大型程序成本高昂,这不仅仅是因为构建程序需要花费时间。程序的大小几乎总是涉及复杂性,而复杂性会让程序员感到困惑。混乱的程序员反过来又会在程序中引入错误(bug)。大型程序则为这些错误提供了大量的隐藏空间,使它们难以被发现。
让我们简单回顾一下导言中的最后两个示例程序。第一个程序自成一体,长六行。

第二行依赖于两个外部函数,长度为一行。

哪个程序更有可能包含错误?
如果算上 sum 和 range 定义的大小,第二个程序也很大,甚至比第一个程序还大。但我仍然认为它更有可能是正确的。这是因为解法是用与所要解决的问题相对应的词汇来表达的。求一系列数字的和与循环和计数器无关。它与范围和求和有关。这些词汇(函数 sum 和 range)的定义仍将涉及循环、计数器和其他附带细节。但由于这些定义表达的概念比整个程序简单,因此更容易理解。
抽象
在编程中,这类词汇通常被称为抽象。抽象使我们有能力在更高的(或更抽象的)层次上讨论问题,而不会被无趣的细节所困扰。
打个比方,比较一下这两种豌豆汤的配方。第一个食谱是这样的:
将每人 1 杯干豌豆放入容器中。加水直到完全盖住豌豆。将豌豆放在水中至少 12 小时。将豌豆从水中取出,放入煮锅中。每人加 4 杯水。盖上锅盖,将豌豆炖煮两小时。每人取半个洋葱。用刀切成块。将其加入豌豆中。每人取一根芹菜。用刀切成块。加入豌豆中。每人取一根胡萝卜。切成块。用刀切!加入豌豆中。再煮 10 分钟。
这是第二个食谱:
每人:1 杯干豌豆、4 杯水、半个切碎的洋葱、一根芹菜和一根胡萝卜。
将豌豆浸泡 12 小时。炖煮 2 小时。切碎并加入蔬菜。再煮 10 分钟。
第二种更简短,也更容易理解。但你确实需要理解更多与烹饪有关的单词,如浸泡、煨、切,我猜还有蔬菜。
在编程时,我们不能指望所有需要的单词都在字典里等着我们。因此,我们可能会陷入第一个菜谱的模式--逐一列出计算机必须执行的精确步骤,而对这些步骤所表达的高层次概念视而不见。在编程过程中,注意到自己的工作抽象程度太低是一项有用的技能。
抽象化重复
正如我们迄今为止所看到的那样,普通函数是构建抽象的好方法。但有时它们也有不足之处。一个程序通常要做一定次数的事情。为此,你可以写一个 for 循环,就像这样:

我们能把 “做 N 次某事 ”抽象成一个函数吗?那么,编写一个调用 N 次 console.log 的函数就很容易了。

但是,如果我们除了记录数字之外还想做其他事情呢?既然 “做某事 ”可以用函数来表示,而函数就是值,那么我们就可以将我们的操作作为函数值传递。

我们不必通过一个预定义函数来重复。通常,在现场创建一个函数值反而更容易。

它的结构有点像 for 循环--首先描述循环的类型,然后提供主体。不过,主体现在写成了函数值,被包裹在重复调用的括号中。这就是为什么它必须用结束括号和结束括号来结束。在本例这种情况下,如果主体是一个小表达式,也可以省略括号,将循环写在一行中。(译者:像Java的lambda表达式,传递的是行为而不是数据)
高阶函数
以其他函数为参数或返回其他函数的函数称为高阶函数。由于我们已经看到函数是有规则的值,因此这种函数的存在并没有什么特别之处。高阶函数一词来自数学,在数学中,函数与其他值之间的区别更受重视。高阶函数允许我们对行为而不仅仅是数值进行抽象。它们有多种形式。例如,我们可以使用创建新函数的函数。

我们还可以让函数改变其他函数。

我们甚至可以编写提供新型控制流的函数。

有一种内置的数组方法 forEach 可以提供类似于 for/of 循环的高阶函数。
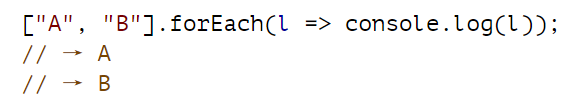
脚本数据集
数据处理是高阶函数大显身手的领域之一。要处理数据,我们需要一些实际的示例数据。本章将使用一个有关脚本的数据集,即拉丁文、西里尔文或阿拉伯文等书写系统。
还记得第 1 章中的 Unicode(统一字符编码标准)吗?这些字符大多与特定的脚本相关联。该标准包含 140 种不同的脚本,其中 81 种现在仍在使用,59 种是历史脚本。
虽然我只能流利地阅读拉丁文字,但我很欣赏人们用至少 80 种其他书写系统书写文字的事实,其中许多我甚至都不认识。例如,这里有一个泰米尔语手写体样本:

