在现代数据驱动的业务环境中,数据迁移和集成是常见的需求。DataX,作为阿里云开源的数据集成工具,提供了强大的数据同步能力,支持多种数据源和目标端。本文将介绍如何使用DataX将数据从MongoDB迁移到MySQL。
环境准备
-
安装MongoDB:首先,我们需要安装MongoDB。通过创建repo文件并配置yum源,我们可以轻松地通过yum安装MongoDB。此外,还需要修改MongoDB的配置文件以允许远程连接,并启动MongoDB服务。
-
MongoDB可视化工具:为了方便数据操作,我们可以使用MongoDB可视化工具进行数据管理。
MongoDB在Linux系统中的安装与配置指南-CSDN博客
数据准备
创建表和添加测试数据
在MongoDB中创建必要的表并添加测试数据。可以使用AIGC工具生成插入语句或使用Python代码进行数据导入。
数据如下:
6685758046e0fb0001dad8e8,340030000B47363438383733,8C780D32F900260383493808CC96,2024-07-04 00:00:00 055
6685758046e0fb0001dad8e9,340030000B47363438383733,8C79A06C39EE65FC81D828307124,2024-07-04 00:00:00 055
6685758046e0fb0001dad8ea,340030000B47363438383733,8C79A06C39EE632C2C12766ABC7D,2024-07-04 00:00:00 055
6685758046e0fb0001dad8eb,340030000B47363438383733,8C780D32381A65EEB9D6ACD107E7,2024-07-04 00:00:00 055
6685758046e0fb0001dad8ec,340030000B47363438383733,8C79A06C39EE65FC83D8242B91FC,2024-07-04 00:00:00 055
6685758046e0fb0001dadb53,180025000847363438383733,02818334223D7A,2024-07-04 00:00:00 125
6685758046e0fb0001dadb54,180025000847363438383733,8C7813B93818F058371851BB46ED,2024-07-04 00:00:00 125
6685758046e0fb0001dadb55,180025000847363438383733,A8001BAF809CEF25E00492C097AD,2024-07-04 00:00:00 125
6685758046e0fb0001dadb56,180025000847363438383733,8D78046A990C8E9DF09019F5FFD9,2024-07-04 00:00:00 125
6685758046e0fb0001dadb57,180025000847363438383733,02C18CB2F5ACA1,2024-07-04 00:00:00 125
6685758046e0fb0001dadb58,180025000847363438383733,200016303DA8AC,2024-07-04 00:00:00 125
6685758046e0fb0001dadb59,180025000847363438383733,02C18CB2F5ACA1,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5a,180025000847363438383733,02C189B8C3FFB4,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5b,180025000847363438383733,8D89805E584FE2AC38F4F65130D7,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5c,180025000847363438383733,02A185BA442656,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5d,180025000847363438383733,8D7805AF9909180C18041613AFAB,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5e,180025000847363438383733,02E18D1AB8F754,2024-07-04 00:00:00 125
6685758046e0fb0001dadb5f,180025000847363438383733,02A184B1B5AC11,2024-07-04 00:00:00 125
6685758046e0fb0001dadb60,180025000847363438383733,80618193580D32DD1EC5D965CAAF,2024-07-04 00:00:00 125
6685758046e0fb0001dadb61,180025000847363438383733,A000019389C80030A40000B08473,2024-07-04 00:00:00 125
6685758046e0fb0001dadb62,180025000847363438383733,A8001235FF731F13FFF453FB3E9D,2024-07-04 00:00:00 125
6685758046e0fb0001dadb63,180025000847363438383733,A00015BDC2980030A400000C9499,2024-07-04 00:00:00 125
6685758046e0fb0001dadb64,180025000847363438383733,02A18639AEDAAD,2024-07-04 00:00:00 125
6685758046e0fb0001dadb65,180025000847363438383733,8D780E409908D120F0482094F4EF,2024-07-04 00:00:00 125
6685758046e0fb0001dadb66,180025000847363438383733,5D75021BAFC19A,2024-07-04 00:00:00 125
6685758046e0fb0001dadb67,180025000847363438383733,02C18930C484A8,2024-07-04 00:00:00 125
6685758046e0fb0001dadb68,180025000847363438383733,A00015BDFFD9F93B2004E186573A,2024-07-04 00:00:00 125示例:
db.yourCollectionName.insertOne({
"id": "6685758046e0fb0001dad8e8",
"serialNumber": "340030000B47363438383733",
"uniqueId": "8C780D32F900260383493808CC96",
"timestamp": "2024-07-04T00:00:00.055Z"
})数据导入方式
介绍了两种数据导入方式,一种是使用Python代码导入,另一种是通过命令行导入。
使用 python 代码导入
pip install pymongo==4.4
from pymongo import MongoClient
# 创建MongoDB连接
client = MongoClient('hadoop13', 27017)
# 选择数据库,如果不存在则会自动创建
db = client['demo']
# 选择集合,如果不存在则会自动创建
collection = db['y_demo']
# 插入数据
#rawDataContent,revTime,deviceCode
with open('测试数据','r') as file1:
for line in file1:
arr = line.split(',')
print(arr)
dict = {"rawDataContent": arr[2], "revTime": arr[3].rstrip('\n'), "deviceCode": arr[1]}
print(dict)
collection.insert_one(dict)使用命令导入
如果不会 python,也可以通过命令导入:
mongoimport -h 127.0.0.1 -d demo -c y_demo --file "/home/y_demo.json" --jsonArrayjson 数据在本文绑定资源可下载


