1. ARM模式和寄存器
1.1 ARM处理器工作模式
Cortex系列之前的ARM处理器工作模式一共有7种。
1.1.1 工作模式
Cortex系列的ARM处理器工作模式有8种,多了1个monitor模式,如下图所示:

ARM之所以设计出这么多种模式出来,就是为了「应对CPU在运行时各种突发事件」,比如要支持正常的应用程序的运行,在运行任何一个时间点又可能发生很多异常事件,比如:关机、收到网卡信息、除数为0、访问非法内存、解析到了非法指令等等,不光要能处理这些异常还要能够从异常中再返回到原来的程序继续执行。
-
用户模式:用户模式是用户程序的工作模式,它运行在操作系统的用户态,它没有权限去操作其它硬件资源,只能执行处理自己的数据,也不能切换到其它模式下,要想访问硬件资源或切换到其它模式只能通过软中断或产生异常。
-
系统模式:系统模式是特权模式,不受用户模式的限制。用户模式和系统模式共用一套寄存器,操作系统在该模式下可以方便的访问用户模式的寄存器,而且操作系统的一些特权任务可以使用这个模式访问一些受控的资源。
-
一般中断模式:一般中断模式也叫普通中断模式,用于处理一般的中断请求,通常在硬件产生中断信号之后自动进入该模式,该模式为特权模式,可以自由访问系统硬件资源。
-
快速中断模式:快速中断模式是相对一般中断模式而言的,它是用来处理对时间要求比较紧急的中断请求,主要用于高速数据传输及通道处理中。
-
管理模式:管理模式是「CPU上电后默认模式」,因此在该模式下主要用来做系统的初始化,软中断处理也在该模式下,当用户模式下的用户程序请求使用硬件资源时通过软件中断进入该模式。
-
终止模式:中止模式用于支持虚拟内存或存储器保护,当用户程序访问非法地址,没有权限读取的内存地址时,会进入该模式,linux下编程时经常出现的segment fault通常都是在该模式下抛出返回的。
-
未定义模式:未定义模式用于支持硬件协处理器的软件仿真,CPU在指令的译码阶段不能识别该指令操作时,会进入未定义模式。
-
Monitor:是为了安全而扩展出的用于执行安全监控代码的模式;也是一种特权模式
除用户模式以外,其余的所有6种模式称之为非用户模式,或特权模式(Privileged Modes);其中除去用户模式和系统模式以外的5种又称为异常模式(ExceptionModes),常用于处理中断或异常,以及需要访问受保护的系统资源等情况。
1.1.2 模式切换
ARM微处理器的运行模式可以通过软件改变,也可以通过外部中断或异常处理改变。应用程序运行在用户模式下,当处理器运行在用户模式下时,某些被保护的系统资源是不能被访问的。
1.1.3 异常(Exception)
指由处理器执行指令导致原来运行程序的中止,异常与指令运行相关,是CPU执行程序产生的,是同步的,可分为精确异常和非精确异常。异常处理遵守严格的程序顺序,不能嵌套,只有当第一个异常处理完并返回后才能处理后续的异常。
1.2 ARM寄存器
Cortex A系列ARM处理器共有40个32位寄存器,其中33个为通用寄存器,7个为状态寄存器。usr模式和sys模式共用同一组寄存器。

通用寄存器包括R0~R15,可以分为3类:
-
未分组寄存器R0~R7
-
分组寄存器R8~R14、R13(SP) 、R14(LR)
-
程序计数器PC(R15)、R8_fiq-R12_fir为快中断独有
1.2.1 未分组寄存器R0~R7
在所有运行模式下,未分组寄存器都指向同一个物理寄存器,它们未被系统用作特殊的用途.因此在中断或异常处理进行运行模式转换时,由于不同的处理器运行模式均使用相同的物理寄存器,所以可能造成寄存器中数据的破坏。
1.2.2 分组寄存器R8~R14
对于分组寄存器,它们每一次所访问的物理寄存器都与当前处理器的运行模式有关。
对于R8~R12来说,每个寄存器对应2个不同的物理寄存器,当使用FIQ(快速中断模式)时,访问寄存器 R8_fiq~R12_fiq;当使用除FIQ模式以外的其他模式时,访问寄存器R8_usr~R12_usr。
1.2.3 寄存器R13(sp)
在ARM指令中常用作「堆栈指针」,用户也可使用其他的寄存器作为堆栈指针,而在Thumb指令集中,某些指令强制性的要求使用R13作为堆栈指针。
寄存器R13在ARM指令中常用作堆栈指针,但这只是一种习惯用法,用户也可使用其他的寄存器作为堆栈指针。而在Thumb指令集中,某些指令强制性的要求使用R13作为堆栈指针。
由于处理器的每种运行模式均有自己独立的物理寄存器R13,在用户应用程序的初始化部分,一般都要初始化每种模式下的R13,使其指向该运行模式的栈空间。这样,当程序的运行进入异常模式时,可以将需要保护的寄存器放入R13所指向的堆栈,而当程序从异常模式返回时,则从对应的堆栈中恢复,采用这种方式可以保证异常发生后程序的正常执行。
1.2.4 R14(LR)链接寄存器(Link Register)
当执行子程序调用指令(BL)时,R14可得到R15(程序计数器PC)的备份。
在每一种运行模式下,都可用R14保存子程序的返回地址,当用BL或BLX指令调用子程序时,将PC的当前值复制给R14,执行完子程序后,又将R14的值复制回PC,即可完成子程序的调用返回。
1.2.5 R15(PC)程序状态寄存器
寄存器R15用作程序计数器(PC),在ARM状态下,位[1:0]为0,位[31:2]用于保存PC,在Thumb状态下,位[0]为0,位[31:1]用于保存PC。
1.2.6 CPSR、SPSR
「CPSR」(Current Program Status Register,当前程序状态寄存器),CPSR可在任何运行模式下被访问,它包括条件标志位、中断禁止位、当前处理器模式标志位,以及其他一些相关的控制和状态位。
每一种运行模式下又都有一个专用的物理状态寄存器,称为「SPSR」(Saved Program Status Register,备份的程序状态寄存器),当异常发生时,SPSR用于保存CPSR的当前值,从异常退出时则可由SPSR来恢复CPSR。
由于用户模式和系统模式不属于异常模式,它们没有SPSR,当在这两种模式下访问SPSR,结果是未知的。
寄存器CPSR格式如下:

1.2.6.1 条件码标志
「N,Z,C,V」均为条件码标志位,它们的内容可被算术或逻辑运算的结果所改变,并且可以决定某条指令是否被执行。在ARM状态下,绝大多数的指令都是有条件执行的,在Thumb状态下,仅有分支指令是有条件执行的。
「N (Number)」: 当用两个补码表示的带符号数进行运算时,N=1表示运行结果为负,N=0表示运行结果为正或零
「Z :(Zero)」: Z=1表示运算结果为零,Z=0表示运行结果非零
「C」 : 可以有4种方法设置C的值:
-
(Come)加法运算(包括CMP):当运算结果产生了进位时C=1,否则C=0
-
减法运算(包括CMP):当运算产生了借位,C=0否则C=1
-
对于包含移位操作的非加/减运算指令 ,C为移出值的最后一位
-
对于其他的非加/减运算指令C的值通常不改变
「V」 :
(oVerflow)对于加/减法运算指令,当操作数和运算结果为二进制的补码表示的带符号位溢出时,V=1表示符号位溢出;对于其他的非加/减运算指令V的值通常不改变
「Q」:在ARM V5及以上版本的E系列处理器中,用Q标志位指示增强的DSP运算指令是否发生了溢出。在其它版本的处理器中,Q标志位无定义
「J:」
仅ARM v5TE-J架构支持 , T=0;J = 1 处理器处于Jazelle状态,也可以和其他位组合.
「E位:」大小端控制位
「A位:」A=1 禁止不精确的数据异常
「T :」T = 0;J=0; 处理器处于 ARM 状态 T = 1;J=0 处理器处于 Thumb 状态 T = 1;J=1 处理器处于 ThumbEE 状态
1.2.6.2 控制位
CPSR的低8位(包括I,F,T和M[4:0])称为控制位,当发生异常时这些位可以被改变,如果处理器运行特权模式,这些位也可以由程序修改。
「中断禁止位I,F」
【重要】 I=1 禁止IRQ中断 F=1 禁止FIQ中断
比如我们要想在程序中实现禁止中断,那么就需要将CPSR[7]置1。
1.2.6.3 运行模式位[4-0]
| bite | 模式 | ARM模式可访问的寄存器 |
|---|---|---|
| 0b10000 | 用户模式user | PC,CPSR,R0~R14 |
| 0b10001 | FIQ模式 | PC,CPSR,SPSR_fiq,R14_fiq~R8_fiq,R0~R7 |
| 0b10010 | IRQ模式 | PC,CPSR,SPSR_irq,R14_irq~R13_irq,R0~R12 |
| 0b10011 | 管理模式 | PC,CPSR,SPSR_svc,R14_svc~R13_svc,R0~R12 |
| 0b10111 | 中止模式Abort | PC,CPSR,SPSR_abt,R14_abt~R13_abt,R0~R12 |
| 0b11011 | 未定义模式 | C,CPSR,SPSR_und,R14_und~R13_und,R0~R12 |
| 0b11111 | 系统模式 | PC,CPSR,R0~R14 |
注意观察这5个bit的特点,最高位都是1,低4位的值则各不相同,这个很重要,要想搞清楚uboot、linux的源码,尤其是异常操作的代码,必须要知道这几个bit的值。
1.3 协处理器

ARM体系结构允许通过增加协处理器来扩展指令集。最常用的协处理器是用于控制片上功能的系统协处理器。
例如,控制Cache和存储管理单元MMU的CP15协处理器、设置异常向量表地址的mcr指令。
ARM支持16个协处理器,在程序执行过程中,每个协处理器忽略属于ARM处理器和其他协处理器指令,当一个协处理器硬件不能执行属于它的协处理器指令时,就会产生一个未定义的异常中断,在异常中断处理程序中,可以通过软件模拟该硬件的操作,比如,如果系统不包含向量浮点运算器,则可以选择浮点运算软件模拟包来支持向量浮点运算。
ARM协处理器指令包括如下三类:
-
用于ARM处理器初始化ARM协处理器的数据操作
-
用于ARM处理器的寄存器和ARM协处理器的寄存器间的数据传送操作
-
用于在ARM协处理器的寄存器和内存单元之间传送数据
这些指令包括如下5条:
-
CDP协处理器数据操作指令
-
LDC协处理器数据读入指令
-
STC协处理器数据写入指令
-
MCR ARM寄存器到协处理器寄存器的数据传送指令
-
MRC 协处理器寄存器到ARM寄存器的数据传送指令
2. ARM汇编指令
2.1 MOV指令
2.1.1 MOV
语法:
MOV{条件}{S} 目的寄存器,源操作数
功能:MOV指令完成从另一个寄存器、被移位的寄存器或将一个立即数加载到目的寄存器。其中S选项决定指令的操作是否影响CPSR中条件标志位的值,当没有S时指令不更新CPSR中条件标志位的值。
指令示例:
MOV r0, #0x1 ;将立即数0x1传送到寄存器R0
MOV R1,R0 ;将寄存器R0的值传送到寄存器R1
MOV PC,R14 ;将寄存器R14的值传送到PC,常用于子程序返回
MOV R1,R0,LSL #3 ;将寄存器R0的值左移3位后传送到R1
【注:不区分大小写】
2.1.2 立即数
MOV R0,#0xfff

要想搞懂这个问题,我们需要了解什么是立即数。
立即数是由 0-255之间的数据循环右移偶数位生成。
判断规则如下:
-
把数据转换成二进制形式,从低位到高位写成4位1组的形式,最高位一组不够4位的,在最高位前面补0。
-
数1的个数,如果大于8个肯定不是立即数,如果小于等于8进行下面步骤。
-
如果数据中间有连续的大于等于24个0,循环左移2的倍数,使高位全为0。
-
找到最高位的1,去掉前面最大偶数个0。
-
找到最低位的1,去掉后面最大偶数个0。
-
数剩下的位数,如果小于等于8位,那么这个数就是立即数,反之就不是立即数。
而例子中的数是0xfff,我们来看下他的二进制:
0000 0000 0000 0000 0000 1111 1111 1111
按照上述规则,我们最终操作结果如下:
1111 1111 1111
可以看到剩余的位数大于8个,所以该数不是立即数。为什么立即数会有这么个限定?我们需要从MOV这条指令的机器码来说起。
2.2 移位操作
ARM微处理器支持数据的移位操作,移位操作在ARM指令集中不作为单独的指令使用,它只能作为指令格式中是一个字段,在汇编语言中表示为指令中的选项。移位操作包括如下6种类型,ASL和LSL是等价的,可以自由互换:
2.2.1 LSL(或ASL)逻辑(算术)左移
寻址格式:
通用寄存器,LSL(或ASL) 操作数
完成对通用寄存器中的内容进行逻辑(或算术)的左移操作,按操作数所指定的数量向左移位,低位用零来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。如:
MOV R0, R1, LSL#2 ;将R1中的内容左移两位后传送到R0中。
2.2.2 LSR逻辑右移
寻址格式:
通用寄存器,LSR 操作数
