我们很多人都知道,分配比我们所需更多的内存可能会对应用程序的性能产生负面影响。因此,使用带有容量的构造函数创建列表可能会产生很大的不同。
但是,使用Maps时,这个优化步骤可能不是那么简单。在本文中,我们将学习如何识别HashMap 中过度分配和分配不足的问题 ,更重要的是,如何解决它。
例子
让我们考虑这个代码片段,其中我们创建一个HashMap并用几个条目填充它:
public static void main(String[] args) {
for (int i = 0; i < 1_000_000_000; i++) {
final HashMap<String, Integer> workDays = new HashMap<>();
workDays.put(new String("Monday"), 1);
workDays.put(new String("Tuesday"), 2);
workDays.put(new String("Wednesday"), 3);
workDays.put(new String("Thursday"), 4);
workDays.put(new String("Friday"), 5);
MAP_ACCUMULATOR.add(workDays);
}
}
这里的问题是HashMap的默认初始容量为 16,而对于上面的情况,我们可以毫无问题地使用 8。幸运的是,如果我们使用HeapHero分析堆转储,这个问题就会变得非常明显:
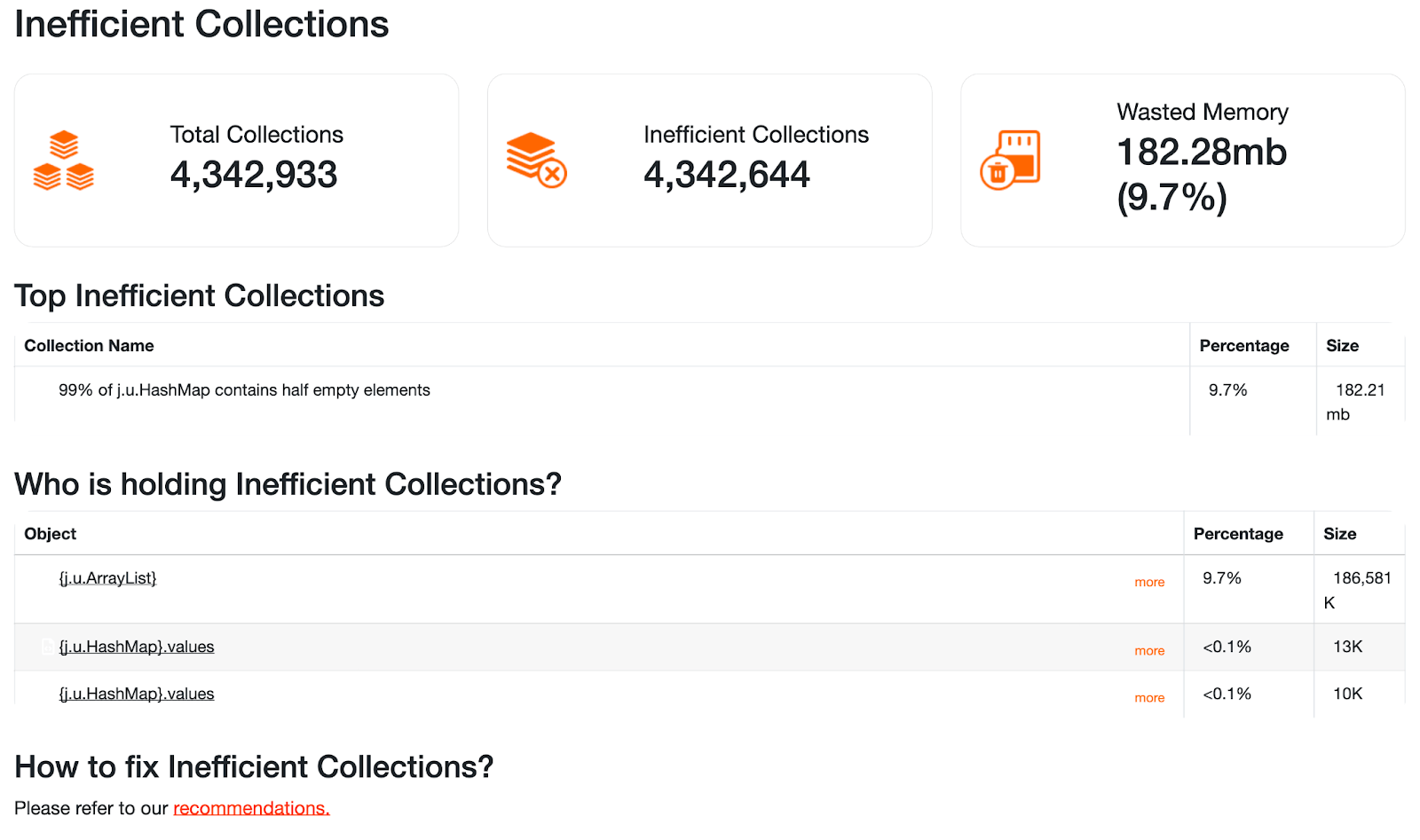
图 1:使用 HeapHero 分析低效集合
低效集合部分显示占用空间过多的集合。在这里,我们可以看到我们的HashMap包含的元素比集合可以容纳的少得多。
但是,让我们考虑一个更微妙的例子:
public static void main(String[] args) {
for (int i = 0; i < 1_000_000_000; i++) {
final HashMap<String, Integer> planets = new HashMap<>(8);
planets.put(new String("Mercury"), 4879);
planets.put(new String("Venus"), 12104);
planets.put(new String("Earth"), 12742);
planets.put(new String("Mars"), 6779);
planets.put(new String("Jupiter"), 139820);
planets.put(new String("Saturn"), 116460);
planets.put(new String("Uranus"), 50724);
planets.put(new String("Neptune"), 49244);
MAP_ACCUMULATOR.add(planets);
}
}
我们有八颗行星和一张容量设置为八的地图。你们中的一些人已经注意到了这个问题。但是,让我们分析一下这个小应用程序的堆转储。让我们也使用 HeapHero 分析器来分析:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
