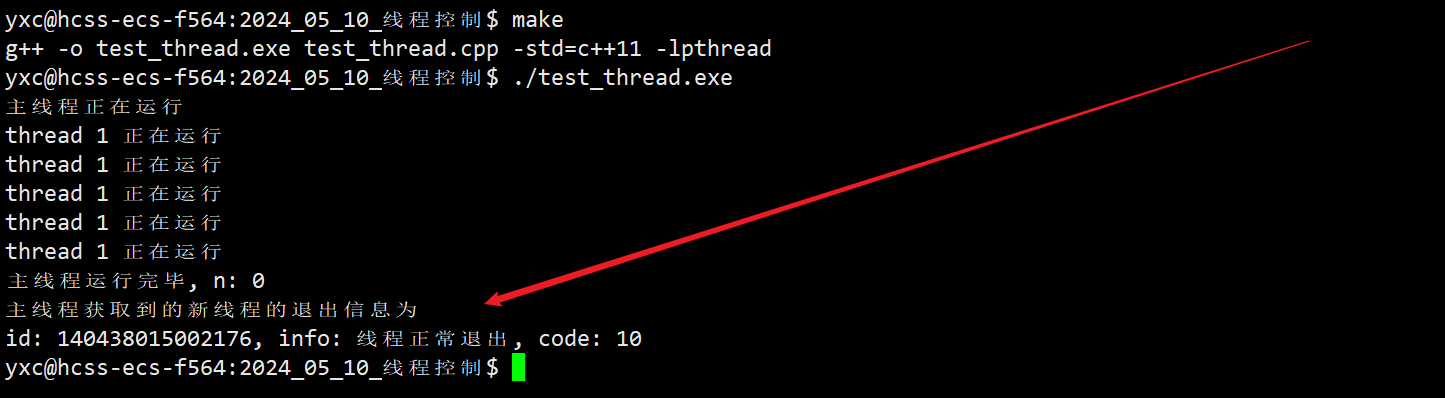
目录
提取GPS信息
提取日期
如下一些关键的定量信息值得“手写”正则表达式:
- GPS位置;
- 日期;
- 价格;
- 数字。
和上述可以通过正则表达式轻松捕获的信息相比,其他一些重要的自然语言信息需要更复杂的模式:
- 问题触发词;
- 问题目标词;
- 命名实体。
提取GPS信息
GPS位置时我们希望正则表达式从文本中提取的各种数值类型数据的典型代表。GPS位置具有成对的经纬度数值。它们有时还包括第三个数值,如高度或海拔高度,但暂时先忽略它。我们只提取十进制的经纬度对,用度数表示。这么模式适用于许多谷歌地图的URL地址。虽然严格说URL不是自然语言,但它们通常是非结构化文本数据的一部分,并且我们希望提取这种信息,从而让聊天机器人能够像了解事物一样了解位置信息。
我们使用十进制数字模式,但增加更多约束,确保该值在纬度和经度的有效范围内。最北到北极(+90度),最高到南极(-90度),具体代码:
import re
lat=r'([-]?[0-9]?[0-9][.][0-9]{2,10})'
lon=r'([-]?1?[0-9]?[0-9][.][0-9]{2,10})'
sep=r'[,/ ]{1,3}'
re_gps=re.compile(lat+sep+lon)
print(re_gps.findall('http://...maps/@34.0551066,-118.2496763'))
print(re_gps.findall("Zig Zag Cafe is at 45.344, -121.9323 on my GPS"))
数值类数据很容易提取,特别是当数字式可机读字符串的一部分的时候。URL和其他可机读字符串以可推测的顺序、格式或单位放置纬度和经度等数字,为提取提供了方便。上述模式还可以处理一些超出真实世界的经度和维度值,它可以较好的处理从地图Web应用程序中复制的大部分URL。
提取日期
提取日期比提取GPS坐标要难很多。日期更接近自然语言,可以通过不同的方言表达类似的事物。在美国,17年圣诞节的表示是“12/25/17”,而在欧洲,却表示为“25/12/17”。我们可以检查用户区域设置,并假设在同一个区域,日期表示方式是一样的。但这种假设可能在实际中是不成立的。
因此,大多数日期和时间提取器尝试适配上面两种日/月的表示顺序,并检查以确保是有效的日期。这也是当我们看到这样的日期时大脑的工作方式。即使是美国英语使用者,圣诞节在欧洲,也能认出“25/12/17”是一个假期。
这种在计算机编程中适用的“鸭子类型”方法也适用于自然语言。如果它看起来像一只鸭子并且表现得像是一一只鸭子,那么它可能就是一只鸭子。如果它看起来像日期并且表现得像日期,那么它可能就是日期。我们将在其他自然语言处理任务重也使用这种“先斩后奏”的方法。下面将尝试一系列方法并选择结果正确的方法,这里将尝试使用提取器或生成器,然后在其上运行验证器来判断它是否合理。
对聊天机器人来说,这是一种特别强大的方法,允许我们组合多个自然语言生成器的最佳结果。为了改善体验,可以生成大量回复并选择具备最佳拼写、语法和情感的回复,例如:
us=r'((([01]?\d)[-/]([0123]?\d))([-/]([0123]\d)\d\d)?)'
