近日,CodeFuse-CGE 项目在外滩大会展出,吸引了众多技术、产品从业者的到访,部分参观者表示“文搜代码”令人耳目一新,期待模型后续的表现。
以下是 CodeFuse-CGE 项目的相关开源介绍,如果对这部分内容感兴趣,欢迎访问我们的项目主页 GitHub - codefuse-ai/CodeFuse-CGE 为我们点赞,支持我们的项目。
01简介
Code Embedding 是一种将代码片段转化为向量表示的技术。这种表示形式使得机器学习模型能够更好地理解和处理代码,在自动化程序分析、代码搜索、代码补全,以及自动化测试等领域都起到非常重要的作用。大语言模型(Large Language Models)因为其在大量的语言数据上预训练,可以获得对语义细微表示的能力。最近,LLMs 在代码生成、代码补全等任务上都有非常出色的表现。
目前 Code Embedding 模型主要基于 Encoder 架构,如 CodeBert、Unixcoder 等。又或者基于 Encoder-Decoder 架构,如 CodeT5、CodeT5+ 等。然而局限于架构设计和模型大小,他们很难获取到更丰富的语义表示能力。
我们以 CodeQwen1.5-7B-Chat 和 Phi-3.5-mini-instruct 模型作为基座模型,通过一个交叉注意力计算模块来提取输入序列的 Embedding,将文本表征和代码表征投射到同一空间中。我们的方法可以激发出基座模型强大的代码、文本的语义表示能力。实验表明我们的方法在 CSN 和 AdvTest 这 2 个 NL2Code Benchmarks 上都有着超越 SOTA 的能力。我们将开源 CGE-Large 和 CGE-Small 两种大小的模型。
TLDR
CGE 即 Code General Embedding。我们提出了一种基于大语言模型的获取 Embedding 方案,通过 Lora 微调来借助大语言模型的语义能力,激发其语义表征能力,在 2 个 NL2Code Benchmarks 上达到了 SOTA 的表现。
🏡Homepage:
https://github.com/codefuse-ai/CodeFuse-CGE
hCGE
(Please give us your support with a Star🌟 + Fork🚀 + Watch 👀)
02 开源模型
CodeFuse-CGE-Large
huggingface 地址
https://huggingface.co/codefuse-ai/CodeFuse-CGE-Large
Model Configuration
- Base Model:CodeQwen1.5-7B-Chat
- Model Size:7B
- Embedding Dimension:1024
Requirements
flash_attn==2.4.2
torch==2.1.0
accelerate==0.28.0
transformers==4.39.2
vllm=0.5.3CodeFuse-CGE-Small
huggingface 地址
- https://huggingface.co/codefuse-ai/CodeFuse-CGE-Small
Model Configuration
- Base Model:Phi-3.5-mini-instruct
- Model Size:3.8B
- Embedding Dimension:1024
Requirements
flash_attn==2.4.2
torch==2.1.0
accelerate==0.28.0
transformers>=4.43.0How to Use?
Transformers
import torch
from transformers import AutoTokenizer, AutoModel
model_name_or_path = "codefuse-ai/CodeFuse-CGE-Large"
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, truncation_side='right', padding_side='right')
if torch.cuda.is_available():
device = 'cuda'
else:
device = 'cpu'
model.to(device)
prefix_dict = {'python':{'query':'Retrieve the Python code that solves the following query:', 'passage':'Python code:'},
'java':{'query':'Retrieve the Java code that solves the following query:', 'passage':'Java code:'},
'go':{'query':'Retrieve the Go code that solves the following query:', 'passage':'Go code:'},
'c++':{'query':'Retrieve the C++ code that solves the following query:', 'passage':'C++ code:'},
'javascript':{'query':'Retrieve the Javascript code that solves the following query:', 'passage':'Javascript code:'},
