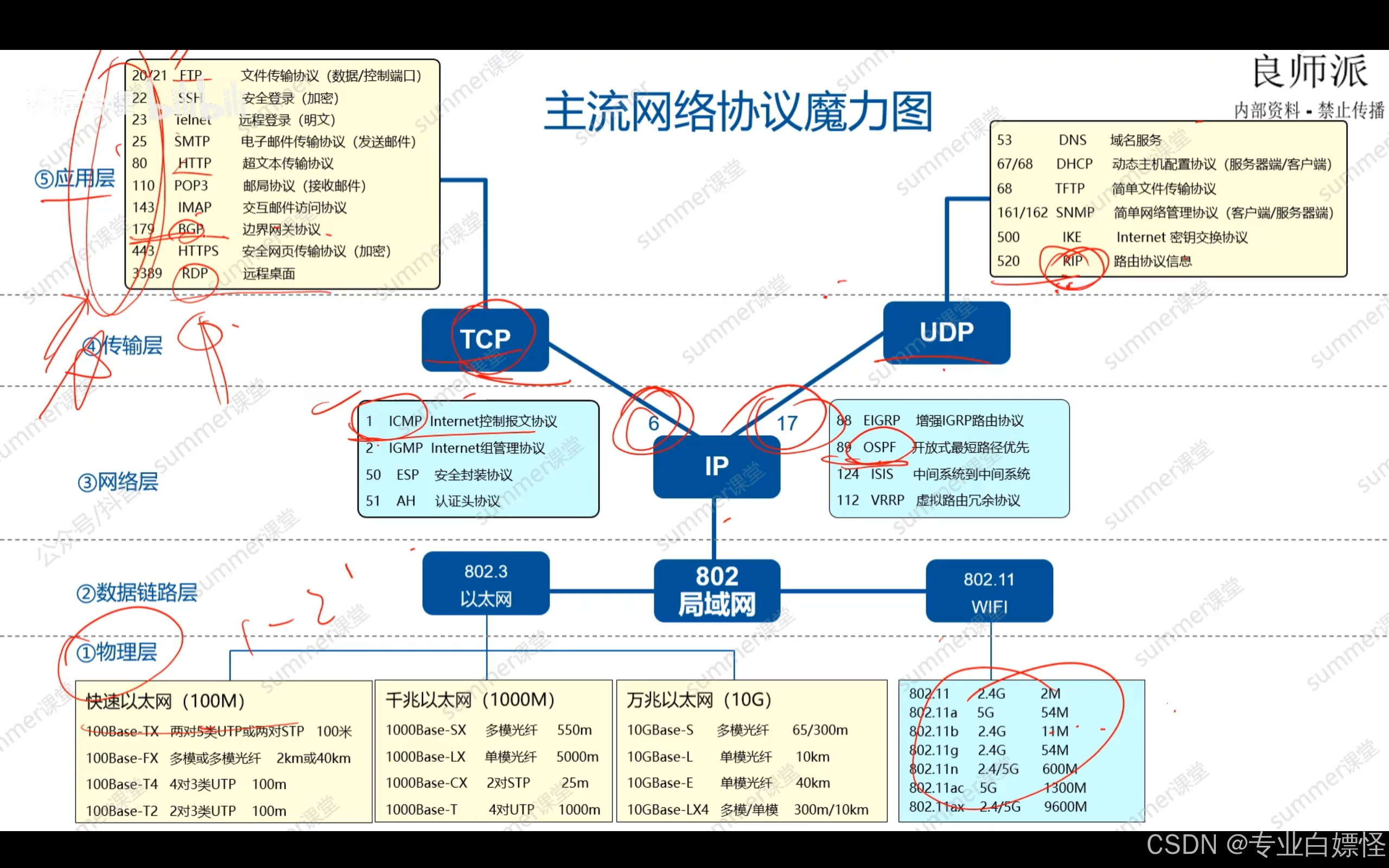
前言
从图的角度出发,树是一种特殊的图。图的大多数算法,树都可以适用。对树操作中,你可以发现有关图算法思想的体现。
不过, 本篇不是完全从图的角度解读树, 重点在初学者视角(一般学习数据结构顺序是从树开始的, 包括笔者也是如此, 但是笔者后续学习离散数学和图的算法回顾树的, 别用一番理解)。这里会沿用图的有关术语,不过不必担心晦涩难懂, 仅从字面意思就能理解, 笔者也会稍加批注。
编程语言: Java, 虽然早些时候想过用多语言实现, 但没有必要, 因为可以借助ChatGpt来转化成自己熟悉的语言。
- 树的铺垫-自由树-有根树-有序树-二叉树的引入
- 实现二叉树的基本操作和一些基本题型。-更多丰富视角,我会后续另出一篇来拓展
- 二叉搜索树的引入。
- 什么是二叉搜索树?
