看到这句话的时候证明:此刻你我都在努力
加油陌生人

个人主页:Gu Gu Study
专栏:用Java学习数据结构系列
喜欢的一句话: 常常会回顾努力的自己,所以要为自己的努力留下足迹
喜欢的话可以点个赞谢谢了。
作者:小闭
优先级队列(Priority Queue)
优先级队列是一种抽象数据类型(ADT),它存储一组元素,每个元素都有一个与之关联的优先级。在优先级队列中,元素的访问顺序取决于它们的优先级,而不是它们被插入的顺序。优先级最高的元素总是最先被移除。
优先级队列的关键特性包括:
- 优先级规则:元素根据其优先级进行排序。通常有两种优先级规则:
-
- 最大优先级:最高优先级的元素(数值最大)最先被移除。
- 最小优先级:最高优先级的元素(数值最小)最先被移除。
- 插入操作:允许将新元素添加到队列中,并根据其优先级放置在正确的位置。
- 删除操作:移除当前优先级最高的元素。这通常被称为“弹出”(pop)操作。
- 查找操作:有时优先级队列支持查找当前优先级最高的元素,这被称为“查看”(peek)或“顶部”(top)操作。
- 动态性:优先级队列能够动态地插入和删除元素,而不仅仅是静态地存储数据。
优先级队列的常见应用:
- 任务调度:在操作系统中,优先级队列用于管理进程或线程的调度,其中每个任务都有一个优先级。
- 事件驱动模拟:在模拟中,事件根据其发生的时间点(优先级)被处理。
- 图算法:在图算法如迪杰斯特拉(Dijkstra)算法和普里姆(Prim)算法中,优先级队列用于选择下一个要处理的顶点或边。
- 数据压缩:例如霍夫曼编码,使用优先级队列来构建最优前缀编码。
- 网络流问题:在解决最大流问题时,优先级队列用于快速找到增广路径。
实现优先级队列的数据结构:
- 数组:简单但效率不高,因为插入和删除操作可能需要移动大量元素。
- 链表:可以快速插入和删除,但查找特定元素可能较慢。
- 二叉堆:最常用的实现方式,特别是二叉最小堆和二叉最大堆,它们提供了对数时间复杂度的插入和删除操作。
- 平衡二叉搜索树:如AVL树或红黑树,提供了对数时间的插入、删除和查找操作。
- 斐波那契堆:在某些操作(如删除最小元素)上非常高效,但插入和合并操作可能较慢。
优先级队列是一种非常有用的数据结构,它在需要根据元素的相对重要性进行操作的场景中非常有用。
但今天我们学习的是用二叉堆来实现优先级队列,主要了解其中的原理。
堆(Heap)
数据结构中的“堆”(Heap)是一种特殊的完全二叉树,它满足以下性质:
- 堆序性:在最大堆中,每个节点的值都不小于其子节点的值;在最小堆中,每个节点的值都不大于其子节点的值。
- 完全二叉树:除了最后一层外,每一层都被完全填满,并且最后一层的所有节点都尽可能地向左排列。
堆通常用于实现优先队列,它支持以下操作:
- 插入(Insert):在堆的末尾添加一个新元素,然后通过上浮(Percolate Up)操作来恢复堆的性质。
- 删除最大/最小元素(Extract Max/Min):移除最大(在最大堆中)或最小(在最小堆中)的元素,通常这个元素是堆的根节点。然后,将最后一个元素移动到根位置,并进行下沉(Percolate Down)操作来恢复堆的性质。
- 查找最大/最小元素(Get Max/Min):在最大堆中返回根节点的值,在最小堆中也是返回根节点的值。
- 堆排序(Heap Sort):通过构建一个最大堆,然后反复移除堆顶元素并重建堆,可以实现数组的原地排序。
堆可以用数组来实现,其中数组的索引与树中的位置有直接的对应关系。对于数组中的任意元素,其父节点和子节点的索引可以通过以下公式计算:
- 父节点索引:
(i-1)/2(其中i是当前节点的索引) - 左子节点索引:
2*i + 1 - 右子节点索引:
2*i + 2
堆的实现通常需要对数组进行操作,以确保在进行插入和删除操作时,能够快速地维护堆的性质。堆是一种非常高效的数据结构,特别是在需要频繁插入和删除最大或最小元素的场景中。
堆的两种储存方式
我们上面说过堆的堆序性,以及堆其实是一颗完全二叉树。那么下面就展示了堆的两种储存方式。大根堆和小根堆 。我们先看下图。
为什么使用完全二叉树呢?因为其实堆的储存结构是一个线性数组,如果使用非完全二叉树则就会比较浪费空间。

小根堆:其根节永远小于他的两个左右孩子。
大根堆:其根节永远大于他的两个左右孩子。
了解完了堆的储存方式后,我们就该模拟实现一下,来加深一下对堆的理解。
堆的模拟实现
首先要模拟堆的实现我们就要了解一下堆的调整方式。
堆有向上调整和向下调整。
那么我们怎么了解这两个调整呢?
