文章目录
- Spring Cloud 工程搭建
- 服务拆分
- 示例
- 数据库
- 工程搭建
- 构建父子工程
- 创建父工程
- 创建子项目
- 完成两个接口
- 远程调用
- 实现
- 添加ProductInfo字段
- 定义RestTemplate
- 修改OrderService
- 服务注册/服务发现 - Eureka
- 注册中心
- CAP理论
- 常见的注册中心
- Zookeeper
- Eureka
- Nacos
- Eureka 介绍
- 搭建Eureka Server
- 创建Eureka-server子模块
- 引入eureka-server依赖
- 编写配置文件
- 启动服务
- 服务注册
- 完善配置文件
- 启动服务
- 服务发现
- 引入依赖
- 完善配置文件
- 远程调用
- 启动服务
Spring Cloud 工程搭建
服务拆分
微服务到底多小才算"微",实际上并没有明确的标准,但是不是越小越好,因为服务越小,微服务架构的缺点会越来越明显
服务拆分一般遵循以下原则:
- 单一职责原则:在微服务架构里面,一个微服务也应该只负责一个功能或业务领域,只关注自己的特定业务领域
- 服务自治:服务自治是指每个微服务都应该具备高度自治功能,即每个服务都要做到独立开发,独立测试,独立构建,独立部署,独立运行
- 单向依赖:微服务之间需要做到单向依赖,严禁循环依赖,双向依赖,但是如果某些场景是在无法避免循环依赖或者双向依赖,可以考虑使用消息队列等其他方式来实现
实际上,微服务架构并没有标准架构,合适的就是最好的
示例
以电商系统的订单列表为例,需要提供订单列表以及商品信息
我们将这个服务拆成:
- 订单服务:提供订单ID,获取订单详细信息
- 商品服务:根据商品ID,提供商品详细信息

数据库
DROP TABLE IF EXISTS `order_detail`;
CREATE TABLE `order_detail` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`product_id` bigint(20) NULL DEFAULT NULL,
`num` int(10) NULL DEFAULT 0,
`price` bigint(20) NULL DEFAULT NULL,
`delete_flag` tinyint(4) NULL DEFAULT 0,
`create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '订单表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of order_detail
