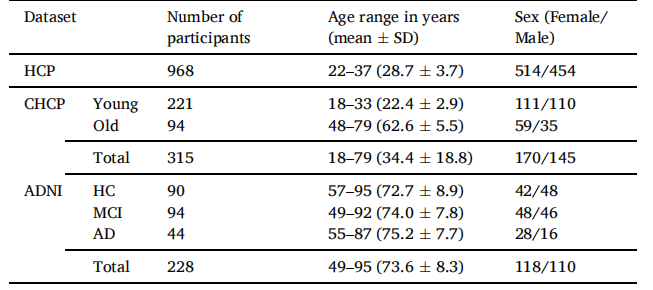
链接:https://pan.baidu.com/s/1t4AzSwytJOG0ZYNMjx7FtQ?pwd=w2ia
提取码:w2ia
--来自百度网盘超级会员V6的分享
设置一下库的依赖
from numpy.random import randn
import numpy as np
np.random.seed(123)
import os
import matplotlib.pyplot as plt
import pandas as pd
plt.rc("figure", figsize=(10, 6))
np.set_printoptions(precision=4)
pd.options.display.max_columns = 20
pd.options.display.max_rows = 20
pd.options.display.max_colwidth = 80首先我们先读取下数据集
import json
# 使用 'utf-8' 编码打开文件,避免 UnicodeDecodeError
with open(path, encoding='utf-8') as f:
records = [json.loads(line) for line in f]
print(records)
time_zones=[rec.get("tz") for rec in records]

然后我们写一个统计数量的函数
写法1:
def get_counts(sequence):
counts={}
for x in sequence:
if x in counts:
counts[x]+=1
else:
counts[x]=1
return counts
然后我们就可以统计“c”数列下“US”的个数:
counts = get_counts(country_zones)
print(counts["US"])
len(country_zones)
方法2:defaultdict,这是 collections 模块中的一种字典类型,可以指定默认的工厂函数,用于在访问不存在的键时自动初始化键的值。
counts = defaultdict(int):
- 创建一个
defaultdict对象counts,并指定int作为默认值的工厂函数。 int()返回0,所以每当一个新的键被访问时,默认值就是0。- 例如,如果访问一个键
"key1",而"key1"不存在,则counts["key1"]会自动初始化为0。
-
for x in sequence::- 遍历传入的
sequence(可以是列表、字符串等任意可迭代对象),x是sequence中的每个元素。
- 遍历传入的
-
counts[x] += 1:- 对每个元素
x,将其作为键在counts中进行累加。 - 如果
x已经在counts中,则增加其对应的值(计数)。 - 如果
x不在counts中,则defaultdict自动初始化为0,然后执行+= 1,计数变为1。
- 对每个元素
-
return counts:- 返回包含元素计数的
defaultdict。
from collections import defaultdict def get_counts2(sequence): counts = defaultdict(int) # values will initialize to 0 for x in sequence: counts[x] += 1 return counts
我们还能写一个函数来统计最大的几个数量,从小到大排序 -
方法1:
def top_counts(count_dict, n=10): value_key_pairs = [(count, tz) for tz, count in count_dict.items()] value_key_pairs.sort() return value_key_pairs[-n:]
方法2:
直接调用collections 下的 Counter模块返回最大的10个from collections import Counter counts = Counter(country_zones) counts.most_common(10)
之后我们打算用pandas对这个数据集进行分析我们使用DataFrameframe = pd.DataFrame(records) print(frame.info()) print(frame["tz"]) frame["tz"].head()
从DataFrame里面提取出来c列
tz_counts = frame["c"].value_counts() tz_counts.head() tz_counts[:10]
我们对缺失的c列进行填充
主要目的是对frame数据框中的"c"列进行清洗,将缺失值替换为"Missing",将空字符串替换为"Unknown",然后统计每个时区(c)的出现次数。
clean_c=frame["c"].fillna("Missing") print(clean_c) clean_c[clean_c == ""] = "Unknown" c_counts = clean_c.value_counts() c_counts.head()
然后我们调用seaborn库对统计的次数进行绘图import seaborn as sns subset = c_counts.head() sns.barplot(y=subset.index, x=subset.to_numpy())