mdy=re.findall(us,"Santa came 12/25/2017.An elf appeared 12/12")
print(mdy)![]()
通过把月、日和年转换成整数并使用有意义的名称标注这些数字信息,我们可以使用列表解析式为提取的数据提供结构化表示,如下所示:
dates=[{'mdy':x[0],'my':x[1],'m':int(x[2]),'d':int(x[3]),'y':int(x[4].lstrip('/') or 0),'c':int(x[5] or 0)} for x in mdy]
print(dates)
即使对于这些简单的日期,也不可能设计一个可以处理“12/12”这个日期中存在的奇异的正则表达式。日期表示中往往存在含糊不清的情况,只有人可以通过使用圣诞节相关的知识或作者的意图来猜测。例如,“12/12”可能表示:
- 2017年12月12日——基于指代消解估计得到的年份的月/日格式;
- 2018年12月12日——出版时当年年份的月/日格式;
- 2012年12月——2012年的月/年格式。
因为月/日在美国日期和正则表达式中都出现在年份的前面,所以“12/12”被认为是某个未知年份的12月12日。我们可以使用在内存的结构化数据的上下文中最近读取到的年份来填充任何缺失的数字字段:
for i,d in enumerate(dates):
for k,v in d.items():
if not v:
d[k]=dates[max(i-1,0)][k]
print(dates)
from datetime import date
datetimes=[date(d['y'],d['m'],d['d']) for d in dates]
print(datetimes)
上面是从自然语言文本中提取日期信息的基本但相当鲁棒的方法。如果将该方法用作生产系统的日期提取器,还需要做的主要工作是添加一些适用于我们应用程序的异常捕获和上下文管理。
我们可以通过一些硬编码逻辑来处理极端情况以及月甚至日的自然语言名称。但是再复杂的逻辑也无法处理“12/11”中存在的日期歧义,它可能是:
- 某个看到或听到过年份的12月11日;
- 11月12日;
- 2011年12月;
- 2012年11月。
即使是人脑也无法解决一些自然语言的歧义问题。但是,需要确保日期提取器可以通过在正则表达式中颠倒月和日来处理欧洲日/月顺序的日期:
eu=r'((([0123]?\d)[-/]([01]?\d))([-/]([0123]\d)?\d\d)?)'
dmy=re.findall(eu,"Alan Mathison Turing OBE FRS(23/6/1912-7/6/1954) as an English computer scientist.")
print(dmy)
dmy=re.findall(eu,"Alan Mathison Turing OBE FRS(23/6/12-7/6/54) as an English computer scientist.")