顾名思义,向下调整就是在给定节点处往下调整,使这个节点往下形成的子树成为一个堆(大根堆或小根堆)
堆的向下调整
向下调整从给点的节点,不断往下调整,我这里假设是调整为小根堆。那么调整的过程就是看两个孩子节点是否比父节点小,如果小就交换一下两个节点的值就可以了。这里调整结束的条件就是child大于树的节点的个数,所以while的条件为(child<=len)。
代码实现)(小根堆为例):
public static void shiftDown(int[] array, int parent,int len) {
int child=2*parent+1; //父节点的左孩子
while(child<=len){
if(child+1<=len&&array[child+1]<array[child]){
child=child+1;
}
if(array[child]<array[parent]){
swap(array,child,parent);
}
parent=child;
child=2*child+1;
}
}
private static void swap(int[] array, int child, int parent) {
int tmp=array[child];
array[child]=array[parent];
array[parent]=tmp;
}使用向下调整建成小根堆
使用向下调整创建小根堆的步骤主要就是,找最后一个节点的父节点(即:(a.length-1-1)/2)开始,不断往前,每一个节点都进行一个向下调整,调整完毕后,就可以创建成一个小根堆了。如果要创建大根堆只需要改一下向下调整的比较部分即可。
import java.util.Arrays;
public class T {
public static void main(String[] args) {
int[] a={273,34,67,22,11,66,8,3};
for (int i = (a.length-1-1)/2; i >=0 ; i--) {
shiftDown(a,i,a.length-1);
}
System.out.println(Arrays.toString(a));
}
public static void shiftDown(int[] array, int parent,int len) {
int child=2*parent+1; //父节点的左孩子
while(child<=len){
if(child+1<=len&&array[child+1]<array[child]){
child=child+1;
}
if(array[child]<array[parent]){
swap(array,child,parent);
}
parent=child;
child=2*child+1;
}
}
private static void swap(int[] array, int child, int parent) {
int tmp=array[child];
array[child]=array[parent];
array[parent]=tmp;
}
}
注意:堆的向下调整主要是运用在建堆,即:给定你一个数组,直接将这个数组创建成大根堆或小根堆。
想要一个一个插入的话,我们是要用到向上调整的。
堆的向上调整
堆的向上调整与向下调整相似,只是调整方向是不断往上的,所以在我们插入数据时(通常是尾插)那么我们就得使用向上调整了,因为这样我们只需要调整这个节点就好了。如果我们向下调整的话,还是需要将每个节点进行调整。
代码实现(小根堆为例):
private static void swap(int[] array, int child, int parent) {
int tmp=array[child];
array[child]=array[parent];
array[parent]=tmp;
}
public static void shiftUp(int[] array, int child) {
int parent=(child-1)/2;
while(child>0){
if(array[child]<array[parent]){
swap(array,child,parent);
child=parent;
parent=(child-1)/2;
}else {
break;
}
}
}使用向上调整一个一个插入创建小根堆
我们随机生成一个随机数,在加入数组,然后在进行调整即可。这样就是逐一插入实现小根堆,大根堆同理。
private static void swap(int[] array, int child, int parent) {
int tmp=array[child];
array[child]=array[parent];
array[parent]=tmp;
}
public static void shiftUp(int[] array, int child) {
int parent=(child-1)/2;
while(child>0){
if(array[child]<array[parent]){
swap(array,child,parent);
child=parent;
