作者:田力、陈允德
编辑整理:曾辉
引言
随着数字化转型的深入,企业对数据集成与处理的需求不断提升,如何高效、灵活地处理多系统、多数据源的同步,成为企业数据系统建设中的关键挑战。

在这篇文章中,来自华润置地的田力和陈允德老师将跟大家回顾PMC对话标杆用户——华润置地的选型数据集成框架的心历路程,在对比多个数据集成开源框架后,最终选择了Apache SeaTunnel。
这背后有哪些技术决策?在使用过程中华润置地又解决了哪些实际问题?这些实际应用经验将为新用户提供宝贵的参考,帮助大家更好地理解和使用SeaTunnel。
为什么做数据集成平台
如何发现Apache SeaTunnel?
在2023年初,我们在数据处理过程中遇到的多个痛点和问题,每个公司在数据集成、数据交换和数据同步方面都有自己的需求,华润置地也不例外。
我们面临着多个数据源的整合需求,包括业务系统之间的集成,以及业务系统与数据仓库之间的数据交互。
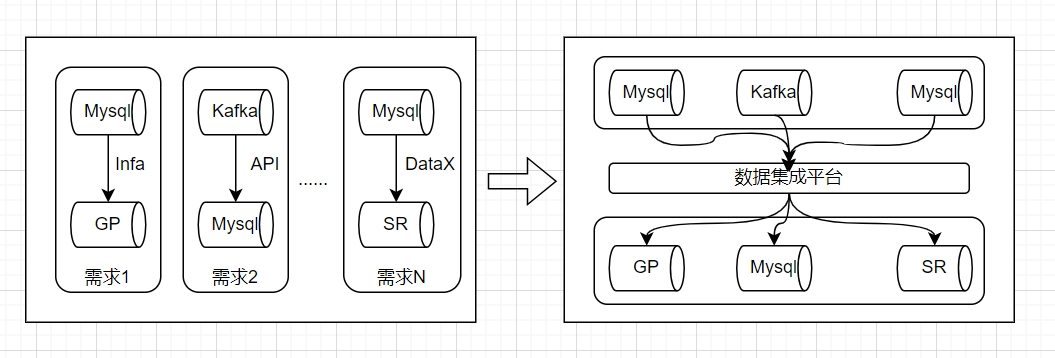
调研了多个流行的数据集成框架,包括DataX、Sqoop等传统工具,然而这些工具在扩展性和多引擎支持方面的局限性都让我们感到不够理想。
平台目标
基于上述背景,我们希望建立一个统一的数据集成平台,采用一致的技术栈来集中管理数据集成的各项需求。
构建数据集成平台后,我们预计会发生以下几个重要转变:
从烟囱式到统一管理:过去的数据集成是以各自独立的方式进行的,建立平台后,我们能够通过统一的接口进行数据集成,所有的集成任务将集中管理,提升了整体效率。
技术栈的统一:选择Apache SeaTunnel作为我们的数据集成引擎,使得我们能够支持多种数据源的整合,同时降低了运维成本。
支持离线和实时集成:早期我们主要采用定期的离线集成,如每小时或每天调度集成任务。而基于SeaTunnel的框架,我们能够支持全场景的实时与离线数据集成,极大丰富了我们的数据处理能力。
数仓构建模式的的转变
除了建立数据集成平台,华润置地的数据仓库构建模式也经历了一次重要转变。

