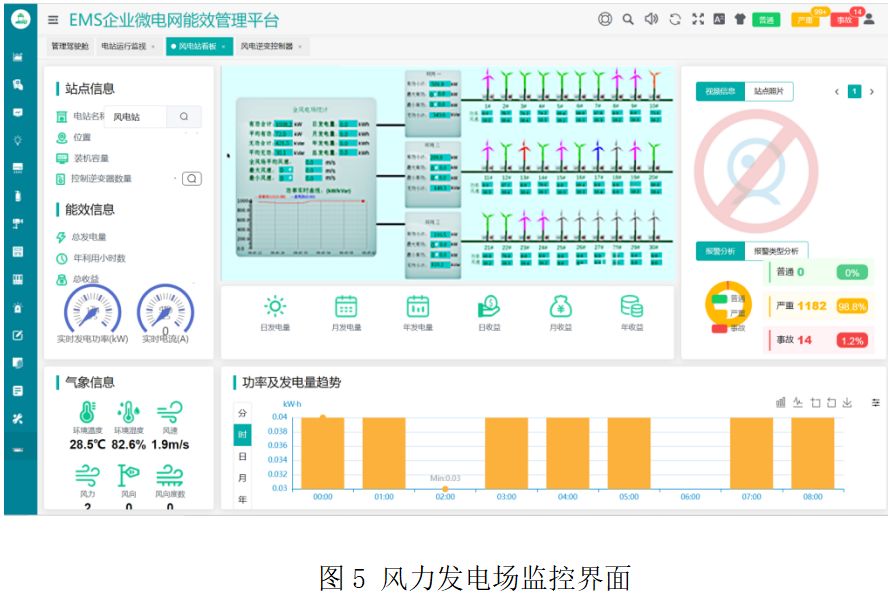
3.3 基础设施、扩展性和效率
我们描述了⽀持Llama 3 405B⼤规模预训练的硬件和基础设施,并讨论了⼏项优化措施,这些措施提⾼了训练效率。
3.3.1 训练基础设施
Llama 1和2模型在Meta的AI研究超级集群(Lee和Sengupta,2022)上进⾏了训练。随着我们进⼀步扩展,Llama 3的训练迁移到了Meta的⽣产集群(Lee等⼈,2024)。此设置优化了⽣产级别的可靠性,这对于我们扩⼤训练⾄关重要。

计算。Llama3 405B在⾼达16K的H100 GPU上进⾏训练,每个GPU运⾏在700W TDP下,配备80GB HBM3,使⽤Meta的Grand Teton AI服务器平台(Matt Bowman,2022)。每个服务器配备有⼋个GPU和两个CPU。在服务器内部,这⼋个GPU通过NVLink连接。使⽤MAST(Choudhury等⼈,2024),Meta的全球规模训练调度器,来安排训练作业。
存储。Tectonic(Pan等⼈,2021),Meta的通⽤分布式⽂件系统,⽤于为Llama 3预训练构建存储⽹络(Battey和Gupta,2024)。它提供了7,500个配备SSD的服务器上的240PB存储空间,并⽀持2TB/s的可持续吞吐量和7TB/s的峰值吞吐量。⼀个主要挑战是⽀持在短时期间饱和存储⽹络的⾼突发性检查点写操作。检查点保存每个GPU的模型状态,每个GPU的范围从1MB到4GB,⽤于恢复和调试。我们的⽬标是最⼩化检查点期间GPU的暂停时间,并增加检查点频率,以减少恢复后丢失的⼯作量。
⽹络。Llama 3 405B使⽤了基于Arista 7800和Minipack2开放计算项⽬OCP机架交换机的RDMA over Converged Ethernet (RoCE)⽹络。Llama 3系列中较⼩的模型使⽤Nvidia Quantum2 Infiniband⽹络进⾏训练。RoCE和Infiniband集群都在GPU之间利⽤400Gbps的互连。尽管这些集群的底层⽹络技术存在差异,但我们调整了它们,以便为这些⼤型训练⼯作负载提供等效的性能。由于我们完全拥有RoCE⽹络的设计,我们将更详细地阐述我们的RoCE⽹络。
• 网络拓扑。我们的基于RoCE的AI集群由24K GPU组成,通过三层Clos⽹络连接(Lee等⼈,2024)。在底层,每个机架托管16个GPU,分成两台服务器,并通过单个Minipack2机架顶部(ToR)交换机连接。在中层,192个这样的机架通过集群交换机连接,形成⼀个拥有3,072个GPU的pod,具有完整的双⼯带宽,确保没有过订。在顶层,同⼀数据中⼼⼤楼内的⼋个这样的pod通过聚合交换机连接,形成⼀个24K GPU的集群。然⽽,在聚合层的⽹络连接没有保持完整的双⼯带宽,⽽是有⼀个1:7的过订⽐率。我们的模型并⾏⽅法(⻅第3.3.2节)和训练作业调度器(Choudhury等⼈,2024)都针对⽹络拓扑进⾏了优化,旨在最⼩化跨pod的⽹络通信。
• 负载均衡。⼤型语⾔模型(LLM)训练产⽣的⽹络流量很⼤,这使得使⽤传统的如等价成本多路径(ECMP)路由⽅法在所有可⽤⽹络路径上进⾏负载均衡变得困难。为了应对这⼀挑战,我们采⽤了两种技术。⾸先,我们的集合库创建了16个⽹络流进⾏负载均衡。其次,我们增强的ECMP(E-ECMP)协议通过在RoCE数据包头部的额外字段上进⾏哈希处理,有效地在不同⽹络路径上平衡了这16个流。

