- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
一、我的环境
1.语言环境:Python 3.9
2.编译器:Pycharm
3.深度学习环境:TensorFlow 2.10.0
二、GPU设置
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")三、导入数据
data_dir = "./data/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:",image_count)
#图片总数为:1200四、数据预处理
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./data/train/",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./data/test/",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)class_names = train_ds.class_names
print(class_names)运行结果:
['Dark', 'Green', 'Light', 'Medium']五、可视化图片
plt.figure(figsize=(10, 4)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(10):
ax = plt.subplot(2, 5, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()运行结果:

再次检查数据:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break运行结果:
(32, 224, 224, 3)
(32,)六、配置数据集
- shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
- prefetch():预取数据,加速运行
- cache():将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))七、自建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()
运行结果:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 4) 16388
=================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
_________________________________________________________________八、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])九、训练模型
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)运行结果:
Epoch 1/20
30/30 [==============================] - 38s 592ms/step - loss: 1.3814 - accuracy: 0.2573 - val_loss: 1.3019 - val_accuracy: 0.3083
Epoch 2/20
30/30 [==============================] - 15s 486ms/step - loss: 1.0376 - accuracy: 0.4719 - val_loss: 0.6470 - val_accuracy: 0.7458
Epoch 3/20
30/30 [==============================] - 14s 475ms/step - loss: 0.6289 - accuracy: 0.6542 - val_loss: 0.4882 - val_accuracy: 0.7500
Epoch 4/20
30/30 [==============================] - 15s 485ms/step - loss: 0.4762 - accuracy: 0.7979 - val_loss: 1.0989 - val_accuracy: 0.8000
Epoch 5/20
30/30 [==============================] - 14s 479ms/step - loss: 0.6664 - accuracy: 0.7260 - val_loss: 0.5444 - val_accuracy: 0.7750
Epoch 6/20
30/30 [==============================] - 14s 474ms/step - loss: 0.3893 - accuracy: 0.8448 - val_loss: 0.2358 - val_accuracy: 0.8875
Epoch 7/20
30/30 [==============================] - 14s 476ms/step - loss: 0.3163 - accuracy: 0.8969 - val_loss: 0.3107 - val_accuracy: 0.8667
Epoch 8/20
30/30 [==============================] - 14s 474ms/step - loss: 0.2634 - accuracy: 0.9062 - val_loss: 0.1829 - val_accuracy: 0.9333
Epoch 9/20
30/30 [==============================] - 14s 476ms/step - loss: 0.1136 - accuracy: 0.9646 - val_loss: 0.1342 - val_accuracy: 0.9458
Epoch 10/20
30/30 [==============================] - 14s 477ms/step - loss: 0.0828 - accuracy: 0.9760 - val_loss: 0.0664 - val_accuracy: 0.9833
Epoch 11/20
30/30 [==============================] - 14s 476ms/step - loss: 0.0683 - accuracy: 0.9729 - val_loss: 0.2063 - val_accuracy: 0.9458
Epoch 12/20
30/30 [==============================] - 14s 473ms/step - loss: 0.0537 - accuracy: 0.9823 - val_loss: 0.0288 - val_accuracy: 0.9917
Epoch 13/20
30/30 [==============================] - 14s 472ms/step - loss: 0.0404 - accuracy: 0.9865 - val_loss: 0.2180 - val_accuracy: 0.9458
Epoch 14/20
30/30 [==============================] - 14s 472ms/step - loss: 0.0382 - accuracy: 0.9917 - val_loss: 0.0738 - val_accuracy: 0.9750
Epoch 15/20
30/30 [==============================] - 14s 474ms/step - loss: 0.0152 - accuracy: 0.9969 - val_loss: 0.0499 - val_accuracy: 0.9750
Epoch 16/20
30/30 [==============================] - 15s 485ms/step - loss: 0.3555 - accuracy: 0.9167 - val_loss: 0.0507 - val_accuracy: 0.9875
Epoch 17/20
30/30 [==============================] - 15s 485ms/step - loss: 0.1555 - accuracy: 0.9552 - val_loss: 0.1155 - val_accuracy: 0.9667
Epoch 18/20
30/30 [==============================] - 15s 489ms/step - loss: 0.0767 - accuracy: 0.9688 - val_loss: 0.0613 - val_accuracy: 0.9875
