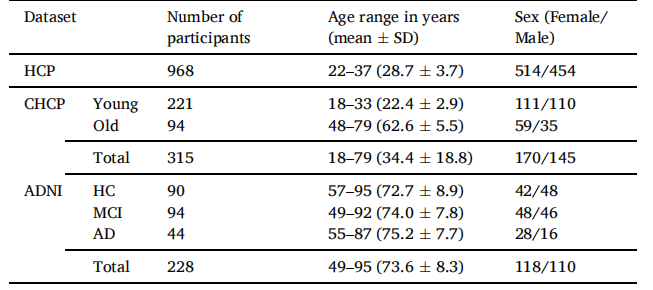
-
编码器:
- 嵌入层:将源语言单词索引转换为嵌入向量。
- RNN层:使用LSTM处理嵌入向量,生成隐藏状态和细胞状态。
- 输出:返回最后一个时间步的隐藏状态和细胞状态,作为上下文向量。
-
解码器:
- 嵌入层:将目标语言单词索引转换为嵌入向量。
- RNN层:使用LSTM处理嵌入向量和上下文向量,生成隐藏状态和细胞状态。
- 输出层:将隐藏状态转换为目标语言词汇表中的概率分布。
编码器的输出
编码器的主要任务是将输入序列(通常是源语言句子)编码成一个固定长度的上下文向量(也称为隐状态或编码器的最终状态)。这个上下文向量包含了输入序列的全部信息,用于帮助解码器生成目标序列。
编码器的输出
- 隐藏状态:编码器生成的最后一个时间步的隐藏状态。
- 细胞状态:对于LSTM,还包括最后一个时间步的细胞状态。
在编码器的前向传播过程中,输入序列被逐个处理,生成一系列隐藏状态。最终的隐藏状态和细胞状态(如果有)被传递给解码器。
解码器的输入
解码器的输入主要有两部分:
- 当前时间步的输入单词(通常是目标语言中的单词索引)。
- 前一个时间步的隐藏状态和细胞状态(来自LSTM或RNN)。
3. 编码器输出与解码器输入的关系
编码器的输出(隐藏状态和细胞状态)作为解码器的初始隐藏状态和细胞状态。这样,解码器在生成目标序列时,可以利用编码器提取的输入序列的全部信息。
import torch
import torch.nn as nn
import torch.optim as optim
import random
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim # 隐藏层维度
self.n_layers = n_layers # LSTM 层的数量
self.embedding = nn.Embedding(input_dim, emb_dim) # 嵌入层,将单词索引转换为嵌入向量
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout) # LSTM 层
self.dropout = nn.Dropout(dropout) # Dropout 层,用于防止过拟合
def forward(self, src):
# src: (seq_len, batch_size)
embedded = self.dropout(self.embedding(src)) # (seq_len, batch_size, emb_dim)
outputs, (hidden, cell) = self.rnn(embedded) # outputs: (seq_len, batch_size, hid_dim), hidden: (n_layers, batch_size, hid_dim), cell: (n_layers, batch_size, hid_dim)
return hidden, cell # 返回最后一个时间步的隐藏状态和细胞状态
# 定义解码器
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim # 目标语言词汇表的大小
self.hid_dim = hid_dim # 隐藏层维度
self.n_layers = n_layers # LSTM 层的数量
self.embedding = nn.Embedding(output_dim, emb_dim) # 嵌入层,将单词索引转换为嵌入向量
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout) # LSTM 层
self.fc_out = nn.Linear(hid_dim, output_dim) # 输出层,将隐藏状态转换为词汇表中的概率分布
self.dropout = nn.Dropout(dropout) # Dropout 层,用于防止过拟合
def forward(self, input, hidden, cell):
# input: (batch_size,)
input = input.unsqueeze(0) # (1, batch_size)
embedded = self.dropout(self.embedding(input)) # (1, batch_size, emb_dim)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell)) # output: (1, batch_size, hid_dim), hidden: (n_layers, batch_size, hid_dim), cell: (n_layers, batch_size, hid_dim)
prediction = self.fc_out(output.squeeze(0)) # (batch_size, output_dim)
return prediction, hidden, cell # 返回预测值、隐藏状态和细胞状态
# 定义序列到序列模型
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder # 编码器
self.decoder = decoder # 解码器
self.device = device # 设备(CPU 或 GPU)
