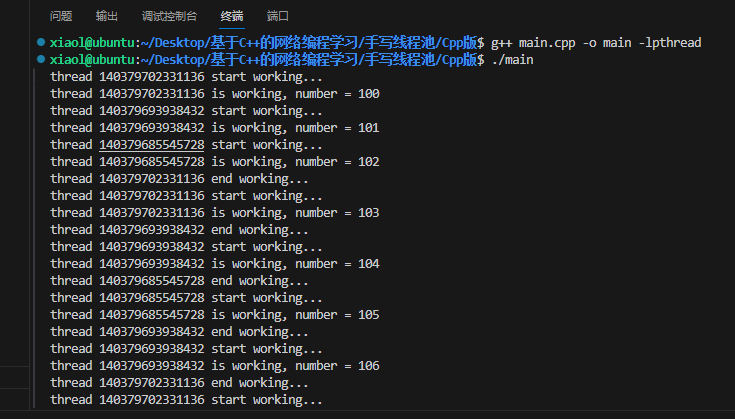
最近看sam2,顺便注释了下代码,方便回顾和分享。
PS: tensor的维度都基于默认参数配置。
SAM
_build_sam
sam模块包含三个部分,ImageEncoderViT、PromptEncoder和MaskDecoder:
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
sam = Sam(
# 普通的VIT模型, 对image进行encoding
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
# 是否使用PE
use_rel_pos=True,
# global_attn_indexes和window_size搭配
# 如果当前block索引不在global_attn_indexes则使用window_size的局部attn
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
),
# prompt,包括point, box, mask
# point支持多个,需要对应的label(1:fg 0:bg)
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
# mask解码器
mask_decoder=MaskDecoder(
# 输出mask个数。默认为3.解决prompt-ambiguous。
num_multimask_outputs=3,
# image-to-prompt和prompt-to-image的cross-attn
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
sam.load_state_dict(state_dict)
return sam
ImageEncoderViT
就是一个传统的vit结构,默认参数配置下[B, 3, 1024, 1024] - > [B, 256, 64, 64]。
PromptEncoder
对prompt(点,框,mask)进行embeding。最终的输出维度如下:
# dense_embeddings Bx256x64x64
# sparse_embeddings Bx(N+1)x256, N为点的个数
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
# 用于坐标归一化
self.input_image_size = input_image_size
# 图像经patch处理之后的width、height,容易和embeding_dim混淆
self.image_embedding_size = image_embedding_size
# PE,sin-cos
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
# 统一point和box的embeding向量
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
# 对point是否有效进行embeding,然后加到PE上
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
# 如果point为无效的(比如pad的),则用下面这个
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
# mask下采样模块
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image encoding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5 # Shift to center of pixel
# pad,保持和box统一
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
## PE
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
## 叠加label标记
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
## 整体思路同_embed_points
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> int:
"""
Gets the batch size of the output given the batch size of the input prompts.
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks)
# sparse_embeddings只是为了保证函数返回形式统一,即点和框都为NONE的时候返回一个空的tensor
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
# mask,来源有几种
# 1. 用户指定的low-resolution mask
# 2. 上一次预测的mask
if masks is not None:
# 4倍下采样
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
# dense_embeddings Bx256x64x64
# sparse_embeddings Bx4x256
return sparse_embeddings, dense_embeddings
MaskDecoder

class MaskDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: int,
transformer: nn.Module,
num_multimask_outputs: int = 3,
activation: Type[nn.Module] = nn.GELU,
iou_head_depth: int = 3,
iou_head_hidden_dim: int = 256,
) -> None:
"""
Predicts masks given an image and prompt embeddings, using a
transformer architecture.