DataX实战
真实需求
将MongoDB中的一个表的三个字段导入到ClickHouse中,并在导入过程中将一个字段拆分为三个字段,同时增加三个新字段,变为 6 个字段。

解决方案
通过修改DataX的MongoDB reader源码来实现这一需求。
源码修改
详细介绍了如何使用IDEA打开DataX源码,修改maven配置,下载必要的jar包,并进行源码的修改和测试。
Datax - mongodb reader
DataX/mongodbreader/doc/mongodbreader.md at master · alibaba/DataX · GitHub
DataX案例:读取MongoDB的数据导入MySQL - 架构艺术 - 博客园 (cnblogs.com)
源码导入
环境准备
使用IntelliJ IDEA打开DataX源码。配置本地Maven,以加快依赖包的下载速度。

下载 jar 包的过程时间有点长,请耐心等待,本身是不大的,大约 20 多 M,但如果你拿到是含有编译过的 target 文件夹的源码,大约有 6G。
分析需求
阅读MongoDBReader的源码,理解其数据抽取和转换的机制。
首先同事已经通过 java 代码将 mongodb 的数据写入到了 ck 之中,想让你通过 datax 进行数据的抽取。同事的代码已经给了:
package com.lzhy.platform.service.impl;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.date.LocalDateTimeUtil;
import cn.hutool.core.util.HexUtil;
import com.lzhy.clickhouse.template.ClickHouseTemplate;
import com.lzhy.platform.entity.ParseData;
import com.lzhy.platform.model.pojo.CkAdsbParseData;
import com.lzhy.platform.model.pojo.CkAdsbRawData;
import com.lzhy.platform.model.pojo.DecodeSaveData;
import com.lzhy.platform.model.pojo.SendKafkaMessage;
import com.lzhy.platform.service.IWorkService;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.concurrent.atomic.LongAdder;
import java.util.stream.Collectors;
@Service("workService")
@Slf4j
@RequiredArgsConstructor
public class WorkServiceImpl implements IWorkService {
private final ClickHouseTemplate<CkAdsbRawData> rawDataClickHouseTemplate;
private final ClickHouseTemplate<CkAdsbParseData> ckAdsbParseDataClickHouseTemplate;
public static final String PARSE_TABLE_NAME = "default.adsb_parse_temp_local";
/**
* 原始数据表名
*/
public static final String RAW_TABLE_NAME = "default.adsb_raw_data_local";
/**
* 原始数据计数器 统计消息个数
*/
private final LongAdder rawDataCount = new LongAdder();
/**
* 解析数据计数器 统计消息个数
*/
private final LongAdder parseDataCount = new LongAdder();
/**
* 原始数据临时存储
*/
@Getter
private final List<CkAdsbRawData> rawDataList = new ArrayList<>(2000);
/**
* 解析数据临时存储
*/
@Getter
private final List<CkAdsbParseData> ckParseDataList = new ArrayList<>(2000);
@Override
public void start() {
}
@Override
public void saveRawDate(SendKafkaMessage sendKafkaMessage) {
try {
List<String> list = sendKafkaMessage.getRawDataValue();
String deviceCode = sendKafkaMessage.getDeviceCode();
long revTime = sendKafkaMessage.getRevTime();
if (CollUtil.isEmpty(list) || Objects.isNull(deviceCode)) {
return;
}
List<CkAdsbRawData> res = list.stream()
.filter(StringUtils::hasLength)
.map(raw -> {
String[] split = raw.split(",");
String rawContent = split[0];
long time = Long.parseLong(split[1]);
CkAdsbRawData ckAdsbRawData = new CkAdsbRawData();
ckAdsbRawData.setIcao(getIcao(rawContent));
ckAdsbRawData.setRevTime(LocalDateTimeUtil.of(time));
ckAdsbRawData.setHandleTime(LocalDateTimeUtil.now());
ckAdsbRawData.setDeviceCode(deviceCode);
ckAdsbRawData.setMsgContent(rawContent);
ckAdsbRawData.setMsgType(getDfType(rawContent));
return ckAdsbRawData;
}).collect(Collectors.toList());
rawDataCount.increment();
rawDataList.addAll(res);
if (rawDataCount.longValue() % 15 == 0) {
//存储
log.info("原始数据存储。存储大小:{}", ckParseDataList.size());
rawDataClickHouseTemplate.insertBath(RAW_TABLE_NAME, rawDataList);
rawDataList.clear();
rawDataCount.reset();
}
} catch (Exception e) {
log.error("储存失败", e);
}
}
@Override
public void saveParseDate(DecodeSaveData decodeSaveData) {
if (Objects.isNull(decodeSaveData)) {
return;