示例数据集包含有关在 Unicode 中定义的 140 个脚本的部分信息。本章的编码沙盒中有 SCRIPTS 绑定。绑定包含一个对象数组,每个对象描述一个脚本。
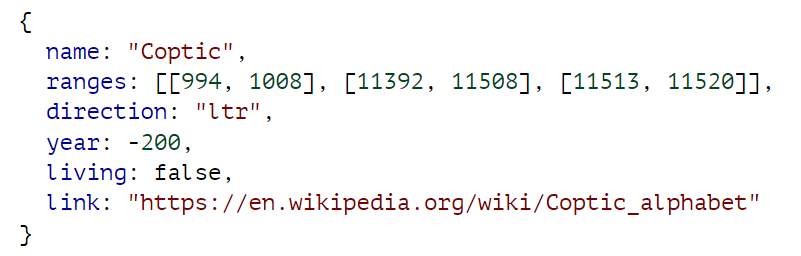
此类对象会告诉我们该文字的名称、分配给它的 Unicode 范围、书写方向、(大致)起源时间、是否仍在使用,以及指向更多信息的链接。方向可以是 “ltr ”表示从左到右,“rtl ”表示从右到左(阿拉伯文和希伯来文的书写方式),或 “ttb ”表示从上到下(蒙古文的书写方式)。
ranges 属性包含一个 Unicode 字符范围数组,每个字符范围都是一个包含下限和上限的双元素数组。这些范围内的任何字符代码都会分配给脚本。下限是包容性的(代码 994 是科普特文字),上限是非包容性的(代码 1008 不是)。
筛选数组
如果我们想找到数据集中仍在使用的脚本,下面的函数可能会有所帮助。它可以过滤掉数组中没有通过测试的元素。

该函数使用名为 test 的参数(一个函数值)来填补计算中的 “空白”--即决定收集哪些元素的过程。请注意,过滤器函数不是从现有数组中删除元素,而是只用通过测试的元素建立一个新数组。这个函数是纯粹的。它不会修改给定的数组。
与 forEach 一样,filter 也是一个标准的数组方法。示例中定义该函数只是为了展示它的内部功能。从现在起,我们将这样使用它:

通过MAP变型
假设我们有一个代表脚本的对象数组,它是通过对 SCRIPTS 数组进行某种过滤而产生的。我们需要的是一个名称数组,这样更容易检查。
map 方法通过对数组的所有元素应用一个函数来转换数组,并根据返回值建立一个新数组。新数组的长度与输入数组相同,但其内容已被函数映射为新形式。

与 forEach 和 filter 一样,map 也是一种标准的数组方法。
通过REDUCE归纳
使用数组的另一个常见方法是计算其中的单个值。我们常举的例子,即计算一组数字的总和,就是这样一个例子。另一个例子是找出字符数最多的脚本。
代表这种模式的高阶操作称为 reduce(有时也称为 fold)。它通过重复从数组中提取单个元素并将其与当前值相结合来建立一个值。当求和数字时,你会从数字 0 开始,然后将每个元素加到总和中。
还原的参数除了数组外,还有组合函数和起始值。这个函数没有 filter 和 map 那么简单,所以要仔细研究一下:

标准数组方法 reduce 当然与此函数相对应,但它还有一个额外的便利之处。如果数组中至少包含一个元素,则允许省略起始参数。该方法将以数组的第一个元素作为起始值,并从第二个元素开始还原。

要使用 reduce(两次)找出字符数最多的脚本,我们可以这样写:

字符计数(characterCount)函数通过对分配给脚本的范围的大小求和来减少这些范围。请注意在reducer函数的参数列表中使用了重组。然后,第二次调用 reduce 函数时,通过反复比较两个脚本并返回较大的一个,从而找到最大的脚本。
在 Unicode 标准中,汉族文字有 89,000 多个字符,是迄今为止数据集中最大的文字系统。汉文字有时用于中文、日文和韩文。这些语言共享大量字符,但书写方式往往不同。统一码联盟(总部设在美国)决定将它们视为单一的书写系统,以节省字符编码。这就是所谓的 “汉文统一”,至今仍让一些人非常愤怒。
可组合性
考虑一下,如果没有高阶函数,我们会如何编写上一个示例(找出最大的脚本)。代码并没有差多少。

虽然多了一些绑定,程序也长了四行,但仍然非常易读。
当你需要组合操作时,这些函数提供的抽象功能就会大放异彩。例如,让我们编写代码,找出数据集中在世和已死亡脚本的平均起源年份。