完成对通用寄存器中的内容进行右移的操作,按操作数所指定的数量向右移位,左端用零来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。如:
MOV R0, R1, LSR #2 ;将R1中的内容右移两位后传送到R0中,左端用零来填充。
2.2.3 ASR算术右移
寻址格式:
通用寄存器,ASR 操作数
完成对通用寄存器中的内容进行右移的操作,按操作数所指定的数量向右移位,左端用第31位的值来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。如:
MOV R0, R1, ASR #2 ;将R1中的内容右移两位后传送到R0中,左端用第31位的值来填充。
2.2.4 ROR循环右移
寻址格式:
通用寄存器,ROR 操作数
完成对通用寄存器中的内容进行循环右移的操作,按操作数所指定的数量向右循环移位,左端用右端移出的位来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。显然,当进行32位的循环右移操作时,通用寄存器中的值不改变。如:
MOV R0, R1, ROR #2 ;将R1中的内容循环右移两位后传送到R0中。
2.2.5 RRX带扩展的循环右移
寻址格式:
通用寄存器,RRX 操作数
完成对通用寄存器中的内容进行带扩展的循环右移的操作,按操作数所指定的数量向右循环移位,左端用进位标志位C来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。如:
MOV R0, R1, RRX #2 ;将R1中的内容进行带扩展的循环右移两位后传送到R0中。
2.2.6 举例
; 第二操作数 寄存器移位操作, 5种移位方式, 9种语法
; 逻辑左移
mov r0, #0x1
mov r1, r0, lsl #1 ; 移位位数1-31肯定合法
mov r0, #0x2
mov r1, r0, lsr #1 ; 逻辑右移
mov r0, #0xffffffff
mov r1, r0, asr #1 ; 算术右移符号位不变, 次高位补符号位
mov r0, #0x7fffffff
mov r1, r0, asr #1
mov r0, #0x7fffffff
mov r1, r0, ror #1 ; 循环右移
mov r0, #0xffffffff
mov r1, r0, rrx ; 唯一不需要指定循环位数的移位方式
;带扩展的循环右移
;C标志位进入最高位,最低位进入C 标志位
; 移位值可以是另一个寄存器的值低5bit, 写法如下
mov r2, #1
mov r0, #0x1
mov r1, r0, lsl r2 ; 移位位数1-31肯定合法
mov r0, #0xffffffff
mov r1, r0, asr r2 ; 算术右移符号位不变, 次高位补符号位
mov r0, #0x7fffffff
mov r1, r0, asr r2
mov r0, #0x7fffffff
mov r1, r0, ror r2 ; 循环右移
2.3 CMP比较指令
语法
CMP{条件} 操作数1,操作数2
CMP指令用于把一个寄存器的内容和另一个寄存器的内容或立即数进行比较,同时更新CPSR中条件标志位的值。
该指令进行一次减法运算,但不存储结果,只更改条件标志位。cmp是做一次减法,并不保存结果,仅仅用来产生一个逻辑,体现在改变cpsr相应的condition位。
标志位表示的是操作数1与操作数2的关系(大、小、相等), 指令示例:
CMP R1,R0 ;将寄存器R1的值与寄存器R0的值相减,并根据结果设置CPSR的标志位
CMP R1,#100 ;将寄存器R1的值与立即数100相减,并根据结果设置CPSR的标志位
2.4 TST条件指令
语法
TST{条件} 操作数1,操作数2
TST指令用于把一个寄存器的内容和另一个寄存器的内容或立即数进行按位的与运算,并根据运算结果更新CPSR中条件标志位的值。操作数1是要测试的数据,而操作数2是一个位掩码,根据测试结果设置相应标志位。当位与结果为0时,EQ位被设置。 指令示例
TST R1,#%1 ;用于测试在寄存器R1中是否设置了最低位(%表示二进制数)。
比较指令和条件执行举例
例1:找出三个寄存器中数据最大的数
mov r0, #3
mov r1, #4
mov r2, #5
cmp r1,r0
movgt r0,r1
cmp r2,r0
movgt r0,r2
例2:求两个数的差的绝对值
mov r0,#9
mov r1,#15
cmp r0,r1
beq stop
subgt r0,r0,r1
sublt r1,r1,r0
2.5 数据的处理指令
2.5.1 ADD
ADD{条件}{S} 目的寄存器,操作数1,操作数2
ADD指令用于把两个操作数相加,并将结果存放到目的寄存器中。操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。指令示例:
ADD R0,R1,R2 ;R0 = R1 + R2
ADD R0,R1,#256 ;R0 = R1 + 256
ADD R0,R2,R3,LSL#1 ;R0 = R2 + (R3 << 1)
2.5.2 ADC
除了正常做加法运算之外,还要加上CPSR中的C条件标志位,如果要影响CPSR中对应位,加后缀S。
2.5.3 SUB
SUB指令的格式为:
SUB{条件}{S} 目的寄存器,操作数1,操作数2
SUB指令用于把操作数1减去操作数2,并将结果存放到目的寄存器中。
操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。该指令可用于有符号数或无符号数的减法运算。
如:
SUB R0,R1,R2 ;R0 = R1 - R2
SUB R0,R1,#256 ;R0 = R1 - 256
SUB R0,R2,R3,LSL#1 ;R0 = R2 - (R3 << 1)2.5.4 SBC
除了正常做加法运算之外,还要再减去CPSR中C条件标志位的反码 根据执行结果设置CPSR对应的标志位 AND指令的格式为:
AND{条件}{S} 目的寄存器,操作数1,操作数2
AND指令用于在两个操作数上进行逻辑与运算,并把结果放置到目的寄存器中。操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。该指令常用于屏蔽操作数1的某些位。如:
AND R0,R0,#3 ; 该指令保持R0的0、1位,其余位清零。
2.5.5 ORR
ORR指令的格式为:
ORR{条件}{S} 目的寄存器,操作数1,操作数2
ORR指令用于在两个操作数上进行逻辑或运算,并把结果放置到目的寄存器中。操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。该指令常用于设置操作数1的某些位。如:
ORR R0,R0,#3 ; 该指令设置R0的0、1位,其余位保持不变。
2.5.6 BIC
这是一个非常实用的指令,在实际寄存器操作经常要将某些位清零,但是又不想影响其他位的值,就可以使用该命令。
BIC指令的格式为:
BIC{条件}{S} 目的寄存器,操作数1,操作数2
BIC指令用于清除操作数1的某些位,并把结果放置到目的寄存器中。
操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。操作数2为32位的掩码,如果在掩码中设置了某一位,则清除这一位。未设置的掩码位保持不变。
如:
BIC R0,R0,#%1011 ; 该指令清除 R0 中的位 0、1、和 3,其余的位保持不变。
2.5.7 举例
mov r0, #1
mov r1, #2
add r2, r0, r1 ; r2 = r0 + r1
add r2, r0, #4
add r2, r0, r1, lsl #2 ; r2 = r0 +R1<<2; (R0 + R1*4)
; 2. adc 64位加法 r0, r1 = r0, r1 + r2, r3
mov r0, #0
mov r1, #0xffffffff
mov r2, #0
mov r3, #0x1
adds r1, r1, r3 ; r1 = r1 + r3 必须加S后缀
adc r0, r0, r2 ; r0 = r0 + r2 + c ;add 带 扩展的加法
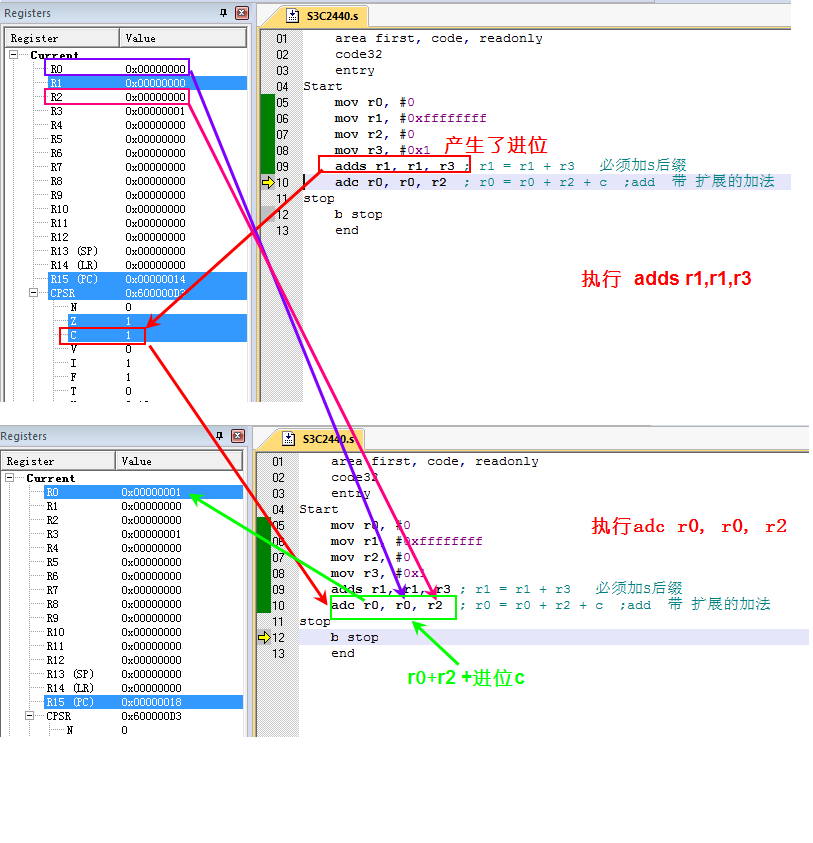
可以对比下add和adds,没有加s的话是不会影响条件位的。
; 3. sub rd = rn - op2
mov r0, #1
sub r0, r0, #1 ; r0 = r0 - 1
; 4. sbc 64位减法 r0, r1 = r0, r1 - r2, r3
; cpsr c 对于加法运算 C = 1 则代表有进位, C = 0 无进位
; 对于减法运算 C = 1 则代表无借位, C = 0 有借位
mov r0, #0
mov r1, #0x0
mov r2, #0
mov r3, #0x1
subs r1, r1, r3
sbc r0, r0, r2 ;sbc 带扩展的减法
; 5. bic 位清除
mov r0, #0xffffffff
bic r0, r0, #0xff ; and r0, r0, #0xffffff00
执行结果
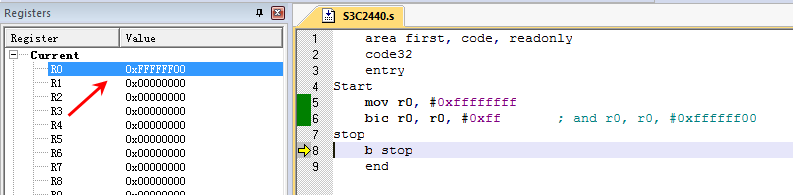
2.6 跳转指令
跳转指令用于实现程序流程的跳转,在ARM程序中有两种方法可以实现程序流程的跳转:
-
使用专门的跳转指令;
-
直接向程序计数器PC写入跳转地址值,通过向程序计数器PC写入跳转地址值,可以实现在4GB的地址空间中的任意跳转,在跳转之前结合使用。
使用以下指令,可以保存将来的返回地址值,从而实现在4GB连续的线性地址空间的子程序调用。
MOV LR,PC
ARM指令集中的跳转指令可以完成从当前指令向前或向后的32MB的地址空间的跳转,包括以下4条指令:
B 跳转指令
BL 带返回的跳转指令
BLX 带返回和状态切换的跳转指令thumb指令
BX 带状态切换的跳转指令thumb指令
2.6.1 B 指令
指令的格式为:
B{条件} 目标地址
B指令是最简单的跳转指令。一旦遇到一个 B 指令,ARM 处理器将立即跳转到给定的目标地址,从那里继续执行。
B label 程序无条件跳转到标号label处执行
CMP R1 ,#0
BEQ label 当CPSR寄存器中的Z条件码置位时,程序跳转到标号Label处执行。
2.6.2 BL 指令
BL 指令的格式为:
BL{条件} 目标地址
BL是另一个跳转指令,但跳转之前,会在寄存器R14中保存PC当前值,因此,可以通过将R14 的内容重新加载到PC中,来返回到跳转指令之后的那个指令处执行。该指令是实现子程序调用的一个基本但常用的手段。
BL label 当程序无条件跳转到标号Label处执行时,同时将当前的PC值保存到R14中
子函数要返回执行以下指令即可:
MOV PC,LR
2.6.3 BL指令机器码
语法:
Branch : B{<cond>} label
Branch with Link : BL{<cond>} subroutine_label
BL机器码格式如下:
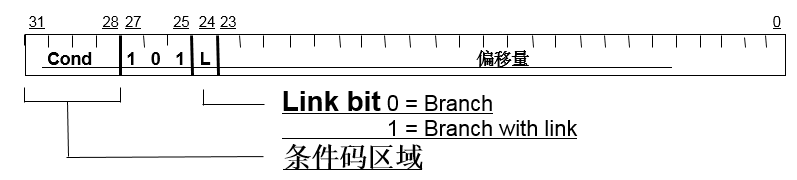
b指令机器码
各域含义:
| 域 | 含义 |
|---|---|
| cond | 条件码 |
| 101 | 操作码 |
| L | 命令是否包含L |
| offset | 指令跳转偏移量 |
其中offset是24个bite,最高位包含一个符号位,1个单位表示偏移一条指令,所以可以寻址±2^23^条指令,即±8M条指令。
而一条指令是4个字节,所以最大寻址空间为±32MB的地址空间。
我们来看下以下代码:
AREA Example,CODE,READONLY
ENTRY ;程序入口
Start
MOV R0,#0
MOV R1,#10
BL ADD_SUM
B OVER
ADD_SUM
ADD R0,R0,R1
MOV PC,LR
OVER
END
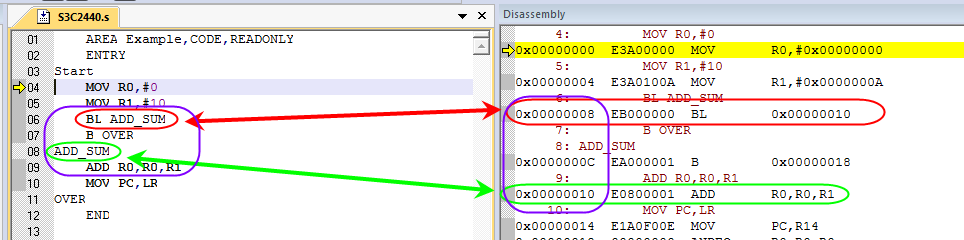
BL机器码
由上图所示:
-
第6行代码BL ADD_SUM 会跳转到第8行,即第9行的代码
-
第6行的指令的机器码是EB000000
根据BL的机器码我们可以得到offset的值是0x000000,也就是说该指令跳转本身,而根据我们的分析第6行代码,应该是向前跳转2条指令,按道理offset是应该是2,为什么是0呢?
因为是3级流水线,所以pc存储指令地址与正在处理指令地址之间相差8个字节,pc的地址是预取指令地址,而不是正在执行的指令的地址。
2.6.4 如何访问全部32-bit地址空间?
可以手动设置LR寄存器,然后装载到PC中。
MOV lr, pc
LDR pc, =dest
在编译项目过程中,ARM连接器(linker)会自动为长跳转(超过32Mb范围)。
ldr下一章会详细详细讲解。
2.6.5 举例
子函数多重嵌套调用,如何从子函数返回?
