关联比赛: 第一届POLARDB数据库性能大赛
1 赛题分析
本次大赛的初赛和复赛的赛题内容是一脉相传的,主要内容都是实现一个KV数据库存储引擎,实现随机插入,随机查询,区间查询这三个功能。赛题的难点主要有两个:1、实现在kill -9时的数据可靠性;2、实现高效的区间查询算法。
程序运行的硬件环境是64个核的志强处理器,从型号核数推测应该为双CPU系统,磁盘为Intel的最新的傲腾SSD,推测型号为P4800X,但是在内存方面限制较为严格,仅允许使用约2G的大小。在开放语言上限定为Java和C++,虽然是开发IO密集型程序,但对内存和数据结构的高要求,C++还是相对占有优势的,从最后结果上也可以看出,C++的最好成绩比Java快了约10s。
相对于比较吃紧的IO和内存,CPU运算还是比较富裕的,如何设计合适的高并发算法,减少线程间冲突,将运算和IO实现尽可能的重叠是高分段的主要优化点。
2 算法及程序结构设计
2.1 缓冲设计
虽然傲腾磁盘拥有极其优秀的随机IO性能,但想要性能进入第一梯队,合适的读写缓冲是必不可少的。
传统的存储模块不需要考虑程序被杀的情况,使用一块内存作为环形缓冲队列是常用的一种方法,但在赛题需求中,需要随时对抗程序被kill-9,由于没有任何事先预警,可能存在在任何情况下程序被终止(虽然在测评中,这个行为比较温和,仅在所以请求返回后调用kill-9),只有至少写入page cache的内容才能被保存下来。
故对传统结构的缓冲结构进行改进,不难想到将传统的内存缓冲移到page cache上,具体实现如图1所示。
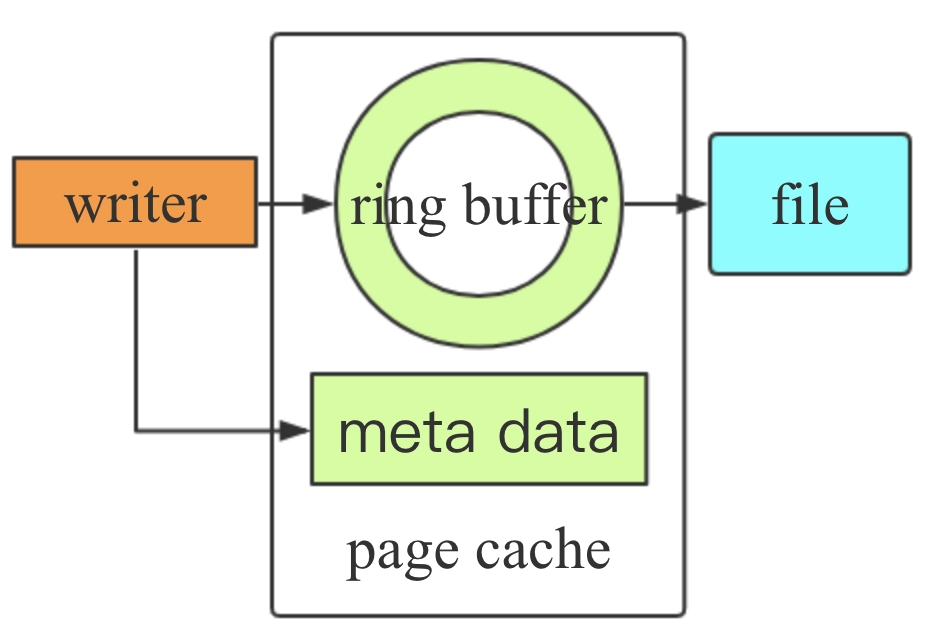
图1 基本缓冲结构
由于将缓冲及相应的offset等元数据写入到page cache上,即使kill -9发生,缓冲中的数据也不会丢失。通过合理设计key、value数据和offset等元数据的输入顺序,配合原子写入(lock前缀原子指令),可以应对任意时刻发生的kill -9,不会对数据的一致性造成破坏,对于未返回的请求,虽然是否被保存是不确定的,但整体数据存储结构不会出现冲突。
