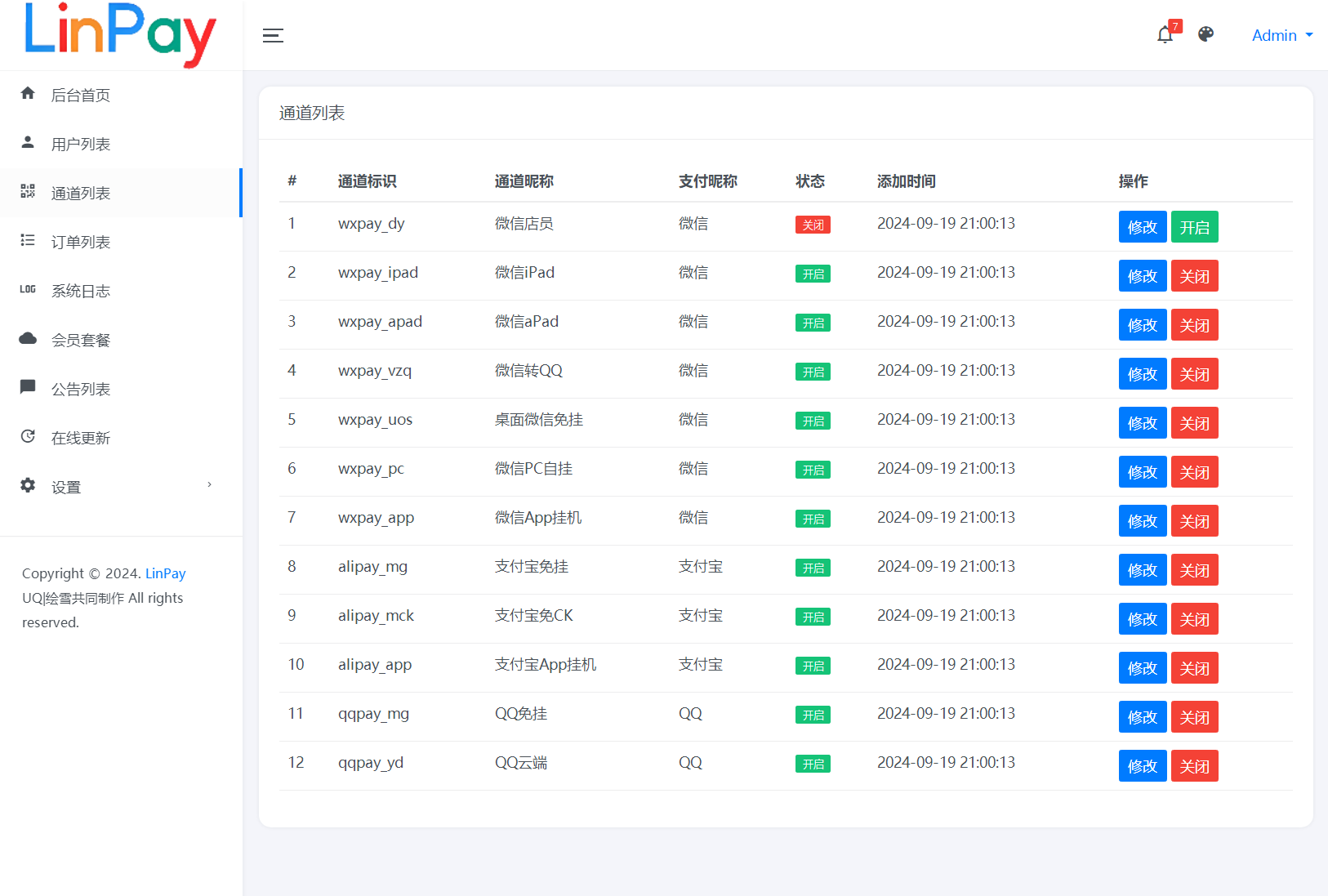
目录
环形缓冲区(Ring Buffer)简介
为什么选择环形缓冲区?