'php':{'query':'Retrieve the PHP code that solves the following query:', 'passage':'PHP code:'},
'ruby':{'query':'Retrieve the Ruby code that solves the following query:', 'passage':'Ruby code:'},
'default':{'query':'Retrieve the code that solves the following query:', 'passage':'Code:'}
}
text = ["Writes a Boolean to the stream.",
"def writeBoolean(self, n): t = TYPE_BOOL_TRUE if n is False: t = TYPE_BOOL_FALSE self.stream.write(t)"]
text[0] += prefix_dict['python']['query']
text[1] += prefix_dict['python']['passage']
embed = model.encode(tokenizer, text)
score = embed[0] @ embed[1].T
print("score", score)Vllm
我们同时适配了 vllm 的部署,来减少部署时的时延。可参考我们的 github 仓库:https://github.com/codefuse-ai/CodeFuse-CGE
from vllm import ModelRegistry
from utils.vllm_codefuse_cge_large import CodeFuse_CGE_Large
from vllm.model_executor.models import ModelRegistry
from vllm import LLM
def always_true_is_embedding_model(model_arch: str) -> bool:
return True
ModelRegistry.is_embedding_model = always_true_is_embedding_model
ModelRegistry.register_model("CodeFuse_CGE_Large", CodeFuse_CGE_Large)
model_name_or_path = "codefuse-ai/CodeFuse-CGE-Large"
model = LLM(model=model_name_or_path, trust_remote_code=True, enforce_eager=True, enable_chunked_prefill=False)
prefix_dict = {'python':{'query':'Retrieve the Python code that solves the following query:', 'passage':'Python code:'},
'java':{'query':'Retrieve the Java code that solves the following query:', 'passage':'Java code:'},
'go':{'query':'Retrieve the Go code that solves the following query:', 'passage':'Go code:'},
'c++':{'query':'Retrieve the C++ code that solves the following query:', 'passage':'C++ code:'},
'javascript':{'query':'Retrieve the Javascript code that solves the following query:', 'passage':'Javascript code:'},
'php':{'query':'Retrieve the PHP code that solves the following query:', 'passage':'PHP code:'},
'ruby':{'query':'Retrieve the Ruby code that solves the following query:', 'passage':'Ruby code:'},
'default':{'query':'Retrieve the code that solves the following query:', 'passage':'Code:'}
}
text = ["Return the best fit based on rsquared",
"def find_best_rsquared ( list_of_fits ) : res = sorted ( list_of_fits , key = lambda x : x . rsquared ) return res [ - 1 ]"]
text[0] += prefix_dict['python']['query']
text[1] += prefix_dict['python']['passage']
embed_0 = model.encode([text[0]])[0].outputs.embedding
