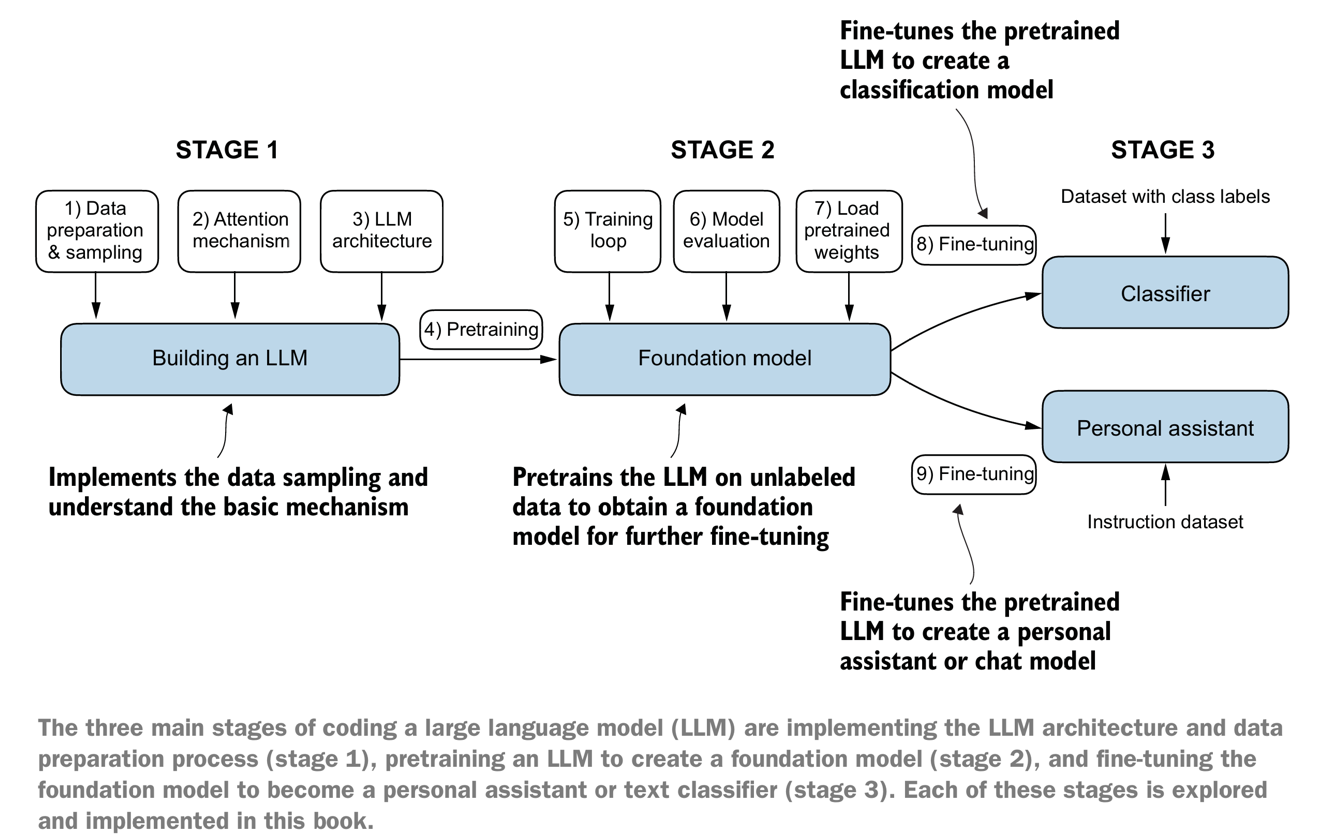
ElasticSearch的使用、Kibana和ES-Head可视化工具
- 一、ElasticSearch概述
- 1. ES
- 2.IK分词器
- 3. Kibana
- 4.Head
- 二、安装
- 1.ES安装
- 2. 配置跨域和IK分词器
- 3.Kibana安装
- 4. Head安装
- 三、常用操作
- 1. ES结构
- 2. ES操作
- 1. 索引的基本操作
- -创建索引
- -查看索引
- -修改索引
- -删除索引
- -特殊查看
- 2.文档的基本操作
- - 创建文档
- - 修改文档:修改指定的某一个字段
- - 查看文档数据
- - 删除文档
- 3. 复杂查询
- - 创建商品索引
- 1)模糊查询match。
- 2)逻辑查询(多条件查询 and or not)
- 3)结果过滤
- 4)字段过滤
- 5)排序:desc 降序 asc升序
- 6)分页查询
- 7)精确查询:term
- 8)高亮查询
一、ElasticSearch概述
1. ES

2.IK分词器
ES的插件,辅助为中文做分词操作。

3. Kibana
ES的开发工具,辅助操作ES。

4.Head
ES的管理工具,可视化工具,辅助操作ES。
二、安装
1.ES安装

- 拉取elasticsearch镜像
docker pull elasticsearch:7.6.2
- 使用docker容器创ES服务
注意:这里没有进行挂载,实际使用还是要进行挂载。
#-d:后台运行 9200是es默认端口 ES_JAVA_OPTS="-Xms64m -Xmx512m":设置内存范围的限制
sudo docker run -d --name es01 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.6.2

