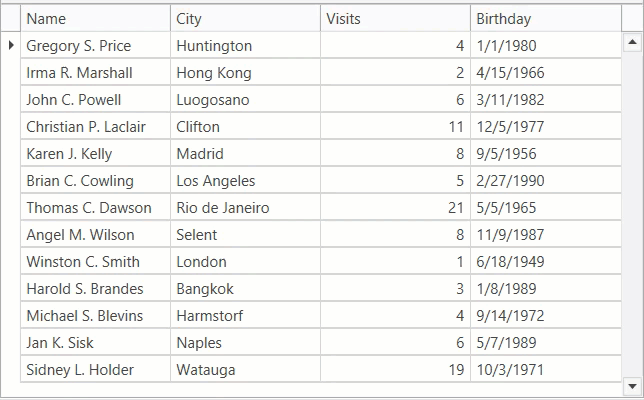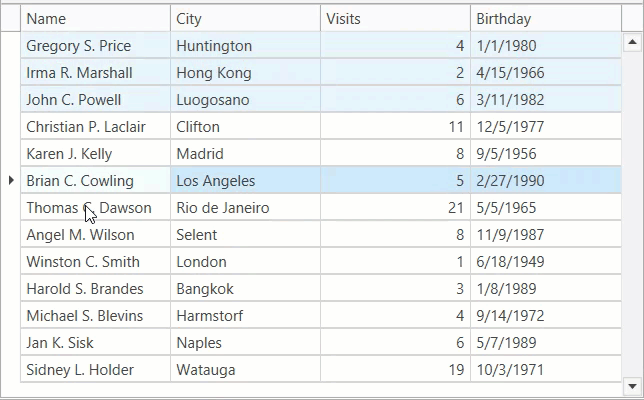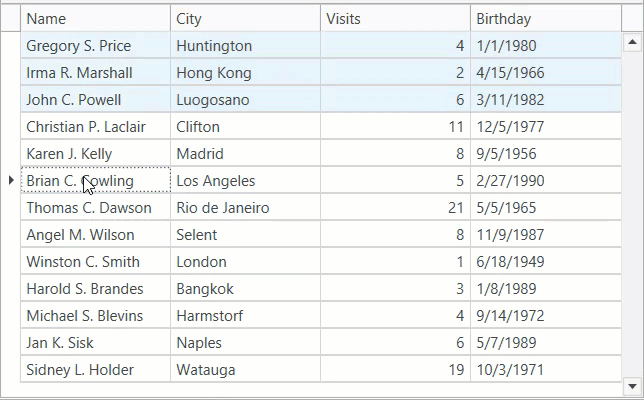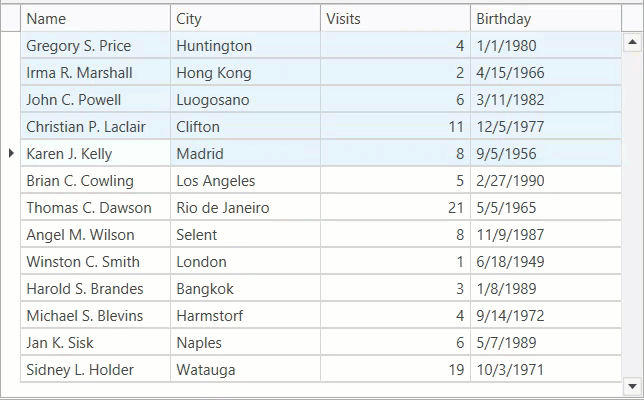
车牌检测与识别技术详解
车牌检测和识别(License Plate Recognition, LPR)是一项重要的计算机视觉任务,它在交通管理、安全监控以及智能门禁系统等多个领域都有着广泛的应用。随着深度学习技术的发展,LPR系统的准确性和鲁棒性得到了显著提升。本文将详细介绍一个基于传统图像处理技术和机器学习模型的车牌检测与识别项目的实现过程。
1. 图像预处理
- 原始图片输入:首先,系统接收一张包含车辆的彩色图像作为输入。
- 二值化:为了简化图像中的信息并突出车牌区域,通常会先将彩色图像转换为灰度图,然后使用自适应阈值或固定阈值方法进行二值化处理。这一步骤有助于去除背景噪声,使得后续处理更加容易。
- 边缘检测:利用Canny边缘检测算法等手段找到图像中所有物体的轮廓,特别是那些具有矩形形状的对象。
- 颜色空间转换及微调:考虑到不同国家和地区车牌的颜色标准可能有所不同,在HSV或其他颜色空间下对特定颜色范围内的像素点进行增强或抑制可以进一步提高车牌定位的准确性。

2. 车牌定位
经过上述步骤后,已经可以从图像中大致圈定出几个疑似车牌的位置了。接下来需要通过形态学操作如膨胀腐蚀来细化这些候选区域,并最终确定真正的车牌位置。常用的策略包括但不限于:
- 根据长宽比筛选符合条件的矩形框;
- 计算每个候选区域内的纹理复杂度或者字符密度等特征,剔除不符合要求的结果;
- 利用SVM等分类器直接判断该区域是否含有车牌。
一旦成功锁定车牌所在的具体坐标,就可以将其从原图中裁剪出来准备下一步处理。

3. 字符分割
获得单独的车牌图像之后,下一步是将其划分为单个字符单元以便于独立识别。一种有效的方法是根据水平投影直方图的变化规律来自动寻找字符间的分界线。具体来说,就是沿着垂直方向计算每一列黑色像素的数量形成一条曲线,然后依据这条曲线上波峰与波谷的位置变化来确定每个字符的大致边界。
4. 字符识别
对于每一个被分割出来的字符,接下来的任务就是正确地识别它们代表的实际含义。在这个项目里采用了支持向量机(SVM)作为主要的识别工具,分别训练两个不同的模型用于解决两类问题:
- 第一个SVM专门用来辨别省份简称,比如中国的各个省级行政区都有其独特的汉字缩写形式。
- 另外一个SVM则专注于字母数字组合部分的解析工作。
这两个SVM模型都需要事先准备好大量的标注数据集,并且通过适当的特征提取方法(例如HOG特征描述子)来表示每个样本。训练完成后,给定一个新的字符图像,模型能够输出最有可能对应的标签。

5. GUI界面开发与软件发布
最后一步是将整个流程整合进一个用户友好的图形界面应用程序当中。这里选择了Python下的PyQt5库来构建GUI,它提供了丰富的控件支持和良好的跨平台兼容性。主要功能包括:
- 文件导入/导出选项
- 实时视频流捕获与处理
- 结果展示窗口
- 参数调整面板等
此外,还可以考虑加入更多高级特性如批量处理、历史记录保存等功能以满足实际应用需求。完成所有开发工作后,可借助PyInstaller之类的工具将程序打包成独立可执行文件,方便部署到目标环境中运行。

总结
综上所述,虽然现代深度学习技术已经在很多方面超越了传统的图像处理方法,但对于某些特定场景下的车牌识别任务而言,结合两者的优势往往能取得更好的效果。本案例介绍了一种较为经典的解决方案框架,希望能够为相关领域的研究者提供一些参考价值。
最后
计算机视觉、图像处理、毕业辅导、作业帮助、代码获取
欢迎评论交流!





![[vulnhub] Prime 1](https://i-blog.csdnimg.cn/direct/b8e8cc8f549847fb9d9b18af89423380.png)