• 拥塞控制。我们在主⼲⽹上使⽤了深度缓冲交换机(Gangidi等⼈,2024年),以适应由集合通信模式引起的瞬态拥塞和缓冲。这种设置有助于限制由慢服务器引起的持续拥塞和⽹络反压的影响,这在训练中很常⻅。最后,通过E-ECMP实现的更好的负载均衡显著降低了拥塞的可能性。有了这些优化,我们成功地运⾏了⼀个24K GPU集群,⽽⽆需使⽤传统的拥塞控制⽅法,如数据中⼼量化拥塞通(DCQCN)。
3.3.2 模型扩展的并⾏性
为了扩展我们最⼤模型的训练,我们采⽤了4D并⾏性⸺结合四种不同类型的并⾏⽅法来切分模型。
这种⽅法有效地在多个GPU之间分配计算,并确保每个GPU的模型参数、优化器状态、梯度和激活能够适应其HBM。我们在图5中展⽰了4D并⾏性的实现。它结合了张量并⾏性(TP;Krizhevsky等⼈(2012年);Shoeybi等⼈(2019年);Korthikanti等⼈(2023年))、流⽔线并⾏性(PP;Huang等⼈(2019年);Narayanan等⼈(2021年);Lamy-Poirier(2023年))、上下⽂并⾏性(CP;Liu等⼈(2023年))和数据并⾏性(DP;Rajbhandari等⼈(2020年);Ren等⼈(2021年);Zhao等⼈(2023年))。
张量并⾏性将个别权重张量分割成不同设备上的多个块。流⽔线并⾏性通过层将模型垂直划分为不同的阶段,以便不同的设备可以并⾏处理完整模型流⽔线的不同阶段。上下⽂并⾏性将输⼊上下⽂分割成段,减少了⾮常⻓的序列⻓度输⼊的内存瓶颈。我们使⽤的是完全分⽚的数据并⾏性(FSDP;Rajbhandari等⼈,2020年;Ren等⼈,2021年;Zhao等⼈,2023年),它在实现数据并⾏性的同时,对模型、优化器和梯度进⾏分⽚,该数据并⾏性在多个GPU上并⾏处理数据,并在每个训练步骤后同步。我们在Llama 3中使⽤FSDP对优化器状态和梯度进⾏分⽚,但对于模型分⽚,在前向计算后我们不重新分⽚,以避免在反向传递期间产⽣额外的全收集通信。
GPU利⽤率。通过对并⾏配置、硬件和软件的精⼼调整,我们实现了表4所⽰配置的BF16模型FLOPs利⽤率(MFU;Chowdhery等⼈(2023年))为38-43%。在16K GPU上,当DP=128时MFU略有下降⾄41%,⽽8K GPU上DP=64时为43%,这是由于在训练期间需要保持每个批次的全局标记数恒定,因此每个DP组的批量⼤⼩需要降低。
流⽔线并⾏性改进。我们在使⽤现有实现时遇到了⼏个挑战:
• 批量⼤⼩限制。当前实现对每个GPU⽀持的批量⼤⼩有限制,要求它可以被流⽔线阶段的数量整除。例如,在图6中的流⽔线并⾏性的深度优先调度(DFS)中(Narayanan等⼈,2021年),需要N = PP = 4,⽽⼴度优先调度(BFS;Lamy-Poirier(2023年))需要N = M,其中M是微批次的总数,N是同⼀阶段的前向或后向的连续微批次的数量。然⽽,预训练通常需要调整批量⼤⼩的灵活性。
• 内存不平衡。现有的流⽔线并⾏性实现导致资源消耗不平衡。第⼀阶段由于嵌⼊和热⾝微批次⽽消耗更多的内存。
• 计算不平衡。在模型的最后⼀层之后,我们需要计算输出和损失,使这个阶段成为执⾏延迟的瓶颈。

为解决这些问题,我们修改了流⽔线调度计划,如图6所⽰,该计划允许灵活设置N⸺在本例中N=5,可以在每个批次中运⾏任意数量的微批次。这允许我们执⾏:
(1) 当我们在⼤规模时有批量⼤⼩限制时,运⾏的微批次少于阶段数;或者(2) 运⾏更多的微批次以隐藏点对点通信,寻找DFS(深度优先调度)和BFS(⼴度优先调度)之间的最佳通信和内存效率的平衡点。为了平衡流⽔线,我们分别从第⼀和最后阶段各减少⼀个Transformer层。这意味着第⼀阶段的第⼀个模型块仅有嵌⼊层,⽽最后阶段的最后⼀个模型块仅有输出投影和损失计算。为了减少流⽔线泡沫,我们采⽤了交错调度(Narayanan等⼈,2021年),在⼀个流⽔线等级上使⽤V个流⽔线阶段。整体流⽔线泡沫⽐率是(PP−1)/V*M。
此外,我们在PP中采⽤异步点对点通信,这在⽂档掩码引⼊额外计算不平衡的情况下显著加快了训练速度。我们启⽤了TORCH_NCCL_AVOID_RECORD_STREAMS,以减少异步点对点通信的内存使⽤。
最后,为了减少内存成本,基于详细的内存分配分析,我们主动释放了未来计算中不会使⽤的张量,包括每个流⽔线阶段的输⼊和输出张量。通过这些优化,我们得以在不使⽤激活检查点的情况下对8K标记的Llama 3进⾏预训练。
⻓序列的上下⽂并⾏性。我们利⽤上下⽂并⾏性(CP)在扩展Llama 3的上下⽂⻓度时提⾼内存效率,并能够训练⻓达128K的极⻓序列。在CP中,我们跨序列维度进⾏分区,特别是我们将输⼊序列划分为2 × CP块,以便每个CP等级接收两个块以实现更好的负载平衡。第i个CP等级接收了第i个和第(2 × CP − 1 − i)个块。
与现有的在环状结构中重叠通信和计算的CP实现不同(Liu等⼈,2023年),我们的CP实现采⽤了基于all-gather的⽅法,我们⾸先all-gather关键(K)和值(V)张量,然后计算局部查询(Q)张量块的注意⼒输出。尽管all-gather通信延迟在关键路径上暴露出来,但我们仍然采⽤这种⽅法,主要有两个原因:
(1) 在基于all-gather的CP注意⼒中,⽀持不同类型的注意⼒掩码(如⽂档掩码)更容易、更灵活;
(2) 由于使⽤了GQA(Ainslie等⼈,2023年),通信的K和V张量⽐Q张量⼩得多,因此暴露的all-gather延迟很⼩。因此,注意⼒计算的时间复杂度⽐all-gather⼤⼀个数量级(O(S^2)与O(S),其中S表⽰全因果掩码中的序列⻓度),使all-gather的开销可以忽略不计。

⽹络感知的并⾏配置。并⾏维度的顺序[TP, CP, PP, DP]针对⽹络通信进⾏了优化。最内层的并⾏需要最⾼的⽹络带宽和最低的延迟,因此通常限制在同⼀个服务器内。最外层的并⾏可以跨越多跳⽹络,并应能容忍更⾼的⽹络延迟。因此,基于对⽹络带宽和延迟的要求,我们按照[TP, CP, PP, DP]的顺序放置并⾏维度。DP(即FSDP)是最外层的并⾏,因为它可以通过异步预取分⽚模型权重和减少梯度来容忍更⻓的⽹络延迟。在避免GPU内存溢出的同时,找到最⼩化通信开销的最佳并⾏配置是具有挑战
性的。我们开发了⼀个内存消耗估计器和性能预测⼯具,帮助我们探索各种并⾏配置,并有效预测整体训练性能和识别内存缺⼝。
数值稳定性。通过⽐较不同并⾏设置之间的训练损失,我们解决了⼏个影响训练稳定性的数值问题。
为确保训练收敛性,我们在多个微批次的反向计算中使⽤FP32梯度累积,并在FSDP中跨数据并⾏⼯作器使⽤FP32进⾏reduce-scatter梯度。对于在前向计算中多次使⽤的中间张量,例如视觉编码器的输出,反向梯度也以FP32累积。
3.3.3 集体通信