-- ----------------------------
INSERT INTO `order_detail` VALUES (1, 2001, 1001, 1, 99, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
INSERT INTO `order_detail` VALUES (2, 2002, 1002, 1, 30, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
INSERT INTO `order_detail` VALUES (3, 2001, 1003, 1, 40, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
INSERT INTO `order_detail` VALUES (4, 2003, 1004, 3, 58, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
INSERT INTO `order_detail` VALUES (5, 2004, 1005, 7, 85, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
INSERT INTO `order_detail` VALUES (6, 2005, 1006, 7, 94, 0, '2024-09-23 20:51:31', '2024-09-23 20:51:31');
-- ----------------------------
-- Table structure for product_detail
-- ----------------------------
DROP TABLE IF EXISTS `product_detail`;
CREATE TABLE `product_detail` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '产品id',
`product_name` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '产品名称',
`product_price` bigint(20) NOT NULL COMMENT '产品价格',
`state` tinyint(4) NULL DEFAULT 0 COMMENT '产品状态 0-有效 1-下架',
`create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10011 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '产品表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of product_detail
-- ----------------------------
INSERT INTO `product_detail` VALUES (1001, 'T恤', 101, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1002, '短袖', 30, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1003, '短裤', 44, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1004, '卫衣', 58, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1005, '⻢甲', 98, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1006, '羽绒服', 101, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1007, '冲锋衣', 30, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1008, '袜子', 44, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (1009, '鞋子', 58, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
INSERT INTO `product_detail` VALUES (10010, '毛衣', 98, 0, '2024-09-23 20:59:38', '2024-09-23 20:59:38');
工程搭建
构建父子工程
创建父工程
pow文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.JWCB</groupId>
