背景介绍
在使用MySQL过程中,如果字符集配置不当,可能会出现插入失败、数据乱码、 索引失效、数据丢失、查询不到期望结果等一系列使用异常的情况。因此,熟练掌握MySQL字符集和比较规则的配置方法,并在此基础上了解MySQL字符集与比较规则的核心逻辑,才能从源码和实现层面上理解,为何字符集配置不当会导致上述问题。
本文主要分为三个部分:
• 详细介绍字符集配置方法;
• 字符集的实现与字符集转换核心逻辑;
• 字符集设置不当导致的问题。
MySQL字符集配置方法
1. MySQL字符集介绍
MySQL支持 ASCII、Latin1、GBK以及Unicode 等绝大多数字符集。需要注意的是utf8 字符集包括 utf8 和 utf8mb4 这两个字符集,且占用的最大长度不一样。在 MySQL 8.0之前的版本,utf8类型每个字符最大占用3个字节空间,8.0之后的版本支持utf8mb4类型,单个字符最大占用4字节空间,且可以支持表情等特殊符号。
2. 比较规则介绍
字符集的作用是提供字符到编码的映射,但是不定义字符之间的比较关系。与数字相关类型一样,字符与字符之间也有大小关系,这一部分工作则由比较规则定义。而字符的排序规则会相对复杂一些,并非单一地按照字符的二进制数值进行比较,还需要考虑是否忽略了重音、大小写以及空格,所以,一个字符集上可以有很多组比较规则,可以通过SHOW COLLATION WHERE Charset = 'utf8mb4’查询某个字符集支持哪些比较规则,对应视图INFORMATION_SCHEMA.COLLATIONS。
MySQL比较规则的后缀,能够说明规则是否区分语言中的重音与大小写等:
• _ai表示不区分重音,_as表示区分重音;
• _ci表示不区分大小写,_cs表示区分大小写;
• _bin表示以二进制方式比较;
比如,MySQL 8.0 UTF8MB4 默认的比较规则是utf8mb4_0900_ai_ci,表示这是utf8mb4字符集的比较规则,不区分重音,不区分大小写。
3. Charset和Collation对应关系
在MySQL中,Charset和Collation遵循以下规则:同一个Collation不能被多个Charset使用,每个Charset都有一个默认Collation,也就是Collation依附于某一个Charset,如果设置了某个比较规则,字符集也会设置为该比较规则对应的字符集。
具体来说就是,如果我们只修改了字符集,比较规则也会跟着变化;如果只修改了比较规则,字符集也会跟着变化。详细规则如下:只修改字符集,则比较规则将变为修改后的字符集默认的比较规则;只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
4. 客户端配置Charset和Collation
1) SQL语句的字符集character_set_client
来自客户端的SQL语句本身也是一个字符串,这个变量的值是客户端在连接到服务器时设置的(–default-character-set选项来显式指定这个字符集);
当客户端请求的值未知或不可用(ucs2、utf16、utf16le、utf32),或者根本没有请求设置Charset,或者服务器配置–skip-character-set-client-handshake忽略客户端请求时,其使用的Charset由character_set_client参数定义,变量的Global值被用来设置Session值。
2) 字面量字符集character_set_connection
SQL语句中的字面量(“SELECT ‘abc’;”中的’abc’就是字面量)传给服务端有自己的Charset,当SQL请求语句本身没有指定字面量Charset时,就用character_set_connection作为该字面量的Charset。
3) 字面量比较规则collation_connection
SQL语句中,字面量传给服务端的比较规则有自己单独的值。SQL请求语句本身可以指定比较规则,当SQL请求语句本身没有指定Collation时,就用collation_connection作为该字面量的Collation。同时,该变量也被用于数字转字符串时目标字符串的Collation,对于以’b’、'X’为前缀的字符串是例外,Charset和Collation将设置为binary。