我们的Llama 3集体通信库是基于Nvidia的NCCL库的⼀个分⽀,称为NCCLX。NCCLX显著提⾼了NCCL的性能,特别是对于⾼延迟⽹络。回想⼀下,平⾏维度的顺序是[TP, CP, PP, DP],其中DP对应于FSDP。最外层的平⾏维度,PP和DP,可能通过多跳⽹络进⾏通信,延迟⾼达数⼗微秒。原始的NCCL集合体⸺FSDP中的all-gather和reduce-scatter,以及PP中的点对点⸺需要数据分块和分阶段数据复制。这种⽅法存在⼏个效率问题,
包括(1)需要在⽹络上交换⼤量的⼩控制消息以促进数据传输,
(2)额外的内存复制操作,以及(3)使⽤额外的GPU周期进⾏通信。对于Llama 3训练,我们通过调整分块和数据传输以适应我们的⽹络延迟来解决这些效率问题的⼀个⼦集,这些延迟在⼤型集群中可能⾼达数⼗微秒。我们还允许⼩控制消息以更⾼的优先级穿越我们的⽹络,特别是避免在深缓冲核⼼交换机中被阻塞。我们为未来Llama版本进⾏的持续⼯作涉及在NCCLX中进⾏更深⼊的更改,以全⾯解决上述所有问题。

3.3.4 可靠性和运营挑战
16K GPU训练的复杂性和潜在故障场景超过了我们运营的更⼤的CPU集群。此外,训练的同步性质使其对故障的容忍度较低⸺单个GPU故障可能需要重启整个作业。尽管存在这些挑战,对于Llama 3,我们在⽀持⾃动化集群维护(如固件和Linux内核升级(Vigraham和Leonhardi,2024年))的同时,实现了超过90%的有效训练时间,这导致⾄少每天有⼀次训练中断。有效训练时间衡量的是流逝时间内⽤于有⽤训练的时间。
在预训练的54天快照期间,我们经历了总共466次作业中断。其中,47次是计划内的中断,由于⾃动化维护操作,如固件升级或操作员启动的操作,如配置或数据集更新。其余419次是意外的中断,在表5中有分类。约78%的意外中断归因于确认的硬件问题,如GPU或主机组件故障,或疑似与硬件相关的问题,如静默数据损坏和计划外的单个主机维护事件。GPU问题是最⼤的类别,占所有意外问题的58.7%。尽管失败数量众多,但在这段时间内,仅三次需要重⼤⼿动⼲预,其余问题由⾃动化处理。
为了增加有效训练时间,我们减少了作业启动和检查点时间,并开发了快速诊断和问题解决⼯具。我们⼴泛使⽤PyTorch内置的NCCL⻜⾏记录器(Ansel等⼈,2024年),这是⼀个捕捉集体元数据和堆栈跟踪到环形缓冲区的功能,因此允许我们在⼤规模上快速诊断挂起和性能问题,特别是与NCCLX相关的。利⽤这个,我们有效地记录了每个通信事件和每次集体操作的持续时间,并且在NCCLX看⻔狗或⼼跳超时时⾃动转储跟踪数据。我们通过在线配置更改(Tang等⼈,2015年)根据需要在⽣产中选
择性地启⽤更多计算密集型的跟踪操作和元数据收集,⽆需代码发布或作业重启。
调试⼤规模训练中的问题由于我们⽹络中混合使⽤NVLink和RoCE⽽变得复杂。
NVLink上的数据传输通常通过由CUDA内核发出的加载/存储操作进⾏,远程GPU或NVLink连接的故障通常表现为CUDA内核内的加载/存储操作停滞,⽽没有返回清晰的错误代码。NCCLX通过与PyTorch的紧密共同设计,提⾼了故障检测和定位的速度和准确性,允许PyTorch访问NCCLX的内部状态并跟踪相关信息。虽然由于NVLink故障引起的停滞⽆法完全防⽌,但我们的系统监控通信库的状态,并在检测到此类停滞时⾃动超时。此外,NCCLX跟踪每个NCCLX通信的内核和⽹络活动,并提供失败的NCCLX集体的内部状态的快照,包括所有等级之间已完成和待定的数据传输。我们分析这些数据以调试NCCLX扩展问题。