- 二叉搜索树提供的基本操作
- 解决二叉搜索树的有关题。
树的概念
用图定义:树是没有简单回路的连通无向图。
自由树是一个连通的, 无环的, 无向图。一般省略自由二字, 简称树。
由于自由树是特殊的图, 是图的子集。那么图的算法使用条件满足自由树的性质, 那么也可以在树中玩图的各种算法。
推论:由于树没有回路-那么它必定不存在多重边和环。

如图, 上面就不是树, 因为树是不能形成回路, 那么子路径不会相交。
启示: 如果树不连通呢?那么它就是一个
森林。森林是多棵树。
如图:
如上所说的树称作自由树。
自由树的性质:

- 连通,无环,无向。连通意味着从某个节点到另一个节点有路径, 无环不能闭合, 无向就是字面意思。
- 边 E E E与顶点 V V V之间的数量关系: ∣ E ∣ = ∣ V ∣ − 1 |E| = |V| - 1 ∣E∣=∣V∣−1。
有根树
首先有根树是自由树,有根树是自由树的子集。
这意味着有根树同样满足自由树上述的性质。
定义: 自由树选择一个点作为根节点, 并且每条边方向都是离开根节点的方向所形成的树是有根树。
如图:

下面我们来描述有根树的术语。
如图:1所在结点是整个有根树的根节点。
假设
v
v
v是
T
T
T中的非根顶点, 则
v
v
v的父母是从
u
u
u到
v
v
v的有向边的起点
u
u
u, 如图中,2的父母就是根节点1, 这是因为
1
−
>
2
1->2
1−>2。定义了父母, 那么相对的我们可以定义孩子,我们称
v
v
v是
u
u
u的孩子。如1的孩子之一是2,可以发现孩子可以有多个,但父母只能有一个。借此,我们定义兄弟的概念,1的孩子一共有三个2,5,7。那么2,5,7有相同的父母,那么它们之间互为各自的兄弟。
现在,我们来定义祖先的概念, 非根节点的祖先:从根节点出发到该顶点所有的路径相关的节点,认为除该节点外的所有结点都是其祖先。如图中结点9,其祖先是1,5,8。可以发现父母也是它的祖先之一。
树叶:没有孩子的节点就是树叶,即叶节点。 图中的3,4,6,7,9,10,12,13均是叶节点。
内点:有孩子的节点就是内点,也称为内节点。 图中的1,2,5,11,8均是内点(分支节点)
有序树和二叉树
m叉树定义:若有根树的内点均不超过m个孩子, 则称它为m叉树, 若该树T的每个内点都有m个孩子, 则其称为满m叉树。
二叉树:m叉树中的m取2, 就是二叉树。
有序树:将有根树的每个内点进行排序, 这意味孩子要分顺序, 一般认为确定有根树的边顺序。
有序二叉树:若树的内点中有2个孩子,分别为左孩子和右孩子。现在可以尝试递归地定义树了, 以某个顶点的左孩子为根节点的树局部来说是顶点的左子树, 同样我们定义了右子树。
树的相关数据结构
- 二叉树,多叉树。
- 二叉堆,优先级队列, 多叉堆。
- 搜索树,平衡搜索树。(B树,2-3-4树,2-3树,AVL树,红黑树,树堆)
- 并查集(不相交集)
- 跳表(它也是一种平衡搜索树)
- 线段树,区间树,树状数组。
- 前缀树(字典树)。
- 动态规划版本的树—>树形DP
- 最小生成树算法(Kruskal 和 Prim)
二叉树的基本问题
枯燥的概念终于说明完了, 这些都是树中的专业术语。
现在我们可以表示一个二叉树了
下面介绍一种简单表示二叉树的方式:
孩子表示法: 二叉树的单个节点有三个属性: 值val, 左孩子的地址, 右孩子的地址。
public class BinaryTree<T extends Comparable<T>> {
public static class TreeNode<T>{
T val;
TreeNode<T> left;
TreeNode<T> right;
public TreeNode(T val) {
this.val = val;
}
}
private TreeNode<Integer> root; //这里指定整数类型。
}
基本问题
/**
* 创建一棵二叉树 返回这棵树的根节点
*
* @return
*/
public TreeNode<Integer> createTree() {
return null;
}
// 前序遍历
public void preOrder(TreeNode<Integer> root) {
}
// 中序遍历
void inOrder(TreeNode<Integer> root) {
}
// 后序遍历
void postOrder(TreeNode<Integer> root) {
}
public static int nodeSize;
/**
* 获取树中节点的个数:遍历思路
*/
void size(TreeNode<Integer> root) {
}
/**
* 获取节点的个数:子问题的思路
*
* @param root
* @return
*/
int size2(TreeNode<Integer> root) {
return -1;
}
/*
获取叶子节点的个数:遍历思路
*/
public static int leafSize = 0;
void getLeafNodeCount1(TreeNode<Integer> root) {
}
/*
获取叶子节点的个数:子问题
*/
int getLeafNodeCount2(TreeNode<Integer> root) {
return -1;
}
/*
获取第K层节点的个数
*/
int getKLevelNodeCount(TreeNode<Integer> root, int k) {
return -1;
}
/*
获取二叉树的高度
时间复杂度:O(N)
*/
int getHeight(TreeNode<Integer> root) {
return -1;
}
// 检测值为value的元素是否存在
TreeNode<Integer> find(TreeNode<Integer> root, Integer val) {
return null;
}
//层序遍历
void levelOrder(TreeNode<Integer> root) {
}
// 判断一棵树是不是完全二叉树