area first, code, readonly
code32
entry
main
; bl 指令, 子函数调用
mov r0,#1
bl child_func
mov r0,#2
stop
b stop
child_func
mov r1,r0
mov r2,lr
mov r0, #3 //<=== pc
bl child_func_2
mov r0,#4
mov r0,r1
mov lr,r2
mov pc, lr
child_func_2 ;叶子函数
mov r3,r0
mov r4,lr ; 保存直接父函数用到的所有寄存器
mov r0, #5
mov r0,r3
mov lr,r4 ;返回到直接父函数之前,把它用到的所有寄存器内容恢复
mov pc, lr
end
=[R1+4]、R1=R1+4
LDR R0,[R1],#4 ;R0=[R1] 、R1=R1+4
LDR R0,[R1,R2] ;R0=[R1+R2]
2.7 程序状态寄存器访问指令
ARM微处理器支持程序状态寄存器访问指令,用于在程序状态寄存器和通用寄存器之间传送数据。
2.7.1 MRS
MRS{条件} 通用寄存器,程序状态寄存器(CPSR或SPSR)
MRS指令用于将程序状态寄存器的内容传送到通用寄存器中。该指令一般用在以下几种情况:
-
当需要改变程序状态寄存器的内容时,可用MRS将程序状态寄存器的内容读入通用寄存器,修改后再写回程序状态寄存器。
-
当在异常处理或进程切换时,需要保存程序状态寄存器的值,可先用该指令读出程序状态寄存器的值,然后保存。如:
MRS R0,CPSR ;传送CPSR的内容到R0
MRS R0,SPSR ;传送SPSR的内容到R0
2.7.2 MSR
MSR{条件} 程序状态寄存器(CPSR或SPSR)_<域>,操作数
MSR指令用于将操作数的内容传送到程序状态寄存器的特定域中。其中,操作数可以为通用寄存器或立即数。<域>用于设置程序状态寄存器中需要操作的位,32位的程序状态寄存器可分为4个域:
位[31:24]为条件标志位域,用f表示;
位[23:16]为状态位域,用s表示;
位[15:8]为扩展位域,用x表示;
位[7:0]为控制位域,用c表示;
该指令通常用于恢复或改变程序状态寄存器的内容,在使用时,一般要在MSR指令中指明将要操作的域。如:
MSR CPSR,R0 ;传送R0的内容到CPSR
MSR SPSR,R0 ;传送R0的内容到SPSR
MSR CPSR_c,R0 ;传送R0的内容到SPSR,但仅仅修改CPSR中的控制位域
2.7.3 举例
-
使能中断
要是能中断,必须将寄存器CPSR的bit[7]设置为0

要将寄存器CPSR的bit[7]设置为0,但是不能影响其他位,所以必须先用msr读取出cpsr的值到通用寄存器Rn(n取值0~8),然后修改bit[7]设置为0,再将该寄存器的值设置到CPSR中。
代码如下:
area reset,code
code32
entry
start
bl enale_irq
enale_irq
mrs r0,cpsr
bic r0,r0,#0x80
msr cpsr_c,r0
mov pc,lr
执行结果:
-
第8行【其实第8行还没有执行】:
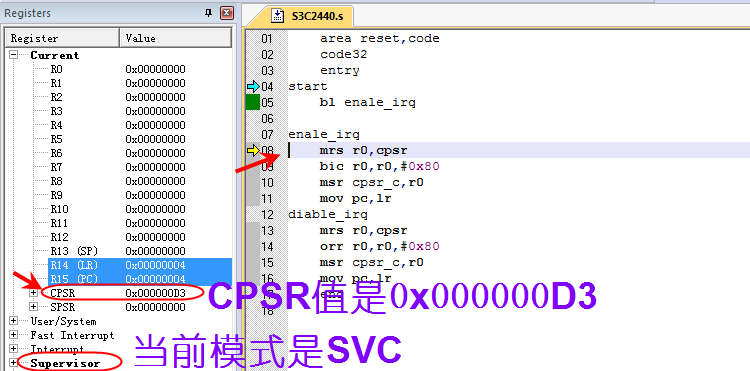
-
当前模式时SVC ,因为开机商店属于reset异常,而该异常会自动进入svc模式
-
CPSR的值是0X000000D3
-
9行
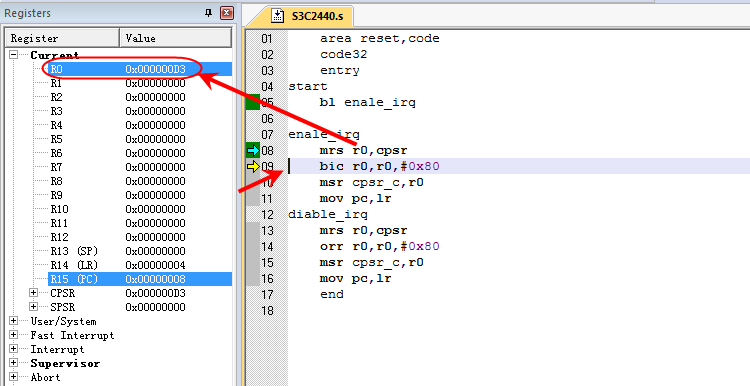
-
mrs r0,cpsr 将cpsr的内容读取到寄存器r0中
-
R0的值为0X000000D3
-
10行
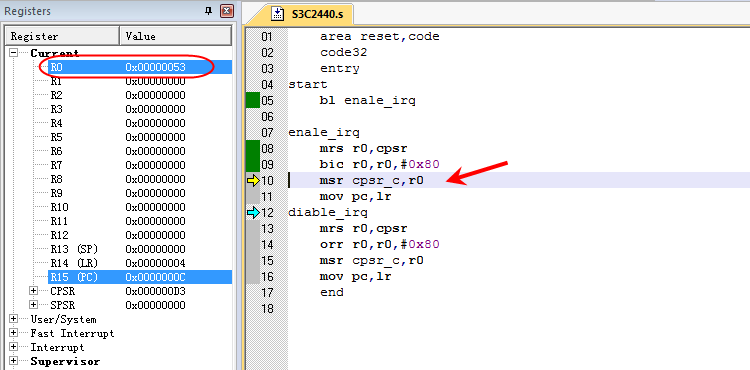
-
bic r0,r0,#0x80 将r0的第7个bit位置设置为0(从低往高数,0开始计数)
-
寄存器R0的值变成0x00000053
-
11行
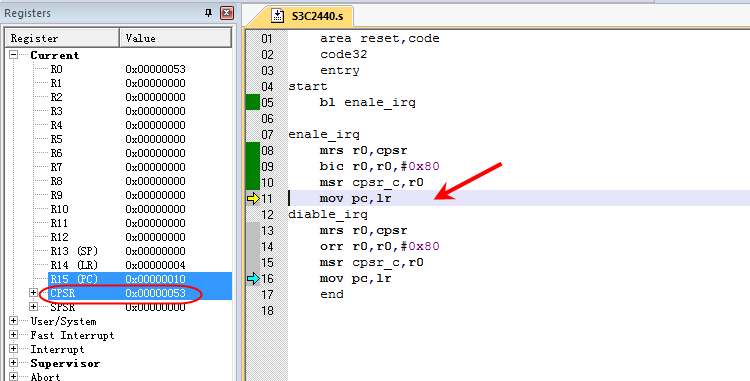
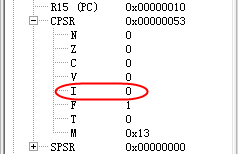
-
msr cpsr_c,r0 将构造好的值写回CPSR,
-
此时CPSR的I 位已经为0从而实现了中断使能
-
禁止中断 同理,我们要关闭中断,只需要将CPSR的I位设置为1即可。
area reset,code
code32
entry
start
bl diable_irq
diable_irq
mrs r0,cpsr
orr r0,r0,#0x80
msr cpsr_c,r0
mov pc,lr
end
-
设置各模式的栈地址 要想初始化各个模式的栈地址,必须首先切换到对应的模式,然后再将栈地址设置到寄存器sp即可。
代码:
area reset,code
code32
entry
start
bl stack_init
stack_init ; 栈指针初始化函数
; @undefine_stack
msr cpsr_c,#0xdb ; 切换到未定义异常
ldr sp,=0x34000000 ; 栈指针为内存最高地址,栈为倒生的栈
; 栈空间的最后1M 0x34000000~0x33f00000
; @abort_stack
msr cpsr_c,#0xd7 ; 切换到终止异常模式
ldr sp,=0x33f00000 ; 栈空间为1M,0x33f00000~0x33e00000
; @irq_stack
msr cpsr_c,#0xd2 ; 切换到中断模式
ldr sp,=0x33e00000 ; 栈空间为1M,0x33e00000~0x33d00000
; @ sys_stack
msr cpsr_c,#0xdf ; 切换到系统模式
ldr sp,=0x33d00000 ; 栈空间为1M,0x33d00000~0x33c00000
msr cpsr_c,#0xd3 ; 切换回管理模式
mov pc,lr
end
「结果分析:」我们只分析undef栈的初始化。
-
8行
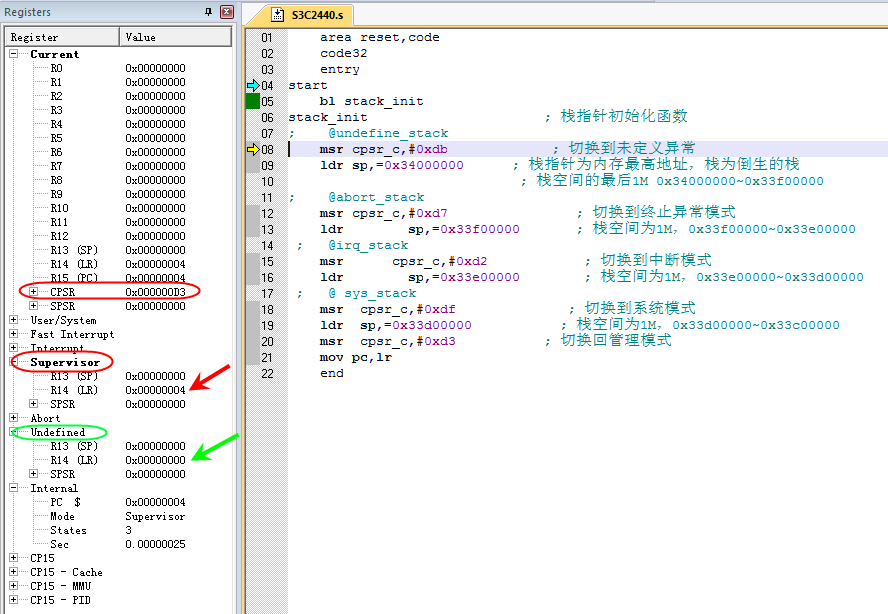
-
模式切换前,当前模式时svc模式,CPSR的值是0x000000D3
-
注意看下SVC和undef模式的SP值都是0
-
9行
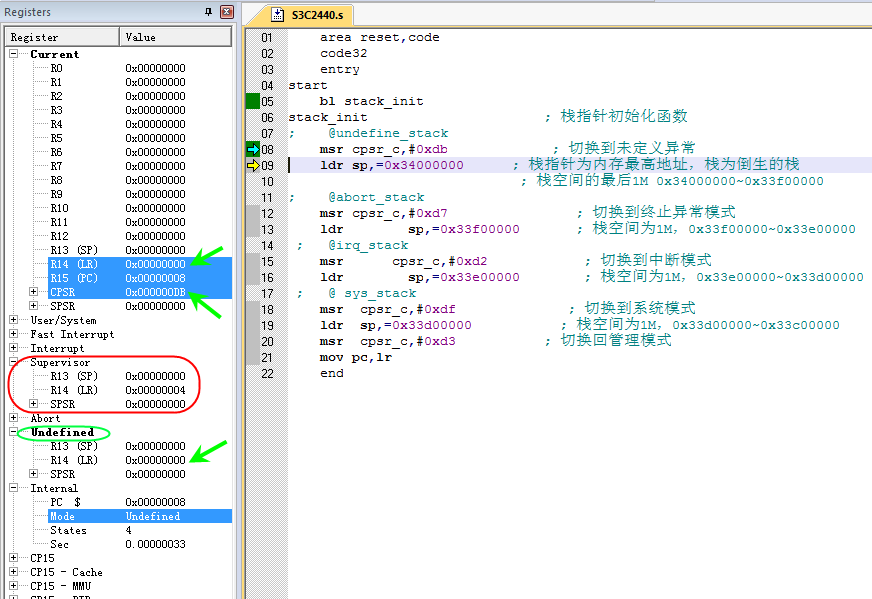
-
msr cpsr_c ,# 0xdb 直接对CPSR进行赋值,将当前模式设置为undef模式
-
Current模式看到的LR寄存器值变成了0,因为模式切换成了undef模式,该模式下有自己的LR、SP寄存器
-
SVC模式的私有寄存器SP和LR没有改变
-
12行
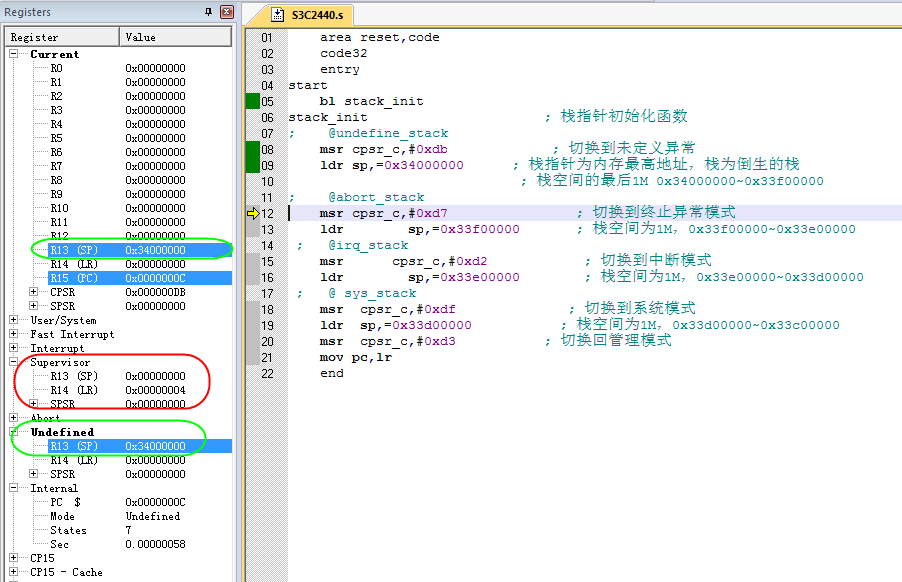
12行
-
ldr sp,=0x34000000 将常数装载到寄存器sp中,(=表示这是一条伪指令)
-
注意观察,SVC模式的sp没有变化,undef模式的SP被设置为 0x34000000
其他模式的栈初始化以此类推。
2.8 寻址方式
处理器根据指令中给出的地址信息来寻找物理地址的方式。
在讲解寻址方式之前,我们首先来看下LDR、STR指令。
2.8.1 加载存储指令
ARM微处理器支持加载/存储指令用于在寄存器和存储器之间传送数据,加载指令用于将存储器中的数据传送到寄存器,存储指令则完成相反的操作。
我们之前讲的寻址方式都是直接对立即数或者寄存器寻址,如果我们想访问外部存储器的某个内存地址或者一些外设的控制器寄存器该如何操作呢?
那就需要进行寄存器间接寻址。如下图所示,访问外存需要通过AHB、APB总线,所以往往需要几个指令周期才能实现1个数据的读写。
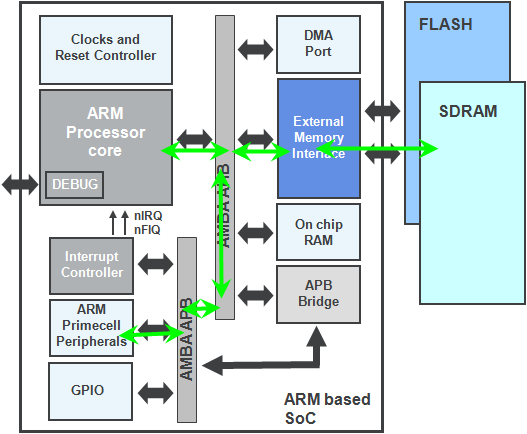
访问外存
2.8.1.1 LDR指令
LDR指令的格式为:
LDR{条件} 目的寄存器,<存储器地址>
LDR指令用于从存储器中将一个32位的字数据传送到目的寄存器中。
1) 用于从存储器中读取32位的字数据到通用寄存器,然后对数据进行处理。2) 当程序计数器PC作为目的寄存器时,指令从存储器中读取的字数据被当作目的地址,从而可以实现程序流程的跳转。如:
LDR R0,[R1] ;将存储器地址为R1的字数据读入寄存器R0。
LDR R0,[R1,R2] ;将存储器地址为R1+R2的字数据读入寄存器R0。
LDR R0,[R1,#8] ;将存储器地址为R1+8的字数据读入寄存器R0。
LDR R0,[R1,R2] ! ;将存储器地址为R1+R2的字数据读入寄存器R0,并将
;新地址R1+R2写入R1。
LDR R0,[R1,#8] ! ;将存储器地址为R1+8的字数据读入寄存器R0,并将新
;地址R1+8写入R1。
LDR R0,[R1],R2 ;将存储器地址为R1的字数据读入寄存器R0,并将新地
;址R1+R2写入R1。
LDR R0,[R1,R2,LSL#2]! ;将存储器地址为R1+R2×4的字数据读入寄存器R0,
;并将新地址R1+R2×4写入R1。
LDR R0,[R1],R2,LSL#2 ;将存储器地址为R1的字数据读入寄存器R0,并将新地
;址R1+R2×4写入R1。
2.8.1.2 STR指令
STR指令的格式为:
STR{条件} 源寄存器,<存储器地址>STR指令用于从源寄存器中将一个32位的字数据传送到存储器中。该指令在程序设计中比较常用,且寻址方式灵活多样,使用方式可参考指令LDR。如:
STR R0,[R1],#8 ;将R0中的字数据写入以R1为地址的存储器中,并将新地址R1+8写入R1。
STR R0,[R1,#8] ;将R0中的字数据写入以R1+8为地址的存储器中。
LDR/STR指令都可以加B、H、SB、SH的后缀,分别表示加载/存储字节、半字、带符号的字节、带符号的半字。如LDRB指令表示从存储器加载一个字节进寄存器。当使用这些后缀时,要注意所使用的存储器要支持访问的数据宽度。
2.8.1.3 LDRB指令
LDRB指令的格式为:
LDR{条件}B 目的寄存器,<存储器地址>
LDRB指令用于从存储器中将一个8位的字节数据传送到目的寄存器中,同时将寄存器的高24位清零。该指令通常用于从存储器中读取8位的字节数据到通用寄存器,然后对数据进行处理。
「指令示例:」
LDRB R0,[R1] ;将存储器地址为R1的字节数据读入寄存器R0,并将R0的高24位清零。
LDRB R0,[R1,#8];将存储器地址为R1+8的字节数据读入寄存器R0,并将R0的高24位清零。
2.8.1.4 LDRH指令
LDRH指令的格式为:
LDR{条件}H 目的寄存器,<存储器地址>
LDRH指令用于从存储器中将一个16位的半字数据传送到目的寄存器中,同时将寄存器的高16位清零。该指令通常用于从存储器中读取16位的半字数据到通用寄存器,然后对数据进行处理。
「指令示例:」
LDRH R0,[R1] ;将存储器地址为R1的半字数据读入寄存器R0,并将R0的高16位清零。
LDRH R0,[R1,R2];将存储器地址为R1+R2的半字数据读入寄存器R0,并将R0的高16位清零。
2.8.1.5 举例
1) STR r0,[r1,#12]
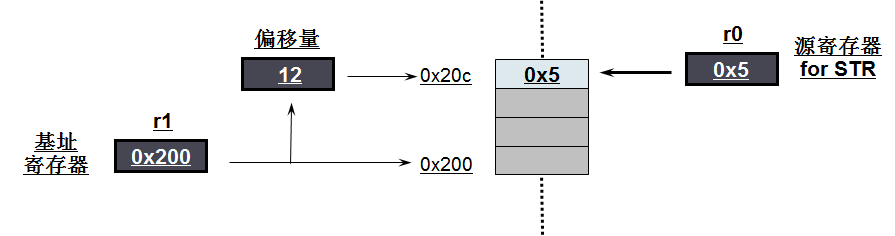
如上图所示:
-
寄存器r0中的值是0x5,r1中的值是0x200
-
将r1的值加上#12,得到地址0x20c
-
将r0寄存器里的值发送给该地址对应的内存,即向地址0x20c中赋值0x5
2) STR r0,[r1],#12
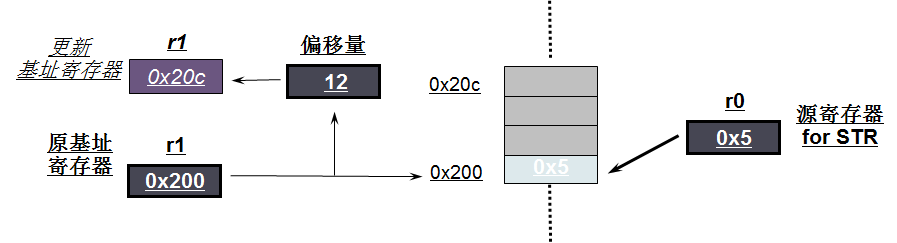
如上图所示:
-
寄存器r0的值是0x5,r1中的值是0x200
-
将r0寄存器里的值发送给该r1中的值对应的内存,即向地址0x200中赋值0x5
-
将r1的值加上#12并赋值给r1,r1的值就变成了0x20c
「扩展:」比如有以下c代码
int *ptr;
x = *ptr++;
经过编译器编译,可以将这两行代码编译为一条单指令:
LDR r0, [r1], #4
2.8.2 立即寻址
立即寻址也叫立即数寻址,这是一种特殊的寻址方式,操作数本身就在指令中给出,只要取出指令也就取到了操作数。这个操作数被称为立即数,对应的寻址方式也就叫做立即寻址。例如以下指令:
Add r0,r0,#1 ;R0=R0+1
在以上两条指令中,第二个源操作数即为立即数,要求以“#”为前缀,对于以十六进制表示的立即数,还要求在“#”后加上“0x”或“&”。
2.8.3 寄存器寻址
利用寄存器中的数值作为操作数,这种寻址方式是各类微处理器经常采用的一种方式,也是一种执行效率较高的寻址方式。
Add R0 , R1,R2 ;R0=R1+R2
该指令的执行效果是将寄存器R1和R2的内容相加,其结果存放在寄存器R0中。
2.8.4 寄存器间接寻址
以寄存器中的值作为操作数的地址,而操作数本身存放在存储器中。例如以下指令:
Add R0,R1,[R2] ; R0=R1+[R2]
LDR R0,[R1] ; R0=[R1]
在第一条指令中,以寄存器R2的值作为操作数的地址,在存储器中取得一个操作数后与R1相加,结果存入寄存器R0中。第二条指令将以R1的值为地址的存储器中的数据传送到R0中。
2.8.5 基址变址寻址
将寄存器(该寄存器一般称作基址寄存器)的内容与指令中给出的地址偏移量相加,从而得到一个操作数的有效地址:
LDR R0,[R1,#4] ;R0=[R1+4]
LDR R0,[R1,#4] ! ;R0=[R1+4]、R1=R1+4
LDR R0,[R1],#4 ;R0=[R1] 、R1=R1+4
LDR R0,[R1,R2] ;R0=[R1+R2]
2.8.6 多寄存器寻址
采用多寄存器寻址方式,一条指令可以完成多个寄存器值的传送。这寻址方式可以用一条指令完成传送最多16个通用寄存器的值。以下指令:
LDMIA R0,{R1,R2,R3,R4} ;R1=[R0] R2=[R0+4] R3=[R0+8] R4=[R0+12]
该指令的后缀IA表示在每次执行完加载/存储操作后,R0按字长度增加,因此,指令可将连续存储单元的值传送到R1~R4。
2.8.7 相对寻址
与基址变址寻址方式相类似,相对寻址以程序计数器PC的当前值为基地址,指令中的地址标号作为偏移量,将两者相加之后得到操作数的有效地址。以下程序段完成子程序的调用和返回,跳转指令BL采用了相对寻址方式:
BL NEXT ;跳转到子程序NEXT处执行
……
NEXT
……
MOV PC,LR ;从子程序返回
2.8.8 堆栈寻址、批量加载/存储指令
堆栈是一种数据结构,按先进后出(First In Last Out,FILO)的方式工作,使用一个称作堆栈指针的专用寄存器指示当前的操作位置,堆栈指针总是指向栈顶。
批量数据加载/存储指令可以一次在一片连续的存储器单元和多个寄存器之间传送数据。常用的加载存储指令如下:
LDM批量数据加载指令
STM批量数据存储指令
LDM(或STM)指令的格式为:
LDM(或STM){条件}{类型} 基址寄存器{!},寄存器列表{∧}
LDM(或STM)指令用于从由基址寄存器所指示的一片连续存储器到寄存器列表所指示的多个寄存器之间传送数据,该指令的常见用途是将多个寄存器的内容入栈或出栈。其中,{类型}为以下几种情况:
IA 每次传送后地址加1;
IB 每次传送前地址加1;
DA 每次传送后地址减1;
DB 每次传送前地址减1;
FD 满递减堆栈; 向低地址方向生长
ED 空递减堆栈;
FA 满递增堆栈; 向高地址方向生长
EA 空递增堆栈;
【满堆栈】:堆栈指针SP指向最后压入堆栈的有效数据项
【空堆栈】:堆栈指针指向下一个要放入数据的空位置
「【特别注意】」
{!}为可选后缀,若选用该后缀,则当数据传送完毕之后,将最后的地址写入基址寄存器,否则基址寄存器的内容不改变。
基址寄存器不允许为R15,寄存器列表可以为R0~R15的任意组合。
{∧}为可选后缀,当指令为LDM且寄存器列表中包含R15,选用该后缀时表示:除了正常的数据传送之外,还将SPSR复制到CPSR。同时,该后缀还表示传入或传出的是用户模式下的寄存器,而不是当前模式下的寄存器。
如:
STMFD R13!,{R0,R4-R12,LR} ;将寄存器列表中的寄存器(R0,R4到R12,LR)存入堆栈,向低地址方向生长。
LDMFD R13!,{R0,R4-R12,PC} ;将堆栈内容恢复到寄存器(R0,R4到R12,LR)。
【注意】 要压栈的寄存器顺序可以乱序,但是实际压栈和出栈仍然会将寄存器顺序调整后再操作。
2.8.9 举例
2.8.9.1 数组求和
编写一个ARM汇编程序,累加一个“数组”的所有元素,碰上0时停止。结果放入 r4。
「实在步骤如下:」
1) 在源文件末尾按如下方式声明“数组”:
array:
.word 0x11
.word 0x22
.word 0
2) 用r0指向“数组”的入口
LDR r0,=array
3) 使用LDR r1,[r0],#4从“数组”中装载数据
4) 累加并放入r4
5) 循环,直到r1为0
6) 停止,进入死循环
代码:
area first, code, readonly
code32
entry
start
ldr r0,=array
; adr r0,array ;ADR为小范围的地址读取伪指令
loop
ldr r1,[r0],#4
cmp r1,#0
addne r4,r4,r1
bne loop
stop
b stop
; DCD 伪操作 数据缓冲池技术
; dcd 机器码
array
dcd 0x11
dcd 0x22
dcd 0
我们看一下最终执行代码在内存中的机器码对比图
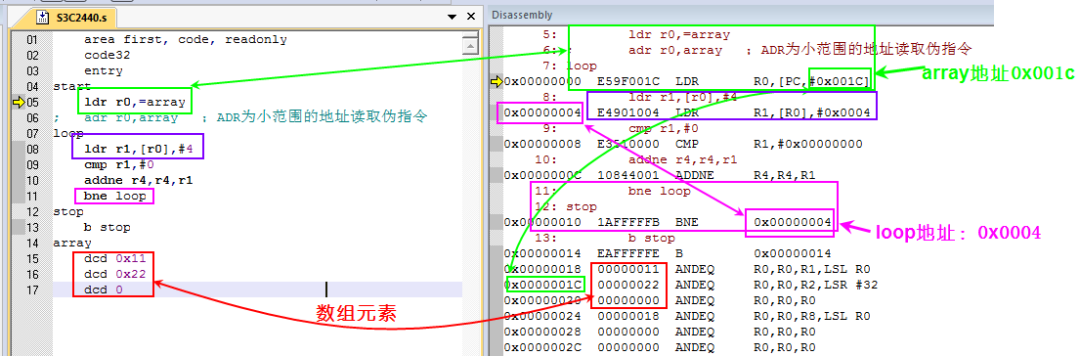
由上图可知:
-
ldr r0,=array,编译器会计算出array标号的地址0x0018,注意该值是偏移当前指令所在内存位置的偏移量,所以该指令最终被翻译成
ldr r0,[pc,#0x001c]
为什么是0x001c而不是0x0018呢?刚上电时此时pc的值是-4,因为下一条要执行的指令的0x0000这个地址的指令
-
数组元素的3个值依次存放在0x0018、0x001c、0x001c这3个地址中
-
ldr r1,[r0],#4每次取出r0指向的内存的值并写入到r1,同时将r0值自加4
-
bne loop 的loop被编译器计算为地址0x0004
2.8.9.2 内存数据读写
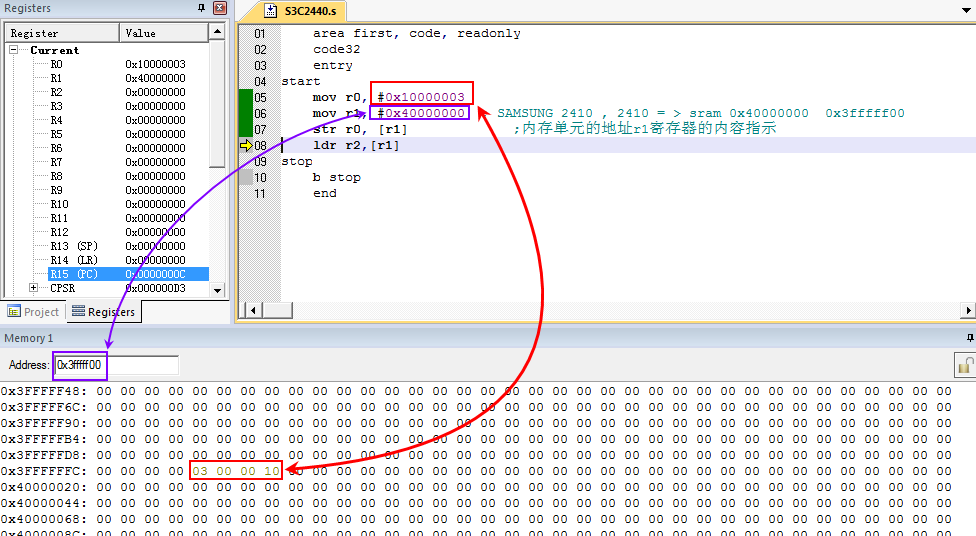
将某个整型值写入到内存0x40000000 中然后再将其读出。
代码:
area first, code, readonly
code32
entry
start
mov r0, #0x10000003
mov r1, #0x40000000 ; SAMSUNG 2410 , 2410 = > sram 0x40000000 0x3fffff00
str r0, [r1] ;内存单元的地址r1寄存器的内容指示
ldr r2,[r1]
stop
b stop
end
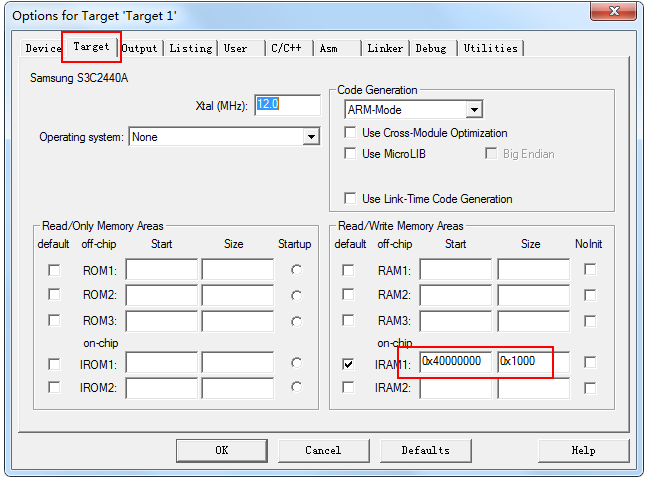
做这个实验之前需要做以下设置。IRAM地址为0x40000000,size设置0x1000,就是我们测试用的IRAM地址范围是0x40000000-0x40001000
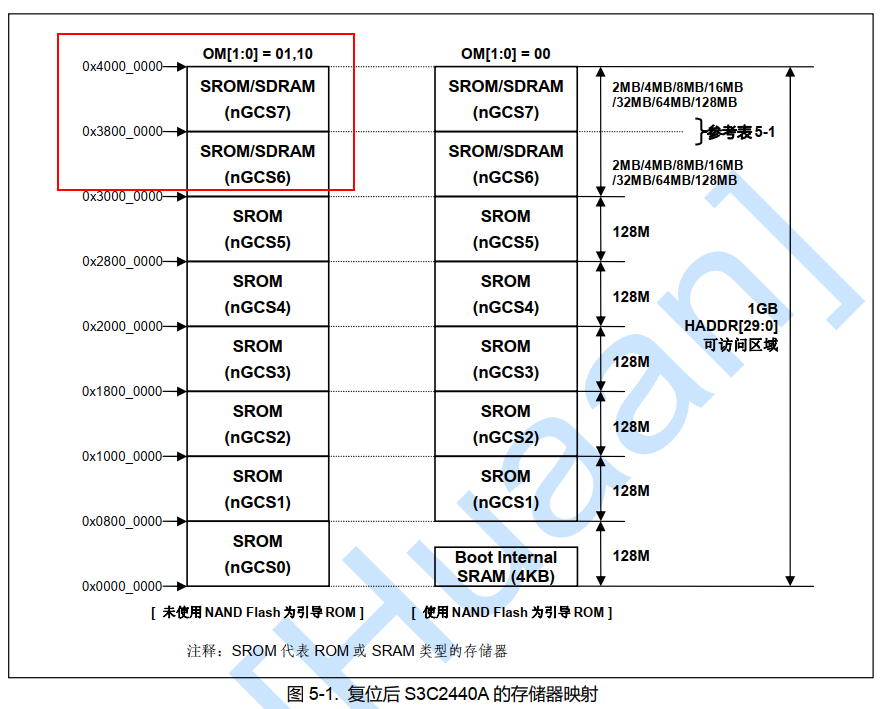
注意,该内存地址不是随意设置的,查看S3C2440A用户手册【因为我们模拟的是S3C2440A这个soc】,从下图可以清楚看到ram地址空间。
「数据写入内存:」
「从内存读取数据:」
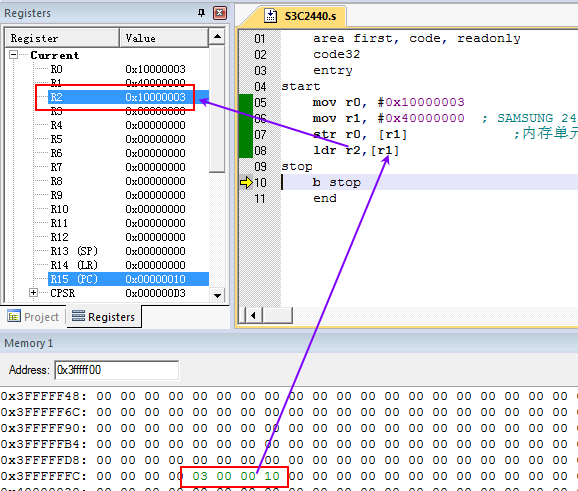
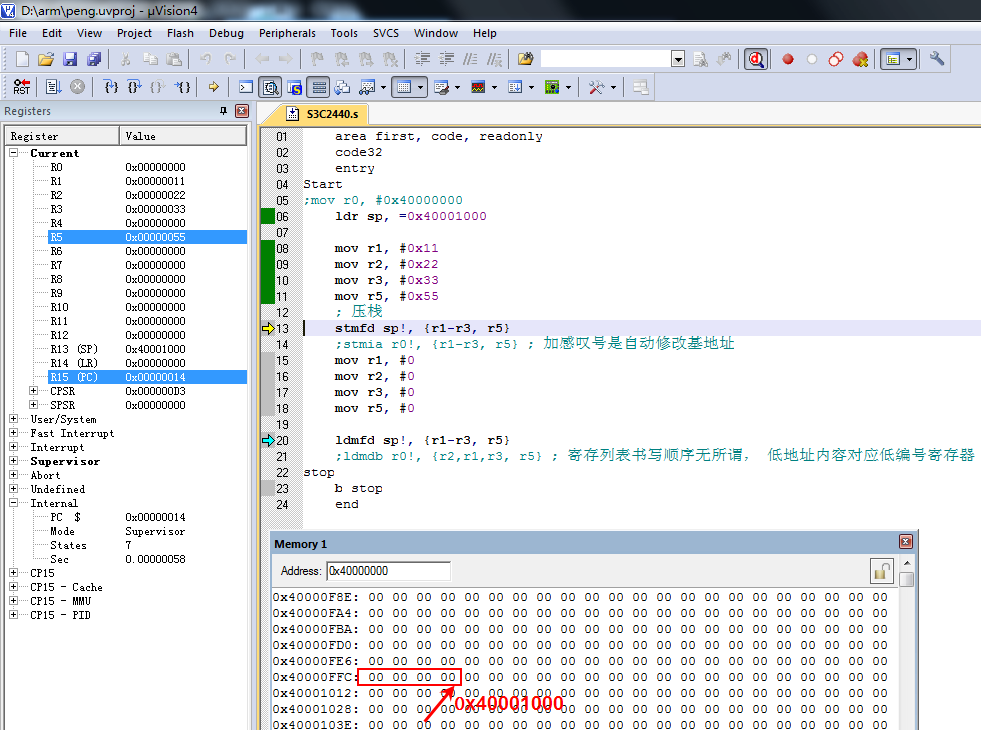
2.8.9.3 数据压栈退栈
先将栈地址设置为将要压栈的数据存入寄存器r1-r5中,然后
area first, code, readonly
code32
entry
Start