在具体实现方式上,使用mmap方式将page cache映射到程序内存空间中,提升操作效率,也为原子操作提供了可能。额外需要注意的是:1、这块page cache并不是kv存储文件,而是另一个定长的单独文件,用于做环形缓冲和元数据的实时存储,单独的文件也有利于整体映射及大小控制。2、page cache使用大小的细节,因为操作系统存在10%的脏写入阈值和20%的阻塞线程阈值,在cgroup限制下,该阈值的计算基数是当前所剩空闲内存的大小,这里需要精心规划内存使用,避免系统后台落盘线程的频繁刷盘。
2.2 存储结构设计
存储结构的设计对写入和读取的性能起至关重要的作用。从数据分布采样统计上来看,具体的正确性测试和性能测试的数据分布略有不同,正确性测试进行了大量重复key及大量hash冲突的key值插入,如果使用hash表方式实现,需要有很好的扩展性。性能测试的数据较为均匀,比较适合使用hash方式进行分片存储。
由于KV数据插入是随机的,第二阶段的测试也是随机读取,所以简单的hash分片存储是较为合适的数据存储方式。为了提升写入速率,采用每个分片内顺序写入的方式进行。考虑到后续区间读取,需要尽量将范围内的数据尽可能聚集,故可以使用key的升序前若干个bit作为key的hash(具体实现为bswap key的64bits然后无符号右移),这样不仅可以动态调整分片粒度,区间读取时也便于对整个分片进行缓存。
结合上一节的缓冲设计,不难得出整体的存储结构,如图2所示。
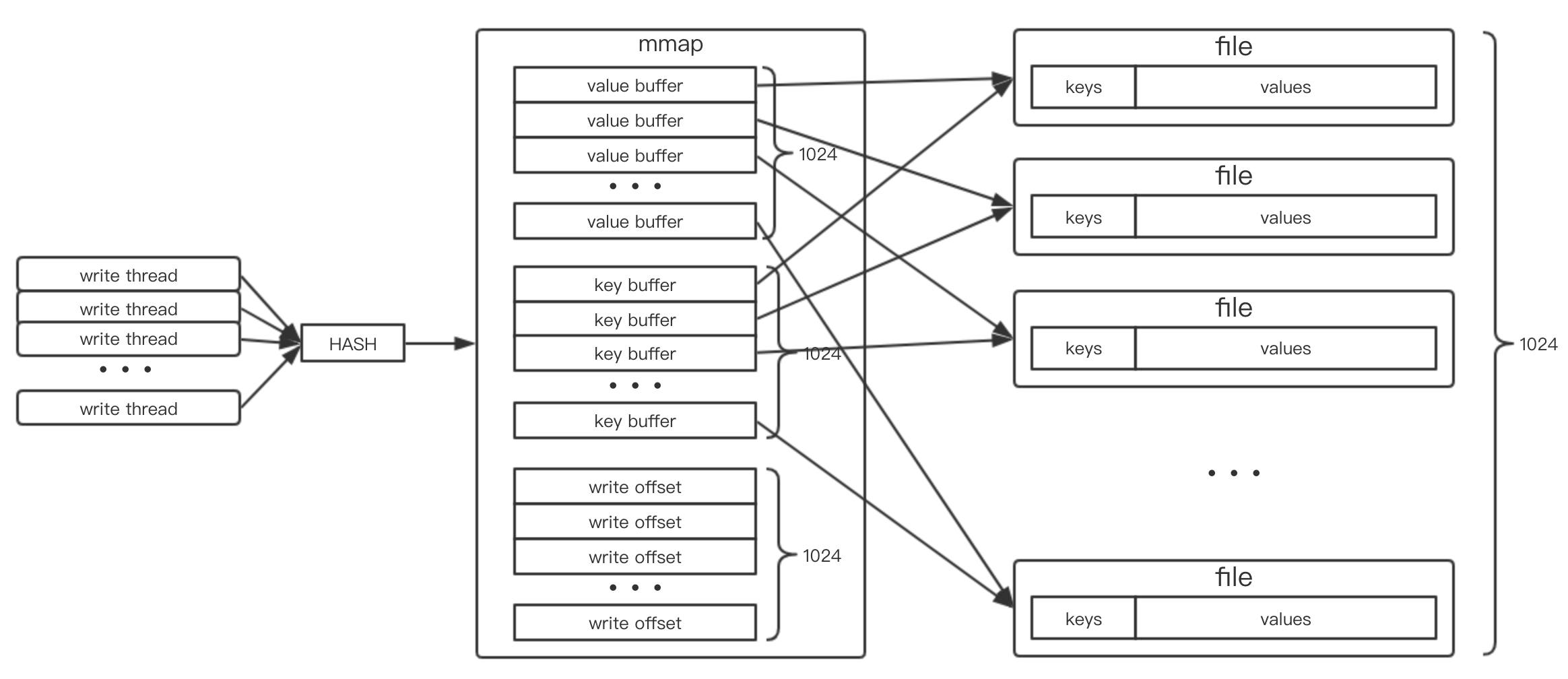
图2 数据存储及缓冲结构(1k分片)