代码解析
1. 头文件与类型定义
1.1 头文件保护符
1.2 包含必要的标准库
1.3 类型定义
2. 环形缓冲区结构体
2.1 结构体成员解释
3. 辅助宏与内联函数
3.1 min 宏
3.2 is_power_of_two 内联函数
3.3 roundup_power_of_two 内联函数
4. 环形缓冲区的基本操作
4.1 创建新缓冲区
4.2 获取缓冲区长度
4.3 释放缓冲区
4.4 添加数据到缓冲区
4.5 从缓冲区移除数据
4.6 清空缓冲区的一部分数据
4.7 在缓冲区中搜索特定字符串
4.8 获取写入缓冲区的可写指针
5. 其他辅助函数
5.1 判断缓冲区是否为空
5.2 判断缓冲区是否已满
5.3 获取缓冲区中剩余的空间
6. 代码中的关键概念与实现
6.1 环形地址计算
6.2 缓冲区大小为2的幂次方
6.3 双指针机制
7. 综合应用
7.1 在用户态缓存区中的应用
7.2 处理生产者与消费者速度不匹配
7.3 结合之前的内容
8. 总结
环形缓冲区(Ring Buffer)简介
环形缓冲区是一种高效的数据结构,广泛应用于生产者-消费者模型中。在网络通信中,尤其是用户态缓存区中,环形缓冲区通过循环使用固定大小的内存区域,减少数据移动和内存管理开销,提升数据传输效率。
为什么选择环形缓冲区?
- 减少数据移动:数据在缓冲区中循环写入和读取,避免了频繁的数据拷贝操作。
- 高效缓存管理:适用于高并发场景,能够快速响应数据的读写请求。
- 简化内存管理:固定大小的缓冲区结构简化了内存分配和释放。
代码解析
让我们逐步解析环形缓冲区代码,理解其各个部分的功能和实现细节。
1. 头文件与类型定义
#ifndef _ringbuffer_h
#define _ringbuffer_h
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// #include <limits.h> // for uint_max
#include <stdint.h>
#include <unistd.h>
typedef struct ringbuffer_s buffer_t;
buffer_t * buffer_new(uint32_t sz);
uint32_t buffer_len(buffer_t *r);
void buffer_free(buffer_t *r);
int buffer_add(buffer_t *r, const void *data, uint32_t sz);
int buffer_remove(buffer_t *r, void *data, uint32_t sz);
int buffer_drain(buffer_t *r, uint32_t sz);
int buffer_search(buffer_t *r, const char* sep, const int seplen);
uint8_t * buffer_write_atmost(buffer_t *r);
#endif
1.1 头文件保护符
#ifndef _ringbuffer_h
#define _ringbuffer_h
...
#endif
- 作用:防止头文件被多次包含,避免重复定义错误。
1.2 包含必要的标准库
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// #include <limits.h> // for uint_max
#include <stdint.h>
#include <unistd.h>
- 标准库:提供了内存管理(
malloc、free)、字符串操作(memcpy)、固定宽度整数类型(uint32_t、uint8_t)等功能。
1.3 类型定义
typedef struct ringbuffer_s buffer_t;
- 作用:为
struct ringbuffer_s定义一个别名buffer_t,简化后续代码的书写。
2. 环形缓冲区结构体
struct ringbuffer_s {
uint32_t size;
uint32_t tail;
uint32_t head;
uint8_t * buf;
};
2.1 结构体成员解释
-
size(uint32_t):缓冲区的总大小,以字节为单位。通常为2的幂次方,便于使用位运算实现环形效果。 -
tail(uint32_t):指向缓冲区的写入位置。每次添加数据时,tail会递增。 -
head(uint32_t):指向缓冲区的读取位置。每次移除数据时,head会递增。 -
buf(uint8_t *):指向实际数据存储区的指针。数据以字节形式存储。
3. 辅助宏与内联函数
#define min(lth, rth) ((lth)<(rth)?(lth):(rth))
static inline int is_power_of_two(uint32_t num) {
if (num < 2) return 0;
return (num & (num - 1)) == 0;
}
static inline uint32_t roundup_power_of_two(uint32_t num) {