图 2:在某些情况下,HeapHero 不会直接检测到问题
低效的信息收集并没有显示出任何问题。 我们必须经过几个步骤和计算才能确定问题所在。为此,我们需要比较我们的地图占用的保留堆和保留节点的内部数组占用的保留堆。差异在于显示我们有多少个空元素的开销:
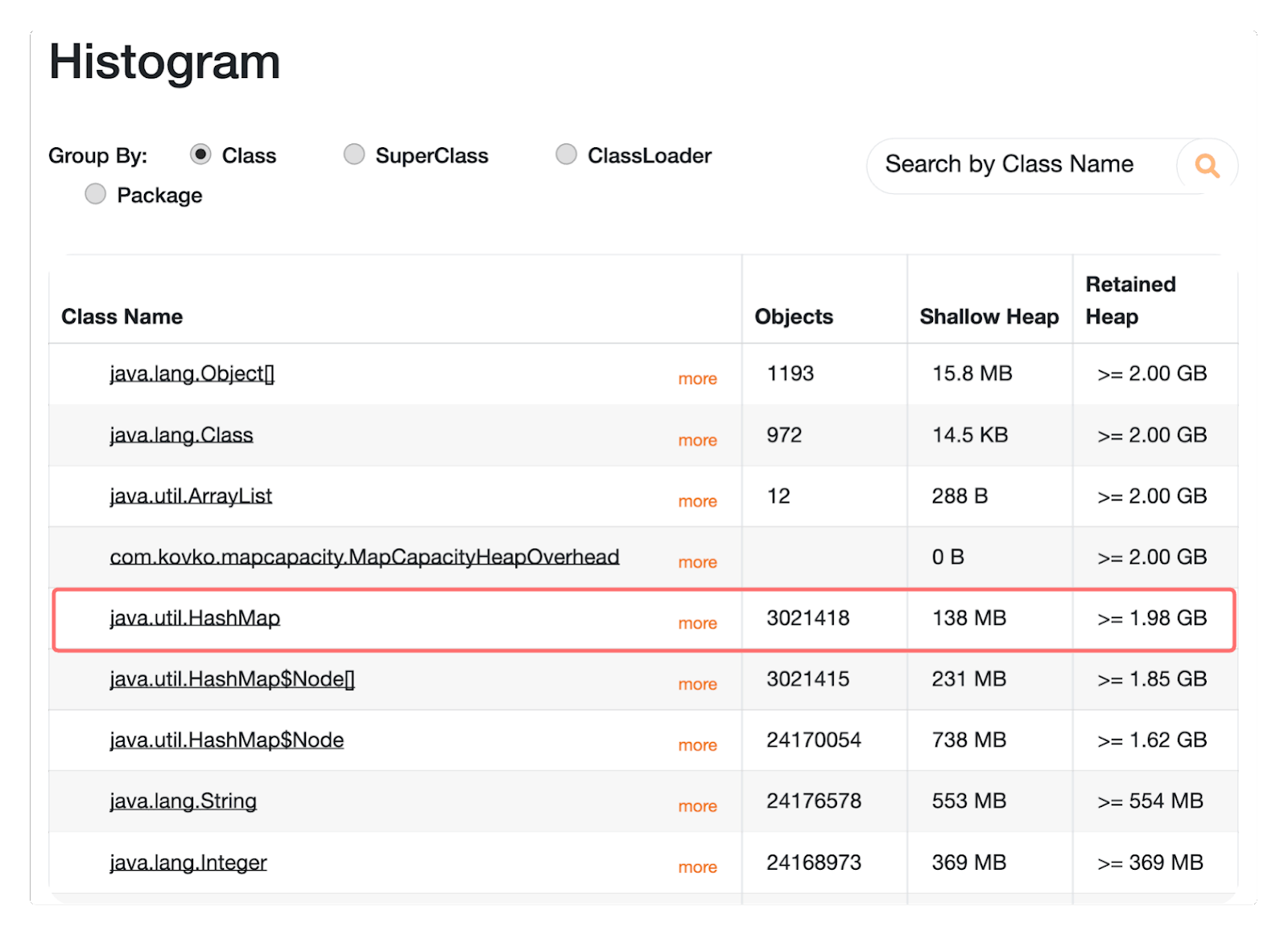
图 3:对象直方图
我们可以看到,HashMaps的整体保留堆几乎为 2GB。但是,节点的总保留堆只有 1.62 GB。**我们有近 400MB 的开销或 5% 的未使用空间。 **
根据堆转储,我们可以看到Map的实际大小高于我们预期的,并且浪费了一些空间。
然而,对于这个问题我们无能为力。map 的容量应该始终是 2 的幂。 此外,我们还应该考虑负载因子:本文将进一步解释。这就是为什么即使创建具有正确容量的 Map ,我们的空间开销也是一样的。
同时,在创建分配不足的地图时,我们还遇到了另一个问题。让我们使用JMH分析代码。我们将进行简单的测试,这些测试将在循环中创建地图:
@Measurement(iterations = 1, time = 2, timeUnit = TimeUnit.MINUTES)
@Warmup(iterations = 1, time = 10)
@Fork(1)
public class MapCapacityOverhead {
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void mapWithUnderestimatedCapacity(Blackhole blackhole) {
final HashMap<String, Integer> map = new HashMap<>(8);
map.put(new String("Mercury"),4879);
map.put(new String("Venus"),12104);
map.put(new String("Earth"),12742);
map.put(new String("Mars"),6779);
map.put(new String("Jupiter"),139820);
map.put(new String("Saturn"),116460);
map.put(new String("Uranus"),50724);
map.put(new String("Neptune"),49244);
blackhole.consume(map);
}
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void mapWithCorrectCapacity(Blackhole blackhole) {
final HashMap<String, Integer> map = HashMap.newHashMap(8);
map.put(new String("Mercury"),4879);
map.put(new String("Venus"),12104);
map.put(new String("Earth"),12742);
map.put(new String("Mars"),6779);
map.put(new String("Jupiter"),139820);