由于数据的总量为6400w X 4KB约为245GB,虽然ext4文件系统支持大文件,但是小于1G的文件对于减小冲突和文件系统负载是比较合适的,故分片数选择256/512/1024/2048这几个2的幂次,对应key的前8-11个bit作为分片的序号。
2.3 随机写入实现
如图3所示为写入缓冲及刷盘控制。
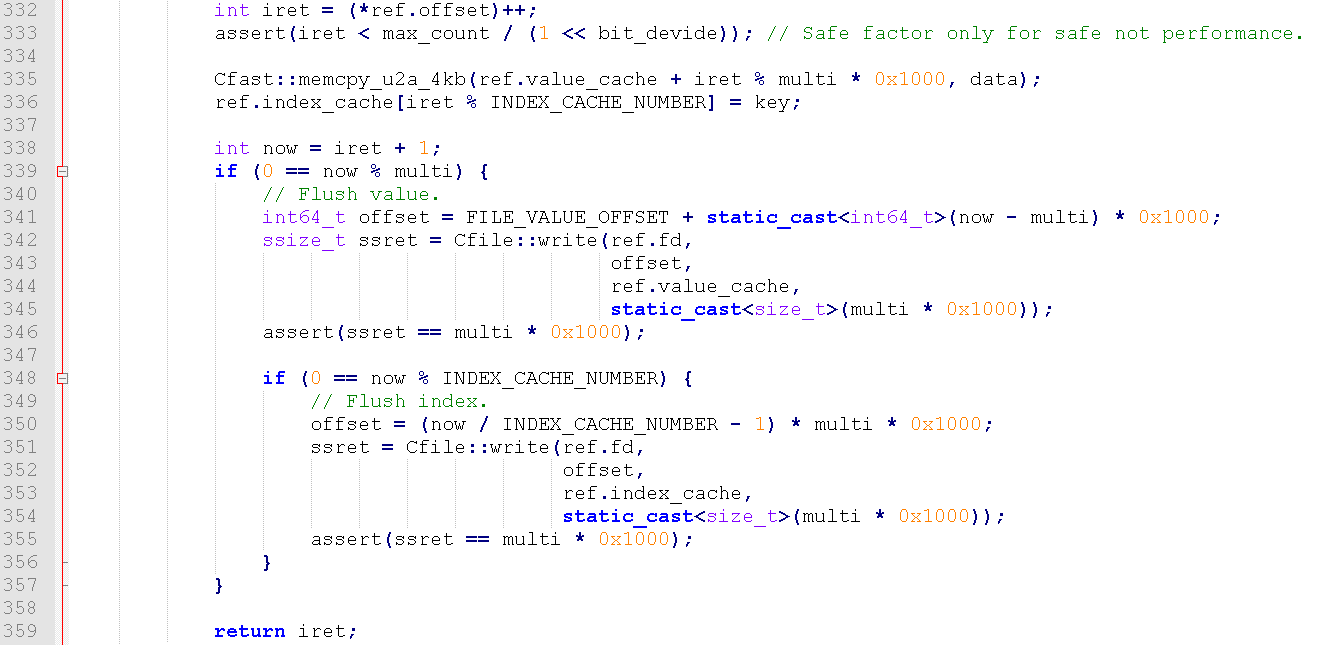
图3 写入部分代码
通过key的hash到具体分片上,针对该分片的key和value的缓冲进行分别填充,当缓冲满则刷入磁盘(这里应该将offset++放在最后,保证任意时刻的数据完整性)。每个分片通过轻量级的自旋锁进行保护,由于分片的数目远大于线程数,冲突的概率很低,且由于CPU性能的富裕,使用自旋+yield的方式就能以很低的系统切换数实现线程的同步。
由图2和3也可以发现,程序将key和value同时存储在一个文件中,由于锁的控制,KV的顺序完全一致,不需要存储额外的offset信息,仅需要顺序读取即可读入所有key建立索引,由于分片的原因,这个过程也可以并行进行。Key和value的存储区域为事先划分的,可以通过分为两个独立文件或设置合理的安全余量保证两者不会相交,同时,代码中也可以进行强制检查。
在文件写入时有很对小的细节技巧:1、O_DIRECT的合理使用,由于自己实现的存储管理系统比操作系统更了解我们数据的读写需求,自己控制缓存能减少系统层面的延迟和额外操作,最大化压榨IO性能。2、fallocate可以对文件完成预分配工作,使得后续数据写入能更加稳定。3、合理设计每个分片的预偏移,在很少空间浪费的情况下,能够将每个缓冲的爆发写入均匀化,平衡写入的冲突。
通过这些细节处理,写入性能能达到55.7w OPS左右,最高性能能达到56w OPS。
2.4 索引设计