}
List<ParseData> parseDataList = decodeSaveData.getParseDataList();
if (CollUtil.isEmpty(parseDataList)) {
return;
}
List<CkAdsbParseData> res = parseDataList.stream().map(parseData -> {
CkAdsbParseData ckAdsbParseData = new CkAdsbParseData();
ckAdsbParseData.setIcao(Integer.parseInt(parseData.getIcao(), 16));
ckAdsbParseData.setRevTime(LocalDateTimeUtil.of(parseData.getRevTime()));
ckAdsbParseData.setDeviceCode(parseData.getDeviceCode());
ckAdsbParseData.setType(parseData.getType());
ckAdsbParseData.setRegNo(parseData.getRegNo());
ckAdsbParseData.setCallsign(parseData.getCallsign());
ckAdsbParseData.setCountry(parseData.getCountry());
ckAdsbParseData.setCompany(parseData.getCompany());
ckAdsbParseData.setLat(parseData.getLat());
ckAdsbParseData.setLng(parseData.getLng());
ckAdsbParseData.setAltitude(parseData.getAltitude());
ckAdsbParseData.setHeading(parseData.getHeading());
ckAdsbParseData.setSpeed(parseData.getSpeed());
ckAdsbParseData.setPositionTime(parseData.getPositionTime().getTime());
ckAdsbParseData.setSpeedTime(parseData.getSpeedTime() == null ? 0L : parseData.getSpeedTime().getTime());
ckAdsbParseData.setVerSpeed(parseData.getVerSpeed());
ckAdsbParseData.setVerSpeedType(parseData.getVerSpeedType());
ckAdsbParseData.setHeight(parseData.getHeight());
ckAdsbParseData.setHandleTime(LocalDateTime.now());
ckAdsbParseData.setACode(parseData.getaCode());
ckAdsbParseData.setIsOnGround(parseData.getIsOnGround());
ckAdsbParseData.setSpi(parseData.getSpi());
ckAdsbParseData.setEmergency(parseData.getEmergency());
ckAdsbParseData.setAlert("");
ckAdsbParseData.setRegNo(parseData.getRegNo());
return ckAdsbParseData;
}).collect(Collectors.toList());
parseDataCount.increment();
ckParseDataList.addAll(res);
if (parseDataCount.longValue() % 20 == 0) {
//存储
try {
log.info("解析数据存储。存储大小:{}", ckParseDataList.size());
ckAdsbParseDataClickHouseTemplate.insertBath(PARSE_TABLE_NAME, ckParseDataList);
} catch (Exception e) {
log.error("存储失败", e);
}
ckParseDataList.clear();
parseDataCount.reset();
}
}
/**
* 获取icao
*
* @param rawContent
* @return
*/
private int getIcao(String rawContent) {
int dfType = getDfType(rawContent);
if (dfType == 4 || dfType == 5) {
return getShortIcao(HexUtil.decodeHex(rawContent));
}
String icaoStr = rawContent.substring(2, 8);
return Integer.parseInt(icaoStr, 16);
}
private final long CRC24_INIT = 0x0;
private final long CRC24_POLY = 0x1FFF409;
/**
* 获取 04 05 报文icao
*
* @param abMessage
* @return
*/
private int getShortIcao(byte[] abMessage) {
long ulCRC = 0;
ulCRC = CRC24_INIT;
for (int i = 0; i < abMessage.length - 3; i++) {
long tem = abMessage[i];
tem = tem << 16;
ulCRC = ulCRC ^ tem;
for (int j = 0; j < 8; j++) {
ulCRC = ulCRC << 1;
if ((ulCRC & 0x1000000) != 0) {
ulCRC = ulCRC ^ CRC24_POLY;
}
}
}
long last3Bits = abMessage[4] * 0x10000 + abMessage[5] * 0x100 + abMessage[6];
String hex = HexUtil.toHex((ulCRC ^ last3Bits));
hex = hex.length() > 6 ? hex.substring(hex.length() - 6) : hex;
return Integer.parseUnsignedInt(hex, 16);
}
/**
* 获取df类型
*
* @param rawContent
* @return
*/
private int getDfType(String rawContent) {
String substring = rawContent.substring(0, 2);
return Integer.parseInt(substring, 16) >> 3;
}
}
因为人家代码中用到了 hutool 工具类,所以我们在源码的坐标中有添加该坐标:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>修改源码并测试打包
在修改完源码后,需要进行编译和打包。文章中提供了详细的编译命令和可能遇到的编译错误及其解决方案。
修改源码
所有字段全部写死