早期,我们主要依赖个人开发,工具则使用Informatica,这一工具采用了传统的ETL(抽取、转换、加载)模式,承担了大量的转换与抽取功能。
随着大数据技术的发展,出现了新的ELT模式。再到后来,又有了EtLT 的数仓加工模式,大家对于这个技术也提的比较多,这种模式能够更灵活地处理数据流,SeaTunnel的框架支持简单的转换处理,有助于提升数据质量和规范性。
在数据进入仓库之前,我们可以进行一些必要的加工和清洗,确保数据的准确性。
数据集成平台架构
我们的数据集成平台架构采用分层设计:
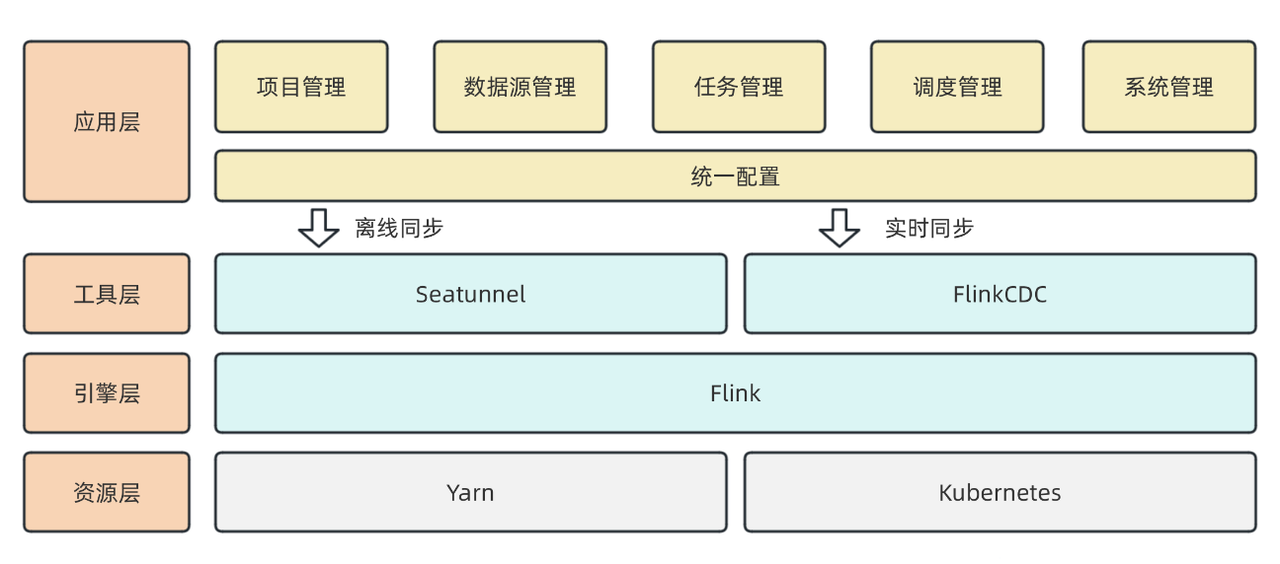
底层资源:包含两类资源,分别是YARN资源和K8S资源。
引擎层:我们复用了已有的Flink集群作为计算引擎,利用Flink强大的实时处理能力进行数据集成。
工具层:离线基于Apache SeaTunnel实现实时同步,实时用的Flink cdc。目前,我们对SeaTunnel的CDC能力进行了调研和验证,利用其功能来增强数据集成的实时性。
应用层:为用户提供项目管理、数据源管理、任务管理和配置等功能,所有管理任务均有界面可供用户操作,旨在提升操作效率,降低使用门槛。
以上是我们目前数据集成平台的整体架构。
为什么选择SeaTunnel?
刚才高老师也提到,为什么我们选择Apache SeaTunnel作为数据集成的引擎。在进行技术选型时,我们对多个框架进行了详细对比,特别关注了Apache SeaTunnel、DataX和Sqoop之间的差异。

在选型过程中,我们还对比了其他一些开源框架,比如DataX和Sqoop。通过对这些框架从多个维度进行比较,在分布式支持、丰富的Connector生态、良好的调度系统集成以及活跃的社区支持方面的表现,使其成为我们的首选解决方案。
对选型对比感兴趣的小伙伴也可以参考下这篇文章:
我们综合考虑了各自的优缺点,结合华润置地的需求与应用场景,最终选择了Apache SeaTunnel。
选型对比维度
我们列出了十几个对比维度,以下是我们关注的几个关键点:
运行模式
我们最关注的第一个维度是运行模式。框架是否支持分布式运行是决定其可扩展性的重要因素。如果一个框架不支持分布式运行,后期的扩展将会非常麻烦。因此,我们排除了不支持分布式的组件。
Connector生态支持
我们关注框架对Connector生态的支持。Apache SeaTunnel在这方面表现出色,其社区活跃,支持众多数据源连接,甚至包括一些新兴的数据源,比如对大模型的支持。良好的生态环境意味着框架将持续更新和演进。
调度系统集成
调度系统的集成是另一个重要考量因素。华润置地的调度系统是基于DolphinScheduler构建的,因此我们需要选择一个与DolphinScheduler有良好集成关系的框架。Apache SeaTunnel与DolphinScheduler之间的紧密集成使其在这一点上具有明显优势。
社区活跃度
我们在对比中还考虑了社区的活跃度。与社区成员交流的反馈速度、解决问题的效率都是我们评估的重要标准。Apache SeaTunnel社区的响应速度和活跃度在我们对比的各个框架中表现出色。
实践部分
接下来,由允德将为大家介绍华润置地在使用Apache SeaTunnel构建数据集成平台的实践经验。我们在平台上搭建了多个模块,包括项目管理、数据源管理、任务管理和数据质量管理等,用户可以在此平台上配置作业和开发任务。
数据集成平台概述
在确认选型Apache SeaTunnel作为离线底层引擎后,我们还选择Flink CDC作为实时底层引擎。