4) 返回结果字符集character_set_results
返回给客户端的结果也是一个字符串,对应的字符集和比较规则由系统参数character_set_results控制,包括结果数据如列值、结果元数据如列名以及错误信息。
5) 客户端配置快捷命令
与数据库连接相关的变量,主要包括以下几项:character_set_client、character_set_results、character_set_connection、collation_connection;
为了方便操作, MySQL 有 SET NAMES 和SET CHARACTER SET 两个命令,可以一次性设置4个变量。
(1)SET NAMES
SET NAMES 'charset_name’这一条语句等价于如下三条语句:
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET character_set_connection = charset_name;
其中设置character_set_connection时,系统会隐式将collation_connection设置为该Charset的默认Collation,如果想更细致地设置Collation,可以使用SET NAMES ‘charset_name’ COLLATE 'collation_name’来指定。
(2)SET CHARACTER SET
SET CHARACTER SET 'charset_name’这一条语句等价于如下三条语句:
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET collation_connection = @@collation_database;
与SET NAMES的唯一不同在于最后一句设置的是collation_connection,变量@@collation_database表示当前所在数据库(use db_name切换库)的默认Collation,这里设置collation_connection也会隐式地将character_set_connection修改为对应Charset。
5. 服务端配置Charset和collation
通过在启动参数中设置character_set_server和collation_server这两个配置项,或者在程序运行中修改下述两个变量的值,可以配置服务器级别的字符集,在服务端没有其他额外设置的情况下,所有操作都是以这个配置为准。当然,服务端还支持进一步的库、表和列级别的配置。
1.创建库
CREATE DATABASE db_name CHARACTER SET charset_name COLLATE collation_name;
2.修改库
ALTER DATABASE db_name CHARACTER SET charset_name COLLATE collation_name;
3.创建表
CREATE TABLE tbl_name (column_list) CHARACTER SET charset_name COLLATE collation_name;
4.修改表
ALTER TABLE tbl_name CHARACTER SET charset_name COLLATE collation_name;
5.创建列
CREATE TABLE tbl_name(col_name VARCHAR(5) CHARACTER SET charset_name COLLATE collation_name);
6.修改列。这里需要注意的是,CHAR、VARCHAR、TEXT、ENUM、SET列都支持指定Charset和Collation,修改列的Charset时,MySQL会尝试映射数据值,但如果修改前后Charset不兼容,可能会发生数据丢失
ALTER TABLE tbl_name MODIFY col_name VARCHAR(5) CHARACTER SET charset_name COLLATE collation_name;
对于服务端的配置,在配置时遵循以下规则:
配置场景 生效规则

MySQL字符集的实现与字符集转换核心逻辑
1. MySQL字符集与比较规则实现
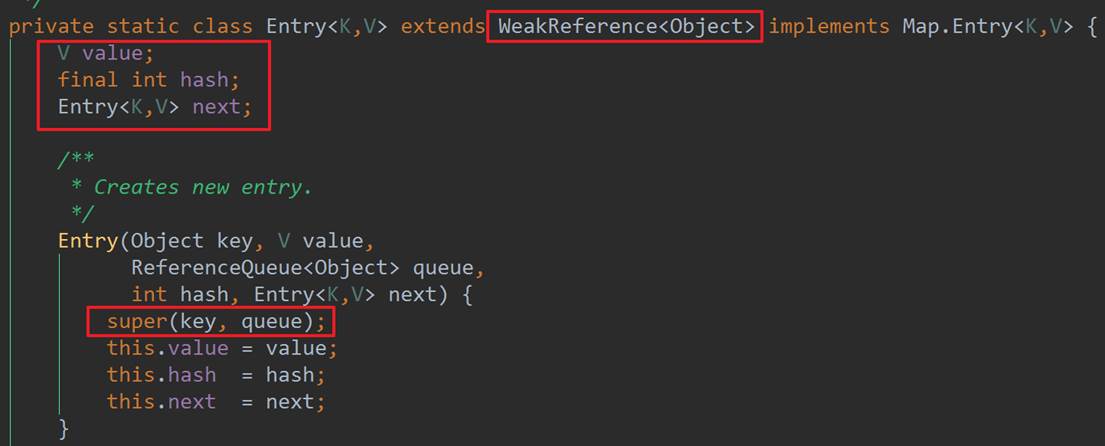