print(dmy)
正则表达式能够正确的从文字中提取日期。但上面的例子中已经把“June”转换成了数字“6”。我们希望聊天机器人能够从没有经过人工预处理的文章中提取日期,从而可以研读信息并学习导入日期。如果希望正则表达式能够处理更自然的像是百科文档中出现的日期信息,就需要再日期提取正则表达式中添加诸如“June”(及其所有缩写)之类的单词。
我们不需要任何特殊的符号来表示词组(按顺序组合在一起的字符),完全按照这些词组在输入中的拼写顺序,可以直接把它们写到正则表达式中,包括大小写。我们所要做的就是在正则表达式中使用一个OR符号(|)隔开这些词组。而且需要确保这个正则表达式既可以处理美国月/日的日期格式,也可以处理欧洲的日期格式。将这两个等同的日期“拼写”添加到正则表达式中,并在它们之间使用一个OR(|)作为正则表达式中决策树的分支。
我们使用一些命名分组来帮助我们识别像1984年的“84”和2008年的“08”这样的年份。尝试更准确地表示想要匹配的4位数年份,从过去的0年到未来的2999年:
yr_19xx=(
r'\b(?P<yr_19xx>'+
'|'.join('{}'.format(i) for i in range(30,100))+
r'?\b'
)
yr_20xx=(
r'\b(?P<yr_20xx>' +
'|'.join('{:02d}'.format(i) for i in range(10)) + '|' +
'|'.join('{}'.format(i) for i in range(10,30))+
r')\b'
)
yr_cent=r'\b(?P<yr_cent>'+'|'.join('{}'.format(i) for i in range(1,40))+r')'
yr_ccxx=r'(?P<yr_ccxx>'+'|'.join('{:02d}'.format(i) for i in range(0,100))+r')\b'
yr_xxxx=r'\b(?P<yr_xxxx>'+yr_cent+')('+yr_ccxx+r'))\b'
yr=(
r'\b(?P<yr>'+
yr_19xx+'|'+yr_20xx+'|'+yr_xxxx+r')\b'
)
groups=list(re.finditer(yr,"0,2000,01,'08,99,1984,2030/1970 85 47 `66"))
full_years=[g['yr'] for g in groups]
print(full_years)![]()
仅仅是使用正则表达式中一些简单的年份规则,还没有用到Python,工作量就很大了。但是软件包可用于识别常见的日期格式,它们更精确、更通用。所以不需要自己编写复杂的正则表达式。上面的示例仅是提供了一种可以遵循的模式,以防将来需要使用正则表达式提取特定类型的数字。在货币数值和IP地址提取的例子中,带有命名分组的更复杂的正则表达式可能会派上用场。
在百科文章的日期中,在提取日期时添加月份名称对应的模式“June”或者“Jun”,来完成正则表达式以提取日期:
mon_words='January February March April May June July August September October November December'
mon=(r'\b('+'|'.join('{}|{}|{}|{}|{:02d}'.format(m,m[:4],m[:3],i+1,i+1) for i,m in enumerate(mon_words.split()))+r')\b')
print(re.findall(mon,"January has 31 days,February the 2nd month of 12, has 28,except in a Leap Year."))![]()
将这些正则表达式组合成一个可以处理所有日期格式的大型表达式的难点在于我们不能为分组(正则表达式中的括号内的部分)复用相同的名称。所以不能再不同格式对应的月份和年份的命名正则表达式之间使用OR。此外,表达式中需要包含日、月和年之间任意分隔符的模式。
下面是一个满足上述需求的例子:
day=r'|'.join('{:02d}|{}'.format(i,i) for i in range(1,32))
eu=(r'\b('+day+r')\b[-,/ ]{0,2}\b('+mon+r')\b[-,/ ]{0,2}\b('+yr.replace('<yr','<eu_yr')+r')\b')
us=(r'\b('+mon+r')\b[-,/ ]{0,2}\b('+day+r')\b[-,/ ]{0,2}\b('+yr.replace('<yr','<us_yr')+r')\b')
date_pattern=r'\b('+eu+'|'+us+r')\b'
print(list(re.finditer(date_pattern,'31 Oct, 1970 25/12/2017')))
最后,需要验证日趋的日期,看这个日期是否可以转换为有效的Python datetime对象:
import datetime
dates=[]
for g in groups:
#print(g.groupdict())
month_num=(g['us_mon'] or g['eu_mon']).strip()
try:
month_num=int(month_num)
except ValueError:
month_num=[w[:len(month_num)]
for w in month_num].index(month_num)+1
date=datetime.date(
int(g['us_yr'] or g['eu_yr']),
month_num,
int(g['us_day'] or g['eu_day'])
)
dates.append(date)
print(dates)日期提取器看起来运行正常,至少在这几个简单的、无歧义的日期上是这样的。
如果只要想一个最先进的日期提取器,基于统计(机器学习)的方法能够更快的满足需求。