<artifactId>JE0924SpringCloudTest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<modules>
<module>order-service</module>
<module>product-service</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.6</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<java.version>17</java.version>
<mybatis.version>3.0.3</mybatis.version>
<mysql.version>8.0.33</mysql.version>
<spring-cloud.version>2022.0.3</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter-test</artifactId>
<version>${mybatis.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
关于DependencyManagement 和 Dependencies
dependencies:将所依赖的jar直接加到项目里面,子项目也会继承该依赖dependencyManagement:只是声明依赖,并不实现jar包引入.如果子项目需要用到相关依赖,需要显示声明.如果子项目没有指定具体版本,会从父项目中读取version,如果子项目中指定了版本号,就会使用子项目中指定的jar版本- 此外父工程的打包方式应该是pom此处需要手动修改

创建子项目

修改两个子项目的pom.xml文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
完成两个接口
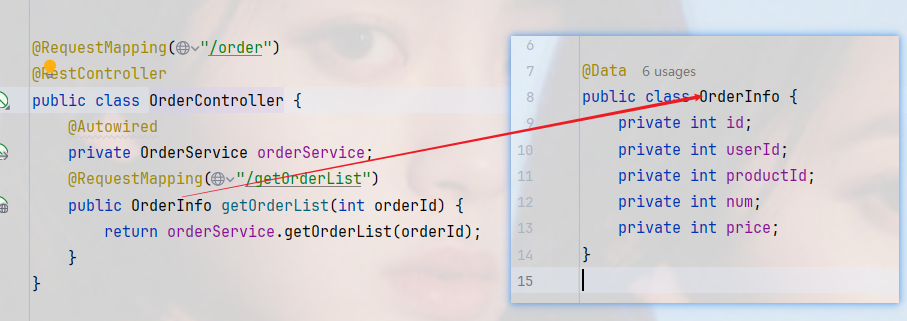

远程调用
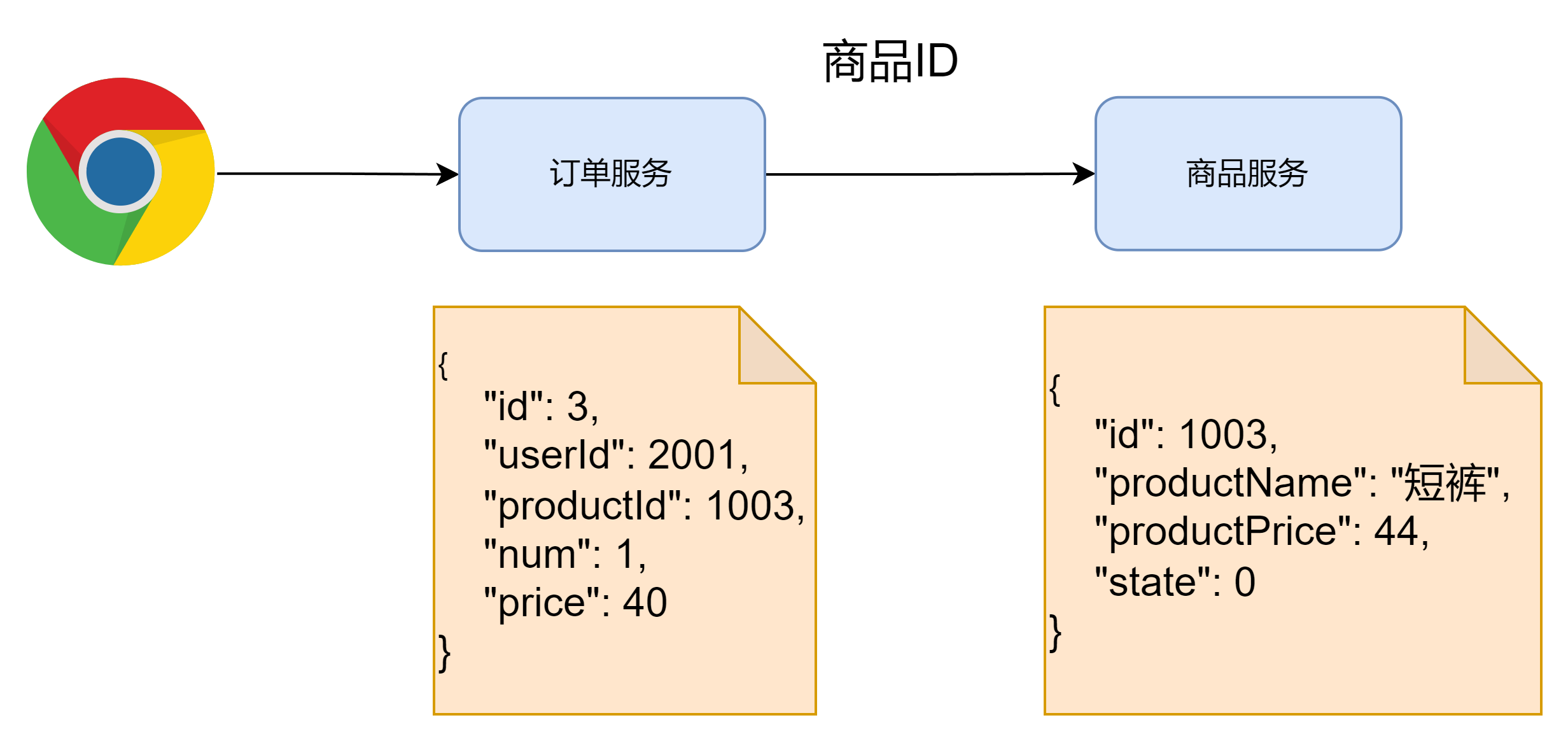
在查询订单信息的时候,根据订单里的产品ID,获取到产品的详细信息
实现
在order-Service服务中向product_service服务发送一个http请求,将获取到的返回结果和订单数据结合在一起即可
添加ProductInfo字段
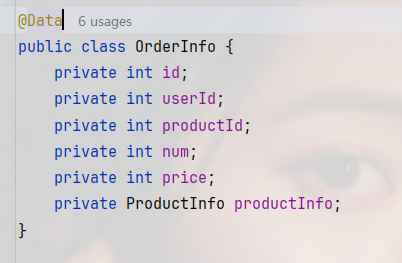
定义RestTemplate
@Configuration