boolean isCompleteTree(TreeNode<Integer> root) {
return true;
}
Pro set1:
后续的习题均是递归思想解决子问题和非递归用栈模拟的思想体现。
8
/ \
3 10
/ \ \
1 6 14
/ \ \
4 7 13
public TreeNode<Integer> createTree(): 构建一个上图的二叉树
/**
* 创建一棵二叉树 返回这棵树的根节点
*
* @return
*/
public TreeNode<Integer> createTree() {
TreeNode<Integer> root = new TreeNode<Integer>(8);
TreeNode<Integer> node1 = new TreeNode<>(3);
TreeNode<Integer> node2 = new TreeNode<>(10);
root.left = node1;
root.right = node2;
//左子树
TreeNode<Integer> node3 = new TreeNode<>(1);
TreeNode<Integer> node4 = new TreeNode<>(6);
node1.left = node3;
node1.right = node4;
TreeNode<Integer> node5 = new TreeNode<>(4);
TreeNode<Integer> node6 = new TreeNode<>(7);
node4.left = node5;
node4.right = node6;
//右子树
TreeNode<Integer> node7 = new TreeNode<>(14);
node2.right = node7;
TreeNode<Integer> node8 = new TreeNode<>(13);
node7.right = node8;
return root;
}
//在写个构造方法
public BinaryTree() {
root = createTree();
}
好了,相信你已经画图把这个树手动构建好了。
Pro set2:
二叉树的遍历
看了视频你应该懂了前序中序后序遍历的思路了。
下面是递归实现代码, 但不是重点,因为很简单。现在介绍用栈模拟递归的思路来加深理解。
// 前序遍历
public void preOrder(TreeNode<Integer> root) {
if(root!=null){
System.out.println(root.val);
preOrder(root.left);
preOrder(root.right);
}
}
// 中序遍历
void inOrder(TreeNode<Integer> root) {
if(root!=null){
inOrder(root.left);
System.out.println(root.val);
inOrder(root.right);
}
}
// 后序遍历
void postOrder(TreeNode<Integer> root) {
if(root!=null){
postOrder(root.left);
postOrder(root.right);
System.out.println(root.val);
}
}
前序遍历的非递归实现
/**
* 先序遍历:根>>左>>右
* ///前序遍历非递归
*/
public void preOrderUnRec(TreeNode<Integer> root){
//用栈模拟递归。
if(root!=null){
//初始状态
Stack<TreeNode<Integer>> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
//从栈中弹出一个元素---由于根节点,先打印处理。
TreeNode<Integer> node = stack.pop();
System.out.println(node.val);
//先压右,再压左-因为栈后进先出,下次循环会处理左子树。
if(node.right!=null){
stack.push(node.right);
}
if(node.left!=null){
stack.push(node.left);
}
//循环往复
}
}
}
前序遍历的非递归,先压右树再压左树, 所有处理顺序是根-左-右,那么我们依次处理打印,就是前序的结果。
后序遍历非递归
假设我们先压左树,再压右树, 那么顺序打印是根-右-左,但我们此时不处理,把收集的节点全部压栈, 然后依次出栈就颠倒了顺序,依次打印,结果是左-右-根。这就是双栈实现后序遍历。
第一个栈, 用来遍历。先左后右。
第二个栈, 用来收集第一个栈处理弹出的节点。挨个出栈打印。
不废话了,请看代码
public void postOrderUnRec(TreeNode<Integer> root){
if(root!=null){
//初始状态
Stack<TreeNode<Integer>> stack1 = new Stack<>();
Stack<TreeNode<Integer>> stack2 = new Stack<>();
stack1.push(root);
while(!stack1.isEmpty()){
//stack2收集stack1弹出的节点
TreeNode<Integer> node = stack1.pop();
stack2.push(node);
//先压左,再压右。--(如果有)
if(node.left!=null) {
stack1.push(node.left);
}
if(node.right!=null){
stack1.push(node.right);
}
//stack1不为空就重复该过程。
}
//输出stack2打印即可。
while(!stack2.isEmpty()){
System.out.println(stack2.pop().val);
}
}
}
单栈实现:感兴趣自己研究一下吧,思考一下为什么如此设计?