正如您所看到的,Unicode 中已消亡的脚本平均比还活着的脚本更古老。这并不是一个非常有意义或令人惊讶的统计数据。但我希望你会同意,用来计算它的代码并不难读。你可以把它看成一个流水线:我们从所有脚本开始,过滤掉活着(或死了)的脚本,从这些脚本中提取年数,求平均值,然后将结果四舍五入。
当然,你也可以把这个计算过程写成一个大循环。

不过,要看清计算的内容和方式就比较困难了。而且,由于中间结果并不表示为连贯的值,因此要将平均值之类的东西提取到一个单独的函数中,工作量会更大。就计算机的实际操作而言,这两种方法也大相径庭。前者在运行 filter 和 map 时会建立新数组,而后者只计算一些数字,工作量较少。你通常可以承受可读性高的方法,但如果你要处理巨大的数组,而且要处理很多次,那么抽象性较低的风格可能值得额外的速度。
字符串和字符编码
这个数据集的一个有趣用途是找出一段文本使用的脚本。让我们通过一个程序来实现这一点。请记住,每个脚本都有一个与之相关的字符代码范围数组。给定一个字符代码后,我们可以使用类似的函数来查找相应的脚本(如果有的话):

some 方法是另一个高阶函数。它接受一个测试函数,并告诉你该函数是否对数组中的任何元素返回 true。
但我们如何获得字符串中的字符编码呢?
在第 1 章中,我提到 JavaScript 字符串是由一串 16 位数字编码而成的。这些数字称为编码单元。最初,Unicode 字符编码就应该包含在这样的单元中(这样就有 65000 多个字符)。当人们发现这显然不够时,许多人对每个字符需要使用更多内存表示反对。为了解决这些问题,人们发明了UTF-16(JavaScript 字符串也使用这种格式)。它使用一个 16 位编码单元来描述大多数常见字符,但对其他字符则使用一对两个这样的单元。
如今,UTF-16 被普遍认为是一个坏主意。UTF-16似乎是故意设计来招致错误的。要编写假装代码单元和字符是一回事的程序很容易。如果你的语言不使用双单位字符,这样的程序看起来会运行得很好。但一旦有人试图将这样的程序用于一些不常用的汉字,程序就会崩溃。幸运的是,随着表情符号的出现,每个人都开始使用双单位字符,处理此类问题的负担也得到了更公平的分配。
遗憾的是,对 JavaScript 字符串的明显操作,如通过 length 属性获取字符串长度和使用方括号访问字符串内容,只涉及代码单元。

JavaScript 的 charCodeAt 方法提供的是代码单元,而不是完整的字符代码。后来添加的 codePointAt 方法确实提供了完整的 Unicode 字符,因此我们可以用它从字符串中获取字符。但传递给 codePointAt 的参数仍然是代码单元序列的索引。要遍历字符串中的所有字符,我们仍然需要处理一个字符占用一个还是两个代码单元的问题。
在上一章中,我提到 for/of 循环也可用于字符串。与 codePointAt 一样,这种循环也是在人们敏锐地意识到 UTF-16 的问题时引入的。使用它对字符串进行循环时,得到的是真实字符,而不是代码单元。

如果您有一个字符(将是一个或两个代码单位的字符串),您可以使用 codePointAt(0) 来获取其代码。
识别文本
我们有了一个 characterScript 函数和一种正确循环遍历字符的方法。下一步是统计属于每个脚本的字符。下面的计数抽象将非常有用:
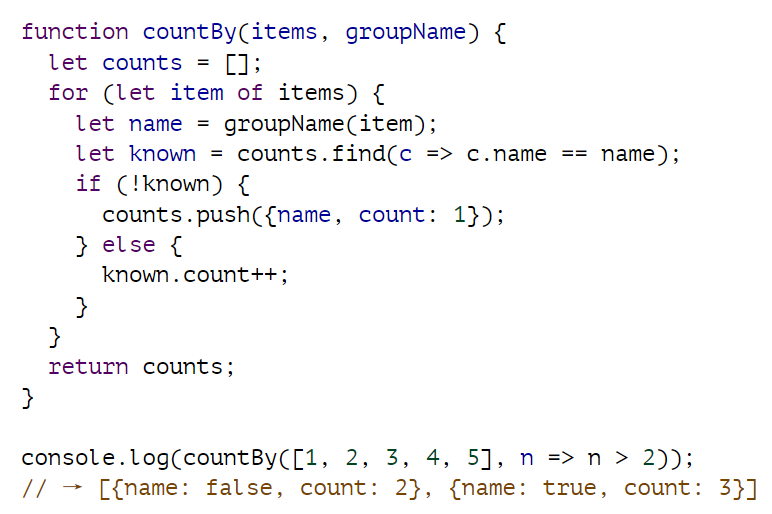
countBy 函数需要一个集合(任何可以用 for/of 循环的集合)和一个为给定元素计算组名的函数。它返回一个对象数组,每个对象都命名一个组,并告诉你在该组中找到的元素数量。
它使用另一个数组方法 find,该方法遍历数组中的元素,并返回函数返回 true 的第一个元素。如果找不到这样的元素,则返回 undefined。
通过使用 countBy,我们可以编写一个函数,告诉我们在一段文本中使用了哪些脚本。