对于数据读取,良好的索引设计对于高速随机和区间读取都有极大的帮助。对于随机查询,性能最高的便是hash table,由于数据分布较为均匀,使用key的升序前几个bit作为hash的冲突率较低。由于之前存储结构的设计也是遵循hash来分片的,可以使用多线程并发加载若干分片的key部分,并且由于文件内部有序,直接将key的大块读入内存,以更细粒度的hash slot加载到索引结构中。
索引中的内容是key和对于value在存储文件中的offset,在大于1024的分片中,offset小于256MB,由于value是定长4KB的,故offset可以压缩到2bytes,故一个索引单元为10bytes,整体索引大小为610MB,算上分配余量,能限制在700MB左右。
图4所示为索引存储结构。为了更好的完成随机查找,索引设计为64k个slot的hash table,每个slot中为自动伸缩的数组,参考deque的实现,通过尾链定长数组的增长方式,最大限度减少内存碎片,也提升了分配效率。数组内数据查找采用排序+二分查找实现。由于存储的分片粒度比索引大,在并行读取存储的key时,hash bucket间不会存在交叉,能够最大化并行效率,同时排序操作会紧接着读取操作完成后进行,充分利用cpu cache,也实现了IO和排序的重叠,整个key存储大小为8bytes*64*1000000=488.2MB,所有读取及排序操作时间在200ms左右。

图4 索引
2.5 随机读取实现
如上一节介绍的,索引在加载完成后即完成了排序操作,后续所有查找即为hash+二分查找,都是只读操作,所有不需要加锁即可完成。在具体读取时使用先hash到slot,再二分查找的方式进行,读取时为了避免多线程在读同一个文件时竞争的问题,用spinlock控制单文件读取,使得性能稳定在60.5W OPS左右,最高可以到60.57W。value读取代码如图5所示。由于采用了写入缓冲,数据会存在于page cache中和具体存储文件中,程序会根据写入offset判断去mmap还是去文件读取。
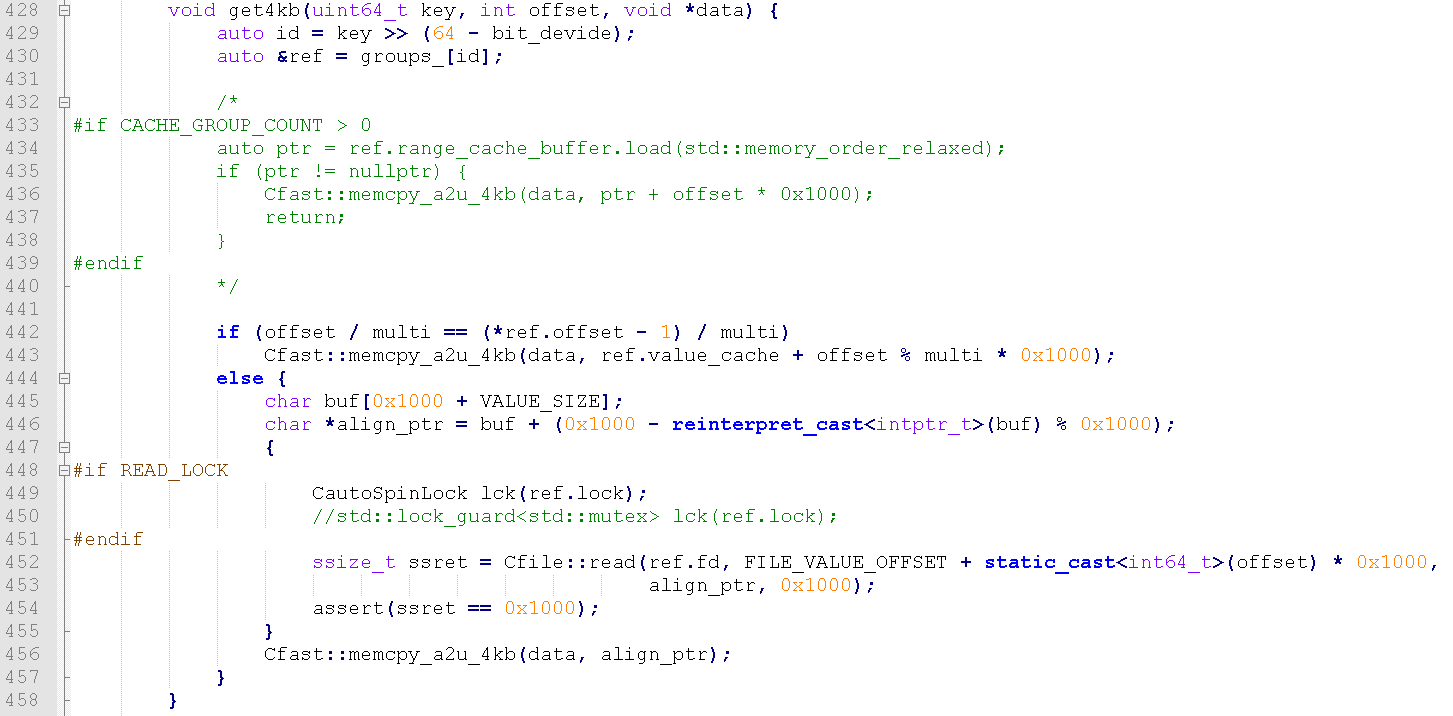
