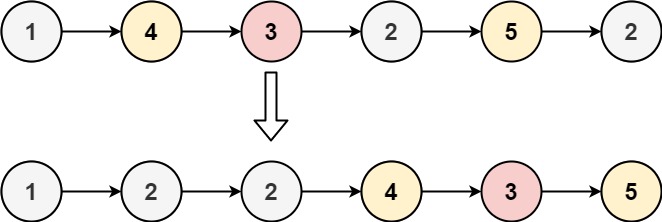
前言
继本文的 上篇 发表之后,没想到反响还挺好,看来大家在 JS 优化的问题上越来越注重“与国际接轨”了。一起来看本文的下篇,也是干货满满。
文章目录
- 6. Avoid large objects
- What the eff should I do about this?
- 7. Use eval
- 8. Use strings, carefully
- What the eff should I do about this?
- On strings complexity
- 9. Use specialization
- Branch prediction and branchless code
- 10. Data structures
- 11. Benchmarking
- 11.0 Start with the top
- 11.1 Avoid micro-benchmarks
- 11.2 Doubt your results
- 11.3 Pick your target
- 12. Profiling & tools
- 12.1 Browser gotchas
- 12.2 Sample vs structural profiling
- 12.3 The tools of the trade
- Final notes
6. Avoid large objects
As explained in section 2, engines use shapes to optimize objects. However, when the shape grows too large, the engine has no choice but to use a regular hashmap (like a Map object). And as we saw in section 5, cache misses decrease performance significantly. Hashmaps are prone to this because their data is usually randomly & evenly distributed over the memory region they occupy. Let’s see how it behaves with this map of some users indexed by their ID.
// setup:
const USERS_LENGTH = 1_000
// setup:
const byId = {}
Array.from({ length: USERS_LENGTH }).forEach((_, id) => {
byId[id] = { id, name: 'John'}
})
let _ = 0
// 1. [] access
Object.keys(byId).forEach(id => { _ += byId[id].id })
// 2. direct access
Object.values(byId).forEach(user => { _ += user.id })

And we can also observe how the performance keeps degrading as the object size grows:
// setup:
const USERS_LENGTH = 100_000

What the eff should I do about this?
As demonstrated above, avoid having to frequently index into large objects. Prefer turning the object into an array beforehand. Organizing your data to have the ID on the model can help, as you can use Object.values() and not have to refer to the key map to get the ID.
7. Use eval
Some javascript patterns are hard to optimize for engines, and by using eval() or its derivatives you can make those patterns disappear. In this example, we can observe how using eval() avoids the cost of creating an object with a dynamic object key:
// setup:
const key = 'requestId'
const values = Array.from({ length: 100_000 }).fill(42)
// 1. without eval
function createMessages(key, values) {
const messages = []
for (let i = 0; i < values.length; i++) {
messages.push({ [key]: values[i] })
}
return messages
}
createMessages(key, values)
// 2. with eval
function createMessages(key, values) {
const messages = []
const createMessage = new Function('value',
`return { ${JSON.stringify(key)}: value }`
)
for (let i = 0; i < values.length; i++) {
messages.push(createMessage(values[i]))
}
return messages
}
createMessages(key, values)

Another good use-case for eval could be to compile a filter predicate function where you discard the branches that you know will never be taken. In general, any function that is going to be run in a very hot loop is a good candidate for this kind of optimization.
Obviously the usual warnings about eval() apply: don’t trust user input, sanitize anything that gets passed into the eval()‘d code, and don’t create any XSS possibility. Also note that some environments don’t allow access to eval(), such as browser pages with a CSP.
8. Use strings, carefully
We’ve already seen above how strings are more expensive than they appear. Well I have kind of a good news/bad news situation here, which I’ll announce in the only logical order (bad first, good second): strings are more complex than they appear, but they can also be quite efficient used well.
String operations are a core part of JavaScript due to its context. To optimize string-heavy code, engines had to be creative. And by that I mean, they had to represent the String object with multiple string representation in C++, depending on the use case. There are two general cases you should worry about, because they hold true for V8 (the most common engine by far), and generally also in other engines.
First, strings concatenated with + don’t create a copy of the two input strings. The operation creates a pointer to each substring. If it was in typescript, it would be something like this:
class String {
abstract value(): char[] {}
}
class BytesString {
constructor(bytes: char[]) {
this.bytes = bytes
}
value() {
return this.bytes
}
}
class ConcatenatedString {
constructor(left: String, right: String) {
this.left = left
this.right = right
}
value() {
return [...this.left.value(), ...this.right.value()]
}
}
function concat(left, right) {
return new ConcatenatedString(left, right)
}
const first = new BytesString(['H', 'e', 'l', 'l', 'o', ' '])
const second = new BytesString(['w', 'o', 'r', 'l', 'd'])
// See ma, no array copies!
const message = concat(first, second)
Second, string slices also don’t need to create copies: they can simply point to a range in another string. To continue with the example above:
class SlicedString {
constructor(source: String, start: number, end: number) {
this.source = source
this.start = start
this.end = end
}
value() {
return this.source.value().slice(this.start, this.end)
}
}
function substring(source, start, end) {
return new SlicedString(source, start, end)
}
// This represents "He", but it still contains no array copies.
// It's a SlicedString to a ConcatenatedString to two BytesString
const firstTwoLetters = substring(message, 0, 2)
But here’s the issue: once you need to start mutating those bytes, that’s the moment you start paying copy costs. Let’s say we go back to our String class and try to add a .trimEnd method:
class String {
abstract value(): char[] {}
trimEnd() {
// `.value()` here might be calling
// our Sliced->Concatenated->2*Bytes string!
const bytes = this.value()
const result = bytes.slice()
while (result[result.length - 1] === ' ')
result.pop()
return new BytesString(result)
}
}
So let’s jump to an example where we compare using operations that use mutation versus only using concatenation:
// setup:
const classNames = ['primary', 'selected', 'active', 'medium']
// 1. mutation
const result =
classNames
.map(c => `button--${c}`)
.join(' ')
// 2. concatenation
const result =
classNames
.map(c => 'button--' + c)
.reduce((acc, c) => acc + ' ' + c, '')