在MySQL中,CHARSET_INFO结构用于描述字符集的信息。图1给出了CHARSET_INFO结构以及组合结构的继承关系,里面的字段约束了字符集本身的特性,包括长度信息、最小最大字符以及一些其他字段,用来支持进行词法解析,这些信息并非本文重点讨论。
本文将着重阐述比较规则以及字符之间转换的实现原理,涉及到的字段有‘cset’、‘coll’ 和‘pad_attribute’。
其中,cset主要提供了处理这个字符集字符串所需要的函数,总共有二十多个,比如判断一个字符串中字符的个数、查找一个字符在字符串中的位置、字符串大小写的转换以及将此字符集编码的数字字符转换成数字等;coll是进行排序比较等所需要函数的句柄集合;pad_attribute约束对pad的行为,pad一般是空格,但对于不同字符集,用户可自定义pad,在CHARSET_INFO中的‘pad_char’中定义。

实现一个字符集和比较规则,都会定义对应CHARSET_INFO类型的全局变量,针对‘cset’和‘coll’两个字段,还需要提供这个函数的实现,这样当用到指定的字符集和字符序时就会调用到具体的实现的函数了。
例如,对于字符集utf8mb4和比较规则utf8mb4_0900_ai_ci,其对应的全局变量为my_charset_utf8mb4_0900_ai_ci,该变量的的cset字段为utf8mb4字符集的函数句柄(my_charset_utf8mb4_handler), coll字段为uca_900这个比较规则的处理函数句柄(my_collation_uca_900_handler)。
在调用层,MySQL中定义一个String类型的变量时,构造函数的第三个入参,为字符集和比较规则信息。
2. 字符集转换实现原理
在MySQL使用过程中,不当的字符集和比较规则配置会触发字符集的隐式转换,导致MySQL行为与预期不符,包括乱码、索引无效、数据丢失和查询不到期望结果等问题。为了进一步探究转换过程中为何会导致上述问题,图2给出了字符转换的核心过程。
首先,判断是否需要转换。如果两个字符集相同或者目标字符集是my_charset_bin,则不需要转换,直接用源字符串即可,否则就会触发字符集转换;还有一种场景是,当原字符集为binary字符集时,需要格外注意,系统会直接逐字节复制,不进行任何检查。
如果不满足上述条件,将触发字符集转换。在转换过程中,以Unicode码点为中介,对每个字符逐个进行转换。在通过Unicode码点生成目标字符集的过程中,如果目标字符集可以通过该码点生成字符,则生成对应字符,否则就会生成‘?’,对应0X3F。
这里字符集转换的实现上,源字符集转换为Unicode码点的函数就是CHARSET_INFO里面两个函数指针mb_wc和wc_mb,分别是将此字符集中的字符转换成unicode字符的函数和将unicode字符转换成此字符集中对应字符的函数,每一个字符集都要实现这两个函数,这样才能保证此字符集和其它字符集之间的转换,源码可以参考copy_and_convert函数的实现。

在实现字符转换函数的过程中,需要正确处理在当前比较规则下对字符串尾部的pad的处理逻辑,pad一般为空格,MySQL中大部分Collation该属性为“PAD SPACE”,基于UCA 9.0.0(名称中带0900字样)实现的Collation该属性为“NO PAD”。
这里需要注意的是,使用LIKE操作符时,MySQL对尾部空格处理不会识别Pad_attribute,源码实现可参考my_like_range函数。
3. 字符集设置不当导致的问题
通过对上述字符集转换逻辑的解读,可以进一步从原理层面解释如果对字符集配置不当可能导致的问题,主要包括乱码、索引无效、数据丢失、查询不到期望结果、插入失败等问题。
1) 乱码
在字符集设置不当的时候,最容易出现的是乱码问题,当数据库表的字符集与查询中使用的字符集不一致时,通过上述转换流程可知,下面的场景会触发乱码:
场景一:
如果目标字符集可以通过该码点生成字符,则生成对应字符,否则就会生成‘?’,对应0X3F,即使该Unicode码可以生成目标字符集的字符,这里也需要考虑,源字符集和目标字符集是否兼容。如果不兼容,可能出现字符丢失或乱码的情况,影响数据的准确性和完整性。
在生产环境中出现乱码问题,大多数情况下,就是因为客户端没有设置好character_set_client和character_set_results所导致的。因为服务端只能依靠客户端传来的信息来决定这两个变量的值,当客户端没有传或错传的时候,就会导致“服务端认为的”与“客户端实际的”对不上,不可预期的乱码就诞生了。
以下面的执行流程为例:
1.创建表t1,使用utf8mb4字符集
mysql> create table t1 (a char(5) character set utf8mb4);
2.客户端错误使用latin1字符集,并插入字符
mysql> set names latin1;mysql> insert into t1 values('张');mysql> insert into t1 values('雷');
3. 将客户端的字符集设置为utf8mb4,查询结果出现乱码,这是源字符集和目标字符集不一样,所以会触发字符集转换,将latin1的‘张’转换为Unicode码值,然后将其转化为该码值编码为utf8mb4字符,这里需要注意的是,latin1和utf8mb4不兼容,如果不转换回latin1,就不是预期内的字符了。
mysql> set names utf8mb4;
mysql> select * from t1;
场景二:
在字符集中插入一个不存在的Unicode码值时,若使用二进制字面量字符串进行操作,由于字符转换逻辑的特性,此时会不加检查的逐个字节复制,但是查询的时候,如果插入的二进制按照对应的字符集正确解析,就会出现乱码。
以下面的执行流程为例:
1.创建表t1,包含latin1字符集的列
mysql> create table t1 (a varchar(5) character set latin1);
2. 使用二进制字面量字符串插入然后查询,由于二进制类型不会进行字符集转换,都是直接复制,查询的时候无法按照字符集解析对应字符,返回乱码
mysql> insert into t1 values(X'E5BCA0');
mysql> select * from t1;
- 索引无效
在某些情况下,字符用作索引时,字符集转换可能导致索引失效。这是因为索引是基于特定字符集的排序规则建立的。字符集不匹配导致数据在比较前需转换字符集,破坏了索引的原有排序逻辑,导致数据库无法使用索引,转而执行全表扫描,显著降低查询效率。
- 数据丢失
修改列的Charset时,一定会触发字符集转换,但如果修改前后Charset不兼容,可能会因为数据截断发生数据丢失。
- 查询不到期望结果
如下面的查询,如果x列的类型和SQL请求中的字面量’Y’,不是一个字符集,在比较时就需要转换为同一个字符集和比较规则再进行比较,但是转换后的字符集如果不兼容,就可能导致查询不到正确结果,客户认为数据损坏,实则客户端配置问题。
对于下面的sql语句,如果x列、字面量、z列都使用相同的Charset和Collation,那么上面的语句将没有任何歧义,但如果它们的Charset或Collation不同,那么以谁的Charset和Collation为准呢?因此对于该类sql语句,需要通过COERCIBILITY函数查看优先级,进而确定以哪个字符集为准。SELECT x FROM T WHERE x = ‘Y’;
4. 字符集隐式转换涉及场景
如果是显式触发的字符集转换,即使缩小了数据宽度,出现数据问题也是预期之内的。生产环境遇到的大多数问题,往往是触发了隐式的转换导致的,因此需要识别常见的触发字符集隐式转换的场景。
通过对转换函数打断点做了一系列验证,总结了部分触发隐式字符集转换的场景,应在MySQL使用中尽量避免。
(1)将一列数据赋值到另一个使用不同Charset的列;
(2)使用字符串字面量INSERT或UPDATE一个使用不同Charset的列;
(3)客户端与服务端字符集不一致;
(4)请求涉及多种字符集的比较;
例如下面的查询,如果x列的类型和SQL请求中的字面量’Y’,不是一个字符集,在比较时需要转换为同一个字符集和比较规则再进行比较。至于以哪个字符集为准,可以通过 COERCIBILITY() 函数获取其优先级,以优先级最高的为准。
总结
本文详细总结了MySQL在使用过程中,MySQL字符集和比较规则的配置方法,转换规则的实现原理,并在此基础上说明哪些配置问题会导致的插入失败、乱码、索引无效、数据丢失、查询不到期望结果等一些MySQL异常问题,为MySQL字符集使用和源码阅读提供指导。