AI算法岗面试八股面经【超全整理】
- 概率论【AI算法岗面试八股面经【超全整理】——概率论】
- 信息论【AI算法岗面试八股面经【超全整理】——信息论】
- 机器学习【AI算法岗面试八股面经【超全整理】——机器学习】
- 深度学习
- CV
- NLP
目录
- 1、激活函数
- 2、Softmax函数及求导
- 3、优化器
1、激活函数
激活函数特征:
- 非线性:激活函数满足非线性时,才不会被单层网络替代,神经网络才有意义
- 可微性:优化器大多数是用梯度下降法更新梯度,如果不可微的话,就不能求导,也不能更新参数
- 单调性:激活函数是单调的,能够保证网络的损失函数是凸函数,更容易收敛
1、Sigmoid函数
f
(
x
)
=
1
1
+
e
−
x
f(x)=\frac{1}{1+e^{-x}}
f(x)=1+e−x1

该函数的导数为:
f
′
(
x
)
=
e
−
x
(
1
+
e
−
x
)
2
=
f
(
x
)
(
1
−
f
(
x
)
)
{f}'(x)=\frac{e^{-x}}{(1+e^{-x})^2}=f(x)(1-f(x))
f′(x)=(1+e−x)2e−x=f(x)(1−f(x))
导数的值在(0,0.25)之间
Sigmoid函数是二分类算法,尤其是逻辑回归算法中的常用激活函数,主要有以下几个特点:
- 能够将自变量的值全部缩放到(0,1)之间
- 当x无穷大的时候,函数值趋近于1;当x无穷小的时候,趋近于0。相当于对输入进行了归一化操作
- 连续可导,0点,导函数的值最大,并且两边逐渐减小
缺点:
- X在无穷大或者负无穷小的时候,导数(梯度)为0,即出现了梯度弥散现象(所谓梯度弥散就是梯度值越来越小)
- 导数的值在(0,0.25)之间,在多层神经网络中,我们需要对输出层到输入层逐层进行链式求导。这样就导致多个0到0.25之间的小数相乘,造成了结果取0,梯度消失
- Sigmoid函数存在幂运算,计算复杂度大,训练时间长
2、Tanh函数
f
(
x
)
=
t
a
n
h
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
f(x)=tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}
f(x)=tanh(x)=ex+e−xex−e−x
导数为:
f
′
(
x
)
=
1
−
(
e
x
−
e
−
x
e
x
+
e
−
x
)
2
=
1
−
t
a
n
h
(
x
)
2
{f}'(x)=1-(\frac{e^x-e^{-x}}{e^x+e^{-x}})^2=1-{tanh(x)}^2
f′(x)=1−(ex+e−xex−e−x)2=1−tanh(x)2
梯度(导数)的取值在(0, 1]之间

特点:
- Tanh函数输出满足0均值
- 当输入较大或者较小时,输出的值变化很小,导致导函数几乎为0,也就是梯度很小,从而不利于W、b的更新
- 梯度(导数)的取值在(0, 1]之间,最大梯度为1,能够保证梯度在变化过程中不消减,缓解了Sigmoid函数梯度消失的问题;但是取值过大或者过小,仍存在梯度消失
- 同样地函数本身存在幂运算,计算量大
3、ReLU函数
f
(
x
)
=
R
e
L
U
(
x
)
=
m
a
x
(
x
,
0
)
=
s
i
g
n
(
x
)
=
{
0
x <=0
x
x>0
f(x)=ReLU(x)=max(x,0)=sign(x)=\begin{cases} 0& \text{x <=0}\\x& \text{x>0} \end{cases}
f(x)=ReLU(x)=max(x,0)=sign(x)={0xx <=0x>0

