摘要
近年来,许多研究致力于减少浮点运算(FLOPs)以加速神经网络。然而,我们观察到这种FLOPs的减少并不一定能带来相应的延迟减少。这主要是由于运算每秒浮点运算数(FLOPS)效率低下,尤其是在频繁的内存访问(如深度卷积)时。为了解决这一问题,提出了一种新的部分卷积(Partial Convolution,PConv),该方法通过减少冗余计算和内存访问来更高效地提取空间特征。基于 PConv,我们进一步提出了 FasterNet,这是一系列新的神经网络家族,在不牺牲各种视觉任务准确性的前提下,大幅提高了在各类设备上的运行速度。例如,在ImageNet-1k数据集上,FasterNet-T0在 GPU、CPU 和 ARM 处理器上的运行速度分别比MobileViT-XXS快2.8倍、3.3倍和2.4倍,同时精度提高了2.9%。FasterNet-L在GPU上的推理吞吐量提高了36%,在CPU上的计算时间减少了37%,达到了与 Swin-B 相当的83.5%的顶级准确率。
理论介绍
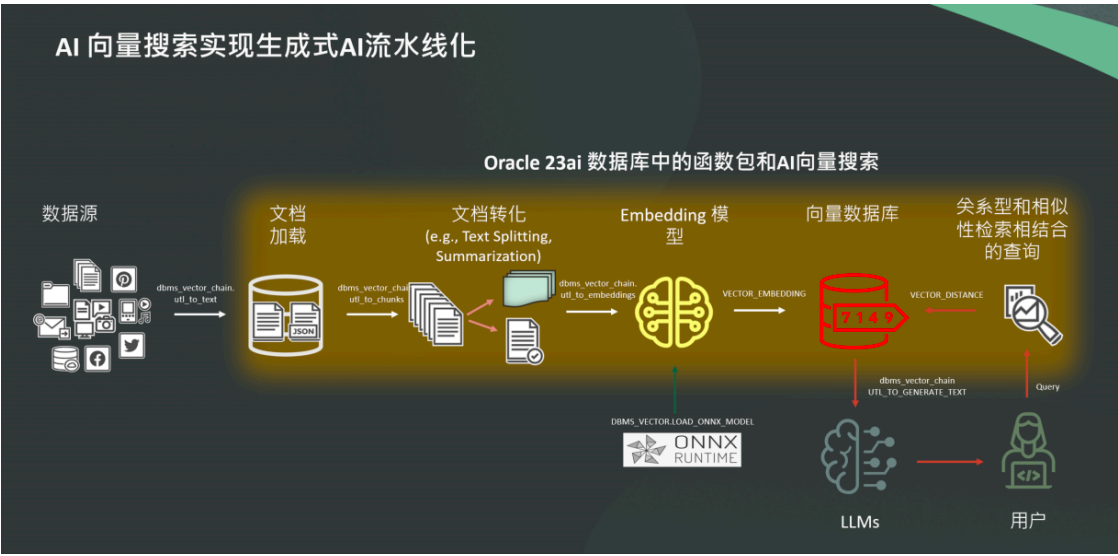
FasterNet 的整体架构由四个分层阶段组成,每个阶段包含一组 FasterNet模块,每个层次采用 PConv 来提取局部特征,同时通过 MLP 块来进行全局的信息处理,每个特征图不仅得到了更高效的局部感知,还能通过 MLP更好地学习全局上下文,并在前面加一个嵌入或合并层,最后三层用于特征分类。每个FasterNet 模块内部,一个 PConv 层后跟两个 PWConv 层,为了保持特征多样性并降低延迟,归一化和激活层仅在中间层之后进行,其中,PConv 是一种快速高效的卷积操作,通过仅对部分输入通道应用卷积滤波器,而保持其余通道不变,从而减少了计算量和内存访问。相比于常规卷积,PConv 具有更低的浮点运算次数(FLOPs),而相比深度卷积或分组卷积,PConv 的每秒浮点运算数(FLOPS)更高。FasterNet 架构如下图:

其中,深度卷积(DWConv&#x