/**
* 单栈实现
* 更加省空间!!!
* 先尽可能往左走,再全力往右走.这就是后序遍历递归序.
* 为什么要设置lastVisited这个变量呢?为什么处理根节点之后,弹栈要标记这个节点呢?
* @param head
*/
public static void postOrderUnRecSingleStack(TreeNode<Integer> head) {
if (head == null) {
return;
}
Stack<Node> stack = new Stack<>();
TreeNode<Integer> cur = head;
TreeNode<Integer> lastVisited = null;
//想象递归的走向,然后循环分支写/
while (!stack.isEmpty() || cur != null) {
if (cur != null) {
//无脑往左走.
stack.push(cur);
cur = cur.left;
} else {
//左边走空了,开始回退上一个根节点往右边走.
TreeNode<Integer> peekNode = stack.peek();
// 若右子节点存在且没有访问过,则先遍历右子节点
if (peekNode.right != null && lastVisited != peekNode.right) {
cur = peekNode.right;
} else {
// 右子节点不存在或已访问,处理(打印)当前子树根节点.
System.out.println(peekNode.value + " ");
lastVisited = stack.pop();
}
}
}
}
中序遍历非递归
/**
* 中序非递归遍历
* 左<根<右
* @param root
*/
public void inOrderUnRec(TreeNode<Integer> root) {
//用栈模拟递归。
if (root != null) {
//初始状态
Stack<TreeNode<Integer>> stack = new Stack<>();
TreeNode<Integer> cur = root;
while (cur!=null || !stack.isEmpty()) {
//先从左走到死
if(cur!=null){
stack.push(cur);
cur = cur.left;
}
else{ // cur==null
//回到上一级子树的根节点
cur = stack.pop();
System.out.println(cur.val);
// 转向右子树
cur = cur.right;
}
//如此处理,相当于只有左和根, 右被分解成了左和根
}
}
}
pro set3
获取树中节点个数
以下使用了静态变量, 你可以设计一个主方法,每次调用该方法时都会重置nodeSize。
// 在每次开始计算之前,将 nodeSize 重置为 0,确保每次调用都不会累加之前的结果。\
public static int nodeSize; /// 静态变量
/**
* 获取树中节点的个数:遍历思路
*/
void calculateSize(TreeNode<Integer> root) {
//用栈模拟递归。
if(root!=null){
//初始状态
Stack<TreeNode<Integer>> stack = new Stack<>();
stack.push(root);
//总之遍历完节点计数就完事了。
while(!stack.isEmpty()){
TreeNode<Integer> node = stack.pop();
nodeSize++;
if(node.right!=null){
stack.push(node.right);
}
if(node.left!=null){
stack.push(node.left);
}
}
}
}
不使用静态变量的方法。
/**
* 获取节点的个数:子问题的思路
*
* @param root
* @return
*/
int calculateSize2(TreeNode<Integer> root) {
return root == null ? 0 : calculateSize2(root.left) + calculateSize2(root.right) + 1;
}
int calculateSize2UnRec(TreeNode<Integer> root) {
if (root == null) {
return 0;
}
int nodeSize = 0;
Stack<TreeNode<Integer>> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode<Integer> node = stack.pop();
nodeSize++; // 每次访问一个节点时,增加计数
// 先压右子节点,再压左子节点,这样出栈时先处理左子节点
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
return nodeSize;
}
Pro set4
计数叶子节点的个数
//静态变量--每次计数使用要重置
public static int leafSize = 0;
/**
* 获取叶子节点的个数:遍历思路
*/
void getLeafNodeCount1(TreeNode<Integer> root) {
/
if(root==null){
return ;
}
//叶子节点判定
if(root.left==null&&root.right==null){
leafSize++;
}
getLeafNodeCount1(root.left);
getLeafNodeCount1(root.right);
}
Pro Set5
层数定义:
- 根节点所在的层数:一般地,根节点被认为是
第 1 层,在某些教材书上根节点被视为在第 0 层。这取决于具体的定义和题目的要求。大多数情况下,根节点被称为第 1 层。 - 子节点所在的层数:对于任何节点,它的左子节点和右子节点所在的层数是它所在层数的下一个层数。例如,如果某个节点在第 k 层,那么它的子节点就在第 k+1 层。
上面两条性质, 我们定义任意层数的大小。
/**
* 获取第K层节点的个数
* 求原来整棵树的第k层节点数 = 左子树的第k-1层节点数 + 右子树的第k-1层节点数
*/
int getKLevelNodeCount(TreeNode<Integer> root, int k) {
// 如果树为空,返回0,表示没有节点
if (root == null) {
return 0;
}
// 如果k==0,表示当前节点就是第K层的节点,返回1
if (k == 0) {
return 1;
} else {
// 递归地计算左右子树第K-1层的节点数之和
return getKLevelNodeCount(root.left, k - 1) + getKLevelNodeCount(root.right, k - 1);
}
}
Pro Set6
·定义·
一般情况下,二叉树的高度定义是以根节点为 1(或者以叶子节点为 0)来计数。这个定义方式与大多数算法和数据结构教科书中使用的方式一致。
- 高度以叶子节点为
0计数:- 叶子节点的高度为
0。 - 非叶子节点的高度为其子树中最大高度加
1。
- 叶子节点的高度为
/**
* 获取二叉树的高度
* 时间复杂度:O(N)
*/
int getHeight(TreeNode<Integer> root) {
if (root == null) {
return 0;
}
int leftHeight = getHeight(root.left);
int rightHeight = getHeight(root.right);
return Math.max(leftHeight, rightHeight) + 1;
}
Pro Set7
检查值value是否在二叉树中存在
/**
* 检测值为 val 的元素是否存在
* 使用深度优先搜索遍历一遍即可。
*
* @param root 根节点
* @param val 要查找的值
* @return 找到的节点,如果不存在则返回 null
*/
TreeNode<Integer> find(TreeNode<Integer> root, Integer val) {
if(root!=null){
Stack<TreeNode<Integer>> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode<Integer> node = stack.pop();
if(node.val.equals(val)) {
return node;
}
if(node.right!=null){
stack.push(node.right);
}
if(node.left!=null){
stack.push(node.left);
}
}
}
return null;
}
Pro Set8
层序遍历-广度优先遍历
/**
* 层序遍历: 广度优先遍历
* @param root
*/
void levelOrder(TreeNode<Integer> root) {
if(root!=null){
Queue<TreeNode<Integer>> queue = new ArrayDeque<>(); //使用双端队列。
queue.offer(root);//根节点入队
while(!queue.isEmpty()){
TreeNode<Integer> node = queue.poll();
System.out.println(node.val);
if(node.left!=null) {
queue.offer(node.left);
}
if(node.right !=null){
queue.offer(node.right);
}
}
}
}
Pro Set9
完全二叉树的概念
完全二叉树(Complete Binary Tree)是二叉树的一种特殊形式,具有以下定义特征:
-
所有层都被完全填满,除了可能的最后一层,最后一层的节点应当尽可能地
向左排列。- 换句话说,除非最后一层,所有层的节点数都是最大可能的。如果最后一层节点缺失,它们应该出现在树的最左侧,而不是右侧。
-
树的深度(高度):
- 完全二叉树的每一层(从根节点开始的层)都应当填满,只有最后一层可以不完全填满,但是节点必须靠左。
-
在堆中, 用数组表示完全二叉树 若你看过我先前的二叉堆的文章那么你知道二叉堆其实也是完全二叉树。
- 对于任何一个节点,如果节点的索引是
i,则:- 节点的左子节点索引是
2*i + 1。 - 节点的右子节点索引是
2*i + 2。 - 节点的父节点索引是
(i - 1) / 2(若执行浮点数除法,应该向下取整)。
- 节点的左子节点索引是
- 对于任何一个节点,如果节点的索引是
-
节点的填充顺序:
- 节点的填充从左到右进行,确保所有节点都尽可能靠左填充。
假设我们有如下树:
1
/ \
2 3
/ \
4 5
/
6
这个树不是完全二叉树,因为:
第三层并没有填满就开始填第四层。
完全二叉树:
前k层必须填满,第k+1层尽可能靠左。
1
/ \
2 3
/ \ / \
4 5 6 7
/ \ \
8 9 10
如何证明其不是完全二叉树
- 不可能存在左孩子不存在, 右孩子存在的情形。
比如删除上图中的6节点, 并删掉最后一层。
1
/ \
2 3
/ \ / \
4 5 7
由于3节点没有左孩子,但是有右孩子,说明下一层有节点但是有漏洞。因此, 不是完全二叉树。
2. 下面讨论左孩子存在, 但右孩子却不存在的情况。
一旦遇上这种情况, 应该判定后续节点是否都为叶子节点!
1
/ \
2 3
/ \ / \
4 5 6 7
/ /
8 10
//这就不是完全二叉树, 因为4没有右孩子, 但5是非叶子节点, 注定下面一层不是连续紧凑的, 不符合完全二叉树的定义。
// 让4后面的节点全是叶子节点就是完全二叉树了。
1
/ \
2 3
/ \ / \
4 5 6 7
/
8
/**
* 检查二叉树是否为完全二叉树
* 简单思路:广度优先遍历(BFS)
* 先观察:完全二叉树不存在左孩子不存在但右孩子存在的情况.
* 再次观察发现:宽度遍历若第一次遇见非二度节点,那么后序节点为叶子节点.
* 反证法可以证明
*/
boolean isCompleteTree(TreeNode<Integer> root) {
if (root == null) {
return true;
}
Queue<TreeNode<Integer>> queue = new LinkedList<>();
queue.offer(root);
boolean leaf = false;
while (!queue.isEmpty()) {
TreeNode<Integer> node = queue.poll();
TreeNode<Integer> left = node.left;
TreeNode<Integer> right = node.right;
if (leaf) {
// 如果已经遇到叶子节点,之后的节点必须都是叶子节点
if (left != null || right != null) {
return false;
}
} else {
if (left == null && right != null) {
// 如果左子节点为空但右子节点不为空,则不是完全二叉树
return false;
}
if (left != null && right == null) {
// 如果左子节点存在而右子节点为空,则标记为叶子节点
leaf = true;
}
// 入队左右子节点
if (left != null) {
queue.offer(left);
}
if (right != null) {
queue.offer(right);
}
}
}
return true;
}
基本问题2—二叉树1,完全二叉树, 满二叉树的性质补充。
定义满二叉树:满二叉树(Full Binary Tree):每个节点或者有2个子节点(左子节点和右子节点),或者没有子节点(叶子节点)。它的每一层的节点都达到了最大数量。
1
/ \
2 3
/ \ / \
4 5 6 7
二叉树的性质之一:假设根节点高度为1. 那么第k层至多可以有
2
k
−
1
2^{k-1}
2k−1 。
我们可以列出节点数序列{1,2,4,8,16, …
2
k
−
1
2^{k-1}
2k−1}, 都是2的幂。
满二叉树每层都装满了,所以每层都有
2
k
−
1
2^{k-1}
2k−1 节点数。
总节点数:
∑
i
=
1
h
2
i
−
1
=
2
h
−
1
\sum_{i=1}^h 2^{i-1} = 2^h - 1
∑i=1h2i−1=2h−1
前面基本问题一处讨论了完全二叉树, 现在补充一下:假设完全二叉树共有k层, 那么完全二叉树可以视为k-1层的满二叉树 + 最后一层的有序树。
比如:下图中前三层可视为满二叉树 + 最后一层
1
/ \
2 3
/ \ / \
4 5 6 7
/ \ /
8 9 10
那么完全二叉树的节点范围 2 h − 1 < N ( n o d e s ) < = 2 h − 1 2^{h-1} < N(nodes) <= 2^h - 1 2h−1<N(nodes)<=2h−1, 注意左边不能取等, 否则最后一层是不存在的,那它就是k-1层的满二叉树, 右边可以取等, 这说明了满二叉树是特殊的完全二叉树。
二叉搜索树
二叉搜索树是一种动态数据结构, 支持查询, 插入, 删除, 获取最大值, 获取最小值的操作。
二叉树的基本操作取决于其高度, 可以认为二叉树的插入查询删除行为
时间复杂度:
O
(
h
)
,
h
为搜索树的高度。
时间复杂度:O(h),h为搜索树的高度。
时间复杂度:O(h),h为搜索树的高度。
二叉搜索树是以一棵二叉树组织的。
不过还需满足以下性质:
设
x
x
x是二叉搜索树中的一个节点。 如果
y
y
y是
x
x
x的左子树中的任意一个节点, 那么都满足
y
.
k
e
y
≤
x
.
k
e
y
y.key \leq x.key
y.key≤x.key, 若
y
y
y是
x
x
x右子树的一个节点, 那么
y
.
k
e
y
≥
x
.
k
e
y
y.key \geq x.key
y.key≥x.key
为了避免重复元素, 通常不能让它们取等。
由于二叉树可以由递归定义, 那么二叉搜索树的根节点左右子树都是二叉搜索树。
图1

由上图: 一般的二叉搜索树不保证树的疏密, 这里树的疏密本质是树的平衡。有关树的平衡我们会在平衡二叉树处说明。
二叉树的表示
二叉搜索树的元素是一个个节点, 节点可以视为一个对象, 每个节点包含属性
k
e
y
key
key,
l
e
f
t
left
left,
r
i
g
h
t
right
right, 还可以包含父节点
p
p
p。
//创建一个BinarySearchTree类
private Node root;
//Node类是其的一个静态内部类。
public static class Node{
int val;
Node left;
Node right;
Node p;
public Node(int val){
this.val = val;
}
}
public BinarySearchTree() {
root = null;
}
搜索树基本问题1-对性质的理解
Pro set1
验证二叉搜索树
题目要求很简单, 就是让我们验证给定二叉树的头节点,验证其是否为二叉搜索树。
本题须知:1. 严格二叉树的根本性质左<根<右 2. 整体来看二叉搜索树满足性质1, 局部来看二叉搜索树同样满足,看问题角度多样。
class Solution {
///选择long类型,因为int有特殊样例过不了
public boolean isValidBST(TreeNode root) {
//先搞特殊的,空树或者平凡图情况直接返回true.