public class BeanConfig {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
修改OrderService
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
public OrderInfo getOrderList(int orderId){
OrderInfo orderInfo = orderMapper.getOrderList(orderId);
String url = "http://127.0.0.1:8081/product/getProduct?productId=" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url,ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
}
RestTemplate是Spring3.0开始支持的一个http请求工具,是一个同步的REST API客户端,提供了常见的REST请求方案的模版
但是这个时候的项目存在有几个问题
- 远程调用的时候,URL和IP和端口号都是写死的,如果更换IP,需要修改代码
- 远程调用的时候,URL非常容易写错
- 多机部署的压力如何分担
- 所有的服务都可以调用这个接口,存在风险
- …
服务注册/服务发现 - Eureka
注册中心
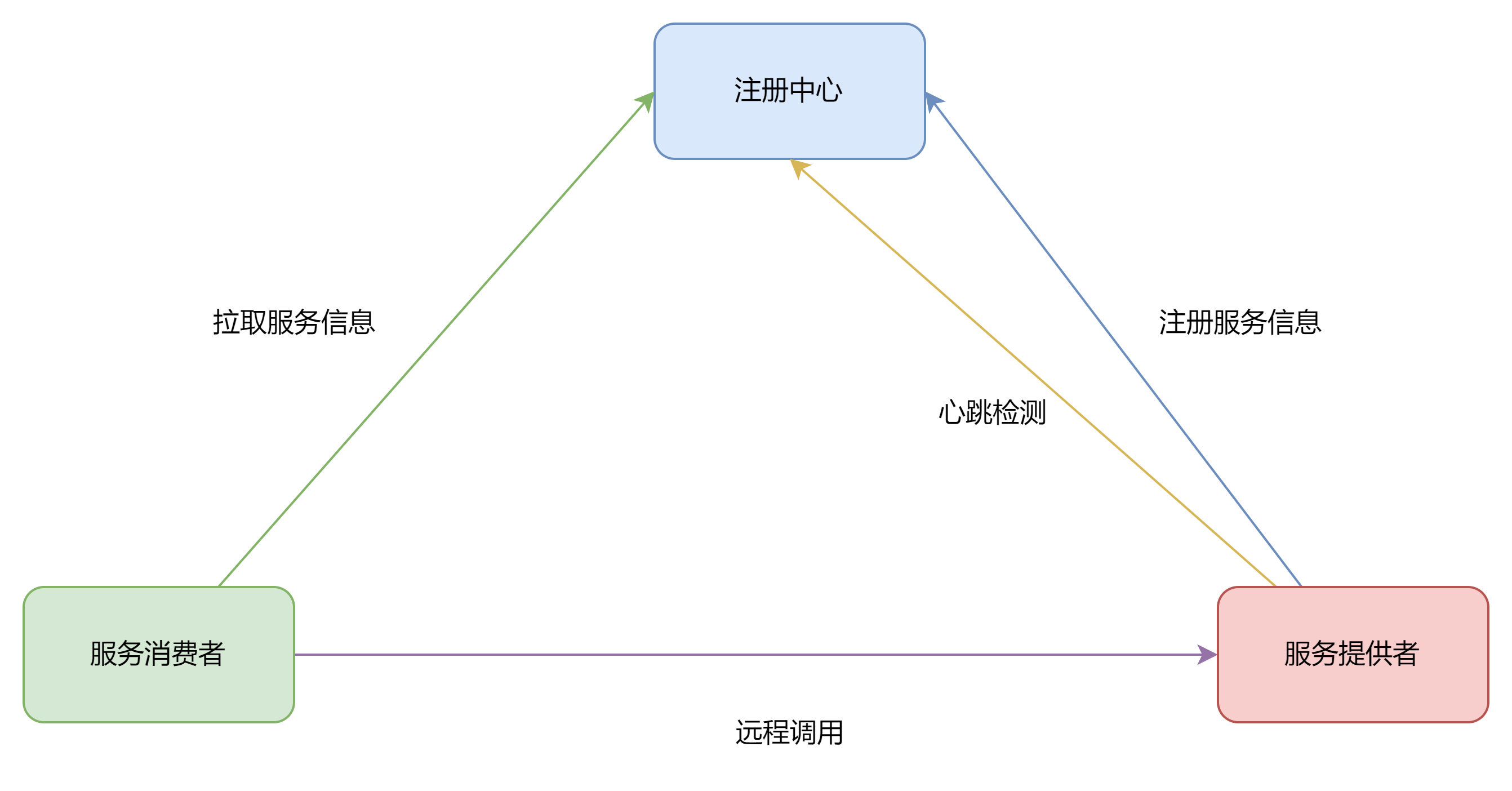
随着微服务的流行与流量的激增,机器规模逐渐增大,并且机器有频繁的上下线行为,这时候就需要手动去维护这个配置信息,是一个比较麻烦的事情.所以我们需要有这么一个东西,能够维护一个服务列表,当哪个机器上线了,那个机器宕机了,这些信息都会自动更新到服务列表上,客户端拿到这个列表,直接进行服务调用即可,这个就是注册中心
注册中心主要有三种角色
- 服务提供者(Server) :一次业务里面,被其他微服务调用的服务,也就是提供接口给其他微服务
- 服务消费者(Client):一次业务中,调用其他微服务的服务,也就是调用其他微服务提供的接口
- 服务注册中心(Register) : 用于保存Service的注册信息,但Service节点发生变化的时候,Register会同步变更,服务与注册中心使用一定的机制通信(如果注册中心与某服务长时间无法通信,就会注销该实例
总结为两个概念
- 服务注册:服务提供者在启动的时候,向Register注册自身服务,并向Register定期发送心跳汇报其存或状态