平台的功能模块包括:
- 项目管理:用户可以管理不同项目的数据集成任务。
- 数据源管理:支持对各种数据源的配置与管理。
- 任务管理:用户可以配置和管理数据集成任务。
- 数据质量管理:确保数据在集成过程中的质量。
用户在平台上可以配置SeaTunnel任务和离线任务,具体步骤包括:
- 配置Source和Sink端的数据源及相关信息。
- 设置任务名称,选择项目组,并确定调度时间。
- 确认数据源类型(全量或增量)并配置增量字段。
- 如果需要切片动作,还需设置切片字段,并配置前后置SQL和映射关系。
在配置完成后,应用层将数据存储到MySQL关系型数据库中,并返回一个Job ID到引擎层。这个任务ID在后续提交、关闭任务及获取任务状态时至关重要。
任务调度与管理
对于实时任务,我们通过CDC将任务提交到Flink。调度系统基于Apache DolphinScheduler构建,调度策略允许失败重试,从而在下次调度时间自动触发任务。
- 初次触发调度任务时,调度Worker会根据配置生成相应的配置文件。
- 我们的集群支持Flink on Yarn和Flink on K8s两个引擎。
- 我们实现了自动启动和关闭任务的脚本,监控任务的启动失败状态、运行状态以及任务资源的使用情况。
当任务启动失败时,Flink会进行相应的告警,确保及时发现问题。最终,运行日志接入到ERK中,并在数据集成平台的可视化界面上展示。
功能与集成
目前,我们的平台也支持Shell、API和客户端三种方式任务提交。
API接口能够返回当前任务的状态及失败原因,同时提供任务监控,包括读取和写入的数据量、任务运行吞吐量等多种指标,提升了用户体验和管理效率。
遇到的问题与解决方案
在实际生产中,我们遇到了几个问题,并总结了相应的经验:
JDBC连接参数问题
我们在使用SeaTunnel Flink引擎时,发现JDBC Connector有以下现象:
- SeaTunnel任务启动后,JDBC Sink下游数据库压力大,数据输出慢。
- Mysql作为Source时,
tinyint(1)类型某种情况同步到下游会变为null值
解决方案
1、JDBC Sink最后生成的SQL语句是多个单条insert语句,我们可以增加以下参数利用驱动的能力对Sink SQL进行攒批实现高性能写入:
reWriteBatchedStatements=true (默认false)reWriteBatchedInserts=true (默认false
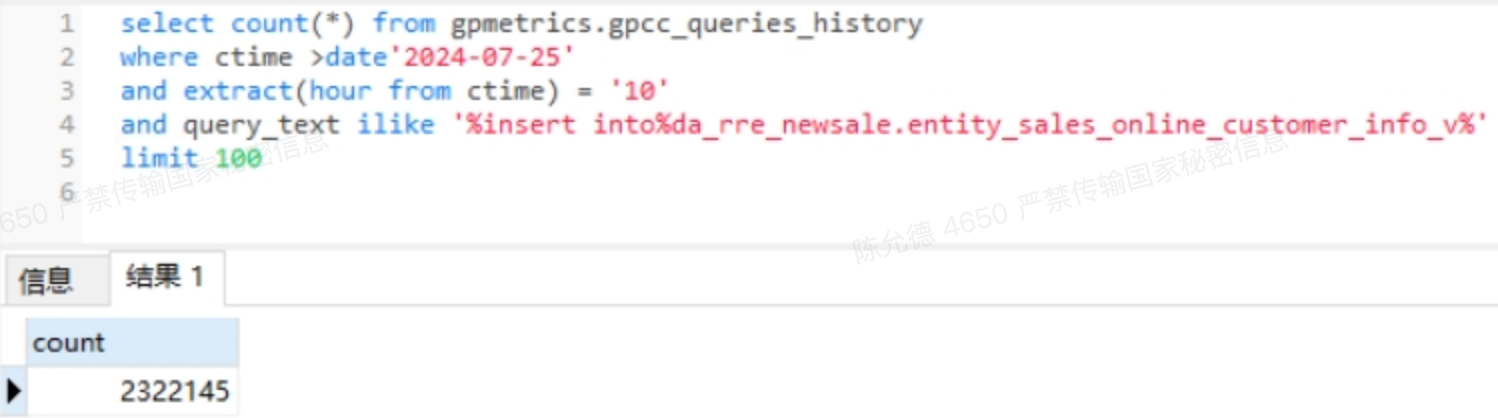
修改后下游数据库压力会大大减小、同步速度会更快。
2、MySQL Source中如果有tinyint(1)类型字段,在SeaTunnel中ResultSet.getObject()中会默认转换成java.lang.Boolean类型(当存储长度大于1时会有问题),需要把该值设置为false转为java.lang.Integer:
-tinyInt1isBit=false (默认true)
接下来,我们将分享一些基于Apache SeaTunnel的数据集成平台的额外配置优化,这些优化能够大幅度提高Source端和Sink端的吞吐量和速度,有效缓解数据库的压力。
优化Fetch Size
在进行数据同步时,我们注意到Greenplum(GP)的审计日志中,Fetch Size的默认值较小,这导致同一任务频繁查询源库。
每127条数据会生成一条SQL执行语句,这样会在一秒内生成成千上万的日志记录。
为了解决这一问题,我们将Fetch Size的值优化到1万,结果明显减少了日志生成量,同时Task Manager的内存使用量也有所增加。
注意:虽然增加Fetch Size可以提高抽取速度,但在生产环境中不宜设置得过大。过大的Fetch Size会导致内存占用过高,可能引发Out of Memory(OOM)错误。因此,合理配置Fetch Size是确保稳定性的关键。
OLAP数据库的优化配置
对于OLAP数据库(如果下游是OLAP数据库,如Starrocks、Doris等),我们可以通过设置一个较大的攒批参数来缓解反压的情况从而加快Streamload速度。
- batch_max_bytes = 943718400
- batch_max_rows = 5000000
- batch_interval_ms = 60000
我们也进行了相应的配置优化,以加速数据同步任务并减少内部审计报错的频率。我们主要使用时间值来控制输出的频率:
- 如果任务在半小时内能够完成同步,建议设置较小的频率。
- 如果任务需要超过半小时,我们可以将频率设置为一分钟以上,从而显著提高同步效率。
解决多并行度字段切分问题
在使用Flink引擎的int类型切片时,我们发现使用数值切分的并不是很均匀,同步速度在多并行度下速率并不理想。