embed_1 = model.encode([text[1]])[0].outputs.embedding注:1、在适配 Vllm 之后,模型的输入只能设置为批量大小为 1;否则会导致数组溢出错误。2、目前仅对 CodeFuse-CGE-Large 模型进行了适配,CodeFuse-CGE-Small 模型的支持将在不久后提供。
03 实验
我们以 CodeQwen1.5-7B-Chat 作为模型底座,主要在 Text2Code Retrieval 这个任务上去验证算法的有效性。用于评测的数据集包括:AdvTest、CSN 以及 CosQA 数据集。评测指标我们主要使用的 MRR。我们在 32 张 80 G A100 上运行训练。
实验结果
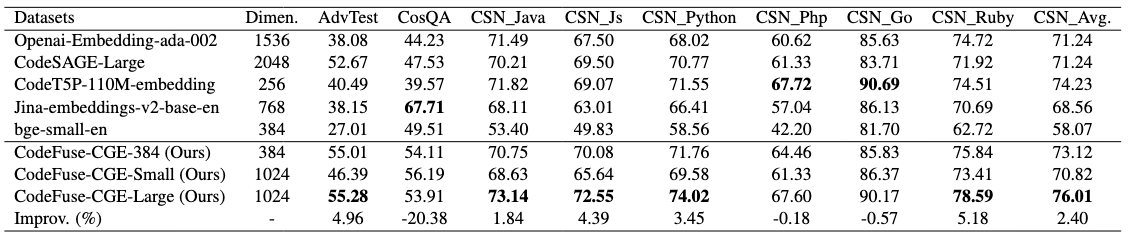
表1:NL2Code Benchmarks
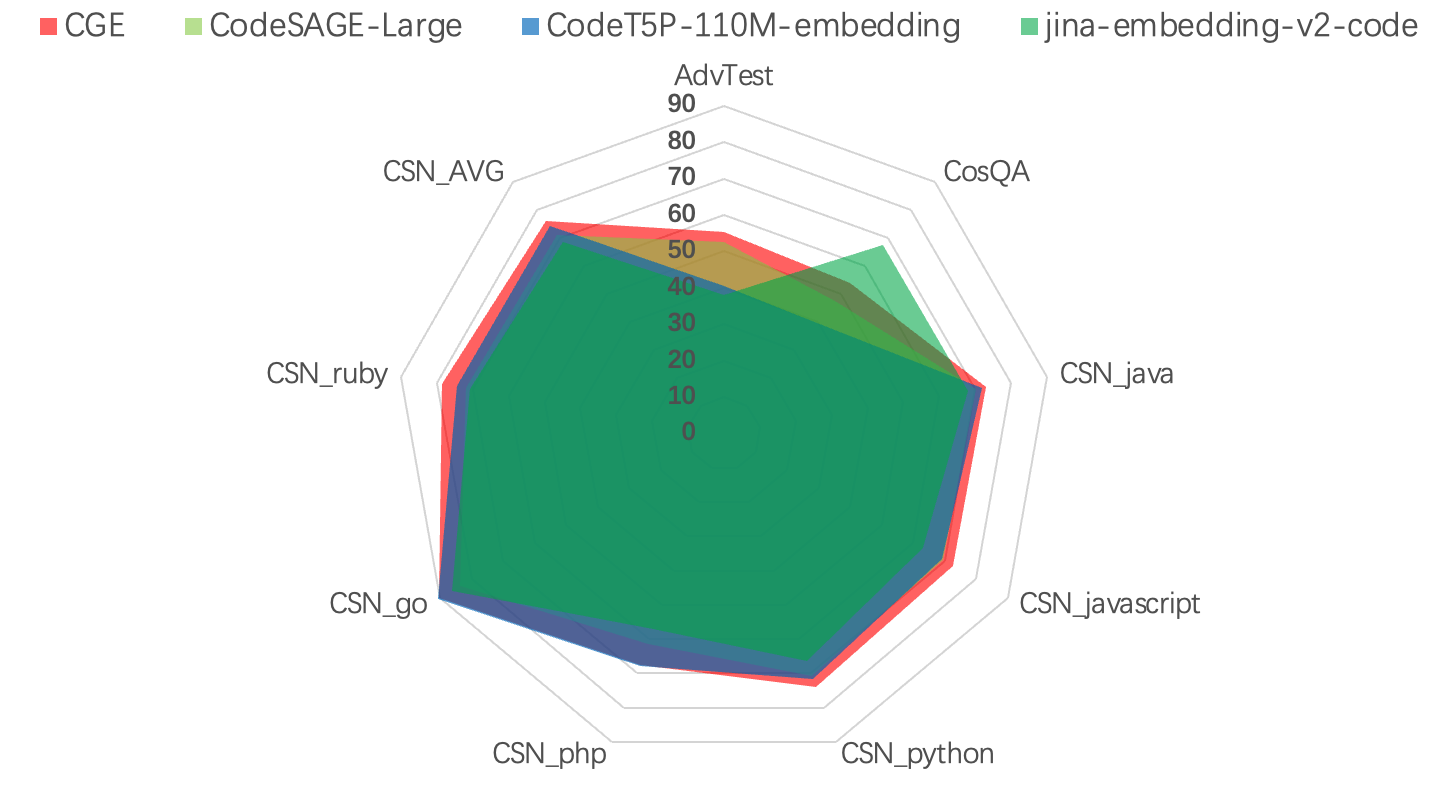
图1:NL2Code Benchmarks雷达图
从实验结果上看,CodeFuse-CGE-Large 的结果优于目前的SOTA,AdvTest 超过 CodeSAGE-Large 2.61%,在 CosQA 数据集上超过 CodeSAGE-Large 6.37% ,而在 CSN 数据集上,在 php 语言和 go 语言上和 CodeT5P-110M-embedding 表现出相当的水平,在其他语言上都超过 CodeT5P-110M-embedding 2%-4%,在 CSN 的平均水平上超过 CodeT5P-110M-embedding 1.8% 的水平。相比于目前在 Code Embedding 领域场景的两种架构, Encoder 以及 Encoder-Decoder 模型,我们模型的结果都有显著优越的结果,而对目前 OpenAI 商用的 Embedding API,我们的结果也在各个方面都超过了商用 Embedding API 的水平。
同时,我们也训练了输出更小维度的 Embedding 模型,从表 1 中可以看到,输出 384 维的模型在 AdvTest 和 CosQA 数据集上相比输出 1024 维的模型效果相当,只是在 CSN 数据集上有 3% 的下降。在实际使用中,如果考虑到存储的问题,可以使用输出 384 维的 Embedding 模型来减少存储压力,同时不会降低太多的性能。
CodeFuse-CGE-Small 的结果相较于 CodeFuse-CGE-Large 在 AdvTest 和 CSN 数据集上分别有着 9% 和 6% 的效果下降,在 CosQA 上有着 2% 的提升。如果考虑到实际使用的时延以及部署机器的限制,可以考虑使用 CodeFuse-CGE-Small 模型。
04 总结
我们基于 Code LLM 作为底座模型,通过 PMA 提取输入 text 或者 token 的 Embedding,在经过 LoRA 微调后,得到了一个对齐 text 和 code 之间语义的 Embedding 模型。实验结果表明,在 Text2Code Retrieval 测试集上都超越了目前 SOTA 的结果。
参考文献
[1] Zhu, Yutao, et al. "Large language models for information retrieval: A survey." arxiv preprint arxiv:2308.07107 (2023).
[2] Zhang, Dejiao, et al. "Code representation learning at scale." arXiv preprint arXiv:2402.01935 (2024).
[3] Feng, Zhangyin, et al. "Codebert: A pre-trained model for programming and natural languages." arXiv preprint arXiv:2002.08155 (2020).
[4] Wang, Yue, et al. "Codet5+: Open code large language models for code understanding and generation." arXiv preprint arXiv:2305.07922 (2023).
[5] Guo, Daya, et al. "Graphcodebert: Pre-training code representations with data flow." arXiv preprint arXiv:2009.08366 (2020).
[6] Zhou, Haoyi, et al. "Informer: Beyond efficient transformer for long sequence time-series forecasting." Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 12. 2021.
[7] Guo, Daya, et al. "Unixcoder: Unified cross-modal pre-training for code representation." arXiv preprint arXiv:2203.03850 (2022).
CodeFuse 相关模型和数据集陆续开源中,如果您喜欢我们的工作,欢迎试用、指正错误和贡献代码,也可以给我们的项目增加 Star ,支持我们
技术交流与探讨,你还可以加入我们的用户交流群



















