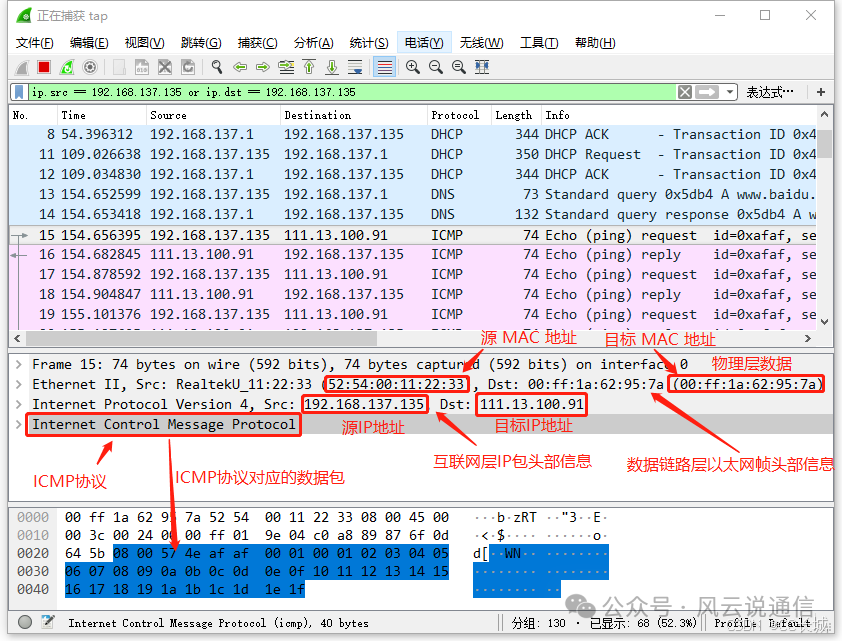
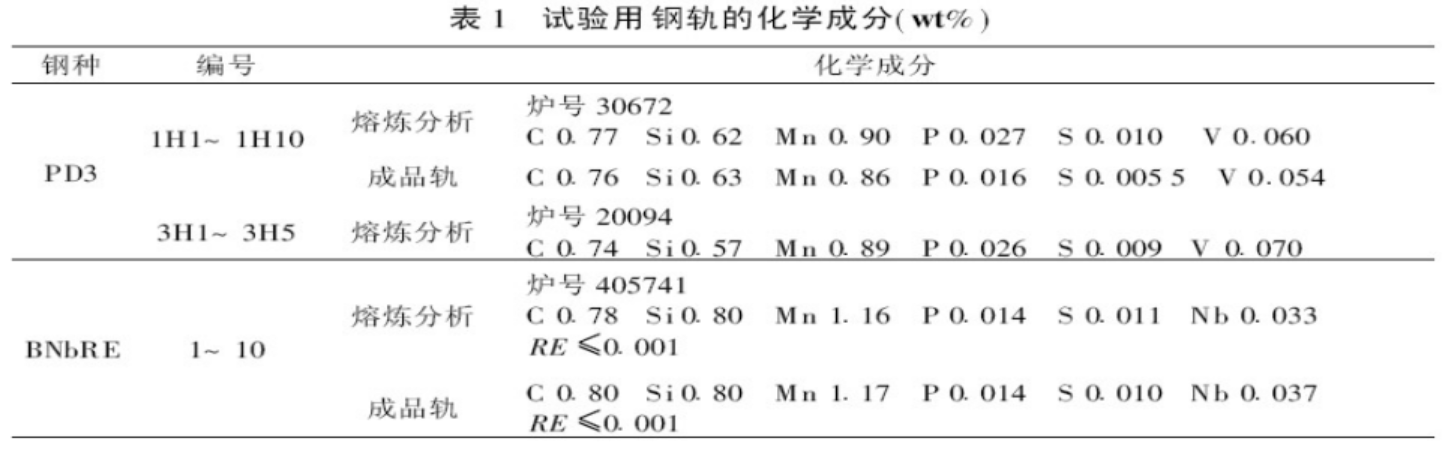
1. Vision Transformer (ViT)
Vision Transformer详解-CSDN博客![]() https://blog.csdn.net/qq_37541097/article/details/118242600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522F8BBAFBF-A4A1-4D38-9C0F-9A43B56AF6DB%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=F8BBAFBF-A4A1-4D38-9C0F-9A43B56AF6DB&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-1-118242600-null-null.142%5Ev100%5Econtrol&utm_term=Vision%20Transformer&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_37541097/article/details/118242600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522F8BBAFBF-A4A1-4D38-9C0F-9A43B56AF6DB%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=F8BBAFBF-A4A1-4D38-9C0F-9A43B56AF6DB&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-1-118242600-null-null.142%5Ev100%5Econtrol&utm_term=Vision%20Transformer&spm=1018.2226.3001.4187