在我们在使用Apache SeaTunnel的2.3.1版本时,发现只支持数值类型,而在2.3.4版本后才开始支持更多数据类型,包括字符串和时间类型。
源码里面有两种切分Chunk的方法,一种是动态切分,另一种时Fixed固定切分。

我们配置的时候有设置query sql,如果设置了partition_column会进入fixedChunkSplitter分支,会按照String类型或数值类型进行不同的逻辑切分。
配置建议
数值类型切片方法和字符串类型切片方法比较不一样的地方是——数值类型内ofBatchNum(partition_num)会影响BatchSize,这个值影响Chunk块切分的大小,会影响到Snapshot阶段抽数效率。

多并行度配置建议:
- env execution.parallelism = x(必须)。
- source 配置partition_column,选择非空字符串类型优先,选择字符串类型时可配置partition_num设置大小等于并行度;如果要选择数值类型,不用配置partition_num,使用默认的split.size 8096即可。
- sink 配置多并行度时假设每个并行度的攒批数据一样,均为1分钟的数据,则内存会增加较多,建议taskmanager内存增加: n x 0.7 x parallelism(n为原来大小,parallelism为并行度,生产看实际情况配置)。

2. 资源优化实践
在运行大量离线任务时,我们观察到内存使用模型的低效。如果仅进行数据抽取和输出,托管内存的40%未被使用,TaskManager的内存利用率并不高。
以下是我们提出的优化方案:
减少托管内存的使用:对于仅执行数据传输和抽取的任务,建议将托管内存设置为最小值,尽量节省不必要的内存占用。
动态调整内存:可以根据数据量、Sink端并行度、Source端
Fetch_size大小动态分配任务TaskManager内存。