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src: (src_seq_len, batch_size)
# trg: (trg_seq_len, batch_size)
batch_size = trg.shape[1] # 批次大小
trg_len = trg.shape[0] # 目标序列的长度
trg_vocab_size = self.decoder.output_dim # 目标语言词汇表的大小
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device) # 初始化输出张量
# 通过编码器生成隐藏状态和细胞状态
hidden, cell = self.encoder(src)
# 初始化解码器的输入为 <sos> 标记
input = trg[0, :]
for t in range(1, trg_len):
# 通过解码器生成当前时间步的输出
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output # 存储当前时间步的输出
top1 = output.argmax(1) # 获取当前时间步的预测单词索引
# 根据教师强制比例决定下一个时间步的输入
input = trg[t] if random.random() < teacher_forcing_ratio else top1
return outputs # 返回所有时间步的输出
# 参数设置
INPUT_DIM = 10000 # 假设源语言词汇表大小
OUTPUT_DIM = 10000 # 假设目标语言词汇表大小
ENC_EMB_DIM = 256 # 编码器嵌入层维度
DEC_EMB_DIM = 256 # 解码器嵌入层维度
HID_DIM = 512 # 隐藏层维度
N_LAYERS = 2 # LSTM 层的数量
ENC_DROPOUT = 0.5 # 编码器的 Dropout 概率
DEC_DROPOUT = 0.5 # 解码器的 Dropout 概率
# 创建模型实例
encoder = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
decoder = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Seq2Seq(encoder, decoder, device).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=0) # 损失函数,忽略 padding token (0)
optimizer = optim.Adam(model.parameters()) # 优化器,使用 Adam
# 训练循环
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
epoch_loss = 0 # 初始化每轮的损失
for batch in train_iterator: # 遍历训练数据
src = batch.src # 获取源语言序列
trg = batch.trg # 获取目标语言序列
optimizer.zero_grad() # 清除梯度
output = model(src, trg) # 前向传播,生成输出
output_dim = output.shape[-1] # 获取输出的词汇表大小
output = output[1:].view(-1, output_dim) # 重塑输出张量,去掉第一个时间步
trg = trg[1:].view(-1) # 重塑目标张量,去掉第一个时间步
loss = criterion(output, trg) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新模型参数
epoch_loss += loss.item() # 累加每批次的损失
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss / len(train_iterator):.4f}') # 打印每轮的平均损失
# 评估循环
model.eval() # 设置模型为评估模式
epoch_loss = 0 # 初始化每轮的损失
with torch.no_grad(): # 关闭梯度计算
for batch in valid_iterator: # 遍历验证数据
src = batch.src # 获取源语言序列
trg = batch.trg # 获取目标语言序列
output = model(src, trg, 0) # 前向传播,生成输出,关闭教师强制
output_dim = output.shape[-1] # 获取输出的词汇表大小
output = output[1:].view(-1, output_dim) # 重塑输出张量,去掉第一个时间步
trg = trg[1:].view(-1) # 重塑目标张量,去掉第一个时间步
loss = criterion(output, trg) # 计算损失
epoch_loss += loss.item() # 累加每批次的损失
print(f'Validation Loss: {epoch_loss / len(valid_iterator):.4f}') # 打印验证集的平均损失
为什么要去掉第一个时间步?