if (num == 0) return 2;
int i = 0;
for (; num != 0; i++)
num >>= 1;
return 1U << i;
}
3.1 min 宏
#define min(lth, rth) ((lth)<(rth)?(lth):(rth))
- 作用:返回两个值中的较小者,简化代码中的条件判断。
3.2 is_power_of_two 内联函数
static inline int is_power_of_two(uint32_t num) {
if (num < 2) return 0;
return (num & (num - 1)) == 0;
}
- 作用:判断一个数是否为2的幂次方。
- 原理:2的幂次方数在二进制中只有一个1,其减1后所有位都会变为1,按位与结果为0。
3.3 roundup_power_of_two 内联函数
static inline uint32_t roundup_power_of_two(uint32_t num) {
if (num == 0) return 2;
int i = 0;
for (; num != 0; i++)
num >>= 1;
return 1U << i;
}
- 作用:将一个数向上舍入到最近的2的幂次方。
- 实现:通过不断右移操作,计算出需要的位数,然后使用位移生成对应的2的幂次方数。
4. 环形缓冲区的基本操作
4.1 创建新缓冲区
buffer_t * buffer_new(uint32_t sz) {
if (!is_power_of_two(sz)) sz = roundup_power_of_two(sz);
buffer_t * buf = (buffer_t *)malloc(sizeof(buffer_t) + sz);
if (!buf) {
return NULL;
}
buf->size = sz;
buf->head = buf->tail = 0;
buf->buf = (uint8_t *)(buf + 1);
return buf;
}
- 功能:分配并初始化一个新的环形缓冲区。
- 步骤:
- 检查传入的大小
sz是否为2的幂次方。如果不是,则向上舍入到最近的2的幂次方数。 - 分配内存:
sizeof(buffer_t) + sz。buffer_t结构体和实际数据存储区buf一起分配。 - 初始化结构体成员:
size:设置为调整后的大小sz。head和tail:初始化为0,表示缓冲区为空。buf:指向结构体之后的内存区域,即实际的数据存储区。
- 检查传入的大小
4.2 获取缓冲区长度
uint32_t buffer_len(buffer_t *r) {
return rb_len(r);
}
static uint32_t
rb_len(buffer_t *r) {
return r->tail - r->head;
}
- 功能:返回缓冲区中当前存储的数据长度。
- 实现:通过
tail - head计算当前缓冲区中有效数据的字节数。
4.3 释放缓冲区
void buffer_free(buffer_t *r) {
free(r);
r = NULL;
}
- 功能:释放之前分配的缓冲区内存。
- 注意:设置指针为
NULL只是为了防止悬挂指针,但在函数外部无效。
4.4 添加数据到缓冲区
int buffer_add(buffer_t *r, const void *data, uint32_t sz) {
if (sz > rb_remain(r)) {
return -1;
}
uint32_t i;
i = min(sz, r->size - (r->tail & (r->size - 1)));
memcpy(r->buf + (r->tail & (r->size - 1)), data, i);
memcpy(r->buf, data+i, sz-i);
r->tail += sz;
return 0;
}
static uint32_t
rb_remain(buffer_t *r) {
return r->size - r->tail + r->head;
}
- 功能:将数据添加到缓冲区中。
- 步骤:
- 检查剩余空间:
- 使用
rb_remain(r)计算缓冲区中剩余的可用空间。 - 如果要添加的数据大小
sz超过剩余空间,返回错误-1。
- 使用
- 计算可写入的字节数
i:- 使用
min(sz, r->size - (r->tail & (r->size - 1)))计算可以连续写入的最大字节数,避免跨越缓冲区末尾。
- 使用
- 数据拷贝:
- 第一部分:将前
i字节的数据拷贝到缓冲区当前位置。 - 第二部分:如果有剩余的数据(
sz - i),将其从缓冲区的起始位置开始拷贝,形成环形。
- 第一部分:将前
- 更新
tail:将tail指针增加sz,标记新数据的结束位置。 - 返回成功:返回
0表示数据添加成功。
- 检查剩余空间:
4.5 从缓冲区移除数据
int buffer_remove(buffer_t *r, void *data, uint32_t sz) {
assert(!rb_isempty(r));