导数:
f
′
(
x
)
=
{
0
x <=0
1
x>0
{f}'(x)=\begin{cases} 0& \text{x <=0}\\1& \text{x>0} \end{cases}
f′(x)={01x <=0x>0
特点:
- 函数本身在输入大于0的时候,输出逐渐增加,这样梯度值也一直存在,从而避免了梯度的饱和:正区间解决梯度消失问题
- 函数本身是线性函数,比Sigmoid或者Tanh函数要计算速度快;同时函数的收敛速度要大于Sigmoid或者Tanh函数
- 函数的输出不是以0为均值,收敛慢
- Dead ReLU问题:在负输入部分,输入的值为0,从而梯度为0,导致参数无法更新,造成神经元死亡;在实际处理中,我们可以减少过多的负数特征进入网络
4、Leaky ReLU问题
在小于0的部分引入一个斜率,使得小于0的取值不再是0(通常a的值为0.01左右)
f
(
x
)
=
{
a
⋅
x
x <=0
x
x>0
f(x)=\begin{cases} a \cdot x& \text{x <=0}\\x& \text{x>0} \end{cases}
f(x)={a⋅xxx <=0x>0

导数:
f
′
(
x
)
=
{
a
x <=0
1
x>0
{f}'(x)=\begin{cases} a& \text{x <=0}\\1& \text{x>0} \end{cases}
f′(x)={a1x <=0x>0
特点:
- 具有和ReLU完全相同的特点,而且不会造成Dead ReLU问题
- 函数本身的取值在负无穷到正无穷;负区间梯度也存在,从而避免了梯度消失。
- 但是实际运用中,尚未完全证明Leaky ReLU总是比ReLU更好
2、Softmax函数及求导
Softmax函数又称归一化指数函数,是基于Sigmoid二分类函数在多分类任务上的推广,在多分类网络中,常用Softmax作为最后一层进行分类。它将一个包含任意实数的K维向量(K是类别数量)映射为一个概率分布,每个类别的预测值都在0到1之间,所有类别的概率总和为1。Softmax函数的作用是将原始得分转换为概率值,使得模型的输出更符合实际的概率分布。
函数公式:
S
i
=
e
a
i
∑
K
=
1
K
e
a
k
S_i=\frac{e^{a_i}}{\sum_{K=1}^K{e^{a_k}}}
Si=∑K=1Keakeai
其中,
a
a
a是输入向量,上述公式表示第
i
i
i个类别的输出概率
Softmax可以使正样本(正数)的结果趋近于1,使负样本(负数)的结果趋近于0;且样本的绝对值越大,两极化越明显。
函数求导分类讨论:
当
i
=
j
i=j
i=j时:
∂
s
i
∂
a
j
=
e
a
i
∑
−
e
a
i
e
a
j
∑
2
=
s
i
−
s
i
s
j
\frac{\partial s_i}{\partial a_j} = \frac{e^{a_i}\sum-e^{a_i}e^{a_j}}{\sum^2}=s_i-s_is_j
∂aj∂si=∑2eai∑−eaieaj=si−sisj
当
i
≠
j
i\neq j
i=j时:
∂
s
i
∂
a
j
=
0
−
e
a
i
e
a
j
∑
2
=
−
s
i
s
j
\frac{\partial s_i}{\partial a_j} = \frac{0-e^{a_i}e^{a_j}}{\sum^2}=-s_is_j