;mov r0, #0x40000000
ldr sp, =0x40001000 ;注意地址
mov r1, #0x11
mov r2, #0x22
mov r3, #0x33
mov r5, #0x55
; 压栈
stmfd sp!, {r1-r3, r5}
;stmia r0!, {r1-r3, r5} ; 加感叹号是自动修改基地址
mov r1, #0
mov r2, #0
mov r3, #0
mov r5, #0
ldmfd sp!, {r1-r3, r5}
;ldmdb r0!, {r2,r1,r3, r5} ; 寄存列表书写顺序无所谓, 低地址内容对应低编号寄存器
stop
b stop
end
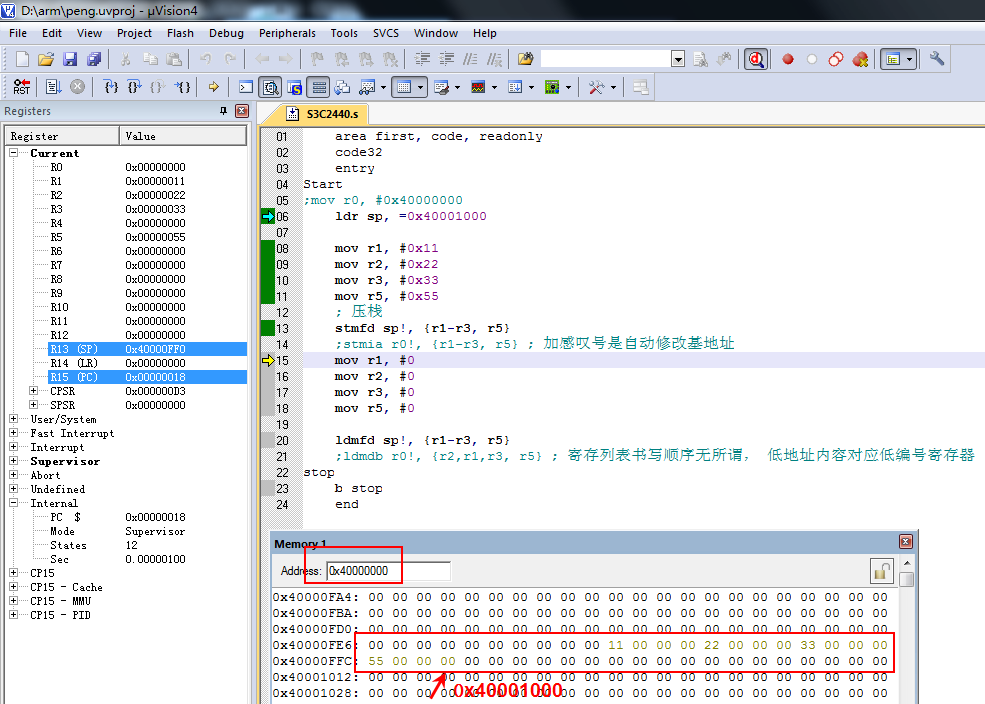
在压栈前,内存0x40001000地址全为0。sp的值为0x40001000。
执行命令ldmfd sp!, {r1-r3, r5}压栈后,因为我们是满递减堆栈,并且SP后又!,所以内存0x40000ff0地址开始的数据是0x11、0x22、0x33、0x44,sp的值修改为为0x40000ff0。以下是压栈后内存的数据:
2.8.9.4 函数嵌套调用
当有多级函数嵌套,函数返回值我们不可能都存储在通用寄存器中,必须利用ldm将程序跳转前的寄存器值以及函数的返回地址压栈。
area first, code, readonly
code32
entry
start
ldr sp, =0x40002000
mov r1, #0x11
mov r2, #0x22
mov r3, #0x33
mov r5, #0x55
bl child_func1 ; 【先写跳转到 child_func1,再写跳转到child_func】
add r0, r1,r2
stop
b stop
; 非叶子函数
child_func
stmfd sp!, {r1-r3,r5,lr} ;;;在子函数里首先将所有寄存器值压栈保存,
;;防止在子函数里篡改原本在主函数里运算需要的值,
;;通常需要把r0-r12全都保存,为了安全和程序通用性应该这么做
mov r1, #10 ;;在这里子函数想怎么做自己的事情就可以做自己的事情
bl child_func1
ldmfd sp!, {r1-r3,r5,lr};;;;; 放在主函数bl之后的第一句行吗?
mov pc, lr
child_func1
stmfd sp!, {r1-r3,r5};;;不论嵌套多少层子函数,都是先压栈,
mov r1, #11
ldmfd sp!, {r1-r3,r5};;对应的,在返回到自己的父函数之前将自己出栈
mov pc, lr
end
读者可以自己debug,查看内存的内容变化
3. ARM异常处理
3.1 异常源
异常是理解CPU运转的最重要的一个知识 点,中断是异常中的一种。在ARM体系结构中,存在7种异常处理。当异常发生时,处理器会把PC设置为一个特定的存储器地址。这一地址放在被称为向量表(vector table)的特定地址范围内,向量表的入口是一些跳转指令,跳转到专门处理某个异常或中断的子程序。
3.1.1 异常源分类
要进入异常模式,一定要有异常源,ARM规定有7种异常源:
| 异常源 | 描述 |
|---|---|
| Reset | 上电时执行 |
| Undef | 当流水线中的某个非法指令到达执行状态时执行 |
| SWI | 当一个软中断指令被执行完的时候执行 |
| Prefetch | 当一个指令被从内存中预取时,由于某种原因而失败,如果它能到达执行状态这个异常才会产生 |
| Data | 如果一个预取指令试图存取一个非法的内存单元,这时异常产生 |
| IRQ | 通常的中断 |
| FIQ | 快速中断 |
(1)reset复位异常
当CPU刚上电时或按下reset重启键之后进入该异常,该异常在管理模式下处理。
(2)irq/fiq一般/快速中断请求
CPU和外部设备是分别独立的硬件执行单元,CPU对全部设备进行管理和资源调度处理,CPU要想知道外部设备的运行状态,要么CPU定时的去查看外部设备特定寄存器,要么让外部设备在出现需要CPU干涉处理时“打断”CPU,让它来处理外部设备的请求,毫无疑问第二种方式更合理,可以让CPU“专心”去工作,这里的“打断”操作就叫做中断请求,根据请求的紧急情况,中断请求分一般中断和快速中断,快速中断具有最高中断优先级和最小的中断延迟,通常用于处理高速数据传输及通道的中数据恢复处理,如DMA等,绝大部分外设使用一般中断请求。
(3)预取指令中止异常
该异常发生在CPU流水线取指阶段,如果目标指令地址是非法地址进入该异常,该异常在中止异常模式下处理。
(4)未定义指令异常
该异常发生在流水线技术里的译码阶段,如果当前指令不能被识别为有效指令,产生未定义指令异常,该异常在未定义异常模式下处理。
(5)软件中断指令(swi)异常
该异常是应用程序自己调用时产生的,用于用户程序申请访问硬件资源时.
例如:printf()打印函数,要将用户数据打印到显示器上,用户程序要想实现打印必须申请使用显示器,而用户程序又没有外设硬件的使用权,只能通过使用软件中断指令切换到内核态,通过操作系统内核代码来访问外设硬件,内核态是工作在特权模式下,操作系统在特权模式下完成将用户数据打印到显示器上。这样做的目的无非是为了保护操作系统的安全和硬件资源的合理使用,该异常在管理模式下处理。
(6)数据中止访问异常
该异常发生在要访问数据地址不存在或者为非法地址时,该异常在中止异常模式下处理。
3.1.2 ARM的异常优先级
Reset→
Data abort→
FIQ→
IRQ→
Prefetch abort→
Undefined instruction/SWI。
3.1.3 FIQ 比 IRQ快的原因
-
FIQ 比IRQ 的优先级高
-
FIQ 向量位于向量表的最末端,异常处理不需要跳转
-
FIQ 比 IRQ 多5个私有的寄存器(r8-r12),在中断操作时,压栈出栈操作的少。
3.2 异常发生的硬件操作
异常发生后,ARM核的操作步骤可以总结为4大步3小步。
3.2.1 4大步3小步
(1)保存执行状态:将CPSR复制到发生的异常模式下SPSR中;
(2)模式切换:
-
CPSR模式位强制设置为与异常类型相对应的值,
-
处理器进入到ARM执行模式,
-
禁止所有IRQ中断,当进入FIQ快速中断模式时禁止FIQ中断;
(3)保存返回地址:将下一条指令的地址(被打断程序)保存在LR(异常模式下LR_excep)中。
(4)跳入异常向量表:强制设置PC的值为相应异常向量地址,跳转到异常处理程序中。
3.2.2 步骤详解
(1)保存执行状态
当前程序的执行状态是保存在CPSR里面的,异常发生时,要保存当前的CPSR里的执行状态到异常模式里的SPSR里,将来异常返回时,恢复回CPSR,恢复执行状态。
(2)模式切换
硬件自动根据当前的异常类型,将异常码写入CPSR里的M[4:0]模式位,这样CPU就进入了对应异常模式下。不管是在ARM状态下还是在THUMB状态下发生异常,都会自动切换到ARM状态下进行异常的处理,这是由硬件自动完成的,将CPSR[5] 设置为 0。同时,CPU会关闭中断IRQ(设置CPSR 寄存器I位),防止中断进入,如果当前是快速中断FIQ异常,关闭快速中断(设置CPSR寄存器F位)。
(3)保存返回地址
当前程序被异常打断,切换到异常处理程序里,异常处理完之后,返回当前被打断模式继续执行,因此必须要保存当前执行指令的下一条指令的地址到LR_excep(异常模式下LR,并不存在LR_excep寄存器,为方便读者理解加上_excep,以下道理相同),由于异常模式不同以及ARM内核采用流水线技术,异常处理程序里要根据异常模式计算返回地址。
(4)跳入异常向量表
该操作是CPU硬件自动完成的,当异常发生时,CPU强制将PC的值修改为一个固定内存地址,这个固定地址叫做异常向量。
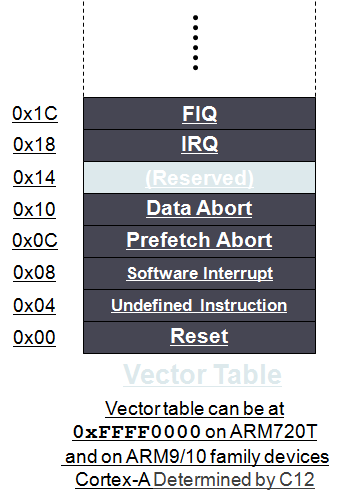
3.3 异常向量表
异常向量表是一段特定内存地址空间,每种ARM异常对应一个字长空间(4Bytes),正好是一条32位指令长度,当异常发生时,CPU强制将PC的值设置为当前异常对应的固定内存地址。
3.3.1 异常向量表
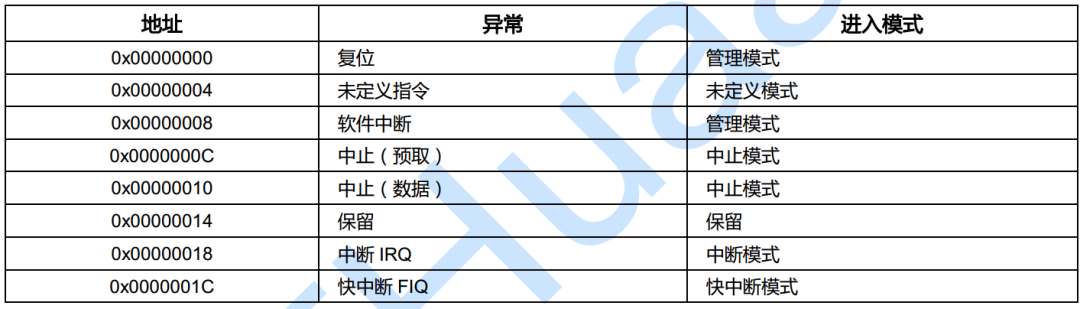
异常向量表
跳入异常向量表操作是异常发生时,硬件自动完成的,剩下的异常处理任务完全交给了程序员。由上表可知,异常向量是一个固定的内存地址,我们可以通过向该地址处写一条跳转指令,让它跳向我们自己定义的异常处理程序的入口,就可以完成异常处理了。
异常向量表
正是由于异常向量表的存在,才让硬件异常处理和程序员自定义处理程序有机联系起来。异常向量表里0x00000000地址处是reset复位异常,之所以它为0地址,是因为CPU在上电时自动从0地址处加载指令,由此可见将复位异常安装在此地址处也是前后接合起来设计的,不得不感叹CPU设计师的伟大,其后面分别是其余7种异常向量,每种异常向量都占有四个字节,正好是一条指令的大小,最后一个异常是快速中断异常,将其安装在此也有它的意义,在0x0000001C地址处可以直接存放快速中断的处理程序,不用设置跳转指令,这样可以节省一个时钟周期,加快快速中断处理时间。
存储器映射地址0x00000000是为向量表保留的。在有些处理器中,向量表可以选择定位在高地址0xFFFF0000处【可以通过协处理器指令配置】,当今操作系统为了控制内存访问权限,通常会开启虚拟内存,开启了虚拟内存之后,内存的开始空间通常为内核进程空间,和页表空间,异常向量表不能再安装在0地址处了。
比如Cortex-A8系统中支持通过设置CP15的C12寄存器将异常向量表的首地址放置在任意地址。
3.3.2 安装异常向量表
我们可以通过简单的使用下面的指令来安装异常向量表:
b reset ;跳入reset处理程序
b HandleUndef ;跳入未定义处理程序
b HandSWI ;跳入软中断处理程序
b HandPrefetchAbt ;跳入预取指令处理程序
b HandDataAbt ;跳入数据访问中止处理程序
b HandNoUsed ;跳入未使用程序
b HandleIRQ ;跳入中断处理程序
b HandleFIQ ;跳入快速中断处理程序
通常安装完异常向量表,跳到我们自己定义的处理程序入口,这时我们还没有保存被打断程序的现场,因此在异常处理程序的入口里先要保存打断程序现场。
3.3.3 保存执行现场
异常处理程序最开始,要保存被打断程序的执行现场,程序的执行现场无非就是保存当前操作寄存器里的数据,可以通过下面的栈操作指令实现保存现场:
STMFD SP_excep!, {R0 – R12, LR_excep}
注:LR_abt,SP_excep分别为对应异常模式下LR和SP,为方便读者理解加上_abt
需要注意的是,在跳转到异常处理程序入口时,已经切换到对应异常模式下了,因此这里的SP是异常模式下的SP_excep了,所以被打断程序现场(寄存器数据)是保存在异常模式下的栈里,上述指令将R0~R12全部都保存到了异常模式栈,最后将修改完的被打断程序返回地址入栈保存,之所以保存该返回地址就是将来可以通过类似:MOV PC, LR的指令,返回用户程序继续执行。
异常发生后,要针对异常类型进行处理,因此,每种异常都有自己的异常处理程序,中断异常处理过程通过下节的系统中断处理来进行分析。
3.4 异常处理的返回
异常处理完成之后,返回被打断程序继续执行,具体操作如下:
-
恢复被打断程序运行时寄存器数据
-
恢复程序运行时状态CPSR
-
通过进入异常时保存的返回地址,返回到被打断程序继续执行
3.4.1 异常返回地址
一条指令的执行分为:取指,译码,执行三个主要阶段, CPU由于使用流水线技术,造成当前执行指令的地址应该是PC – 8(32位机一条指令四个字节),那么执行指令的下条指令应该是PC – 4。在异常发生时,CPU自动会将将PC – 4 的值保存到LR里,但是该值是否正确还要看异常类型才能决定。
各模式的返回地址说明如下:
(1)一般/快速中断请求:
快速中断请求和一般中断请求返回处理是一样的。通常处理器执行完当前指令后,查询FIQ/IRQ中断引脚,并查看是否允许FIQ/IRQ中断,如果某个中断引脚有效,并且系统允许该中断产生,处理器将产生FIQ/IRQ异常中断,当FIQ/IRQ异常中断产生时,程序计数器pc的值已经更新,它指向当前指令后面第3条指令(对于ARM指令,它指向当前指令地址加12字节的位置;对于Thumb指令,它指向当前指令地址加6字节的位置),当FIQ/IRQ异常中断产生时,处理器将值(pc-4)保存到FIQ/IRQ异常模式下的寄存器lr_irq/lr_irq中,它指向当前指令之后的第2条指令,因此正确返回地址可以通过下面指令算出:
SUBS PC,LR_irq,#4 ; 一般中断
SUBS PC,LR_fiq,#4 ; 快速中断
注:LR_irq/LR_fiq分别为一般中断和快速中断异常模式下LR,并不存在LR_xxx寄存器,为方便读者理解加上_xxx,下同。
(2)预取指中止异常:
在指令预取时,如果目标地址是非法的,该指令被标记成有问题的指令,这时,流水线上该指令之前的指令继续执行,当执行到该被标记成有问题的指令时,处理器产生指令预取中止异常中断。发生指令预取异常中断时,程序要返回到该有问题的指令处,重新读取并执行该指令,因此指令预取中止异常中断应该返回到产生该指令预取中止异常中断的指令处,而不是当前指令的下一条指令。
指令预取中止异常中断由当前执行的指令在ALU里执行时产生,当指令预取中止异常中断发生时,程序计数器pc的值还未更新,它指向当前指令后面第2条指令(对于ARM指令,它指向当前指令地址加8字节的位置;对于Thumb指令,它指向当前指令地址加4字节的位置)。此时处理器将值(pc-4)保存到lr_abt中,它指向当前指令的下一条指令,所以返回操作可以通过下面指令实现:
SUBS PC,LR_abt,#4(3)未定义指令异常:
未定义指令异常中断由当前执行的指令在ALU里执行时产生,当未定义指令异常中断产生时,程序计数器pc的值还未更新,它指向当前指令后面第2条指令(对于ARM指令,它指向当前指令地址加8字节的位置;对于Thumb指令,它指向当前指令地址加4字节的位置),当未定义指令异常中断发生时,处理器将值(pc-4)保存到lr_und中,此时(pc-4)指向当前指令的下一条指令,所以从未定义指令异常中断返回可以通过如下指令来实现:
MOV PC, LR_und(4)软中断指令(SWI)异常:
SWI异常中断和未定义异常中断指令一样,也是由当前执行的指令在ALU里执行时产生,当SWI指令执行时,pc的值还未更新,它指向当前指令后面第2条指令(对于ARM指令,它指向当前指令地址加8字节的位置;对于Thumb指令,它指向当前指令地址加4字节的位置),当未定义指令异常中断发生时,处理器将值(pc-4)保存到lr_svc中,此时(pc-4)指向当前指令的下一条指令,所以从SWI异常中断处理返回的实现方法与从未定义指令异常中断处理返回一样:
MOV PC, LR_svc
(5)数据中止异常:
发生数据访问异常中断时,程序要返回到该有问题的指令处,重新访问该数据,因此数据访问异常中断应该返回到产生该数据访问中止异常中断的指令处,而不是当前指令的下一条指令。数据访问异常中断由当前执行的指令在ALU里执行时产生,当数据访问异常中断发生时,程序计数器pc的值已经更新,它指向当前指令后面第3条指令(对于ARM指令,它指向当前指令地址加12字节的位置;对于Thumb指令,它指向当前指令地址加6字节的位置)。此时处理器将值(pc-4)保存到lr_abt中,它指向当前指令后面第2条指令,所以返回操作可以通过下面指令实现:
SUBS PC, LR_abt, #8
上述每一种异常发生时,其返回地址都要根据具体异常类型进行重新修复返回地址,「再次强调下,被打断程序的返回地址保存在对应异常模式下的LR_excep里」。
3.4.2 模式恢复
异常发生后,进入异常处理程序时,将用户程序寄存器R0~R12里的数据保存在了异常模式下栈里面,异常处理完返回时,要将栈里保存的的数据再恢复回原先R0~R12里。
毫无疑问在异常处理过程中必须要保证异常处理入口和出口时栈指针SP_excep要一样,否则恢复到R0~R12里的数据不正确,返回被打断程序时执行现场不一致,出现问题,虽然将执行现场恢复了,但是此时还是在异常模式下,CPSR里的状态是异常模式下状态。
因此要恢复SPSR_excep里的保存状态到CPSR里,SPSR_excep是被打断程序执行时的状态,在恢复SPSR_excep到CPSR的同时,CPU的模式和状态从异常模式切换回了被打断程序执行时的模式和状态。
此刻程序现场恢复了,状态也恢复了,但PC里的值仍然指向异常模式下的地址空间,我们要让CPU继续执行被打断程序,因此要再手动改变PC的值为进入异常时的返回地址,该地址在异常处理入口时已经计算好,直接将PC = LR_excep即可。
上述操作可以一步一步实现,但是通常我们可以通过一条指令实现上述全部操作:
LDMFD SP_excp!, {r0-r12, pc}^
注:SP_excep为对应异常模式下SP,^符号表示恢复SPSR_excep到CPSR。
LDMFD:加载多个寄存器(Load Multiple Full Descending)。FD表示“Full Descending”,这是一种堆栈的操作模式,堆栈是向下生长的。SP_excp!:SP_excp是堆栈指针寄存器,!表示在执行指令后更新堆栈指针的值。{r0-r12, pc}:这是一个寄存器列表,表示要从堆栈中加载寄存器 r0 到 r12 以及程序计数器(pc)的值。^ 表示在执行完加载操作后,更新程序状态寄存器(CPSR)
3.5 异常与模式关系
-
reset异常进入SVC模式
-
fiq快速中断请求异常进入快中断模式,支持高速数传输及通道处理(FIQ异常响应时进入此模式)
-
irq中断请求异常进入中断模式,用于通用中断处理,(IRQ异常响应时进入此模式)
-
prefetch预取指中止,数据中止异常进入中止模式,用于支持虚拟内存和/或存储器保护
-
undef未定义指令异常进入未定义模式,支持硬件协处理器的软件仿真(未定义指令异常响应时进入此模式)
-
swi软件中断,复位异常进入管理模式,操作系统保护代码(系统复位和软件中断响应时进入此模式)
3.6 IRQ中断异常
3.6.1 中断的概念
什么是中断,我们从一个生活的例子引入。我们正在家中看书,突然电话铃响了,你放下书本,去接电话,和来电话的人交谈,然后放下电话,回来继续看你的书。这就是生活中的"中断"的现象,也就是正常的工作过程被外部的事件打断了。
在处理器中,所谓中断,是一个过程,即CPU在正常执行程序的过程中,遇到外部/内部的紧急事件需要处理,暂时中断(中止)当前程序的执行,而转去为事件服务,待服务完毕,再返回到暂停处(断点)继续执行原来的程序。为事件服务的程序称为中断服务程序或中断处理程序。
严格地说,上面的描述是针对硬件事件引起的中断而言的。用软件方法也可以引起中断,即事先在程序中安排特殊的指令,CPU执行到该类指令时,转去执行相应的一段预先安排好的程序,然后再返回来执行原来的程序,这可称为软中断。把软中断考虑进去,可给中断再下一个定义:中断是一个过程,是CPU在执行当前程序的过程中因硬件或软件的原因插入了另一段程序运行的过程。因硬件原因引起的中断过程的出现是不可预测的,即随机的,而软中断是事先安排的。
3.6.2 中断处理流程
中断异常发生时,整个处理流程:
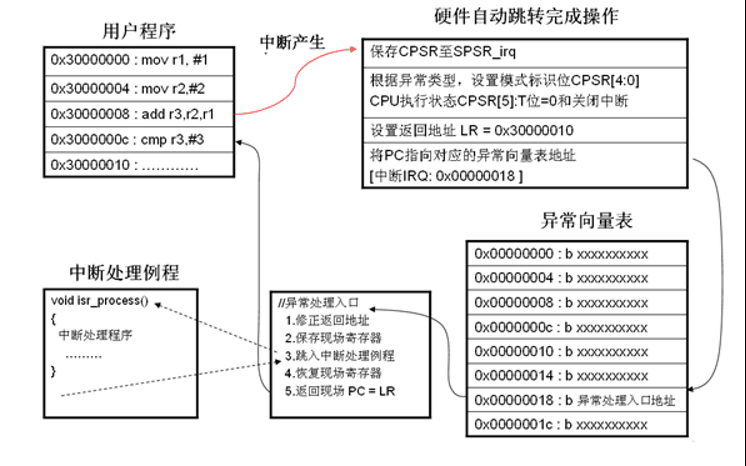
如上图所示:
(1)执行执行到0x30000008时产生中断
(2)cpu执行4大步3小步
1) 保存CPSR到SPSR_irq
2) 根据异常类型,设置模式标识位CPSR[4:0],CPU执行状态CPSR[5]:T位=0和关闭中断
3) 设置返回地址LR=0x30000010
4) 将PC指向对应的异常向量表地址 [中断IRQ:0x00000018]
(3)进入到异常向量表后执行 b 指令,跳转到异常处理函数
(4)异常处理函数需要执行以下操作
1) 修正返回地址 SUBS PC,LR_irq,#4 ,即0x3000000C
2) 保存现场寄存器
3) 跳入中断处理函数isr_proccess(),执行中断处理程序
4) 恢复现场寄存器
5) 返回现场PC=LR
(5)程序又回到0x3000000C位置,继续执行
3.7 SWI异常
3.7.1 SWI指令
SWI指令的格式为:
SWI{条件} 24位的立即数
SWI指令用于产生软件中断,以便用户程序能调用操作系统的系统例程。操作系统在SWI的异常处理程序中提供相应的系统服务,指令中24位的立即数指定用户程序调用系统例程的类型,相关参数通过通用寄存器传递,当指令中24位的立即数被忽略时,用户程序调用系统例程的类型由通用寄存器R0的内容决定,同时,参数通过其他通用寄存器传递。
举例:
SWI 0x02 ;该指令调用操作系统编号位02的系统例程。
3.7.2 BKPT指令
BKPT指令的格式为:BKPT 16位的立即数 BKPT指令产生软件断点中断,可用于程序的调试。
3.7.3 举例
以下是一个包含异常向量表的代码,程序值填写了reset异常和swi异常的入口,其他入口地址可以用空指令nop填充在这个位置。
area first, code, readonly
code32
entry
; 定义的异常向量表
vector
b reset_handler ; 跳转到 reset_handler
nop
b swi_handler ; SWI 指令异常跳转的地址
nop
nop
nop
nop
nop
swi_handler
; swi handler code
; 异常处理首先要压栈保存处理器现场
mrs r0, cpsr
bic r0, r0, #0x1f
orr r0, r0, #0x10
msr cpsr_c, r0
;ldr r0, [lr, #-4] ; 获得SWI指令的机器码,lr前面那个指令是swi指令,下标在该指令中
;bic r0, r0, #0xff000000 ; 通过机器码获得SWI NUMBER
movs pc, lr ; lr > pc 且 spsr -> cpsr返回 SVC -> USER
reset_handler
; 初始化 SVC 模式堆栈
ldr sp, =0x40001000
; 修改当前的模式从SVC模式改变为USER模式
mrs r0, cpsr
bic r0, r0, #0x1f
orr r0, r0, #0x10
msr cpsr_c, r0
; 初始化 USER 模式堆栈
ldr sp, =0x40000800
mov r0, #1
; USER SWI
swi 5 ; open APP USER 这条语句由用户程序自己出发异常
; 观察并记录对比指令执行前后的 PC LR CPSR SPSR SP的变化
;并思考异常产生后处理器硬件自动发生了那些变化
add r1, r0, r0
stop
b stop
end
运行过程如下所示:
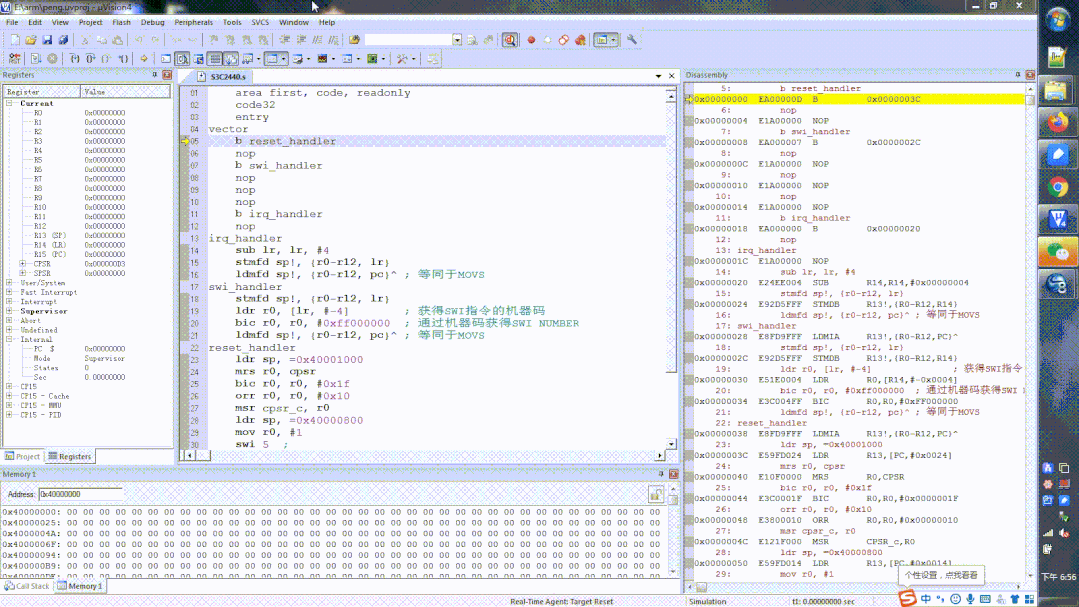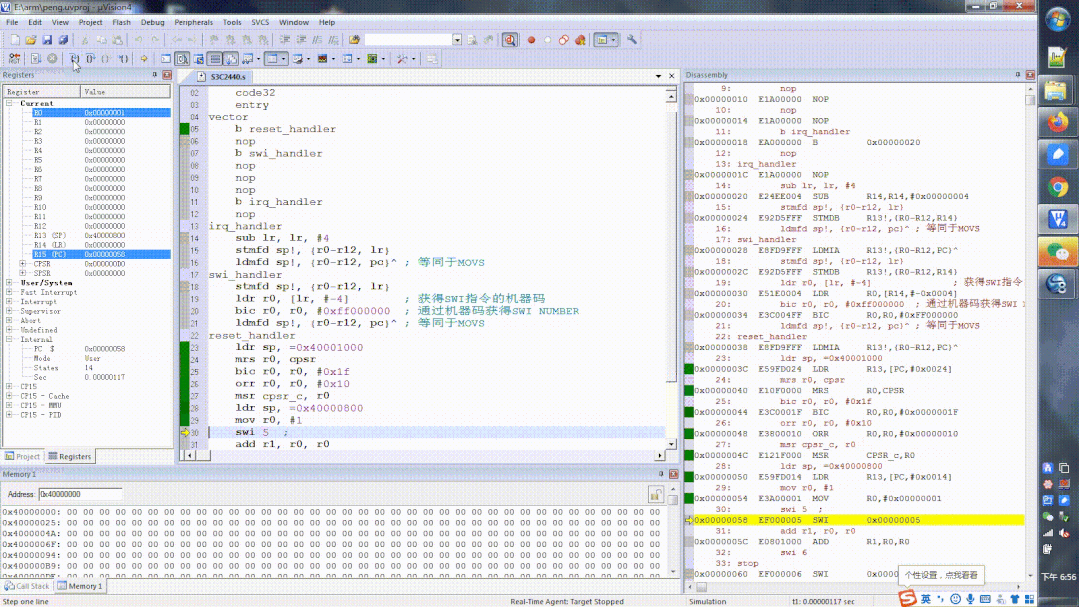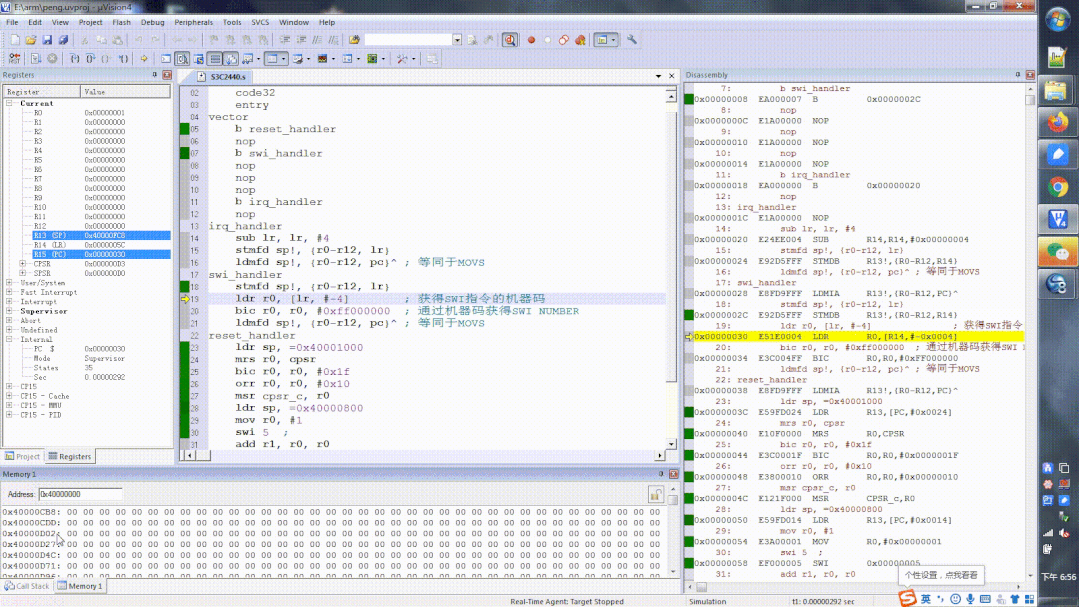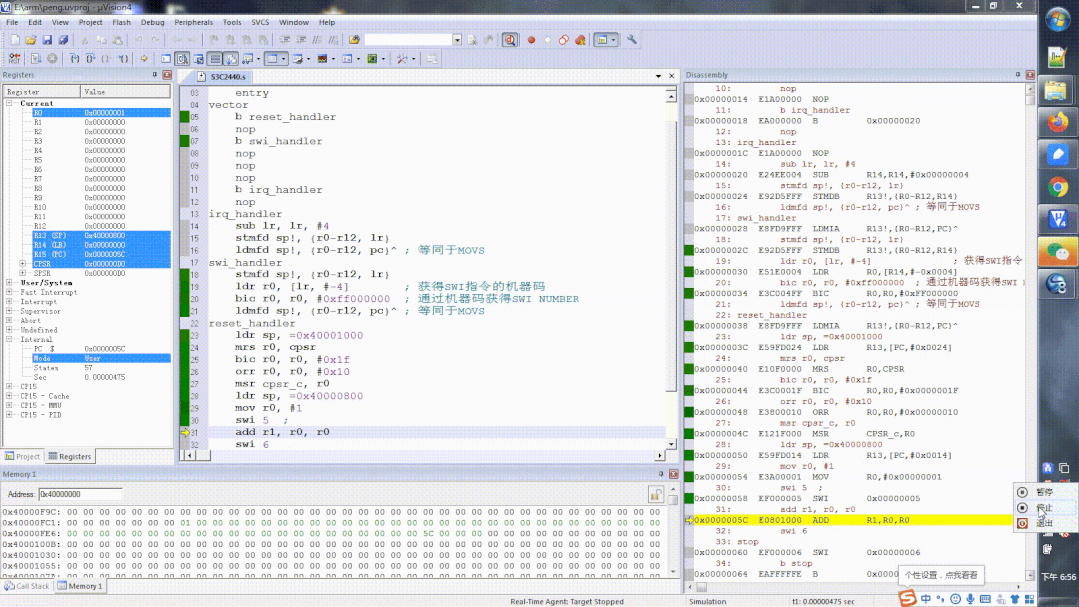
swi指令执行

主要是注意观察swi执行前和执行后,模式的变化,大家可以按照4大步3小步来分析。
swi指令执行前后对比变化
3.8 如何同时跳转并切换模式
从swi异常返回时,我们需要执行两个动作:
-
将spsr拷贝会cpsr,
-
pc = lr 跳转回原来的位置
这两个动作都必须要执行,但是如果分步执行的话,spsr拷贝回去后,当前模式就变回了usr模式,那么对应的lr的值就变成了lr_usr,此时的值0x0【之前没有执行过bl指令】,那怎么跳转会去呢?我们可以用以下命令
movs pc, lr
此命令同时执行两个动作:
pc = lr
cpsr = spsr 返回 SVC -> USER
从而实现了同时跳转并切换模式。如果入口已经使用 LDM 压栈可以用一下指令回复:
LDMFD SP_excp!, {r0-r12, pc}^
3.9 如何获取软中断号
-
要获取 SWI 指令的中断号,我们只能从 SWI 的机器码中得到对应的值,
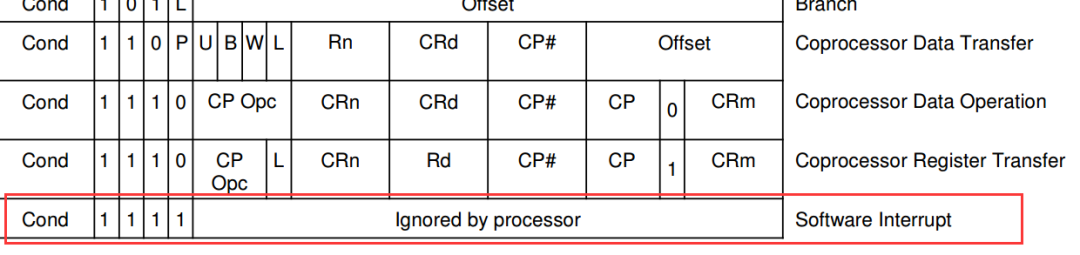
2. 而要想得到swi这条指令的内容,就要先找到这条指令的地址, 而lr的值是swi这条指令的下一条指令的地址,所以我们可以通过以下代码得到软中断号。
ldr r0, [lr, #-4] ; 获得SWI指令的机器码,lr前面那个指令是swi指令,下标在该指令中
bic r0, r0, #0xff000000 ; 通过机器码获得SWI NUMBER
3.10 系统调用与SWI
3.10.1 系统调用