if (tempCol == null) {
//continue; 这个不能直接continue会导致record到目的端错位
String columnName = column.getString(KeyConstant.COLUMN_NAME);
if ("icao".equals(columnName)){
record.addColumn(new LongColumn(getIcao(item.getString("rawDataContent"))));
}else if("msg_type".equals(columnName)){
record.addColumn(new LongColumn(getDfType(item.getString("rawDataContent"))));
}else if("handle_time".equals(columnName)){
record.addColumn(new StringColumn(DateUtil.now()));
}else{
record.addColumn(new StringColumn(null));
}
}打包上传
代码编写完之后,需要编译,打包上传:
对datax的所有模块进行打包,时间比较长 30 分钟左右 【该命令会将 datax 中的所有插件全部打包】
mvn -U clean package assembly:assembly '-Dmaven.test.skip=true'
指定mongodbreader模块 以及 它所依赖的模块进行打包 【推荐使用,大约只运行 3 分钟左右】
mvn -U clean package -pl mongodbreader -am assembly:assembly '-Dmaven.test.skip=true'-p1 表示只打包对应的模块 -am 表示对应模块关联的模块也要打包编译。

编译报错

看到这个错误,是 java 环境变量的问题,这个问题非常难找,配置如下:
配置 CLASSPATH:
配置 JAVA_HOME:
配置 PATH 路径:
然后继续执行编译打包名命令,成功!
将idea中打的jar包上传到datax的mongodbreader下,替换原本的插件jar包
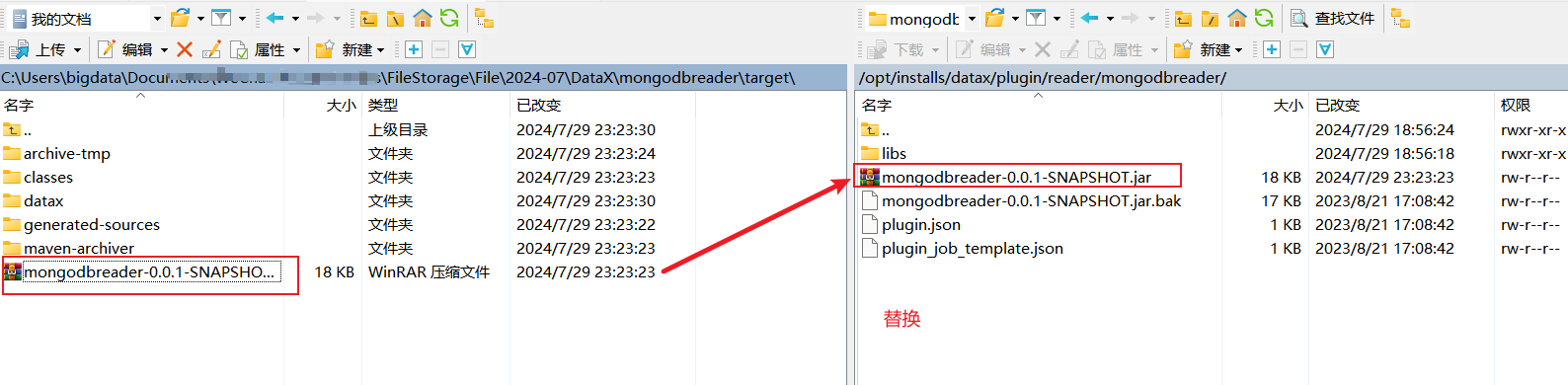
此时如果运行 job 任务,会报错,因为会提示缺 hutool 工具的 jar 包
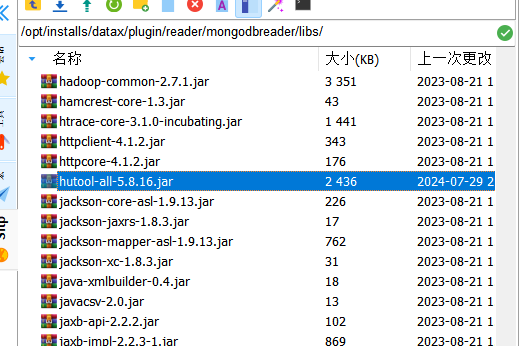
hutool工具类jar包上传到datax的mongodbreader的libs目录下
出现这种错误

DataX实战之MongoDB导入数据到mysql——打包jar包时出现Could not find goal assembly in plugin org.apache.maven.plugins_datax mongodbreader源码-CSDN博客
测试一下
在完成源码修改和打包后,需要在MySQL中创建相应的表,并编写DataX的JSON配置文件进行测试运行。
mysql建表