- 服务发现:服务消费者从注册查询查询服务提供者的地址,并通过该地址调用服务提供者的接口,服务发现的一个重要作用就是提供给服务消费者一个可用的服务列表
CAP理论
CAP理论是分布式系统设计最基础,也是最为关键的理论

- 一致性:在CAP理论中的一致性,指的是强一致性,所有节点在同一时间具有相同的数据
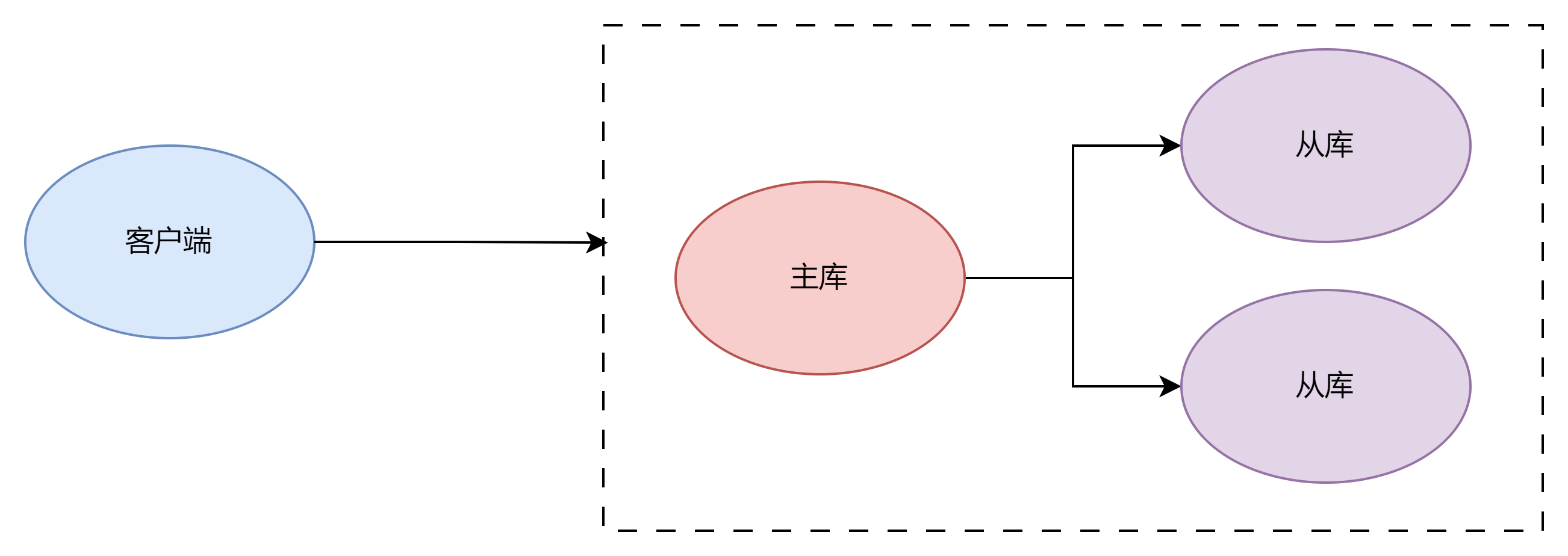
以数据库集群为例
此时当客户端向数据库集群发送了一个数据修改的请求的时候,数据库集群需要向客户端进行响应
响应的实际分为两种:
- 主库收到请求,并且处理成功,此时数据还未完全同步到从库,但是随着时间的推移,最终会达到一致性
- 主库接受到请求,并且所有从库数据都同步成功的时候
那么就对应两种一致性
- 强一致性:主库和仓库,不论何时,对外提供的服务嗾使一致的
- 弱一致性:随着时间的推移,最终达到了一致
- 可用性:指的是,对所有的请求,都有响应,但是这个响应可能是错误的
- 分区容错性:指的是,在网络分区的情况下,系统依然可以对外提供服务
因为P一定要保证,那么A和C只能是二选一
所以我们的架构就只能是CP架构或者是AP架构:
- cp架构,为了保证分布式系统对外的数据一致性,于是选择不返回任何数据
- ap架构,为了分布式系统的可用性,节点返回旧版本的数据(即使这个数据不正确)
常见的注册中心
Zookeeper
实际上Zookeeper的官方并没有说他是一个注册中心,但是国内java体系,大部分的集群环境都是依赖他来完成注册中心的功能
Eureka
Eureka是Netflix开发的基于Rest的服务发现框架,主要用于服务注册,管理,负载均衡和服务故障转移
Nacos
Nacos是Spring Cloud Alibaba架构中重要的组件,除了服务注册的功能之外,Nacos还支持配置管理,流量管理,DNS,动态DNS等多种特性
其中:
Zookeeper支持的CAP理论是CP,Eureka是AP,Nacos默认是AP,也可以是CP
Eureka 介绍
Eureka主要分为两个部分
- Eureka Server:作为注册中心Service端,向微服务应用程序提供服务注册,发现,健康检查等能力
- Eureka Client:服务提供者,服务启动的时候,会向Eureka Service注册自己的信息(IP,端口,服务信息等)
我们使用Eureka的学习,主要包含以下三个部分:
- 搭建Eureka Server
- 将order-service,product-service都注册到Eureka