函数首先按名称统计字符数,使用 characterScript 为字符分配名称,对于不属于任何脚本的字符,则返回字符串 “none”。由于我们对这些字符不感兴趣,因此过滤调用会从结果数组中删除 “none ”条目。
为了计算百分比,我们首先需要知道属于脚本的字符总数,这可以通过 reduce 计算。如果找不到这样的字符,函数会返回一个特定的字符串。否则,它会用 map 将计数条目转换为可读字符串,然后用 join 将它们合并。
总结
能够将函数值传递给其他函数是 JavaScript 的一个非常有用的方面。它允许我们编写一些函数,这些函数可以为计算建模,但其中存在 “空白”。调用这些函数的代码可以通过提供函数值来填补空白。
数组提供了许多有用的高阶方法。您可以使用 forEach 循环数组中的元素。filter 方法会返回一个新数组,其中只包含通过谓词函数的元素。你可以使用 map 将每个元素通过一个函数来转换数组。你可以使用 reduce 将数组中的所有元素合并为一个值。some 方法会测试是否有元素匹配给定的谓词函数,而 find 方法则会找到第一个匹配谓词的元素。
练习
扁平化
将 reduce 方法与 concat 方法结合使用,可将数组 “扁平化 ”为包含原始数组所有元素的单个数组。
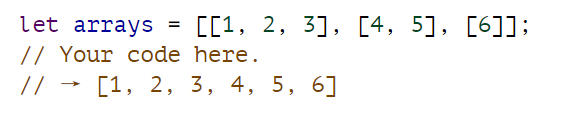
代码:
function flatArray(arr) {
return arr.reduce((a, b) => {
return a.concat(b);
}, []);
}
console.log(flatArray([[1,2,3],[4,5]]));自循环
编写一个高阶函数循环,提供类似 for 循环语句的功能。它应包含一个值、一个测试函数、一个更新函数和一个主体函数。每次迭代时,应首先在当前循环值上运行测试函数,如果返回 false,则停止。然后调用 body 函数,给出当前值,最后调用 update 函数创建一个新值,并从头开始。
在定义函数时,可以使用普通循环来执行实际循环。

代码:
function loop(value, test, update, body) {
while(test(value)) {
body(value);
value = update(value);
}
}
loop(2, n => n < 10, n=> n + 1, console.log)任何事
数组也有一个与 some 方法类似的 every 方法。当给定函数对数组中的每个元素都返回 true 时,该方法返回 true。在某种程度上,some 是作用于数组的 || 操作符的一个版本,而 every 则类似于 && 操作符。
将 every 实现为一个以数组和谓词函数为参数的函数。编写两个版本,一个使用循环,另一个使用 some 方法。

循环:
function loop_every(array, test) {
let flag = true;
for (let arr of array) {
if (!test(arr)) {
flag = false;
break;
}
}
return flag;
}
console.log(loop_every([1, 2, 3, 4], n => n > 0));some:
function loop_some(array, test) {
let flag = true;
for (let arr of array) {
if (![arr].some(test)) {
flag = false;
break;
}
}
return flag;
}
console.log(loop_some([1, 2, 3, 4], n => n > 0));主导写作方向
编写一个函数,计算文本字符串的主要书写方向。请记住,每个脚本对象都有一个方向属性,可以是 “ltr”(从左到右)、“rtl”(从右到左)或 “ttb”(从上到下)。
主导方向是与脚本关联的大多数字符的方向。本章前面定义的 characterScript 和 countBy 函数在这里可能很有用。

译者注:我是把返回值这里做了一下调整,其他的地方没变
//输出
return scripts.map(({ name, count }) => {
let rate = Math.round(count * 100 / total);
if (rate > 50) {
let script = SCRIPT2.find(n=>n.name == name);
if(script){
return script.direction;
}
}
return 'none';
// return `${Math.round(count * 100 / total)} % ${name}`;
}).filter(n=>n != 'none').join(',');