linux的应用程序有很多的系统调用,比如open,read,socket等实际上会触发swi异常,触发系统调用sys_open,sys_read等,内核根据swi的值来执行具体的操作。
每个系统调用都有自己惟一的编号,系统调用函数的标识符在以下文件定义:
linux/arch/arm/kernel/calls.S
内容如下:
/* 0 */ CALL(sys_restart_syscall)
CALL(sys_exit)
CALL(sys_fork)
CALL(sys_read)
CALL(sys_write)
…………
/* 375 */ CALL(sys_setns)
CALL(sys_process_vm_readv)
CALL(sys_process_vm_writev)
CALL(sys_kcmp)
CALL(sys_finit_module)
#ifndef syscalls_counted
.equ syscalls_padding, ((NR_syscalls + 3) & ~3) - NR_syscalls
#define syscalls_counted
#endif
.rept syscalls_padding
CALL(sys_ni_syscall)
.endr
3.10.2 SWI代码片段分析
搜索下vector_swi,找到入口函数
arch\arm\kernel\entry-common.S
.align 5
ENTRY(vector_swi)
@ 保存现场
sub sp, sp, #S_FRAME_SIZE
stmia sp, {r0 - r12} @ Calling r0 - r12
add r8, sp, #S_PC
stmdb r8, {sp, lr}^ @ Calling sp, lr
mrs r8, spsr @ called from non-FIQ mode, so ok.
str lr, [sp, #S_PC] @ Save calling PC
str r8, [sp, #S_PSR] @ Save CPSR
str r0, [sp, #S_OLD_R0] @ Save OLD_R0
zero_fp
@ 获得swi的指令地址,确保是swi指令
ldr scno, [lr, #-4] @ get SWI instruction
A710( and ip, scno, #0x0f000000 @ check for SWI )
A710( teq ip, #0x0f000000 )
A710( bne .Larm710bug )
@ tbl等于数组表基地址
get_thread_info tsk
adr tbl, sys_call_table @ load syscall table pointer
ldr ip, [tsk, #TI_FLAGS] @ check for syscall tracing
@清除高8位
bic scno, scno, #0xff000000 @ mask off SWI op-code
@ #define __NR_SYSCALL_BASE 0x900000 这里swi的值实际上是0x900000 0x900001 ...所以要清除这个高位的9
eor scno, scno, #__NR_SYSCALL_BASE @ check OS number
@根据索引号,去tbl 这个数组中调用函数
@ tbl:数组表基地址, scno:要调用的sys_write()的索引值 lsl #2:左移2位,一个函数指针占据4个字节
cmp scno, #NR_syscalls @ check upper syscall limit
adr lr, ret_fast_syscall @ return address
ldrcc pc, [tbl, scno, lsl #2] @ call sys_* routine
-
这里首先获得swi这条指令的内容,swi指令位于lr-4,原因如下图

2. 然后分析确保是swi指令,也就是
and ip, scno, #0x0f000000

3. 获得全局的一个存有系统调用函数的数组的地址 4. 通过swi的值去找到这个数组的索引,执行函数
4. 汇编伪指令
4.1 MDK和GNU伪指令区别
我们在学习汇编代码的时候经过会看到以下两种风格的代码:
gnu代码开头是:
.global _start
_start: @汇编入口
ldr sp,=0x41000000
.end @汇编程序结束
MDK代码开头是:
AREA Example,CODE,READONLY ;声明代码段Example
ENTRY ;程序入口
Start
MOV R0,#0
OVER
END
这两种风格的代码是要使用不同的编译器,我们之前的实例代码都是MDK风格的。
但是现在只需要学习GNU风格的汇编代码,因为做Linux驱动开发必须掌握的linux内核、uboot,而这两个软件就是GNU风格的。
4.2 GNU汇编书写格式
4.2.1 代码行中的注释符号
‘@’ :整行注释符号
‘#’ :语句分离符号
‘#’ 或 ‘$’ :直接操作数前缀
4.2.2 全局标号
标号只能由a~z,A~Z,0~9,“.”,_等(由点、字母、数字、下划线等组成,除局部标号外,不能以数字开头)字符组成,标号的后面加“:”。
段内标号的地址值在汇编时确定;
段外标号的地址值在连接时确定。
4.2.3 局部标号
局部标号主要在局部范围内使用而且局部标号可以重复出现。它由两部组成开头是一个0-99直接的数字局部标号 后面加“:”
F:指示编译器只向前搜索,代码行数增加的方向 / 代码的下一句
B:指示编译器只向后搜索,代码行数减小的方向
注意局部标号的跳转,就近原则「举例:」
文件位置
arch/arm/kernel/entry-armv.S


4.3 伪操作
4.3.1 符号定义伪指令
| 标号 | 含义 |
|---|---|
| .global | 使得符号对连接器可见,变为对整个工程可用的全局变量 |
| _start | 汇编程序的缺省入口是_ start标号,用户也可以在连接脚本文件中用ENTRY标志指明其它入口点. |
| .local | 表示符号对外部不可见,只对本文件可见 |
4.3.2 数据定义(Data Definition)伪操作
数据定义伪操作一般用于为特定的数据分配存储单元,同时可完成已分配存储单元的初始化。常见的数据定义伪操作有如下几种:
| 标号 | 含义 |
|---|---|
| .byte | 单字节定义 0x12,‘a’,23 【必须偶数个】 |
| .short | 定义2字节数据 0x1234,65535 |
| .long /.word | 定义4字节数据 0x12345678 |
| .quad | 定义8字节 .quad 0x1234567812345678 |
| .float | 定义浮点数 .float 0f3.2 |
| .string/.asciz/.ascii | 定义字符串 .ascii “abcd\0”, 注意:.ascii 伪操作定义的字符串需要每行添加结尾字符 '\0',其他不需要 |
| .space/.skip | 用于分配一块连续的存储区域并初始化为指定的值,如果后面的填充值省略不写则在后面填充为0; |
| .rept | 重复执行接下来的指令,以.rept开始,以.endr结束 |
【举例】
.word
val: .word 0x11223344
mov r1,#val ;将值0x11223344设置到寄存器r1中
.space
label: .space size,expr ;expr可以是4字节以内的浮点数
a: space 8, 0x1
.rept
.rept cnt ;cnt是重复次数
.endr
注意:
-
变量的定义放在,stop后,.end前
-
标号是地址的助记符,标号不占存储空间。位置在end前就可以,相对随意。
4.3.3 if选择
语法结构
.if logical-expressing
……
.else
……
.endif
类似c语言里的条件编译 。
【举例】
.if val2==1
mov r1,#val2
.endif
4.3.4 macro宏定义
.macro,.endm 宏定义类似c语言里的宏函数 。
macro伪操作可以将一段代码定义为一个整体,称为宏指令。然后就可以在程序中通过宏指令多次调用该段代码。
语法格式:
.macro {$label} 名字{$parameter{,$parameter}…}
……..code
.endm
其中,$标号在宏指令被展开时,标号会被替换为用户定义的符号。
宏操作可以使用一个或多个参数,当宏操作被展开时,这些参数被相应的值替换。
「注意」:先定义后使用
举例:
「【例1】:没有参数的宏实现子函数返回」
.macro MOV_PC_LR
MOV PC,LR
.endm
调用方式如下:
MOV_PC_LR
「【例2】:带参数宏实现子函数返回」
.macro MOV_PC_LR ,param
mov r1,\param
MOV PC,LR
.endm
调用方法如下:
MOV_PC_LR #12
4.4 杂项伪操作
| 标号 | 含义 |
|---|---|
| .global/ | 用来声明一个全局的符号 |
| .arm | 定义一下代码使用ARM指令集编译 |
| .thumb | 定义一下代码使用Thumb指令集编译 |
| .section | .section expr 定义一个段。expr可以使.text .data. .bss |
| .text | .text {subsection} 将定义符开始的代码编译到代码段 |
| .data | .data {subsection} 将定义符开始的代码编译到数据段,初始化数据段 |
| .bss | .bss {subsection} 将变量存放到.bss段,未初始化数据段 |
| .align | .align{alignment}{,fill}{,max} 通过用零或指定的数据进行填充来使当前位置与指定边界对齐 |
| .align 4 --- 16字节对齐 2的4次方 | |
| .align (4) --- 4字节对齐 | |
| .org | .org offset{,expr} 指定从当前地址加上offset开始存放代码,并且从当前地址到当前地址加上offset之间的内存单元,用零或指定的数据进行填充 |
| .extern | 用于声明一个外部符号,用于兼容性其他汇编 |
| .code 32 | 同.arm |
| .code 16 | 同.thumb |
| .weak | 用于声明一个弱符号,如果这个符号没有定义,编译就忽略,而不会报错 |
| .end | 文件结束 |
| .include | .include “filename” 包含指定的头文件, 可以把一个汇编常量定义放在头文件中 |
| .equ | 格式:.equ symbol, expression把某一个符号(symbol)定义成某一个值(expression).该指令并不分配空间,类似于c语言的 #define |
| .set | 给一个全局变量或局部变量赋值,和.equ的功能一样 |
举例:.set
.set start, 0x40
mov r1, #start ;r1里面是0x40
举例 .equ
.equ start, 0x40
mov r1, #start ;r1里面是0x40
#define PI 3.1415
等价于
.equ PI, 31415
4.5 GNU伪指令
关键点:伪指令在编译时会转化为对应的ARM指令
(1)ADR伪指令 :该指令把标签所在的地址加载到寄存器中。ADR伪指令为小范围地址读取伪指令,使用的相对偏移范围:当地址值是字节对齐 (8位) 时,取值范围为-255~255,当地址值是字对齐 (32位) 时,取值范围为-1020~1020。语法格式:
ADR{cond} register,label
ADR R0, lable
(2)ADRL伪指令:将中等范围地址读取到寄存器中
ADRL伪指令为中等范围地址读取伪指令。使用相对偏移范围:当地址值是字节对齐时,取值范围为-64~64KB;当地址值是字对齐时,取值范围为-256~256KB
语法格式:
ADRL{cond} register,label
ADRL R0,lable
(3)LDR伪指令: LDR伪指令装载一个32位的常数和一个地址到寄存器。语法格式:
LDR{cond} register,=[expr|label-expr]