有时,硬件问题可能导致仍在运⾏但缓慢的落后者,这很难检测。即使是单个落后者也可以减慢数千个其他GPU的速度,通常表现为通信功能正常但速度慢。我们开发了⼯具,以优先处理选定进程组中可能存在问题的通信。通过仅调查少数⼏个头号嫌疑对象,我们通常能够有效地识别落后者。
⼀个有趣的观察是环境因素对⼤规模训练性能的影响。对于Llama 3 405B,我们注意到基于⼀天中的时间的⽇间1-2%的吞吐量变化。这种波动是由于中午更⾼的温度影响GPU动态电压和频率缩放所致。
在训练期间,数万个GPU可能同时增加或减少功耗,例如,由于所有GPU等待检查点或集体通信完成,或整个训练作业的启动或关闭。当这种情况发⽣时,它可能导致数据中⼼的功耗瞬间波动数⼗兆⽡,考验电⽹的极限。随着我们为未来的、甚⾄更⼤的Llama模型扩展训练,这是我们⾯临的⼀个持续挑战。
3.4 训练配方
⽤于预训练Llama 3 405B的配⽅包括三个主要阶段:
(1)初始预训练,
(2)⻓上下⽂预训练,以及
(3)退⽕。
下⾯分别描述这三个阶段。我们使⽤类似的配⽅来预训练8B和70B模型。
3.4.1 初始预训练
我们使⽤余弦学习率计划对Llama 3 405B进⾏预训练,峰值学习率为8 × 10^−5,线性预热8,000
步,然后在1,200,000个训练步骤中衰减到8 × 10^−7。我们在训练初期使⽤较⼩的批量⼤⼩以提⾼训
练稳定性,并随后增加它以提⾼效率。具体来说,我们最初的批量⼤⼩为4M个标记,序列⻓度为4,096,然后在预训练了252M个标记后,将这些值加倍到8M个标记,序列⻓度为8,192。
我们在预训练了2.87T个标记后再次将批量⼤⼩加倍到16M。我们发现这种训练配⽅⾮常稳定:我们观察到的损失峰值很少,并且不需要⼲预来纠正模型训练发散。
调整数据混合。在训练期间,我们对预训练数据混合进⾏了⼏次调整,以提⾼模型在特定下游任务上的性能。特别是,我们在预训练期间增加了⾮英语数据的百分⽐,以提⾼Llama 3的多语⾔性能。我们还上采样数学数据以提⾼模型的数学推理性能,我们在预训练的后期增加了更多最新的⽹络数据以推进模型的知识截⽌⽇期,并且我们对后来被识别为质量较低的预训练数据⼦集进⾏了下采样。
3.4.2 长上下文预训练
在预训练的最后阶段,我们对⻓序列进⾏训练,以⽀持⾼达128K个标记的上下⽂窗⼝。我们之所以没有提前对⻓序列进⾏训练,是因为⾃注意⼒层的计算在序列⻓度上呈⼆次⽅增⻓。我们逐步增加⽀持的上下⽂⻓度,直到模型成功适应增加的上下⽂⻓度。我们通过测量(1)模型在短上下⽂评估上的性能是否完全恢复,以及(2)模型是否能够完美解决⻓达那个⻓度的“针尖上的针”任务来评估成功的适应。在Llama 3 405B预训练中,我们从最初的8K上下⽂窗⼝开始,逐步增加了上下⽂⻓度,经过六个阶段,最终达到128K上下⽂窗⼝。这个阶段的⻓上下⽂预训练使⽤了⼤约800B个训练标记。 
3.4.3 退火
在最后的40M个标记的预训练中,我们将学习率线性退⽕⾄0,同时保持上下⽂⻓度为128K个标记。在这个退⽕阶段,我们还调整了数据混合,以增加对极⾼质量数据源的采样;⻅第3.1.3节。最后,在退火期间,我们计算模型检查点(Polyak(1991年)平均)的平均值,以产⽣最终的预训练模型。
注:上述文章内容来自于LLama3.1的技术报告,本文是翻译文章!!!