图5 读取实现代码
2.6 区间读取实现
作为复赛新增加的功能,区间读取下的IO性能压榨是个很富有挑战性的问题。性能测试阶段,64个线程分别进行2次全量的顺序读取。基础的思路是将这64个线程融合为2次全盘读取。由于全量顺序读也是创新运行实例,第一步同样是加载索引,将所有key和offset读入内存并排序。为了实现多个线程共享读取结果,以每个存储文件分片作为一个基础共享单元,以引用计数控制其生命周期,使用异步线程加载value数据,实现类似电梯算法的缓存算法。具体流程如图6所示。
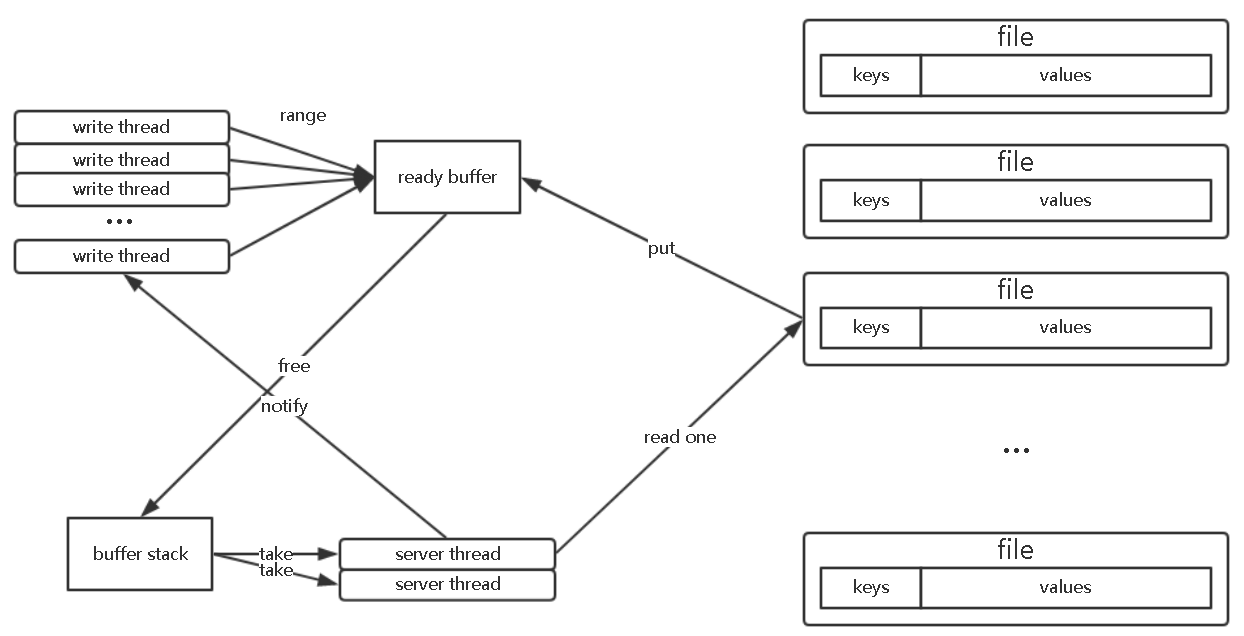
图6 区间读缓存结构

图7 缓存控制部分变量
因为分片算法将一个升序区间内的所有KV都放在一个存储文件中,同时hash table的分片也是有序和区间聚合的,所以一个hash table slot中的存储的所有KV都能在同一个存储文件中找到,且当遍历超出区间后,无论是存储文件还是hash table slot中的内容都不会再需要。因此遍历操作有很强的局部聚集性,不仅便于缓存的读取也更有利于CPU cache的命中。
为了提升遍历操作和IO的重叠率,提升速度,在进行遍历时,请求线程会在所有需要遍历的分片上加引用计数,而服务线程则根据这些标记,在有空余内存块时,完成下一个块的预读。而对于遍历线程和读取线程间内存块的交换则通过一个无锁的栈结构实现,使用栈结构而不是队列,因为刚用完的内存相对于之前用完的内存具有更好的CPU cache命中率。
2.7 一些细节的优化
由于本次比赛的数据量巨大,为了提升内存间数据拷贝的效率,可以使用SIMD指令进行数据拷贝加速,比如针对多种对齐和非对齐等内存拷贝可以使用AVX2指令集进行优化。具体实现可以使用asmjit或xbyak等动态汇编生成,当然使用gcc的immintrin.h头文件中的函数是一种更快捷的方式,但在调用前需要对CPU指令集支持情况进行判断。