LDR R0,=0XFFFF0000 ;mov r1,#0x12 对比一下
注意:(a)ldr伪指令和ldr指令区分 下面是ldr伪指令:
ldr r1,=val @ r1 = val 是伪指令,将val标号地址赋给r1
【与MDK不一样,MDK只支持ldr r1,=val】
下面是ldr指令:
ldr r2,val @ r1 = *val 是arm指令,将标号val地址里的内容给r2
val: .word 0x11223344
(b)如何利用ldr伪指令实现长跳转
ldr pc,=32位地址
(c)编码中解决非立即数的问题 用arm伪指令ldr
ldr r0,=0x999 ;0x999 不是立即数,
4.6 GNU汇编的编译
4.6.1 不含lds文件的编译
假设我们有以下代码,包括1个main.c文件,1个start.s文件:start.s
.global _start
_start: @汇编入口
ldr sp,=0x41000000
b main
.global mystrcopy
.text
mystrcopy: //参数dest->r0,src->r2
LDRB r2, [r1], #1
STRB r2, [r0], #1
CMP r2, #0 //判断是不是字符串尾
BNE mystrcopy
MOV pc, lr
stop:
b stop @死循环,防止跑飞 等价于while(1)
.end @汇编程序结束
main.c
extern void mystrcopy(char *d,const char *s);
int main(void)
{
const char *src ="yikoulinux";
char dest[20]={};
mystrcopy(dest,src);//调用汇编实现的mystrcopy函数
while(1);
return 0;
}
Makefile编写方法如下:
TARGET=start
TARGETC=main
all:
arm-none-linux-gnueabi-gcc -O0 -g -c -o $(TARGETC).o $(TARGETC).c
arm-none-linux-gnueabi-gcc -O0 -g -c -o $(TARGET).o $(TARGET).s
#arm-none-linux-gnueabi-gcc -O0 -g -S -o $(TARGETC).s $(TARGETC).c
arm-none-linux-gnueabi-ld $(TARGETC).o $(TARGET).o -Ttext 0x40008000 -o $(TARGET).elf
arm-none-linux-gnueabi-objcopy -O binary -S $(TARGET).elf $(TARGET).bin
clean:
rm -rf *.o *.elf *.dis *.bin
Makefile含义如下:
-
定义环境变量TARGET=start,start为汇编文件的文件名
-
定义环境变量TARGETC=main,main为c语言文件
-
目标:all,4~8行是该指令的指令语句
-
将main.c编译生成main.o,$(TARGETC)会被替换成main
-
将start.s编译生成start.o,$(TARGET)会被替换成start
-
4-5也可以用该行1条指令实现
-
通过ld命令将main.o、start.o链接生成start.elf,-Ttext 0x40008000表示设置代码段起始地址为0x40008000
-
通过objcopy将start.elf转换成start.bin文件,-O binary (或--out-target=binary) 输出为原始的二进制文件,-S (或 --strip-all)输出文件中不要重定位信息和符号信息,缩小了文件尺寸,
-
clean目标
-
clean目标的执行语句,删除编译产生的临时文件
【补充】
-
gcc的代码优化级别,在 makefile 文件中的编译命令 4级 O0 -- O3 数字越大,优化程度越高。O3最大优化
-
volatile作用 volatile修饰的变量,编译器不再进行优化,每次都真正访问内存地址空间。
4.6.2 依赖lds文件编译
实际的工程文件,段复杂程度远比我们这个要复杂的多,尤其Linux内核有几万个文件,段的分布及其复杂,所以这就需要我们借助lds文件来定义内存的分布。
main.c和start.s和上一节一致。
map.lds
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
/*OUTPUT_FORMAT("elf32-arm", "elf32-arm", "elf32-arm")*/
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x40008000;
. = ALIGN(4);
.text :
{
.start.o(.text)
*(.text)
}
. = ALIGN(4);
.rodata :
{ *(.rodata) }
. = ALIGN(4);
.data :
{ *(.data) }
. = ALIGN(4);
.bss :
{ *(.bss) }
}
解释一下上述的例子:
-
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm") 指定输出object档案预设的binary 文件格式。可以使用objdump -i列出支持的binary 文件格式;
-
OUTPUT_ARCH(arm) 指定输出的平台为arm,可以透过objdump -i查询支持平台;
-
ENTRY(_start) :将符号_start的值设置成入口地址;
-
. = 0x40008000: 把定位器符号置为0x40008000(若不指定, 则该符号的初始值为0);
-
.text : { .start.o(.text) *(.text) } :前者表示将start.o放到text段的第一个位置,后者表示将所有(*符号代表任意输入文件)输入文件的.text section合并成一个.text section;
-
.rodata : { *(.data) } : 将所有输入文件的.rodata section合并成一个.rodata section;
-
.data : { *(.data) } : 将所有输入文件的.data section合并成一个.data section;
-
.bss : { *(.bss) } : 将所有输入文件的.bss section合并成一个.bss section;该段通常存放全局未初始化变量
-
. = ALIGN(4);表示下面的段4字节对齐
连接器每读完一个section描述后, 将定位器符号的值增加该section的大小。
来看下,Makefile应该如何写:
# CORTEX-A9 PERI DRIVER CODE
# VERSION 1.0
# ATHUOR 一口Linux
# MODIFY DATE
# 2020.11.17 Makefile
#=================================================#
CROSS_COMPILE = arm-none-linux-gnueabi-
NAME =start
CFLAGS=-mfloat-abi=softfp -mfpu=vfpv3 -mabi=apcs-gnu -fno-builtin -fno-builtin-function -g -O0 -c
LD = $(CROSS_COMPILE)ld
CC = $(CROSS_COMPILE)gcc
OBJCOPY = $(CROSS_COMPILE)objcopy
OBJDUMP = $(CROSS_COMPILE)objdump
OBJS=start.o main.o
#================================================#
all: $(OBJS)
$(LD) $(OBJS) -T map.lds -o $(NAME).elf
$(OBJCOPY) -O binary $(NAME).elf $(NAME).bin
$(OBJDUMP) -D $(NAME).elf > $(NAME).dis
%.o: %.S
$(CC) $(CFLAGS) -c -o $@ $<
%.o: %.s
$(CC) $(CFLAGS) -c -o $@ $<
%.o: %.c
$(CC) $(CFLAGS) -c -o $@ $<
clean:
rm -rf $(OBJS) *.elf *.bin *.dis *.o
编译结果如下:
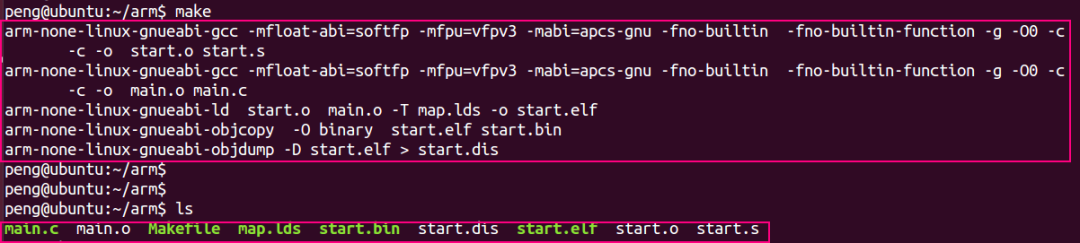
最终生成start.bin,改文件可以烧录到开发板测试,因为本例没有直观现象,后续文章我们加入其它功能再测试。
【注意】
-
其中交叉编译工具链「arm-none-linux-gnueabi-」 要根据自己实际的平台来选择,本例是基于三星的exynos-4412工具链实现的。
-
地址0x40008000也不是随便选择的,

exynos4412 地址分布
读者可以根据自己手里的开发板对应的soc手册查找该地址。
4.6.3 linux内核的异常向量表
linux内核的内存分布也是依赖lds文件定义的,linux内核的编译我们暂不讨论,编译好之后会再以下位置生成对应的lds文件:
arch/arm/kernel/vmlinux.lds
我们看下该文件的部分内容:
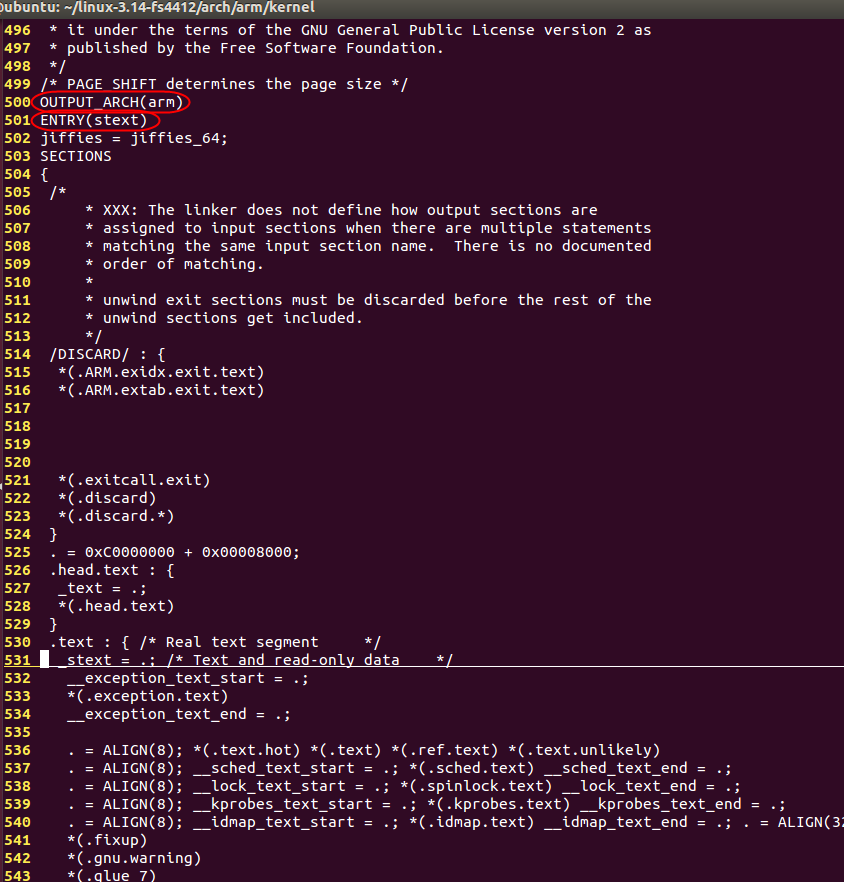
vmlinux.lds
-
OUTPUT_ARCH(arm)制定对应的处理器;
-
ENTRY(stext)表示程序的入口是stext。
同时我们也可以看到linux内存的划分更加的复杂,后续我们讨论linux内核,再继续分析该文件。
4.6.4 elf文件和bin文件区别
1) ELF
ELF文件格式是一个开放标准,各种UNIX系统的可执行文件都采用ELF格式,它有三种不同的类型:
-
可重定位的目标文件(Relocatable,或者Object File)
-
可执行文件(Executable)
-
共享库(Shared Object,或者Shared Library)
ELF格式提供了两种不同的视角,链接器把ELF文件看成是Section的集合,而加载器把ELF文件看成是Segment的集合。
2) bin
BIN文件是直接的二进制文件,内部没有地址标记。bin文件内部数据按照代码段或者数据段的物理空间地址来排列。一般用编程器烧写时从00开始,而如果下载运行,则下载到编译时的地址即可。
在Linux OS上,为了运行可执行文件,他们是遵循ELF格式的,通常gcc -o test test.c,生成的test文件就是ELF格式的,这样就可以运行了,执行elf文件,则内核会使用加载器来解析elf文件并执行。
在Embedded中,如果上电开始运行,没有OS系统,如果将ELF格式的文件烧写进去,包含一些ELF文件的符号表字符表之类的section,运行碰到这些,就会导致失败,如果用objcopy生成纯粹的二进制文件,去除掉符号表之类的section,只将代码段数据段保留下来,程序就可以一步一步运行。
elf文件里面包含了符号表等。BIN文件是将elf文件中的代码段,数据段,还有一些自定义的段抽取出来做成的一个内存的镜像。
并且elf文件中代码段数据段的位置并不是它实际的物理位置。他实际物理位置是在表中标记出来的。
4.7 gcc内联汇编
内联汇编即在C中直接使用汇编语句进行编程,使程序可以在C程序中实现C语言不能完成的一些工作,例如,在下面几种情况中必须使用内联汇编或嵌入型汇编。
-
程序中使用饱和算术运算(Saturating Arithmetic)
-
程序需要对协处理器进行操作
-
在C程序中完成对程序状态寄存器的操作
格式:
__asm__ __volatile__("asm code"
:output
:input
:changed registers);
asm或__asm__开头,小括号+分号,括号内容写汇编指令。
4.8 结构体优化性能
对于大量使用全局变量的地方,需要使用结构体以优化性能。
因为所有访问结构体成员的操作只需要加载一次基地址即可。
使用结构体就可以大大的节省指令周期,而节省指令周期对于提高cpu的运行效率自然不言而喻。