map.put(new String("Saturn"),116460);
map.put(new String("Uranus"),50724);
map.put(new String("Neptune"),49244);
blackhole.consume(map);
}
}
从结果中我们可以看出,它们的吞吐量差别很大:
| 基准 | 模式计数 | 分数 | 错误 | 单位 |
|---|---|---|---|---|
| 具有正确容量的地图 | 节肢动物 | 7256575.859 | 操作/秒 | |
| 容量低估的地图 | 节肢动物 | 5581449.247 | 操作/秒 |
使用低估的初始容量会导致代码比我们在初始化Map时分配正确数量的存储桶时慢 25% 左右。
容量与映射
要理解的主要内容是List和Map 的容量之间的区别 。 列表的容量很简单:我们计划存储在列表中的元素数量*。 *
然而,在 HashMap 中, 我们需要考虑另一个重要参数:负载因子。 默认情况下, HashMap使用设置为 0.75 的负载因子,这意味着Map**永远不会达到其满容量,并且当其达到 75% 满容量时将增加其大小。 **
我们在前面的例子中看到了这一点,问题是我们应该分配多少容量来存储特定数量的元素。正确执行此操作将节省我们的空间和时间 - 因为我们不会浪费处理能力来重新散列映射中的条目。
计算容量
现在,当我们知道容量不等于映射数时,我们假设它始终是正确的。 但是,从技术上讲,我们可以将负载因子设置为 100%,这会产生另一个问题:哈希冲突。
有多种方法可以计算给定映射数量的正确容量。让我们回顾一下其中的一些。
1.佐藤直人的配方
这个公式相对容易使用和理解:
int capacity = (int) (number of mappings/load factor) + 1;
但是,它可能会为某些值分配比所需更多的内存。如果我们的负载因子为 0.75,那么此方法将为可被三整除的映射数分配额外的空间:
int capacity = (int) ( 6 / 0.75) + 1 = 9;
从技术上讲,最终的容量是正确的,但八个存储桶足以容纳六个元素,无需调整大小。 如果我们使用此公式创建需要容纳六个元素的 Map ,最终将预分配十六个元素。请记住, HashMap中的内部表的大小应始终为 2 的幂。
2. Google Guava 的公式
此公式与上一个公式类似,但整个计算使用浮点数:
int capacity = (int) ((float) numMappings / 0.75f + 1.0f);
但是,如果前一个公式存在高估容量的问题,那么这个公式则存在相反的问题。由于浮点 运算和舍入, HashMap 的容量可能会更小,从而迫使重新哈希。
3.十进制算术
这两个公式不存在舍入和不完美浮点计算的问题。第一个公式直接使用整数**:
int capacity = (numMappings * 4 + 2) / 3;
第二个公式使用 long :
int capacity = (int) ((numMappings * 4L + 2L) / 3L);
不幸的是,两者都存在整数溢出问题,这可能导致负数或远离最佳值的数字。
4. 上限公式
计算容量的另一个简单公式是使用 Math.ceil(float) :