ViT 是最早将 Transformer 应用于图像任务的模型,最先由 Google 提出。它采用了与 NLP 中 Transformer 类似的结构,但做了一些调整以适应图像数据。
主要特点:
- Patch Embedding:ViT 将输入图像分割为固定大小的非重叠小块(patch),例如 16×16,然后将每个 patch 展开为一个向量,类似于 NLP 中的词嵌入。
- Positional Encoding:由于 Transformer 没有卷积层,因此缺乏对图像中空间信息的直接感知,ViT 使用位置编码来保留图像的空间信息。
- 全局注意力机制:ViT 的注意力机制是全局的,允许任意两个 patch 之间进行信息交换,但由于每个 patch 都参与到计算中,所以当图像尺寸较大时,计算成本非常高。
优点:
- 全局信息捕捉能力强:全局注意力机制使 ViT 能够很好地捕捉到图像中的长距离依赖关系。
- 适合大规模数据:ViT 在大规模数据集(如 ImageNet-21k)上训练时表现优异,能够充分利用数据。
缺点:
- 对数据需求较高:ViT 在小规模数据集上表现较差,因为其需要大量数据才能学到有效的表示。
- 计算成本高:全局注意力机制带来了较高的计算和内存开销。
2. Swin Transformer
Swin-Transformer网络结构详解_swin transformer-CSDN博客![]() https://blog.csdn.net/qq_37541097/article/details/121119988?ops_request_misc=%257B%2522request%255Fid%2522%253A%25223B8A1942-84DA-4C42-ACEC-D87B5803F3AE%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=3B8A1942-84DA-4C42-ACEC-D87B5803F3AE&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121119988-null-null.142%5Ev100%5Econtrol&utm_term=Swin%20Transformer&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_37541097/article/details/121119988?ops_request_misc=%257B%2522request%255Fid%2522%253A%25223B8A1942-84DA-4C42-ACEC-D87B5803F3AE%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=3B8A1942-84DA-4C42-ACEC-D87B5803F3AE&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121119988-null-null.142%5Ev100%5Econtrol&utm_term=Swin%20Transformer&spm=1018.2226.3001.4187

主要特点:
- 层级结构:Swin Transformer 通过构建分层的特征图结构(类似于 CNN 的金字塔结构),从而可以捕捉到不同尺度的特征。其输入从高分辨率开始,逐步降低分辨率,增加通道数,类似于 ResNet 等卷积神经网络。
- 滑动窗口注意力机制:为了降低全局注意力的计算开销,Swin Transformer 在每一层仅在局部的滑动窗口内计算自注意力。每个窗口内的 patch 之间进行注意力计算,窗口大小固定。
- 跨窗口交互:在后续的层次中,通过移位窗口机制,可以让不同窗口之间也进行交互,提升全局信息的融合能力。
优点:
- 高效的局部注意力机制:滑动窗口和移位窗口机制大大降低了计算复杂度,使得 Swin Transformer 在计算上更加高效。
- 强大的特征层次化表示:通过构建层级结构,Swin Transformer 在处理不同尺度的物体时表现更好。
- 良好的泛化能力:Swin Transformer 在多个视觉任务(如图像分类、目标检测、语义分割)中表现出色。
缺点:
- 注意力依然局限于局部:虽然 Swin Transformer 引入了跨窗口交互机制,但在某一层中,注意力机制依然主要局限于局部范围,全局信息的捕捉依赖于深层网络。
3. Focal Transformer

Focal Transformer 是一种在 Swin Transformer 的基础上进一步改进的模型,它通过引入多尺度的注意力机制来更好地捕捉全局和局部信息。这种方法在注意力计算时结合了细粒度的局部信息和粗粒度的全局信息,旨在平衡精度和效率。
主要特点:
- 多尺度注意力:Focal Transformer 的注意力机制融合了不同尺度的信息。在小范围内(局部),使用高分辨率的细粒度注意力;在较大范围内(全局),使用低分辨率的粗粒度注意力。这种设计使得模型既能关注到局部的细节,又能捕捉到全局的长距离依赖。
- 渐进式注意力范围:Focal Transformer 不仅局限于固定窗口,还通过多个层次逐渐扩大注意力范围,确保模型能够从局部信息逐步扩展到全局信息。
- 灵活的层次化结构:与 Swin Transformer 类似,Focal Transformer 也构建了一个层次化的结构,通过逐层降低分辨率、增加通道数来捕捉多尺度特征。
优点:
- 平衡局部和全局信息:通过多尺度注意力机制,Focal Transformer 在保持局部细节的同时,能更有效地捕捉全局信息。
- 计算效率较高:虽然引入了多尺度注意力,但这种机制比全局注意力的计算效率更高,能够在较大的特征图上运行得更快。
- 表现更稳定:Focal Transformer 在小型和大型数据集上都有不错的表现,不像 ViT 需要极大规模的数据集来进行训练。
缺点:
- 架构相对复杂:与 ViT 或 Swin Transformer 相比,Focal Transformer 的多尺度注意力设计引入了更多复杂的计算模块,难以直接适用于极端高效的模型设计。