然后我们对数据集的a标签进行分析
给整个dataframe加一个os列
frame["a"].dropna(): - 从
frame数据框中提取"a"列,并使用.dropna()方法移除所有的缺失值(NaN)。这确保后续操作不会因空值引发错误。
[x.split()[0] for x in frame["a"].dropna()]: - 这是一个列表推导式,用于处理
"a"列中的每个非空字符串x。 x.split():将字符串x按照空格拆分为一个列表,包含各个单词。x.split()[0]:获取拆分后的第一个单词,即列表中的第一个元素。- 这一过程将
"a"列中每个字符串的第一个单词提取出来。 -
pd.Series([...]):- 将提取出的第一个单词列表转换为一个 Pandas
Series对象,方便后续的统计和分析。
- 将提取出的第一个单词列表转换为一个 Pandas
-
print(results.head(5)):- 打印
resultsSeries 的前 5 个元素,查看提取出的第一个单词。
- 打印
-
results.value_counts():value_counts()方法统计results中每个唯一值的出现次数,并按频次降序排列。- 返回的结果是一个 Series,其中索引是唯一值,值是对应的出现次数。
-
print(results.value_counts().head(8)):- 打印前 8 个最常见的第一个单词及其出现次数,便于查看数据分布情况
-
frame["a"].notna():notna()是 Pandas 中的一个方法,用于判断数据是否不是NaN(即空值)。frame["a"].notna()返回一个布尔 Series,标识"a"列中哪些值不是NaN。- 例如,对于
"a"列中的数据["Mozilla/5.0", NaN, "Safari", "Chrome", NaN],notna()返回[True, False, True, True, False]。
-
frame[frame["a"].notna()]:- 使用布尔索引筛选
frame数据框,仅保留"a"列中非空的行。 - 结果是一个新的数据框,只包含
"a"列中值不是NaN的行。
- 使用布尔索引筛选
-
.copy():.copy()方法用于生成筛选后数据框的一个深拷贝,确保cframe是独立的,不会与frame共享数据。- 这样做是为了防止对
cframe的操作(如修改数据)影响到原始数据frame。
-
cframe:cframe是经过筛选和复制的新的数据框,它包含所有"a"列非空的行cframe = frame[frame["a"].notna()].copy() cframe
这里是删除了所有存在NAN的行
在数据框cframe中创建一个新的列"os",用于标记每行对应的操作系统是"Windows"还是"Not Windows",根据"a"列中是否包含"Windows"字样来判断。
cframe["os"] = np.where(cframe["a"].str.contains("Windows"), "Windows", "Not Windows") cframe["os"].head(5)
-
cframe["a"].str.contains("Windows"):cframe["a"]:获取cframe数据框中的"a"列。.str.contains("Windows"):检查"a"列中的每个字符串是否包含"Windows",返回一个布尔 Series。如果包含"Windows",则为True;否则为False。
-
np.where(condition, x, y):np.where是 NumPy 的一个函数,根据condition的布尔值来选择x或y。- 如果
condition为True,则返回x;如果为False,则返回y。 - 在这里,根据是否包含
"Windows",分别返回"Windows"或"Not Windows"。
-
cframe["os"] = np.where(...):- 将
np.where(...)的结果赋值给cframe的新列"os"。 - 这样,
"os"列中的每一行将被标记为"Windows"或"Not Windows",取决于"a"列的内容。
- 将
-
cframe["os"].head(5):.head(5)用于显示"os"列的前 5 行,方便查看标记结果。
对整个dataframe进行按照 “c”,"os"两列分组by_c_os = cframe.groupby(["c", "os"]) print(by_c_os)-
by_c_os = cframe.groupby(["c", "os"]):- 这行代码对
cframe数据框进行分组,按c(时区或其他分类)和os(操作系统)组合分组。 by_c_os是一个分组对象,后续可以对分组数据进行聚合操作。
- 这行代码对
-
agg_counts = by_c_os.size().unstack().fillna(0):by_c_os.size():计算每个(c, os)组合的分组大小(即记录数量)。.unstack():将os从行索引转换为列,形成一个 DataFrame,行是c的值,列是os的值。.fillna(0):用0填充NaN,表示某个(c, os)组合没有出现时的计数。
-
agg_counts.head():- 显示
agg_countsDataFrame 的前 5 行,方便快速查看分组统计结果。
- 显示
-