Epoch 19/20
30/30 [==============================] - 15s 482ms/step - loss: 0.0432 - accuracy: 0.9812 - val_loss: 0.0915 - val_accuracy: 0.9750
Epoch 20/20
30/30 [==============================] - 14s 475ms/step - loss: 0.0367 - accuracy: 0.9906 - val_loss: 0.0337 - val_accuracy: 0.9833十、模型评估
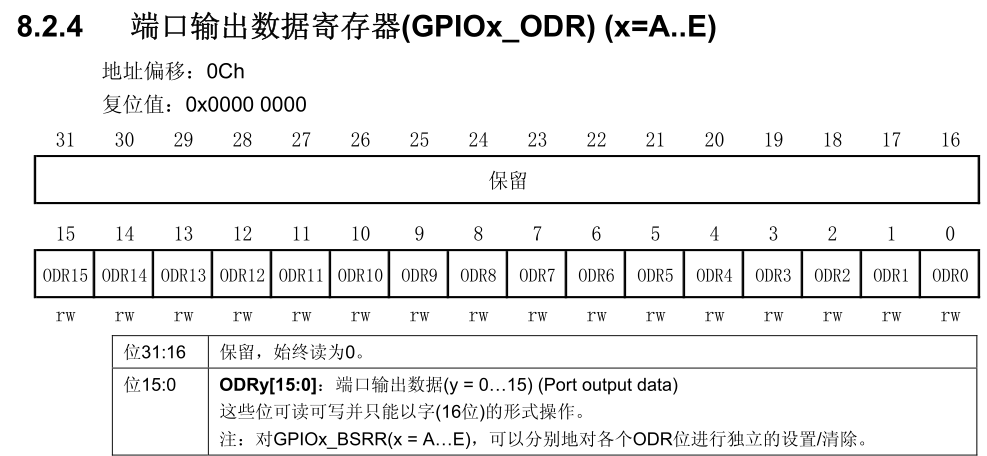
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
全局平均池化代替全连接层
- 极大的减少了网络的参数量(原始网络中全连接层参数量占到整个网络参数总量的80%作用)
- 相当于在网络结构上做正则,防止模型发生过拟合
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
predictions (Dense) (None, 4) 2052
=================================================================
Total params: 14,716,740
Trainable params: 14,716,740
Non-trainable params: 0
_________________________________________________________________Epoch 1/20
30/30 [==============================] - 36s 561ms/step - loss: 1.3824 - accuracy: 0.2552 - val_loss: 1.3368 - val_accuracy: 0.2125
Epoch 2/20
30/30 [==============================] - 14s 451ms/step - loss: 1.2286 - accuracy: 0.3667 - val_loss: 0.9773 - val_accuracy: 0.5500
Epoch 3/20
30/30 [==============================] - 14s 452ms/step - loss: 0.8348 - accuracy: 0.6021 - val_loss: 0.7338 - val_accuracy: 0.6625
Epoch 4/20
30/30 [==============================] - 14s 450ms/step - loss: 0.6489 - accuracy: 0.7333 - val_loss: 0.8191 - val_accuracy: 0.6542
Epoch 5/20
30/30 [==============================] - 14s 451ms/step - loss: 0.6889 - accuracy: 0.7188 - val_loss: 0.4738 - val_accuracy: 0.8167
Epoch 6/20
30/30 [==============================] - 14s 452ms/step - loss: 0.3798 - accuracy: 0.8479 - val_loss: 0.3068 - val_accuracy: 0.8667
Epoch 7/20
30/30 [==============================] - 14s 453ms/step - loss: 0.3275 - accuracy: 0.8906 - val_loss: 0.2464 - val_accuracy: 0.9000
Epoch 8/20
30/30 [==============================] - 14s 460ms/step - loss: 0.4658 - accuracy: 0.8271 - val_loss: 0.6661 - val_accuracy: 0.7500
Epoch 9/20
30/30 [==============================] - 14s 462ms/step - loss: 0.2678 - accuracy: 0.9031 - val_loss: 0.2194 - val_accuracy: 0.9208
Epoch 10/20
30/30 [==============================] - 14s 456ms/step - loss: 0.2523 - accuracy: 0.9187 - val_loss: 0.2138 - val_accuracy: 0.9250
Epoch 11/20
30/30 [==============================] - 14s 460ms/step - loss: 0.1870 - accuracy: 0.9354 - val_loss: 0.2064 - val_accuracy: 0.9125
Epoch 12/20
30/30 [==============================] - 14s 456ms/step - loss: 0.2718 - accuracy: 0.9135 - val_loss: 0.6631 - val_accuracy: 0.7500
Epoch 13/20
30/30 [==============================] - 14s 458ms/step - loss: 0.3490 - accuracy: 0.8740 - val_loss: 0.1596 - val_accuracy: 0.9458
Epoch 14/20
30/30 [==============================] - 14s 463ms/step - loss: 0.1525 - accuracy: 0.9563 - val_loss: 0.1226 - val_accuracy: 0.9625
Epoch 15/20
30/30 [==============================] - 14s 454ms/step - loss: 0.1136 - accuracy: 0.9656 - val_loss: 0.2463 - val_accuracy: 0.8958
Epoch 16/20
30/30 [==============================] - 14s 453ms/step - loss: 0.0945 - accuracy: 0.9646 - val_loss: 0.2166 - val_accuracy: 0.9250
Epoch 17/20
30/30 [==============================] - 14s 453ms/step - loss: 0.1903 - accuracy: 0.9333 - val_loss: 0.0848 - val_accuracy: 0.9625
Epoch 18/20
30/30 [==============================] - 14s 455ms/step - loss: 0.1039 - accuracy: 0.9729 - val_loss: 0.1146 - val_accuracy: 0.9542
Epoch 19/20
30/30 [==============================] - 14s 453ms/step - loss: 0.0801 - accuracy: 0.9781 - val_loss: 0.0763 - val_accuracy: 0.9708
Epoch 20/20
30/30 [==============================] - 14s 453ms/step - loss: 0.0769 - accuracy: 0.9750 - val_loss: 0.0492 - val_accuracy: 0.9708十一、总结
本周通过tenserflow框架创建VGG16网络模型进行猴痘病识别学习,学习如何搭建VGG16网络模型,学习在不影响准确率的前提下轻量化模型;通过使用全局平均池化代替全连接层,极大的减少了网络的参数量。





![[Matplotlib教程] 02 折线图、柱状图、散点图教程](https://img-blog.csdnimg.cn/img_convert/eb0d2849d0b92c7e744e3d7d2bdf29bb.png)