int capacity = (int) Math.ceil(numMappings / 0.75f);
由于精度操作,结果可能会导致对特定大数的低估。
5. Java 19 API
Java 19 引入了一个新的静态工厂, HashMap.newHashMap(int) 获取映射数并透明地计算容量。 这种新方法是一种直接创建具有所需容量的HashMap 的方法,不会高估或低估。
桶数
虽然我们可以在创建 HashMap 时传递所需的容量 , 但这并不意味着该映射将包含指定数量的 bucket。出于性能原因,bucket 的数量是最接近的 2 的幂的较大或相等的值。
例如,如果我们将容量设为 8:
final int initialCapacity = 8;
final HashMap<String, String> map = new HashMap<>(initialCapacity);
map.put("Hello", "World");
final int actualCapacity = getCapacity(map);
System.out.println("The initial capacity is %d and the actual one is %d"
.formatted(initialCapacity, actualCapacity));
实际容量为 8:
The initial capacity is 8, and the actual one is 8
同时,如果我们再多要求一点的话:
final int initialCapacity = 9;
final HashMap<String, String> map = new HashMap<>(initialCapacity);
map.put("Hello", "World");
final int actualCapacity = getCapacity(map);
System.out.println("The initial capacity is %d, and the actual one is %d"
.formatted(initialCapacity, actualCapacity));
容量将是最接近的 2 的幂的较大数字,即十六:
The initial capacity is 9, and the actual one is 16
请注意,方法getCapacity是一个使用反射获取容量的自定义方法。
结论
为了分配正确数量的 bucket,最好且最易读的方法是使用 Java 19 API 创建 HashMap 。 但是,有时由于限制或历史原因,无法升级 Java 版本。
下一个最佳解决方案是使用 Naoto 公式,这是上面介绍的唯一无错误的方法。 它不是完美的最佳方法,但它不会强制重新散列。另一个好处是它很容易记住和理解。
总体而言,每个应用程序都有其特定的问题和可能的优化。 解决这些问题的最佳方法是使用诊断工具(例如yCrash)来检查其内存使用情况和低效集合,无论是在专用部分还是通过分析保留堆 。




![[系列]相关的知识点关联](https://i-blog.csdnimg.cn/direct/584d440a856248c990c9815e75cc98fd.png)