parent=(child-1)/2;
}else {
break;
}
}
}
public static void main(String[] args) {
int[] arr=new int[10];
Random random=new Random();
for (int i = 0; i < 10; i++) {
int n= random.nextInt(100);
arr[i]=n;
shiftUp(arr,i);
}
System.out.println(Arrays.toString(arr));
}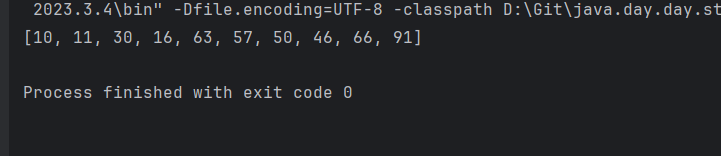
检验一下结果,确实是一个小根堆。
向下调整和向上调整的总结
向下调整:适用于给定一个数组,要将数组中的元素建成堆的形式,这时我们用向下调整的话是比较合适的,相比与向上调整是比较快的从时间复杂度上看。
向上调整:适用于要将数据一个一个插入,使其每次插入完成后还是堆的形式,这时因为数据通常是插入在数组尾端然后在进行调整。所以只需要调用向上调整一下为节点就可以,而这是向下调整做不到的。
模拟实现优先级队列的方法接口
如下:简单实现了offer,poll,peek方法。
offer:将数据进行尾插后,直接对该节点进行向下调整。
poll:我们将头节点数据,用另一个变量进行储存后,与最后一个节点进行调换位置然后进行一次i向下调整。
peek:查看根节点的数据。
注意:我们这里吧数组当作一颗完全二叉树,即数组的下标相当于层序遍历的顺序对应的那个节点。
public void offer(int e) {
array[size++] = e;
shiftUp(array,size - 1);
}
public int poll() {
int oldValue = array[0];
array[0] = array[--size];
shiftDown(array,0,size-1);
return oldValue;
}
public int peek() {
return array[0];
}以下是全部代码:
public class MyPriorityQueue {
private int[] array = new int[100];
private int size = 0;
public void shiftDown(int[] array, int parent, int len) {
int child = 2 * parent + 1; //父节点的左孩子
while (child <= len) {
if (child + 1 <= len && array[child + 1] < array[child]) {
child = child + 1;
}
if (array[child] < array[parent]) {
swap( child, parent);
}
parent = child;
child = 2 * child + 1;
}
}
private void swap( int child, int parent) {
int tmp = array[child];
array[child] = array[parent];
array[parent] = tmp;
}
public void shiftUp(int[] array, int child) {
int parent = (child - 1) / 2;
while (child > 0) {
if (array[child] < array[parent]) {
swap(child, parent);
child = parent;
parent = (child - 1) / 2;
} else {
break;
}
}
}
public void offer(int e) {
array[size++] = e;
shiftUp(array,size - 1);
}
public int poll() {
int oldValue = array[0];
array[0] = array[--size];
shiftDown(array,0,size-1);
return oldValue;
}
public int peek() {
return array[0];
}
public static void main(String[] args) {
MyPriorityQueue queue=new MyPriorityQueue();
queue.offer(1);
queue.offer(4);
queue.offer(33);
queue.offer(9);
queue.offer(14);
queue.offer(6);
for (int i = 0; i < queue.size; i++) {
System.out.print(queue.array[i]+" ");
}
System.out.println();
queue.poll();
for (int i = 0; i < queue.size; i++) {
System.out.print(queue.array[i]+" ");
}
}
}


















