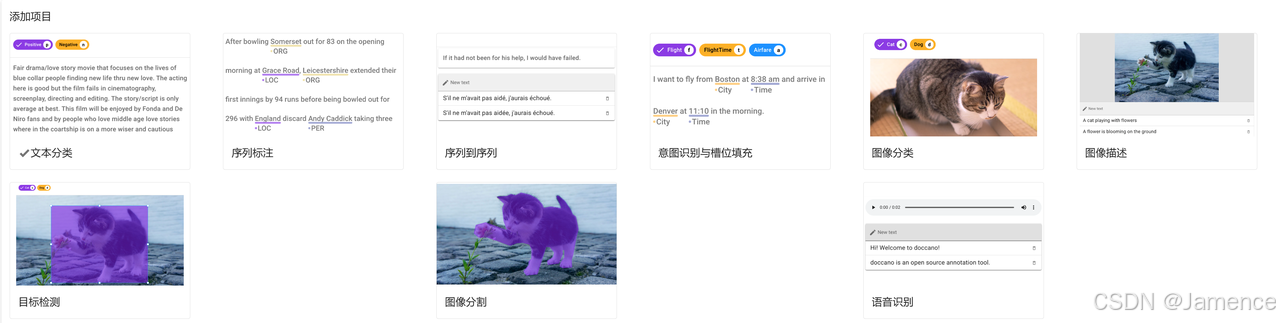
计算机前沿技术-人工智能算法-生成对抗网络-算法原理及应用实践
1. 什么是生成对抗网络?
生成对抗网络(Generative Adversarial Networks,简称GANs)是由Ian Goodfellow等人在2014年提出的一种深度学习模型,主要用于数据生成任务。在GAN出现之前,传统的生成模型(如变分自编码器VAE)虽然能够生成数据,但生成的样本往往质量不高,缺乏多样性。
GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是生成尽可能接近真实数据的假数据,而判别器的目标是尽可能准确地区分真实数据和生成器生成的假数据。两者之间形成了一种对抗关系,通过这种对抗训练,生成器逐渐学会生成高质量的数据。
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log 1 − D ( G ( z ) ) ] \min_{G}\max_{D} V(D, G)=E_{x \thicksim p_{data}(x)}[\log{D(x)}] + E_{z \thicksim p_{z}(z)}[\log{1-D(G(z))}] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log1−D(G(z))]
-
生成器:通常是一个深度神经网络,它接收一个随机噪声向量作为输入,通过一系列变换生成数据。生成器的目标是欺骗判别器,使其将生成的数据误判为真实数据。
-
判别器:也是一个深度神经网络,它的任务是区分输入数据是来自真实数据集还是生成器生成的。判别器通过输出一个概率值来表示输入数据为真实数据的可能性。
-
训练过程:训练GAN时,生成器和判别器会交替进行训练。首先固定生成器,训练判别器;然后固定判别器,训练生成器。这个过程可以看作是一场博弈,生成器试图生成越来越真实的数据,而判别器则不断提高其鉴别能力。

2. 如何实现和优化GAN?
在实际应用中,GAN的实现涉及到以下关键步骤:
- 网络架构设计:选择合适的网络结构作为生成器和判别器。常见的有卷积神经网络(CNN)等。
- 损失函数定义:定义合适的损失函数来训练生成器和判别器。常用的损失函数包括二元交叉熵损失。
- 优化算法选择:选择合适的优化算法,如Adam、RMSprop等,来更新网络参数。
- 超参数调整:调整学习率、批量大小、训练迭代次数等超参数,以获得最佳训练效果。
- 稳定性技巧:应用如梯度惩罚、标签平滑等技巧来提高训练的稳定性。
3如何在实际应用中使用GAN?