2. 配置跨域和IK分词器


-
在网上下载IK分词器

IK分词器与ES的版本对应

本文使用7.6.2版本,下载网址如下

-
把IK分词器传入到容器中
#./elasticsearch-analysis-ik-7.6.2.zip :IK分词器插件路径
#es01:/usr/share/elasticsearch/plugins/:移动到es01容器下的插件路径plugins下
sudo docker cp ./elasticsearch-analysis-ik-7.6.2.zip es01:/usr/share/elasticsearch/plugins/

- 进入容器配置插件
1)进入容器

2)进入config目录

3)进入elasticsearch.yml文件,进行配置

增加配置内容,:wq保存退出。
http.cors.enabled:true #允许跨域
http.cors.allow-origin: "*" #允许所有的来源

- 安装IK分词器插件
1)进入es01的容器,进入到存放插件的目录plugins中

2)创建文件夹ik,之后把插件解压到该文件夹

3)将压缩包移动到ik文件夹下

4)解压压缩包、

5)删除压缩包

- 配置完后重启容器

- 测试,检测es服务是否启动。或者直接网址访问。


3.Kibana安装
- 下载Kibana镜像
sudo docker pull kibana:7.6.2
- 创建Kibana容器
#ELASTICSEARCH_HOSTS=http://xx.xx.xx.xx:9200 配置ES的访问地址
#kibana 的端口是5601
sudo docker run --name kibana -e ELASTICSEARCH_HOSTS=http://xx.xx.xx.xx:9200 -p 5601:5601 -d kibana:7.6.2
- 访问网址127.0.0.1:5601

进入Try our sample data——Dev Tools

在这里编写请求,来查询数据

- IK分词器有两种划分:ik_smart和ik_max_word
- ik_smart:最少切分
英文会根据空格划分

- ik_max_word:最细粒度切分
注:这里写了三个请求,如果只发送一个请求,点击请求右边的三角符号

4. Head安装
- 下载镜像
sudo docker pull mobz/elasticsearch-head:5
- 搭建容器
# 默认端口是9100:9100
sudo docker run -d --name es_admin -p 9100:9100 mobz/elasticsearch-head:5
- 进入容器(注:pwd可以查看当前目录)

注:pwd可以查看当前目录

- 通过vim进入_site文件中的vendor.js中

没有vim的话进行下载

- 修改vendor.js内容
1) 跳转到指定行:按ESC键,输入:6888,回车,跳转到6888行
2)修改contentType内容如下。按i键进入插入模式。

3)跳转到7584行,同样修改contentType内容。:wq保存退出

-
退出后重启es_admin容器
-
访问网址127.0.0.1:9100

在”索引“可以查看到数据详情

三、常用操作
1. ES结构
- 索引:相当于mysql中的数据库
- 类型:相当于mysql中的表
- 文档:和mongoDB的文档概念一致数据
在ES中,可以有多个索引,每个类型可以有多个索引,每个索引可以有多个文档
2. ES操作

1. 索引的基本操作
-创建索引
1)在kibana中创建索引
mappings:映射数据

2)点击启动,显示以下信息表示成功创建了一个名为teset1的索引

3)用HEAD可视化查看。在索引和数据浏览中都可以看到test01这个索引

-查看索引
1)在kibana中编写查看索引

2)发送请求,返回结果如下

-修改索引
在发起一次请求即可

-删除索引

执行成功

此时在可视化工具中test1也被删除

-特殊查看
如查看基群的健康值

2.文档的基本操作
- 创建文档
用put方法,没有数据创建,有数据修改
test1:索引名
_doc:类型,固定写这个就行
1:指定id为1,不指定随机生成id

生成随机id写法参考:

执行如下:

此时用可视化工具可以查看到这条数据

- 修改文档:修改指定的某一个字段

执行结果如下

- 查看文档数据

执行结果如下:

- 删除文档
可以直接删除索引

3. 复杂查询
- 创建商品索引

查询结果如下

1)模糊查询match。
q(代表query)后面接字段名,并指定模糊查询条件
路由传参写法:

结构体写法:

返回结果如下

注意:match会用分词器进行解析
如:查询华为手机,也会查询出小米手机,华为手机匹配度得分_score要高一点

查询结果如下:

2)逻辑查询(多条件查询 and or not)
- must可以理解为and

查询结果如下

- should可以理解为or

查询结果如下:

- 取反

查询结果如下:

3)结果过滤
比较运算:大于,小于,等于,大于等于,小于等于
大于是gt,等于是eq,小于是lt,大于等于gte,小于等于lte

执行结果如下:

4)字段过滤

执行结果如下:返回结果的字段只有title和price

5)排序:desc 降序 asc升序

执行结果如下:

6)分页查询
from:从哪一页开始。可以理解为offset偏移量
size:展示条数
//偏移量计算参考
页数 偏移量 显示条数
1 0 10
2 10 10
3 20 10
page from size
计算公式:from =( page-1)*size

执行结果如下:value:2表示有两条数据

要查询第二页的数据,from改成1

7)精确查询:term

查询结果如下:

查询结果如下:

8)高亮查询
突出搜索内容,如在京东搜索"衬衫",标题会有颜色标红。


查询结果如下:此时查询出来的title全部被em标签包裹起来,所以只需要在前端增加css样式,对em标签包裹的数据设置颜色即可。但是这种使用场景可能会导致前端其他被em标签包裹的数据也会变成红色。那这个怎么解决呢?

这里我们使用自定义高亮来解决这个问题。

执行结果如下: