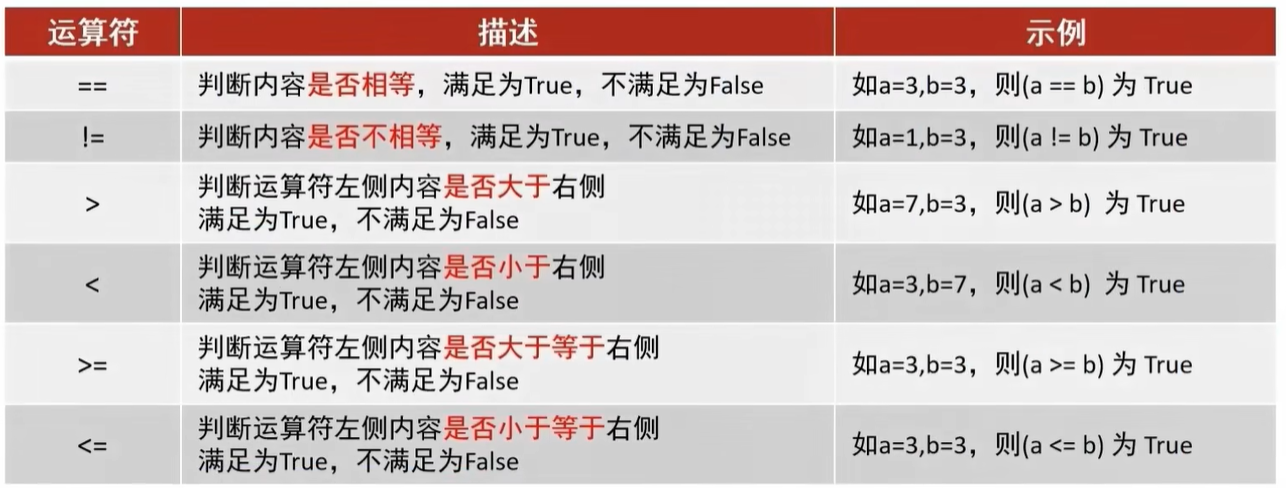
一篇题为《The Mamba in the Llama: Distilling and Accelerating Hybrid Models》的论文证明:通过重用注意力层的权重,大型 transformer 可以被蒸馏成大型混合线性 RNN,只需最少的额外计算,同时可保留其大部分生成质量。

先来说说大模型的缺点,要想实现轻量化的部署,必须对体量巨大的大模型进行压缩,大模型功能虽然强大,但是存在过多的数据冗余,实际上有一些模型副本的权重参数是可以省去的,同样可以实现相应的能力,因此便有了模型压缩的研究。
Transformer
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,因此大模型的体量也都非常大,难以实现轻量化的部署,模型压缩研究也显得尤为重要
模型压缩
大模型压缩技术是当前人工智能领域的一个热点研究方向,它旨在减少大型机器学习模型的存储和计算开销,以便这些模型能够更高效地部署在资源受限的环境中。以下是一些主要的大模型压缩技术:
-
模型量化(Quantization):这是一种通过减少模型参数的表示精度来降低模型大小和加速推理的技术。量化可以通过量化感知训练(QAT)、量化感知微调(QAF)或训练后量化(PTQ)来实现。量化技术可以将模型的权重从浮点数转换为整数或其他离散形式,从而减少模型的存储需求和计算复杂性。例如,K-Quants是一种基于KMeans聚类的量化方法,imatrix增强的K-Quants通过学习量化前后模型输出的差异来建立校正矩阵,而i-quants则在量化过程中联合优化量化中心点和矩阵校正参数。
-
参数剪枝(Pruning):剪枝技术通过删除模型中的不重要连接或参数来减少模型的大小和计算量。剪枝可以分为结构化剪枝和非结构化剪枝,结构化剪枝通常删除整个神经元或过滤器,而非结构化剪枝则在更细的粒度上工作,删除单个权重或神经元连接。
-
知识蒸馏(Knowledge Distillation):知识蒸馏是一种压缩技术,它通过训练一个小型的“学生”模型来模仿一个大型的“教师”模型的行为。这种方法允许学生模型学习并复制教师模型的决策过程,从而在较小的模型中实现类似的性能。
-
低秩分解(Low-Rank Factorization):低秩分解通过将大型矩阵分解为低秩的子矩阵来减少模型参数的数量。这种方法可以在保持模型性能的同时减少模型的复杂性。
-
架构搜索(Architecture Search):神经网络搜索是一种自动化算法,用于设计高效的模型架构。这种方法可以优化模型的性能和复杂度,以适应特定的任务和资源限制。
-
参数共享(Weight Sharing):参数共享通过让模型的不同部分共享相同的权重来减少模型的参数数量,从而减小模型规模。
-
混合精度训练(Mixed Precision Training):这种方法结合了不同精度的数值表示,以减少模型的存储和计算需求,同时保持模型的性能。
这些技术可以单独使用,也可以组合使用,以达到最佳的压缩效果。例如,可以将量化和剪枝结合使用,以进一步减少模型的大小和加速推理过程。随着研究的进展,这些技术不断发展和改进,以支持更高效的大模型部署和应用。
知识蒸馏
《The Mamba in the Llama: Distilling and Accelerating Hybrid Models》这篇论文探讨了如何将大型的Transformer模型通过知识蒸馏技术转化为线性RNN模型,特别是Mamba模型,并加速其推理过程。研究者们展示了通过重用Transformer注意力层的线性投影权重,可以在保持原始模型大部分性能的同时,减少计算资源的需求。这种方法使得混合模型在聊天基准测试中与原始Transformer模型相比具有可比的性能,并且在某些情况下超过了从头开始训练的开源混合Mamba模型。
论文中提到的混合模型包含了一部分注意力层,并且通过硬件感知的推测解码算法提高了推理速度。研究者们还提出了一种多阶段的蒸馏方法,包括渐进式蒸馏、监督微调和定向偏好优化,以提高模型的性能。实验结果表明,从Llama3-8B-Instruct模型中蒸馏出的最佳性能模型在AlpacaEval 2上相对于GPT-4实现了29.61的长度控制胜率,在MT-Bench上实现了7.35的胜率,超过了最佳的指令调整线性RNN模型。
这项研究的相关工作包括了对Transformer模型和线性RNN模型的研究,以及对知识蒸馏和推测解码算法的研究。论文的关键词包括Mamba、Distillation(蒸馏)、Speculative Decoding(推测解码)。
论文的摘要指出,最近的研究表明,像Mamba这样的状态空间模型(SSMs)在语言建模方面可以与Transformer模型竞争,并且具有更有利的部署特性。研究者们考虑了将这些预训练的Transformer模型转换为SSMs以用于部署的挑战,并展示了通过学术GPU资源重用注意力层的线性投影权重来实现这一目标的可行性。由此产生的混合模型包含了四分之一的注意力层,并在性能上与原始Transformer相当。此外,研究者们还引入了一种硬件感知的推测解码算法,以加速状态空间模型的推理速度。总的来说,研究者们展示了如何在有限的计算资源下,将大型Transformer模型蒸馏成混合SSM,并有效地进行解码。
GitHub地址
https://github.com/jxiw/MambaInLlama
论文地址
https://openreview.net/forum?id=UBSOUBC8Fd