indexer = agg_counts.sum("columns").argsort():agg_counts.sum("columns"):对每一行(每个c)按列方向求和,即计算各时区中所有操作系统的总计数。.argsort():返回求和结果从小到大的排序索引。indexer是一个Index对象,包含了排序后的索引位置。
-
indexer.values[:10]:- 取出
indexer的前 10 个索引值。这通常用于选择出现次数较少的时区或分类。
- 取出
-
print(indexer):- 打印
indexer,显示排序后的索引。
by_c_os = cframe.groupby(["c", "os"]) print(by_c_os) agg_counts = by_c_os.size().unstack().fillna(0) agg_counts.head() indexer = agg_counts.sum("columns").argsort() indexer.values[:10] print(indexer)
-
count_subset = agg_counts.take(indexer[-10:]):indexer[-10:]:获取indexer的最后 10 个索引。这表示选择排序后计数值最大的 10 个组。agg_counts.take(indexer[-10:]):使用take()方法根据indexer中的索引提取对应的行。count_subset:是一个新的 DataFrame,包含了agg_counts中按总计数排序的最后 10 行数据(即计数最高的 10 组)。
-
agg_counts.sum(axis="columns").nlargest(10):agg_counts.sum(axis="columns"):对agg_counts的每一行(即每个c组)按列方向求和,得到每个组的总计数。nlargest(10):获取求和后值最大的前 10 个组。- 结果是一个包含前 10 个最大值及其对应索引的 Series。
- 打印

pandas有⼀个简便⽅法nlargest,可以做同样的⼯作:agg_counts.sum(1).nlargest(10)
(注意的是对a标签 所有 缺失值都delete了 对c标签 缺失值都 fill了)
-
count_subset = count_subset.stack():stack()方法将count_subsetDataFrame 的列索引(os)转为行索引,从而将宽表(Wide Format)转换为长表(Long Format)。- 这使得每个时区 (
c) 和操作系统 (os) 的组合有各自的行,并且相应的计数值也在同一列中。
例如,
count_subset经过stack()后的效果:count_subset = count_subset.stack() count_subset.name = "total" count_subset = count_subset.reset_index() count_subset.head(10) sns.barplot(x="total", y="c", hue="os", data=count_subset)
-
count_subset.name = "total":- 给
count_subset命名为"total",即将刚刚生成的值列命名为"total",这对后续的绘图有利。
- 给
-
count_subset = count_subset.reset_index():reset_index()方法将多级索引 (c和os) 转为普通的 DataFrame 列,使数据更整洁,并方便后续绘图使用。
-
count_subset.head(10):- 显示
count_subsetDataFrame 的前 10 行,用于快速查看数据的结构和内容。
- 显示
-
sns.barplot(x="total", y="c", hue="os", data=count_subset):- 使用 seaborn 的
barplot()函数绘制分组条形图:x="total":将"total"列的值作为 X 轴。y="c":将"c"列的值作为 Y 轴(时区)。hue="os":根据"os"列(操作系统)对数据进行分组和着色。data=count_subset:指定用于绘图的数据源是count_subset。
-
定义函数
norm_total(group):- 这是一个自定义函数,用于对每个分组的数据进行处理。
group["total"] / group["total"].sum():- 计算
group["total"]中每个值相对于该组内总和的比例。 - 归一化操作:将每个
total值除以该组(c)内所有total的总和。
- 计算
group["normed_total"] = ...:- 将计算的归一化比例存储在新的列
"normed_total"中。
- 将计算的归一化比例存储在新的列
return group:- 返回经过处理的分组数据。
-
count_subset.groupby("c").apply(norm_total):.groupby("c"):将count_subset按"c"(时区)进行分组。.apply(norm_total):对每个分组调用norm_total()函数。results是包含了所有分组及其处理结果的 DataFrame,带有新增的"normed_total"列。
-
-

-
还可以⽤ groupby 的transform⽅法,更⾼效的计算标准化的和

本人为大三本科生,由于时间仓促,本文难免会出现错误或者纰漏!欢迎大家评论区讨论交流!互粉!
-
- 使用 seaborn 的
- 返回包含元素计数的