Arguments:
transformer_dim (int): the channel dimension of the transformer
transformer (nn.Module): the transformer used to predict masks
num_multimask_outputs (int): the number of masks to predict
when disambiguating masks
activation (nn.Module): the type of activation to use when
upscaling masks
iou_head_depth (int): the depth of the MLP used to predict
mask quality
iou_head_hidden_dim (int): the hidden dimension of the MLP
used to predict mask quality
"""
super().__init__()
# transformer的编码维度
self.transformer_dim = transformer_dim
# mask预测,twoway-transformer
self.transformer = transformer
self.num_multimask_outputs = num_multimask_outputs
# iou预测token
self.iou_token = nn.Embedding(1, transformer_dim)
# 从代码看,+1是为了匹配非multi_mask的情况
self.num_mask_tokens = num_multimask_outputs + 1
# mask预测token
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
# 对mask预测值上采样
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
# mask-MLP
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# iou预测头
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
"""
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# Select the correct mask or masks for output
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# Prepare output
return masks, iou_pred
def predict_masks(
self,
image_embeddings: torch.Tensor, #[B, 256, 64, 64]
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# Concatenate output tokens
pdb.set_trace()
# 拼接iou_token和mask_tokens,分别预测iou和mask
# [5, 256]
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
# 扩展到batch维度
# [B, 5, 256]
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
# 拼接sparse_prompt_embeding
# [B, 8, 256]
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# Expand per-image data in batch direction to be per-mask
# [B, 256, 64, 64]
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
# image_embeding 和 dense_prompt_embedings进行element-wise add
# [B, 256, 64, 64]
src = src + dense_prompt_embeddings
# 扩展image_pe
# [B, 256, 64, 64]
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# Run the transformer
# 下面的部分对应论文Figure.14。
# hs, 对应论文中的output_token [B, 8, 256]
# src, attn后的image_embeding [B, 4096, 256] (PS: 4096=64x64)
hs, src = self.transformer(src, pos_src, tokens)
# 取出iou_token [B, 256]
iou_token_out = hs[:, 0, :]
# 取出mask_tokens [B, 4, 256]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
# reshape回去 [B, 256, 64, 64]
src = src.transpose(1, 2).view(b, c, h, w)
# 上采样 [B, 32, 256, 256]
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
# 把每个mask_token送入各自的MLP
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# 拼接 [B, 4, 32]
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
# image_embeding和mask_tokens进行矩阵乘得到最终的masks [B, 4, 256, 256]
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# Generate mask quality predictions
# [B, 4]
iou_pred = self.iou_prediction_head(iou_token_out)
# mask经过上采样X4后,就和image一致了
return masks, iou_pred
SAM-HQ
对比sam,主要区别有这几个:
- global-loca fusion。高频-低频特征融合,类似于FPN,提升微小mask的精度;
- 添加了HQ-OUTPUT TOKEN。保持原始结构不变,只微调该分支,类似于lora,可以保持原始sam部分能力。

比较mask_decoder_hq.py和mask_decoder.py,构造函数里面主要添加了几个OP,如下:
# HQ-SAM parameters
self.hf_token = nn.Embedding(1, transformer_dim) # HQ-Ouptput-Token
self.hf_mlp = MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) # corresponding new MLP layer for HQ-Ouptput-Token
# three conv fusion layers for obtaining HQ-Feature
self.compress_vit_feat = nn.Sequential(
nn.ConvTranspose2d(vit_dim, transformer_dim, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim),
nn.GELU(),
nn.ConvTranspose2d(transformer_dim, transformer_dim // 8, kernel_size=2, stride=2))
self.embedding_encoder = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
nn.GELU(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
)
self.embedding_maskfeature = nn.Sequential(
