版工作更加高效。
- 动态分辨率处理:GOT-OCR2.0采用动态分辨率技术,支持对超高分辨率图像(如大幅海报、拼接PDF页面)进行OCR处理,确保在图像过大时仍能保持较高的识别准确性。
- 多页OCR:该系统能够批量处理多页文档,例如长篇PDF文件或包含多张图片的OCR任务,显著提升了处理效率。这对于需要大量文档处理的用户尤为重要。公式、表格与图表识别除了基本文本识别,GOT-OCR2.0还能够识别和处理文档中的数学公式、化学分子式、表格及图表等复杂结构,并将其转换为可编辑格式(如LaTeX或Python字典格式),满足更专业的需求。
- 格式化输出:该系统支持生成多种格式化输出,包括Markdown、TikZ、SMILES、LaTeX等,以结构化方式输出识别到的字符,例如表格、数学公式和分子结构等,使得信息传递更加清晰。
- 性能与架构:GOT-OCR2.0采用了集成的vision encoder和decoder设计,能够同时处理多种类型的OCR输入,从而极大提高信息传递效率。其模型大小仅为1.43GB,相较于其他AI模型而言较小,但性能却非常强大,特别适合需要处理高复杂度OCR任务的用户。该模型还引入了local attention机制,有效解决了全局注意力机制在高分辨率图像中的内存消耗问题。
高性价比GPU资源:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_tongyong_toutiao
识别效果展示
截屏文本识别/文档识别/乐谱识别/图表识别

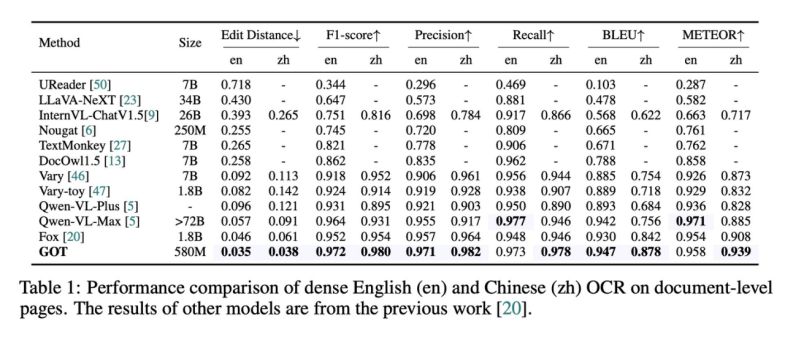
OCR2.0评测
总结
GOT-OCR2.0作为AI 2.0时代的重要产品,通过端到端设计、一体化架构和对多场景复杂内容的识别能力,为用户提供了精准、高效的OCR解决方案。无论是在文档数字化、场景文本识别还是复杂数据处理方面,它都展现出卓越的性能,是开发者和研究人员不可或缺的工具。




![[笔记]数据结构](https://i-blog.csdnimg.cn/direct/5660b22f11324ed38cf19e38e5706726.png)