∂aj∂si=∑20−eaieaj=−sisj
3、优化器
在深度学习中,优化器(optimizer)是一种用于调整神经网络模型参数以最小化损失函数的算法。优化器的目标是分局输入数据和期望的输出标签来调整模型的权重和偏置,使得模型能够更好地拟合训练数据并在未见过的数据上表现良好。
1、BGD(Batch Gradient Descent)
在更新参数时使用所有样本进行更新,假设样本综述为N:
θ
(
t
+
1
)
=
θ
(
t
)
−
α
⋅
1
N
∑
i
=
1
N
∇
θ
J
(
θ
i
(
t
)
)
\theta ^{(t+1)} = \theta^{(t)}-\alpha \cdot \frac{1}{N}\sum_{i=1}^N\nabla_\theta J(\theta_i^{(t)})
θ(t+1)=θ(t)−α⋅N1i=1∑N∇θJ(θi(t))
其中,
θ
(
t
)
\theta^{(t)}
θ(t)为第t次迭代时的参数值,
α
\alpha
α为学习率,
∇
θ
J
(
θ
i
(
t
)
)
\nabla_\theta J(\theta_i^{(t)})
∇θJ(θi(t))为损失函数
J
(
θ
)
J(\theta)
J(θ)关于模型参数
θ
\theta
θ的梯度。
BGD得到的是一个全局最优解,但是每迭代一步,都要用到训练集的所有数据,如果样本数巨大,那上述公式迭代起来则非常耗时,模型训练速度很慢。
2、SGD(随机梯度下降)
更新参数时使用随机选取的一个样本来进行更新。
θ
(
t
+
1
)
=
θ
(
t
)
−
∇
θ
J
(
θ
i
(
t
)
)
\theta ^{(t+1)} = \theta^{(t)}-\nabla_\theta J(\theta_i^{(t)})
θ(t+1)=θ(t)−∇θJ(θi(t))
SGD的优点是实现简单、效率高,缺点是收敛速度慢,容易陷入局部最小值。
3、MDGD(Mini Batch梯度下降)
介于批梯度下降和随机梯度下降之间,每次更新参数时使用b个样本。
θ
(
t
+
1
)
=
θ
(
t
)
−
α
⋅
1
b
∑
i
=
1
b
∇
θ
J
(
θ
i
(
t
)
)
\theta ^{(t+1)} = \theta^{(t)}-\alpha \cdot \frac{1}{b}\sum_{i=1}^b\nabla_\theta J(\theta_i^{(t)})
θ(t+1)=θ(t)−α⋅b1i=1∑b∇θJ(θi(t))
训练过程比较稳定;BGD可以找到局部最优解,不一定是全局最优解;若损失函数为凸函数,则BGD所求解一定为全局最优解。
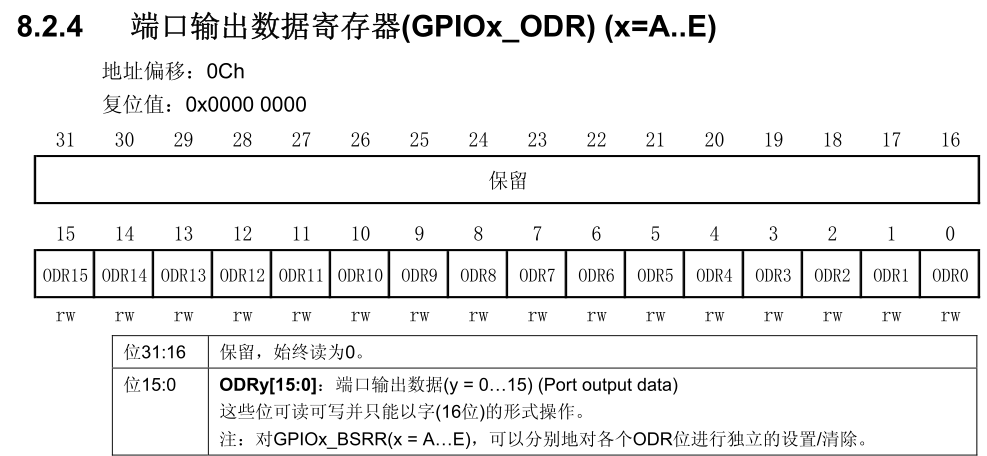
4、AdaGrad(Adaptive Gradient,自适应梯度优化器/自适应学习率优化器)
AdaGrad优点是可以自适应学习率。该优化算法在较为平缓处学习速率达,有比较高的学习效率,在陡峭处学习率小,在一定程度上可以避免越过极小值。


![[Matplotlib教程] 02 折线图、柱状图、散点图教程](https://img-blog.csdnimg.cn/img_convert/eb0d2849d0b92c7e744e3d7d2bdf29bb.png)