What the eff should I do about this?
In general, try to avoid mutation for as long as possible. This includes methods such as .trim(), .replace(), etc. Consider how you can avoid those methods. In some engines, string templates can also be slower than +. In V8 at the moment it’s the case, but might not be in the future so as always, benchmark.
A note on SlicedString above, you should note that if a small substring to a very large string is alive in memory, it might prevent the garbage collector from collecting the large string! If you’re processing large texts and extracting small strings from it, you might be leaking large amounts of memory.
const large = Array.from({ length: 10_000 }).map(() => 'string').join('')
const small = large.slice(0, 50)
// ^ will keep `large` alive
The solution here is to use mutation methods to our advantage. If we use one of them on small, it will force a copy, and the old pointer to large will be lost:
// replace a token that doesn't exist
const small = small.replace('#'.repeat(small.length + 1), '')
For more details, see string.h on V8 or JSString.h on JavaScriptCore.
On strings complexity
I have skimmed very quickly over things, but there are a lot of implementation details that add complexity to strings. There are often minimum lengths for each of those string representations. For example a concatenated string might not be used for very small strings. Or sometimes there are limits, for example avoiding pointing to a substring of a substring. Reading the C++ files linked above gives a good overview of the implementation details, even if just reading the comments.
9. Use specialization
One important concept in performance optimization is specialization: adapting your logic to fit in the constraints of your particular use-case. This usually means figuring out what conditions are likely to be true for your case, and coding for those conditions.
Let’s say we are a merchant that sometimes needs to add tags to their product list. We know from experience that our tags are usually empty. Knowing that information, we can specialize our function for that case:
// setup:
const descriptions = ['apples', 'oranges', 'bananas', 'seven']
const someTags = {
apples: '::promotion::',
}
const noTags = {}
// Turn the products into a string, with their tags if applicable
function productsToString(description, tags) {
let result = ''
description.forEach(product => {
result += product
if (tags[product]) result += tags[product]
result += ', '
})
return result
}
// Specialize it now
function productsToStringSpecialized(description, tags) {
// We know that `tags` is likely to be empty, so we check
// once ahead of time, and then we can remove the `if` check
// from the inner loop
if (isEmpty(tags)) {
let result = ''
description.forEach(product => {
result += product + ', '
})
return result
} else {
let result = ''
description.forEach(product => {
result += product
if (tags[product]) result += tags[product]
result += ', '
})
return result
}
}
function isEmpty(o) { for (let _ in o) { return false } return true }
// 1. not specialized
for (let i = 0; i < 100; i++) {
productsToString(descriptions, someTags)
productsToString(descriptions, noTags)
productsToString(descriptions, noTags)
productsToString(descriptions, noTags)
productsToString(descriptions, noTags)
}
// 2. specialized
for (let i = 0; i < 100; i++) {
productsToStringSpecialized(descriptions, someTags)
productsToStringSpecialized(descriptions, noTags)
productsToStringSpecialized(descriptions, noTags)
productsToStringSpecialized(descriptions, noTags)
productsToStringSpecialized(descriptions, noTags)
}