注意:在Flink引擎的批模式下,Source阶段结束后才会进入Sink阶段,因此只需关注一个阶段的最大内存,并预留20%-30%的缓冲作为Task Manager的内存。
自定义Save_Mode
在SeaTunnel 2.3.1版本还没有SaveMode,我们有着较多自动建表,PreSQL,PostSQL类的需求
解决方案:
- 是通过JAVA程序去获取Source端
DatabaseMetaData拿到COLUMN_NAME、TYPE_NAME、COLUMN_SIZE、DECIMAL_DIGITS,根据配置规则在首次运行SeaTunnel任务前下游自动创建表。 - PreSQL和PostSQL通过封装好的Python脚本,传入jobid,在任务执行前运行PreSQL,成功后开始同步任务,RestAPI获取到SeaTunnel任务状态成功后执行PostSQL。
- 2.3.4版本后支持
SchemaSaveMode和DataSaveMode,我们后续可以功能合并,也是建议社区的小伙伴们如果是刚使用SeaTunnel或者准备上SeaTunnel的可以优先尝试2.3.4以上的版本。
离线全增量切换问题
数据同步过程中,全量同步无法满足所有业务需求,因此需要首次同步全量数据,后续进行增量同步。
我们在极限情况下发现,增量运行时可能出现漏数和幂等数据重复的问题,这给数据的准确性带来了挑战。
解决方案:
- 全量同步完记录max(timestamp),增量query sql中增加where表达式,where 大于max(timestamp),需要保证配置的时间字段是系统生成的且有序、正确;如果需要按照自增id进行增量配置同理。
- 离线增量阶段JDBC需开启参数:support_upsert_by_query_primary_key_exitst = true 自定义primary_keys = xxx,按照业务逻辑设计。
- 下游如果是JDBC、OLAP主键模型,可以将Timestamp前移几秒预留buffer,保证数据精确一致。
- 增量任务下游建议不要使用Doris、StarRocks的模型明细表(不支持upsert),会造成数据重复。
通过以上优化,我们显著提升了数据同步的效率,降低了数据库的压力,为后续的业务发展打下了坚实的基础。
最看重什么功能?
通过一段时间的实践,我们发现Apache SeaTunnel的以下功能对我们的日常数据集成任务尤为重要:
丰富的Connector支持
华润置地内部存在多样化的系统架构,涉及众多异构数据源,例如传统数据库、消息队列、对象存储等。
SeaTunnel为我们提供了丰富的Connector支持,能够无缝连接各种数据源。相比起其他工具,SeaTunnel不仅支持更多的数据源类型,还能够在实际应用中保持稳定的连接与高效的数据同步,这让我们的多源数据集成需求得到了极大满足。
性能与扩展性
在早期,我们尝试了DataX,但发现其开源版本仅支持单机模式,在处理大规模数据集成时性能显得不足。而Apache SeaTunnel的架构设计使其具备良好的扩展性,能够支持分布式数据集成。这使得我们可以轻松应对大数据量、高并发的同步需求,且性能表现明显优于单机模式的工具。
多引擎支持
SeaTunnel对多引擎的支持是其最独特的优势之一。华润置地的数据处理工作流广泛应用Flink作为引擎,而SeaTunnel能够灵活支持多个引擎运行,确保在不同的业务场景下,我们可以根据需求选择合适的引擎,提升了系统的适应性与灵活性。
全流程完备的数据处理
SeaTunnel不仅在数据源(Source)和数据目标(Sink)支持上非常完善,其Transform模块也非常强大。通过Transform,我们能够在数据传输的过程中,灵活地进行数据清洗、类型转换以及简单的业务逻辑处理。这种“无代码”的简易操作,减少了我们在数据清洗过程中编写额外代码的时间,也提高了开发效率。
怎么解决遇到的问题?
我们在使用Apache SeaTunnel过程中,偶尔也会遇到一些问题。
以下是我们通常获取帮助和学习的主要途径:
社区支持
SeaTunnel的开源社区非常活跃。当我们遇到较为常见的问题时,首先会在社区中提问。社区成员的响应非常迅速,开发者们热心且经验丰富,能够提供很有帮助的解答。
GitHub Issues
对于比较复杂的技术问题,我们会直接在GitHub上提交Issue。SeaTunnel的开发团队非常高效,通常能够及时回复并跟踪问题。通过这种直接的反馈机制,我们得以快速解决问题,并且有机会为项目贡献自己的改进建议。
官方文档与技术博客
SeaTunnel的官方文档非常详实,为我们在系统搭建与Connector开发过程中提供了非常有价值的指导。同时,我们也会关注公众号查阅相关的技术博客,学习其他开发者的实践经验。
🎯 结语
感谢Apache SeaTunnel社区提供的支持和帮助,我们期待未来能继续深入探索这个强大的平台,推动更多的数据集成项目落地。
同时,也希望通过我们的实践经验,能够为更多开发者提供有价值的参考。
本文由 白鲸开源科技 提供发布支持!