3.1 生成图像应用
这里,以一个简单的GAN来生成手写数字,TensorFlow代码如下:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
# 加载 MNIST 数据集
(train_images, train_labels), (_, _) = mnist.load_data()
# 归一化图像到 0-1 范围
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32')
train_images = (train_images - 127.5) / 127.5
# 创建生成器模型
def build_generator():
model = Sequential([
layers.Dense(7*7*256, use_bias=False, input_shape=(100,)),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Reshape((7, 7, 256)),
layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
])
return model
# 创建判别器模型
def build_discriminator():
model = Sequential([
layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=(28, 28, 1)),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(1)
])
return model
# 构建和编译模型
generator = build_generator()
discriminator = build_discriminator()
# 为生成器和判别器定义损失函数和优化器
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
generator_optimizer = Adam(1e-4)
discriminator_optimizer = Adam(1e-4)
# 训练步骤
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, 100])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = cross_entropy(tf.ones_like(fake_output), fake_output)
disc_loss = cross_entropy(tf.ones_like(real_output), real_output) + cross_entropy(tf.zeros_like(fake_output), fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# 设置训练参数
BATCH_SIZE = 64
EPOCHS = 50
# 训练模型
for epoch in range(EPOCHS):
for image_batch in train_images.reshape(60000, 28, 28, 1)[np.random.choice(60000, 60000 // BATCH_SIZE * BATCH_SIZE, replace=False)]:
train_step(image_batch)
# 可选:每个epoch后打印日志
if epoch % 10 == 0:
print(f'Epoch {epoch} completed')
# 保存生成器模型
generator.save('generator_model.h5')
对应的PyTorch代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 超参数设置
batch_size = 64
learning_rate = 0.0002
num_epochs = 50
latent_dim = 100
# MNIST 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 生成器定义
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, 28, 28)
return img
# 判别器定义
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 损失和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练过程
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(train_loader):
# 训练判别器
real = torch.ones(imgs.size(0), 1)
fake = torch.zeros(imgs.size(0), 1)
real_imgs = imgs
optimizer_D.zero_grad()
output_real = discriminator(real_imgs)
errD_real = criterion(output_real, real)
errD_real.backward()
noise = torch.randn(imgs.size(0), latent_dim)
fake_imgs = generator(noise)
output_fake = discriminator(fake_imgs.detach())
errD_fake = criterion(output_fake, fake)
errD_fake.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
output = discriminator(fake_imgs)
errG = criterion(output, real)
errG.backward()
optimizer_G.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss D: {errD_real.item()+errD_fake.item()}, Loss G: {errG.item()}')
# 显示生成的图像
with torch.no_grad():
fix_noise = torch.randn(25, latent_dim)
fake_images = generator(fix_noise)
fake_images = fake_images.view(25, 1, 28, 28)
plt.figure(figsize=(5, 5))
plt.axis("off")
plt.title("Generated Images")
plt.imshow(np.transpose(fake_images.cpu().numpy(), (1, 2, 0)))
plt.show()
3.2 图像分类应用
简要思路如下:
-
步骤1: 训练GAN
首先,我们需要训练一个GAN来生成逼真的图像。这部分代码与之前提供的相同,用于生成高质量的手写数字图像。 -
步骤2: 生成额外的训练数据
一旦GAN被训练好,我们可以使用它来生成额外的训练样本。这些样本将被添加到原始的训练集中,以期望提高分类模型的准确性和泛化能力。 -
步骤3: 训练分类模型
使用扩展后的数据集来训练一个分类模型。这里,我们可以使用简单的卷积神经网络(CNN)作为分类器。
具体代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import numpy as np
import matplotlib.pyplot as plt
# 超参数设置
batch_size = 64
learning_rate = 0.0002
num_epochs = 50
latent_dim = 100
num_samples_to_generate = 5000 # 生成的样本数量
# MNIST 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 生成器定义
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, 28, 28)
return img
# 判别器定义
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 损失和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练GAN
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(train_loader):
real = torch.ones(imgs.size(0), 1)
fake = torch.zeros(imgs.size(0), 1)
real_imgs = imgs
optimizer_D.zero_grad()
output_real = discriminator(real_imgs)
errD_real = criterion(output_real, real)
errD_real.backward()
noise = torch.randn(imgs.size(0), latent_dim)
fake_imgs = generator(noise)
output_fake = discriminator(fake_imgs.detach())
errD_fake = criterion(output_fake, fake)
errD_fake.backward()
optimizer_D.step()
optimizer_G.zero_grad()
output = discriminator(fake_imgs)
errG = criterion(output, real)
errG.backward()
optimizer_G.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss D: {errD_real.item()+errD_fake.item()}, Loss G: {errG.item()}')
# 生成额外的训练数据
class GeneratedDataset(Dataset):
def __init__(self, generator, num_samples):
self.generator = generator
self.num_samples = num_samples
self.noise = torch.randn(num_samples, latent_dim)
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
img = self.generator(self.noise[idx].unsqueeze(0))
label = torch.randint(0, 10, (1,)) # 随机标签
return img, label
# 使用生成器生成数据
generated_dataset = GeneratedDataset(generator, num_samples_to_generate)
generated_loader = DataLoader(dataset=generated_dataset, batch_size=batch_size, shuffle=True)
# 定义分类器模型
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64 * 7 * 7, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 初始化分类器
classifier = Classifier()
# 合并原始数据集和生成的数据集
def collate_fn(batch):
imgs, labels = zip(*batch)
imgs = torch.cat(imgs, dim=0)
labels = torch.cat(labels, dim=0)
return imgs, labels
combined_train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
combined_train_loader = DataLoader(dataset=combined_train_dataset, batch_size=batch_size, shuffle=True)
# 训练分类器
classifier_optimizer = optim.Adam(classifier.parameters(), lr=learning_rate)
classifier_criterion = nn.CrossEntropyLoss()
for epoch in range(10): # 训练几个epoch来测试
for imgs, labels in combined_train_loader:
classifier_optimizer.zero_grad()
outputs = classifier(imgs)
loss = classifier_criterion(outputs, labels)
loss.backward()
classifier_optimizer.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/10], Step [{i+1}/{len(combined_train_loader)}], Loss: {loss.item()}')
# 测试分类器性能
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in test_loader:
outputs = classifier(imgs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the classifier on the test images: {100 * correct / total}%')