This sort of optimization can give you moderate improvements, but those will add up. They are a nice addition to more crucial optimizations, like shapes and memory I/O. But note that specialization can turn against you if your conditions change, so be careful when applying this one.
Branch prediction and branchless code
Removing branches from your code can be incredibly efficient for performance. For more details on what a branch predictor is, read the classic Stack Overflow answer Why is processing a sorted array faster.
10. Data structures
I won’t go in details about data structures as they would require their own post. But be aware that using the incorrect data structures for your use-case can have a bigger impact than any of the optimizations above. I would suggest you to be familiar with the native ones like Map and Set, and to learn about linked lists, priority queues, trees (RB and B+) and tries.
But for a quick example, let’s compare how Array.includes does against Set.has for a small list:
// setup:
const userIds = Array.from({ length: 1_000 }).map((_, i) => i)
const adminIdsArray = userIds.slice(0, 10)
const adminIdsSet = new Set(adminIdsArray)
// 1. Array
let _ = 0
for (let i = 0; i < userIds.length; i++) {
if (adminIdsArray.includes(userIds[i])) { _ += 1 }
}
// 2. Set
let _ = 0
for (let i = 0; i < userIds.length; i++) {
if (adminIdsSet.has(userIds[i])) { _ += 1 }
}

As you can see, the data structure choice makes a very impactful difference.
As a real-world example, I had a case where we were able to reduce the runtime of a function from 5 seconds to 22 milliseconds by switching out an array with a linked list.
11. Benchmarking
I’ve left this section for the end for one reason: I needed to establish credibility with the fun sections above. Now that I (hopefully) have it, let me tell you that benchmarking is the most important part of optimization. Not only is it the most important, but it’s also hard. Even after 20 years of experience, I still sometimes create benchmarks that are flawed, or use the profiling tools incorrectly. So whatever you do, please put the most effort into benchmarking correctly.
11.0 Start with the top
Your priority should always be to optimize the function/section of code that makes up the biggest part of your runtime. If you spend time optimizing anything else than the top, you are wasting time.
11.1 Avoid micro-benchmarks
Run your code in production mode and base your optimizations on those observations. JS engines are very complex, and will often behave differently in micro-benchmarks than in real-world scenarios. For example, take this micro-benchmark:
const a = { type: 'div', count: 5, }
const b = { type: 'span', count: 10 }
function typeEquals(a, b) {
return a.type === b.type
}
for (let i = 0; i < 100_000; i++) {
typeEquals(a, b)
}
If you’ve payed attention sooner, you will realize that the engine will specialize the function for the shape { type: string, count: number }. But does that hold true in your real-world use-case? Are a and b always of that shape, or will you receive any kind of shape? If you receive many shapes in production, this function will behave differently then.
11.2 Doubt your results
If you’ve just optimized a function and it now runs 100x faster, doubt it. Try to disprove your results, try it in production mode, throw stuff at it. Similarly, doubt also your tools. The mere fact of observing a benchmark with devtools can modify its behavior.
11.3 Pick your target
Different engines will optimize certain patterns better or worse than others. You should benchmark for the engine(s) that are relevant to you, and prioritize which one is more important. Here’s a real-world example in Babel where improving V8 means decreasing JSC’s performance.
12. Profiling & tools
Various remarks about profiling and devtools.
12.1 Browser gotchas
If you’re profiling in the browser, make sure you use a clean and empty browser profile. I even use a separate browser for this. If you’re profiling and you have browser extensions enabled, they can mess up the measurements. React devtools in particular will substantially affect results, rendering code may appear slower than it appears in the mirror to your users.
12.2 Sample vs structural profiling
Browser profiling tools are sample-based profilers, which take a sample of your stack at regular intervals. This had a big disadvantage: very small but very frequent functions might be called between those samples, and might be very much underreported in the stack charts you’ll get. Use Firefox devtools with a custom sample interval or Chrome devtools with CPU throttling to mitigate this issue.
12.3 The tools of the trade
Beyond the regular browser devtools, it may help to be aware of these options:
- Chrome devtools have quite a few experimental flags that can help you figure out why things are slow. The style invalidation tracker is invaluable when you need to debug style/layout recalculations in the browser.
https://github.com/iamakulov/devtools-perf-features - The deoptexplorer-vscode extension allows you to load V8/chromium log files to understand when your code is triggering deoptimizations, such as when you pass different shapes to a function. You don’t need the extension to read log files, but it makes the experience much more pleasant.
https://github.com/microsoft/deoptexplorer-vscode - You can always compile the debug shell for each JS engine to understand more in details how it works. This allows you to run
perfand other low-level tools, and also to inspect the bytecode and machine code generated by each engine.
Example for V8 | Example for JSC | Example for SpiderMonkey (missing)
Final notes
Hope you learned some useful tricks. If you have any comments, corrections or questions, email in the footer. I’m always happy to receive feedback or questions from readers.
From: https://romgrk.com/posts/optimizing-javascript

![[Java并发编程] synchronized(含与ReentrantLock的区别)](https://i-blog.csdnimg.cn/direct/e71b6dbf13de416280461074513e1034.png)










![[JavaEE] UDP协议](https://i-blog.csdnimg.cn/direct/6dd00106404e4e14b88dac8d2fe220d0.png)