create table y_demo(
device_code varchar(100),
rev_time varchar(100),
msg_content varchar(100),
icao varchar(100),
msg_type varchar(100),
handle_time varchar(100)
) 
编写datax的json文件,并且测试运行
测试 json
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["bigdata01:27017"],
"collectionName": "y_demo",
"column": [
{
"name":"deviceCode",
"type":"string"
},
{
"name":"revTime",
"type":"string"
},
{
"name":"rawDataContent",
"type":"string"
},
{
"name":"icao",
"type":"string"
},
{
"name":"msg_type",
"type":"string"
},
{
"name":"handle_time",
"type":"string"
}
],
"dbName": "demo",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["device_code","rev_time","msg_content","icao","msg_type","handle_time"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://bigdata01:3306/sqoop",
"table": ["y_demo"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}运行报错

添加 jar 包

运行 json 脚本,导入成功

mysql 中的数据如下

资料
Datax mongodbreader源码jar包 ,替换/opt/installs/datax/plugin/reader/mongodbreader/
![]()
自定义函数的jar包 /opt/installs/datax/plugin/reader/mongodbreader/libs
![]()
hutool工具类 /opt/installs/datax/plugin/reader/mongodbreader/libs
![]()
fastjson2 的 jar 包
![]()
通过网盘分享的文件:datax-mongo-1.0-SNAPSHOT.jar等4个文件
视频讲解链接
通过修改DataX源码解决Mongodb导入数据到ClickHouse的问题_哔哩哔哩_bilibili
结语
DataX提供了一个简单而有效的方法来迁移MongoDB数据到MySQL。通过编写适当的JSON配置文件,我们可以灵活地处理各种复杂的数据迁移任务。这不仅提高了DataX的可用性,也为我们的数据同步工作提供了更多的可能。