在很多序列生成任务中,第一个时间步通常是一个特殊的起始符号(如 <sos>),用于标记序列的开始。在训练过程中,模型需要学习如何从这个起始符号开始生成序列。
序列到序列学习(Sequence-to-Sequence Learning,简称Seq2Seq)是一种用于处理序列数据的深度学习框架,广泛应用于自然语言处理任务,如机器翻译、文本摘要、对话系统等。Seq2Seq 模型的核心思想是将一个输入序列转换为另一个输出序列。下面我们将详细讲解Seq2Seq模型的各个组成部分及其工作原理。
1. 模型概述
Seq2Seq 模型通常由两部分组成:
- 编码器(Encoder):将输入序列编码成一个固定长度的上下文向量(也称为隐状态或编码器的最终状态)。
- 解码器(Decoder):根据编码器生成的上下文向量,逐步生成目标序列。
2. 编码器
2.1 结构
编码器通常是一个递归神经网络(RNN),最常见的选择是长短期记忆网络(LSTM)或门控循环单元(GRU)。编码器的任务是将输入序列编码成一个固定长度的上下文向量。
2.2 工作流程
- 输入:编码器的输入是一个源语言句子的单词索引序列,形状为
(seq_len, batch_size)。 - 嵌入层:将输入序列中的单词索引转换为嵌入向量,形状为
(seq_len, batch_size, emb_dim)。 - RNN层:通过RNN层(如LSTM)处理嵌入向量,生成每个时间步的隐藏状态和细胞状态。
- 输出:编码器的输出是最后一个时间步的隐藏状态和细胞状态,这些状态作为解码器的初始状态。
3. 解码器
3.1 结构
解码器也是一个RNN,通常也是LSTM或GRU。解码器的任务是根据编码器生成的上下文向量,逐步生成目标序列。
3.2 工作流程
- 初始输入:解码器的初始输入通常是目标语言的起始标记
<sos>。 - 嵌入层:将输入单词索引转换为嵌入向量。
- RNN层:通过RNN层处理嵌入向量,生成当前时间步的隐藏状态和细胞状态。
- 输出层:将隐藏状态通过全连接层转换为词汇表中的概率分布,选择概率最高的单词作为当前时间步的输出。
- 教师强制:在训练时,可以使用教师强制技术,即在每个时间步使用真实的上一个单词作为输入,而不是模型预测的单词。这有助于加快训练过程,但可能会导致模型在推理时表现不佳。::::
-
训练过程
-
初始化:
- 我们从特殊的起始符号
<sos>开始生成中文句子。
- 我们从特殊的起始符号
-
第一个时间步:
- 教师强制:我们使用真实的下一个单词
我作为输入。 - 非教师强制:模型可能会预测一个单词,比如
今天。
- 教师强制:我们使用真实的下一个单词
-
第二个时间步:
- 教师强制:我们使用真实的下一个单词
热爱作为输入。 - 非教师强制:模型可能会预测另一个单词,比如
是。
- 教师强制:我们使用真实的下一个单词
-
第三个时间步:
- 教师强制:我们使用真实的下一个单词
编程作为输入。 - 非教师强制:模型可能会预测另一个单词,比如
中国。
- 教师强制:我们使用真实的下一个单词
-
第四个时间步:
- 教师强制:我们使用特殊的结束符号
<eos>作为输入,表示句子结束。 - 非教师强制:模型可能会预测另一个单词,但我们将其停止。
- 教师强制:我们使用特殊的结束符号
- 循环:重复上述步骤,直到生成目标序列的结束标记
<eos>或达到最大序列长度。
4. 模型训练
4.1 数据准备
- 输入数据:源语言句子的单词索引序列。
- 目标数据:目标语言句子的单词索引序列。
4.2 损失函数
- 交叉熵损失:常用的损失函数是交叉熵损失,它衡量模型预测的概率分布与真实标签之间的差异。通常会忽略填充标记(如0)的损失。
4.3 优化器
- Adam:常用的优化器是Adam,它结合了动量和RMSProp的优点,适用于大多数深度学习任务。




![[利用python进行数据分析01] “来⾃Bitly的USA.gov数据” 分析出各个地区的 windows和非windows用户](https://i-blog.csdnimg.cn/direct/fb36b41fde154881a78108aac6e73bd9.png)