- order-service远程调用时,从Eureka中获取product-service的服务列表,然后进行交互
搭建Eureka Server
创建Eureka-server子模块
引入eureka-server依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
编写配置文件
server:
port: 8082
spring:
application:
name: eureka-server
eureka:
instance:
hostname: localhost
client:
fetch-registry: false # 表⽰是否从Eureka Server获取注册信息,默认为true.因为这是⼀个单点的Eureka Server,不需要同步其他的Eureka Server节点的数据,这⾥设置为false
register-with-eureka: false # 表⽰是否将⾃⼰注册到Eureka Server,默认为true.由于当前应⽤就是Eureka Server,故⽽设置为false.
service-url:
# 设置与Eureka Server的地址,查询服务和注册服务都需要依赖这个地址.
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
启动服务
@EnableEurekaServer
@SpringBootApplication
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class,args);
}
}
通过http://127.0.0.1:8082/访问
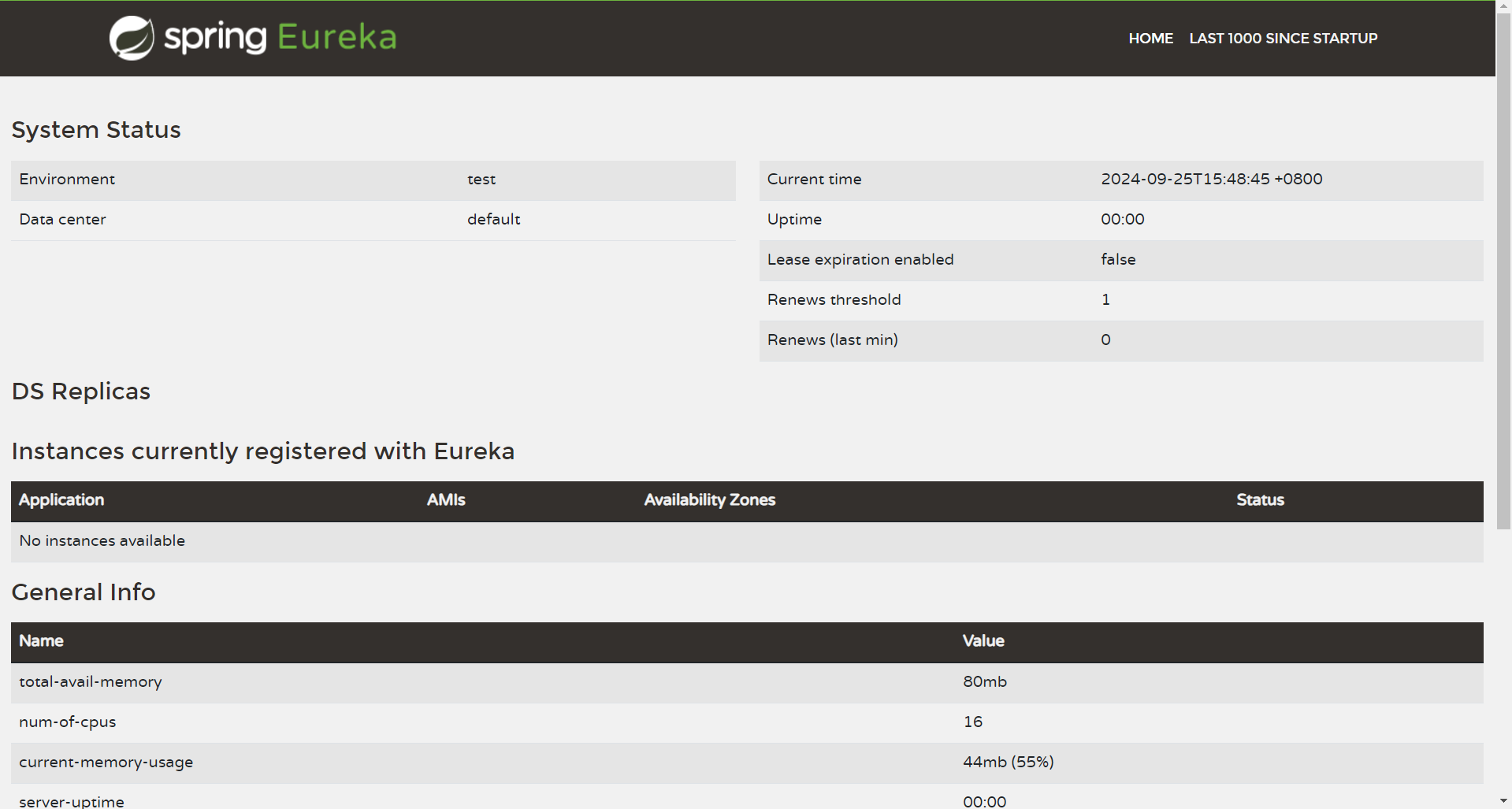
服务注册
将product-service注册到eureka-server中
```xml org.springframework.cloud spring-cloud-starter-netflix-eureka-client ```完善配置文件
添加服务名称和eureka地址
spring:
application:
name: product-service
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8082/eureka
启动服务
再次访问http://127.0.0.1:8082/
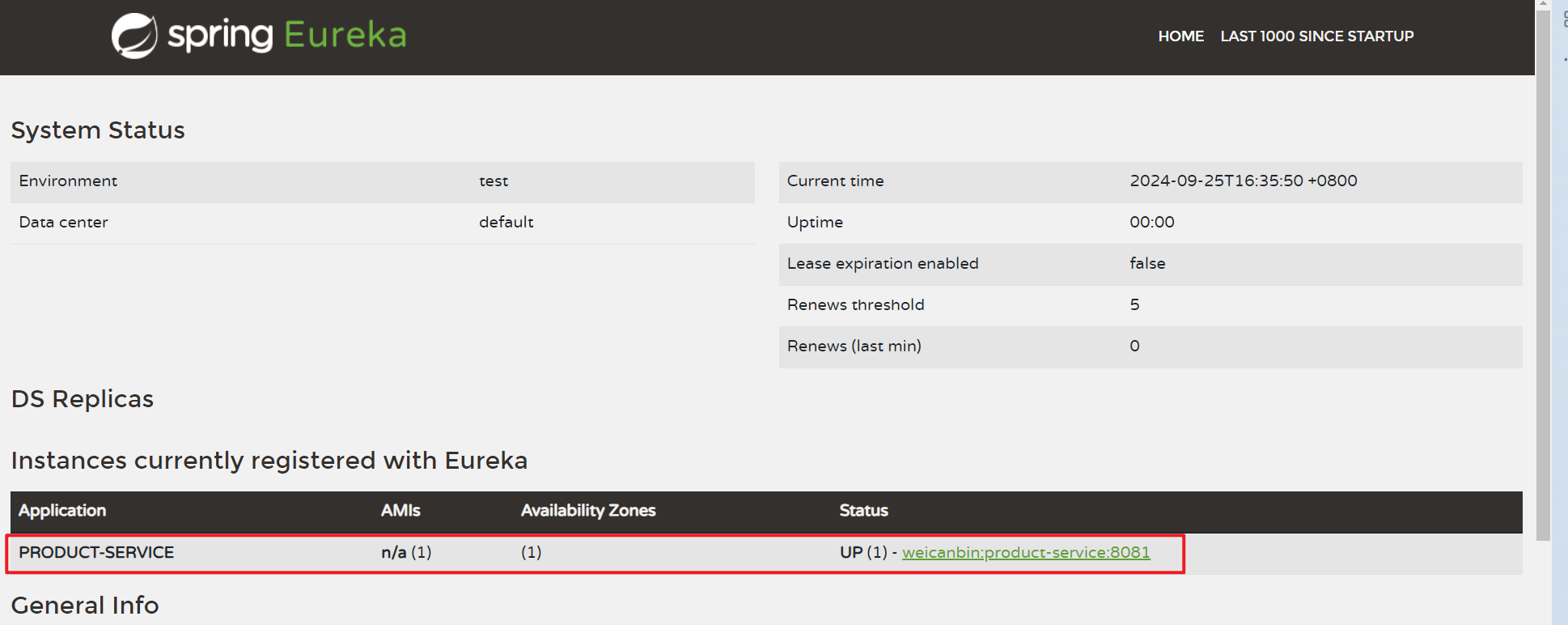
可以看到product-service已经注册到eureka上了
服务发现
修改order-service,在远程调用的时候,从eureka-server拉取product-service的服务信息,实现服务发现
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
完善配置文件
服务发现也需要知道eureka地址
spring:
application:
name: order-service
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8082/eureka
远程调用
我们需要从eureka-service中获取product-service的列表,并选择其中的一个进行调用
@Service
public class OrderService {
private static final Logger log = LoggerFactory.getLogger(OrderService.class);
@Autowired
private OrderMapper orderMapper;
@Resource
private DiscoveryClient discoveryClient;
@Autowired
private RestTemplate restTemplate;
public OrderInfo getOrderList(int orderId){
OrderInfo orderInfo = orderMapper.getOrderList(orderId);
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(0);
String url = instance.getUri()+"/product/getProduct?productId=" + orderInfo.getProductId();
log.info(url);
ProductInfo productInfo = restTemplate.getForObject(url,ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
}
启动服务

此时通过接口访问:

但是

如果一个服务对应了多个实例呢?? 流量是否可以合理的分配到多个实例呢,这时候就需要负载均衡了




![[遇到问题] Word中插入公式横线“-”变成了长连字符](https://i-blog.csdnimg.cn/direct/1162b1da32384435b83d866db0a6e64d.png)