uint32_t i;
sz = min(sz, r->tail - r->head);
i = min(sz, r->size - (r->head & (r->size - 1)));
memcpy(data, r->buf+(r->head & (r->size - 1)), i);
memcpy(data+i, r->buf, sz-i);
r->head += sz;
return sz;
}
static uint32_t
rb_isempty(buffer_t *r) {
return r->head == r->tail;
}
- 功能:从缓冲区中移除并读取数据。
- 步骤:
- 断言缓冲区不为空:使用
assert(!rb_isempty(r))确保缓冲区中有数据可读。 - 调整读取大小:将
sz限制为缓冲区中实际存储的数据量r->tail - r->head。 - 计算可连续读取的字节数
i:- 使用
min(sz, r->size - (r->head & (r->size - 1)))计算可以连续读取的最大字节数,避免跨越缓冲区末尾。
- 使用
- 数据拷贝:
- 第一部分:将前
i字节的数据从缓冲区当前位置拷贝到目标缓冲区。 - 第二部分:如果有剩余的数据(
sz - i),将其从缓冲区的起始位置开始拷贝。
- 第一部分:将前
- 更新
head:将head指针增加sz,标记数据的读取位置。 - 返回读取的字节数:返回实际读取的数据大小
sz。
- 断言缓冲区不为空:使用
4.6 清空缓冲区的一部分数据
int buffer_drain(buffer_t *r, uint32_t sz) {
if (sz > rb_len(r))
sz = rb_len(r);
r->head += sz;
return sz;
}
- 功能:从缓冲区中清除
sz字节的数据,而不读取到用户空间。 - 步骤:
- 调整清除大小:将
sz限制为缓冲区中实际存储的数据量rb_len(r)。 - 更新
head:将head指针增加sz,标记数据的清除位置。 - 返回清除的字节数:返回实际清除的数据大小
sz。
- 调整清除大小:将
4.7 在缓冲区中搜索特定字符串
int buffer_search(buffer_t *r, const char* sep, const int seplen) {
int i;
for (i = 0; i <= rb_len(r)-seplen; i++) {
int pos = (r->head + i) & (r->size - 1);
if (pos + seplen > r->size) {
if (memcmp(r->buf+pos, sep, r->size-pos))
return 0;
if (memcmp(r->buf, sep+r->size-pos, pos+seplen-r->size) == 0) {
return i+seplen;
}
}
if (memcmp(r->buf+pos, sep, seplen) == 0) {
return i+seplen;
}
}
return 0;
}
- 功能:在缓冲区中搜索特定的分隔符
sep,用于界定数据包的边界(如协议解析)。 - 步骤:
- 遍历缓冲区:从
head开始,逐个字节检查是否匹配sep。 - 计算当前检查的位置
pos:使用(r->head + i) & (r->size - 1)实现环形地址计算。 - 处理跨越缓冲区末尾的情况:
- 如果
pos + seplen > r->size,表示分隔符跨越缓冲区末尾,需要分两部分比较。 - 第一部分:比较从
pos到缓冲区末尾的部分。 - 第二部分:比较从缓冲区起始位置到剩余长度的部分。
- 如果
- 匹配成功:如果找到匹配的分隔符,返回分隔符的位置(偏移量
i + seplen)。 - 未找到匹配:返回
0,表示未找到。
- 遍历缓冲区:从
4.8 获取写入缓冲区的可写指针
uint8_t * buffer_write_atmost(buffer_t *r) {
uint32_t rpos = r->head & (r->size - 1);
uint32_t wpos = r->tail & (r->size - 1);
if (wpos < rpos) {
uint8_t* temp = (uint8_t *)malloc(r->size * sizeof(uint8_t));
memcpy(temp, r->buf+rpos, r->size - rpos);
memcpy(temp+r->size-rpos, r->buf, wpos);
free(r->buf);
r->buf = temp;
return r->buf;
}
return r->buf + rpos;
}
- 功能:获取当前缓冲区中可写入数据的位置指针,最多可写入的字节数。
- 步骤:
- 计算读取和写入位置:
rpos:head指针在缓冲区中的当前位置。wpos:tail指针在缓冲区中的当前位置。
- 判断是否需要重新排列缓冲区:
- 如果
wpos < rpos,表示写入位置已环绕到缓冲区的起始位置,需要将数据重新排列,使得写入位置连续。 - 重新排列:
- 分配新的缓冲区
temp,大小与原缓冲区相同。 - 将从
rpos到缓冲区末尾的数据复制到temp的起始位置。 - 将从缓冲区起始位置到
wpos的数据复制到temp的剩余位置。 - 释放原缓冲区内存,并将
buf指针指向新的缓冲区temp。 - 返回新的缓冲区起始位置。
- 分配新的缓冲区
- 如果
- 直接返回写入位置:
- 如果不需要重新排列,直接返回
buf + rpos,即当前可写入的位置。
- 如果不需要重新排列,直接返回
- 计算读取和写入位置:
5. 其他辅助函数
5.1 判断缓冲区是否为空
static uint32_t
rb_isempty(buffer_t *r) {
return r->head == r->tail;
}
- 功能:检查缓冲区是否为空。
- 返回值:
1表示为空,0表示不为空。
5.2 判断缓冲区是否已满
static uint32_t
rb_isfull(buffer_t *r) {
return r->size == (r->tail - r->head);
}
- 功能:检查缓冲区是否已满。
- 返回值:
1表示已满,0表示未满。
5.3 获取缓冲区中剩余的空间
static uint32_t
rb_remain(buffer_t *r) {
return r->size - r->tail + r->head;
}
- 功能:计算缓冲区中剩余的可用空间。
- 返回值:剩余空间的字节数。
6. 代码中的关键概念与实现
6.1 环形地址计算
在环形缓冲区中,head 和 tail 指针是以字节为单位递增的。当指针超过缓冲区的大小时,通过位运算(& (r->size - 1))将其映射回缓冲区的起始位置,实现环形效果。
(r->tail & (r->size - 1))
- 条件:
r->size通常为2的幂次方,这样(r->size - 1)就是一个全1的二进制数,可以用来快速计算模运算。
6.2 缓冲区大小为2的幂次方
为了简化环形地址的计算,缓冲区的大小通常设置为2的幂次方。这不仅提高了效率,还使得位运算成为可能,从而加快了数据的读写操作。
6.3 双指针机制
head:指向下一个读取位置。tail:指向下一个写入位置。- 优势:通过维护两个指针,可以高效地管理生产者(写入)和消费者(读取)之间的数据流动,避免数据冲突和竞争条件。
7. 综合应用
7.1 在用户态缓存区中的应用
在用户态缓存区中,环形缓冲区用于存储和管理网络数据的读写操作。生产者(如内核协议栈)将数据添加到缓冲区,消费者(如应用程序)从缓冲区读取数据。通过环形缓冲区的高效管理,确保数据传输的流畅性和可靠性。
7.2 处理生产者与消费者速度不匹配
当生产者(如内核协议栈)生成数据的速度快于消费者(应用程序)的处理速度时,缓冲区可以暂存这些数据,避免数据丢失。同样,当消费者处理数据的速度快于生产者生成数据的速度时,缓冲区也能有效地管理数据流动,确保数据的连续性。
7.3 结合之前的内容
用户态缓存:高效数据交互与性能优化![]() https://blog.csdn.net/weixin_43925427/article/details/142354725?fromshare=blogdetail&sharetype=blogdetail&sharerId=142354725&sharerefer=PC&sharesource=weixin_43925427&sharefrom=from_link在之前的讲解中,我们提到了读写缓存区在网络通信中的重要性,以及不同的缓冲区设计(固定内存块、环形缓冲区、链式缓冲区)对性能和效率的影响。环形缓冲区通过减少数据移动和优化内存管理,提升了数据传输的效率和系统的整体性能。
https://blog.csdn.net/weixin_43925427/article/details/142354725?fromshare=blogdetail&sharetype=blogdetail&sharerId=142354725&sharerefer=PC&sharesource=weixin_43925427&sharefrom=from_link在之前的讲解中,我们提到了读写缓存区在网络通信中的重要性,以及不同的缓冲区设计(固定内存块、环形缓冲区、链式缓冲区)对性能和效率的影响。环形缓冲区通过减少数据移动和优化内存管理,提升了数据传输的效率和系统的整体性能。
8. 总结
通过详细解析这段环形缓冲区的代码,我们深入理解了环形缓冲区的结构和工作原理:
- 高效的数据管理:通过固定大小的缓冲区和双指针机制,环形缓冲区实现了高效的数据读写操作。
- 减少数据移动:利用环形地址计算和分段拷贝,避免了大量的数据拷贝和移动操作,提升了性能。
- 灵活的空间管理:通过动态调整和优化(如
buffer_write_atmost函数),环形缓冲区能够适应不同的数据量需求,保持高效运行。 - 可靠的数据传输:在生产者和消费者速度不匹配的情况下,环形缓冲区通过暂存和管理数据,确保数据的完整性和可靠性。
参考:
0voice · GitHub
GitHub - TryTryTL/buffer_design
用户态缓存:高效数据交互与性能优化-CSDN博客