if(root==null||(root.left==null&&root.right==null)){
return true;
}
//主方法封装一个单元素数组充当指针。-设定系统最小值。
///prevValue记录左子树的上一个节点的值
long[] prevValue = {Long.MIN_VALUE};
return checkBST(root,prevValue);//初次调用
}
private boolean checkBST(TreeNode root,long[] prevValue){
//子树为空树,即空节点的情况。
if(root==null){
return true;
}
//探测左子树
boolean isLeftBST = checkBST(root.left,prevValue);
if(!isLeftBST){
///左子树不是搜索树
return false;
}
///此时的prevValue[0]记录当前根节点的左子树值
if(root.val<=prevValue[0]){
///这里取等要求严格的二叉搜索树
return false;
}else{
//更新prevValue[0] 为根节点的值
prevValue[0] = root.val;
}
return checkBST(root.right,prevValue);
}
}
search操作
观察图1:
从根节点开始遍历, 如果给定值val大于当前值,则前往右子树,反之小于前往左子树,递归执行,直到找到符合的节点或者找不到为null.
注:这里设计的二叉搜索树不包含重复元素, 所以不取等号。
/**
*
* @param cur 指定节点
* @param val 查找值
* @return 返回值所在节点的地址。
*/
public static Node search(Node cur, int val) {
if (cur == null || cur.val == val) {
return cur;
}
if (cur.val < val) {
// 前往右子树,递归调用
return search(cur.right, val);
} else {
// cur.val > val : 前往左子树, 递归调用。
return search(cur.left, val);
}
}
迭代实现
public Node search(int val) {
Node cur = root;
while(cur != null){
if(cur.val < val){
cur = cur.right;
}
else if(cur.val > val){
cur = cur.left;
}
else{
// cur.val == val;
return cur;
}
}
//cur == null;
return cur;
}
二叉搜索树的中序遍历有序性
二叉搜索树的根,左子树,右子树满足
左
<
根
<
右
左<根<右
左<根<右。
中序遍历的也满足顺序
左
<
根
<
右
左<根<右
左<根<右。
因此:
二叉搜索树按照中序遍历打结果必定是有序的。
最大关键字和最小关键字元素
由中序有序性的性质:
"最小值"是最左边, "最大值"是最右边。
二叉搜索树的最小值:沿着left指针一直走,最边界的节点
二叉搜索树的最大值:沿着rightt指针一直走,最边界的节点
public static Node maximum(Node head) {
Node p = null;
Node cur = head;
while (cur != null) {
p = cur;
cur = cur.right;
}
return p;
}
public static Node minimum(Node head) {
Node p = null;
Node cur = head;
while (cur != null) {
p = cur;
cur = cur.left;
}
return p;
}
首先,两个操作时间复杂度均为
O
(
h
)
O(h)
O(h), 直观来看,那么一直往左或往右最坏情况就是走完树的整个高度。
获取前驱节点和后继节点。
前驱节点(predecessor)是指小于当前节点的最大节点。
已知一个节点x,由于二叉搜索树的性质:
- 先从左子树出发:因为必定满足左<根<右的性质。那么左子树的某一个节点就是它的前驱节点, 哪一个节点?
就是该左子树的最大节点。-----若左子树存在那么其局部最大值就是前驱节点。 - 第一种情况不满足, 讨论该节点作为其前驱节点的子树情况,第一条的前驱节点是在节点x的左子树上。第一种情况, 若该节点x是其前驱节点的右子树呢?那么x的前驱节点就是x.p。第二种情况, 若该节点x是其前驱节点的左子树呢, 我们还是由二叉搜索树的性质,一个节点右子树的任意节点均大于它。只需要往上找父亲节点(祖先),若某个祖先节点正好是某个节点z右子树,那么z必定小于x和祖先节点那条路径的所有节点,而x正好是该子树的最小节点(因为它没有左子树,没有更小的了)。
- 第三情况, 无前驱节点。全局来看,整棵树的最小值无前驱节点。
public static Node predecessor(Node head) {
if (head != null) {
if (head.left != null) {
// 如果有左子树,前驱节点是左子树中的最大节点
return maximum(head.left);
} else {
// 如果没有左子树,向上查找前驱节点
Node cur = head.p; // 追溯父节点
while (cur != null && head == cur.left) {
head = cur;
cur = cur.p; // 继续向上查找祖先节点
}
return cur; // 最终返回前驱节点
}
}
return null; // 如果head为空,返回null
}
后继节点的定义和代码实现和前驱节点是对称的。
后继节点是大于当前节点的最小节点。
由于和前驱节点是对称的, 那么不废话了。
- 如果当前节点有右子树,则后继节点是右子树中的最小节点
- 如果当前节点没有右子树,则需要向上追溯,找到一个节点,它是其父节点的左子节点,该父节点就是后继节点。