nn.Conv2d(transformer_dim // 8, transformer_dim // 4, 3, 1, 1),
LayerNorm2d(transformer_dim // 4),
nn.GELU(),
nn.Conv2d(transformer_dim // 4, transformer_dim // 8, 3, 1, 1))
具体的运算代码:
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
hq_token_only: bool,
interm_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the ViT image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
"""
# 首先,取出浅层的image_embeding,这个时候的特征感受野比较小,高频特征
vit_features = interm_embeddings[0].permute(0, 3, 1, 2) # early-layer ViT feature, after 1st global attention block in ViT
# 特征融合。类似于检测模型里面的FPN,至此,高频+低频特征融合完成
hq_features = self.embedding_encoder(image_embeddings) + self.compress_vit_feat(vit_features)
# mask预测函数入口
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
hq_features=hq_features,
)
# Select the correct mask or masks for output
if multimask_output:
# mask with highest score
mask_slice = slice(1,self.num_mask_tokens-1)
iou_pred = iou_pred[:, mask_slice]
iou_pred, max_iou_idx = torch.max(iou_pred,dim=1)
iou_pred = iou_pred.unsqueeze(1)
masks_multi = masks[:, mask_slice, :, :]
masks_sam = masks_multi[torch.arange(masks_multi.size(0)),max_iou_idx].unsqueeze(1)
else:
# singale mask output, default
mask_slice = slice(0, 1)
iou_pred = iou_pred[:,mask_slice]
masks_sam = masks[:,mask_slice]
masks_hq = masks[:,slice(self.num_mask_tokens-1, self.num_mask_tokens)]
if hq_token_only:
masks = masks_hq
else:
masks = masks_sam + masks_hq
# Prepare output
return masks, iou_pred
predict_masks函数注释:
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
hq_features: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# Concatenate output tokens
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight, self.hf_token.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# Expand per-image data in batch direction to be per-mask
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens)
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding_sam = self.output_upscaling(src)
# 上面部分代码和sam几乎一样,下面部分是关于HQ
# 融合sam和hq特征,对应论文中的global-local fusion
upscaled_embedding_hq = self.embedding_maskfeature(upscaled_embedding_sam) + hq_features.repeat(b,1,1,1)
hyper_in_list: List[torch.Tensor] = []
# 对mask_token_out进行MLP,对应论文的updated hq-output token
for i in range(self.num_mask_tokens):
if i < self.num_mask_tokens - 1:
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
else:
hyper_in_list.append(self.hf_mlp(mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding_sam.shape
# mask_out和global-local fusion进行矩阵乘法
masks_sam = (hyper_in[:,:self.num_mask_tokens-1] @ upscaled_embedding_sam.view(b, c, h * w)).view(b, -1, h, w)
masks_sam_hq = (hyper_in[:,self.num_mask_tokens-1:] @ upscaled_embedding_hq.view(b, c, h * w)).view(b, -1, h, w)
masks = torch.cat([masks_sam,masks_sam_hq],dim=1)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out)
return masks, iou_pred
FastSAM
两个独立部分:
- 全图实例分割。输出图片中所有目标mask(只有一个类别)。
- prompt匹配。对prompt进行编码,然后对上一步的输出的mask进行匹配。简单的如box、point直接通过点的位置、IOU等方式匹配,如果是text则用clip进行embeding,然后计算相似度。
相比于sam,fastsam在seg-anything模式下因为不需要进行稠密prompt采样,因此输出mask会更快。这也是mobilesamV2改进的方向。

MobileSAM
这个更简单,整体的逻辑都是沿用sam,对sam的image-encoder(ViT)进行蒸馏到轻量级网络(Tiny-ViT),减少网络尺寸和耗时。
看下tinyvit的方法就差不多了:
TinyViT: Fast Pretraining Distillation for Small Vision Transformers

还有其他几个:
- Ground-SAM。text-detection-segment,侧重文字交互式的进行检测和分割。
- Semantic-SAM。着重优化目标局部和整体之间的关系、分割。
- sam2。 引入了track思想,不需要逐帧prompt的end2end连续帧的分割。
应用
sam应用还是挺广的,主要负责抠图,然后对这些区域进行擦除、替换、修复等。
- https://github.com/geekyutao/Inpaint-Anything
- https://github.com/advimman/lama
引用
https://github.com/facebookresearch/segment-anything
https://github.com/SysCV/SAM-HQ
https://github.com/CASIA-IVA-Lab/FastSAM
https://github.com/ChaoningZhang/MobileSAM
https://github.com/IDEA-Research/Grounded-Segment-Anything
https://github.com/UX-Decoder/Semantic-SAM