另外从榜上可以看到414s和415s之间存在一个分界,很大一部分原因是在区间读取时的差距,根据时间统计结果不难发现,在预读线程读取和遍历线程调用遍历回调之间存在预读线程干等的情况,在我的实现中是由于遍历线程都等待一个condition_variable上,在唤醒时由于同一个mutex造成了线程竞争,总共1k次等待造成了约1s的延迟,导致预读线程等待遍历线程的情况。通过改进唤醒机制使64个遍历线程等待在不同condition_variable上,解决了这个问题,但多个condition_variable也是个不小的负担。最后通过使用标志位+spin+yield解决了该问题,合理设置自旋阈值不会对CPU造成太大负担,也能使预读线程不会出现等待交出执行时间片。这个优化能将速度优化到414.23s。
最后,两次range之间的预读也是一个优化点,即第一次遍历完成后立刻开始下一次预读,这也能提升约100ms,同时在内存中缓存上次range的部分块,也能提升些许的性能。
3 总结
这是我第三次参加天池程序设计类竞赛,虽然这次比赛的题目看似简单,没有过于复杂的业务逻辑,但往往越是简单基础的功能,越考验基本功。KV数据存储引擎看似简单一个map就能实现的功能,在遇上大规模数据情况下变得异常复杂。特别是这次比赛中用到了新的硬件设备——傲腾SSD,这块神奇的磁盘刷新我对存储设备的认识,也让我学习到了对新设备进行评估测试及在上面进行开发的完整过程。
由于这次比赛时间段比较特殊,复赛阶段没有太多的空余时间进行研究测试新的方案,有很多优化想法没有付诸实践,只能在初赛的测试结果和框架上修修改改,但这次比赛也让我学习到了很多知识,通过在竞赛交流群中的讨论,了解到了很多新思路新想法,是我受益匪浅。
查看更多内容,欢迎访问天池技术圈官方地址:第一届POLARDB数据库性能大赛-亚军0xCC☣☢比赛攻略_天池技术圈-阿里云天池