- 如不存在后继节点, 那么它必定整棵树的最大节点, 即调用前面
maximum(root)方法所得到的节点。
public static Node successor(Node head) {
if (head != null) {
// 如果节点的右子树非空,那么右子树的最小节点就是它的后继
if (head.right != null) {
return minimum(head.right);
} else {
// head.right == null
// 那么head节点的后继节点是某个最近底层祖先节点的右子树
Node cur = head.p; // 追溯父节点
while (cur != null && head == cur.right) {
head = cur;
cur = cur.p; // 继续向上寻找祖先节点
}
return cur; // 找到后继节点后返回
}
}
return null; // 如果head为空,返回null
}
predecessor和successor的时间复杂度均为
O
(
h
)
O(h)
O(h)
推论(显然的结论):如果一棵二叉搜索树中的一个节点有两个孩子, 那么后继无左孩子,前驱无右孩子。
不妨自行画图一下, 事实上是因为该节点左右孩子存在, 那么前驱节点和后继节点均满足前面情况1的情形, 结合反证法很容易得出。在此不多赘述。
我们讨论的这4个函数将会在后续的平衡搜索树学习中发挥出意想不到的作用。
现在,你可以尝试调用这些方法来模拟比如中序遍历。
结论:若二叉搜索树的高度: 二叉搜索树的前面五种操作时间复杂度均是
O
(
h
)
O(h)
O(h)
插入和删除
插入和删除操作允许二叉搜索树动态的变化, 我们需要注意的是,一个二叉搜索树增加或者删除一个节点后必须还是二叉搜索树。
我们采取事后调整来维护这些性质。
插入删除操作会频繁出现在后续的二叉平衡搜索树中, 不过那时候会忽略此部分,这里重点学习。
插入
插入没有任何调整的必要,因为我们总是从外层节点选择合适的位置, 采用了两个指针p,cur。
熟悉链表操作的你,阅读下面的代码一定不会有难度。
/**
* insert 操作与search操作类似,都需要大致相同的循环流程
* cur , p:遍历指针。 p始终是cur的父亲。
* 时间复杂度:O(h).
*
* @param val 值
*/
public void insert(int val) {
//保持p始终执行cur的双亲。
Node p = null;
Node cur = root;
while (cur != null) {
if (cur.val < val) {
p = cur;
cur = cur.right;
} else if (cur.val == val) {
return; //重复元素不允许插入。
} else {
p = cur;
cur = cur.left;
}
}
//p的位置就是新节点的父亲
Node node = new Node(val);
if (p == null) {
//未进循环---本身未空树。让头指针指向新节点。
root = node;
}
///确认新节点是左还是右孩子。
else if (p.val < val) {
p.right = node;
} else {
// p.val > val
p.left = node;
}
}
删除
关于删除操作我先介绍一个非常好用的函数接口, 过去我纠结于值替换法带来的糟糕体验(当然现在提供的上面4个函数接口可以很好的处理,减少代码冗杂在一起的糟糕可读体验), 不过很庆幸算法导论一书提供了父与子指针连接的接口。----这简直打通了我的任督二脉, 再也不用为“该死”的分类讨论,和一连串的指针懊恼了。
transplant
/**
* u是二叉搜索树或其子树的根节点
* v 是顶替u位置的节点
* 讨论了u是根节点的情形, v是null!即空树的场景。
*/
private void transplant(Node u, Node v){
if(u.p==null){
//u.p==null 意味这u是整棵二叉搜索树的根节点。
root = v;//修改根节点。
}
//u.p!=null 讨论u是其u.p的左孩子还是右孩子, 然后连接。
else if(u == u.p.left){
u.p.left = v;
}
else if(u == u.p.right){
u.p.right = v;
}
if(v!=null){
//单独处理v!=null
v.p = u.p;
}
///总之v相当与顶替u原先的地位,成为了u.p的孩子。
///但是仅处理了父子关系的连接, u还是连接着u.p,不过u.p已经不认u这个孩子了。
///其余指针的修改必须在函数外部处理了。
}
public void delete(int val) {
Node cur = root;
while (cur != null) {
if (cur.val < val) {
cur = cur.right;
} else if (cur.val > val) {
cur = cur.left;
} else {
// 找到要删除的节点
break;
}
}
if (cur == null) {
// 没有找到值为 val 的节点
return;
}
if (cur.left == null) {
transplant(cur, cur.right);
} else if (cur.right == null) {
transplant(cur, cur.left);
} else {
Node successor = minimum(cur.right);
if (successor.p != cur) {
transplant(successor, successor.right);
successor.right = cur.right;
cur.right.p = successor;
}
transplant(cur, successor);
successor.left = cur.left;
cur.left.p = successor;
}
}
尾声
时间匆忙,写下此篇已间隔太远了 不再修改了, 留待日后复习再做补充。