介绍
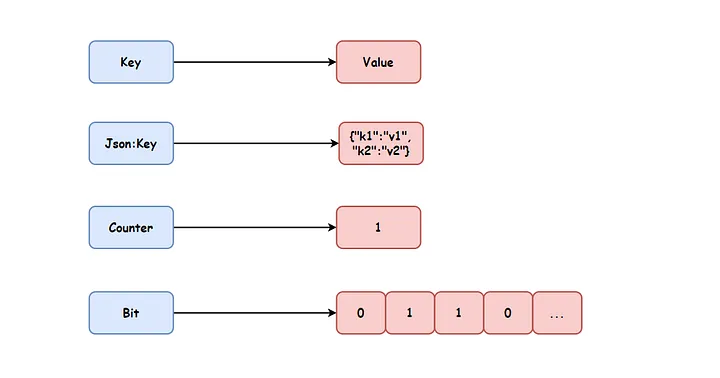
在 Redis 中,String 是一种重要的数据类型,是最基本的 key-value 结构,在这个结构中, value 是一个字符串。value 所能容纳的数据最大长度为512M。
需要注意的是,这里的字符串不只指文本数据,它还可以是数字、JSON 对象、二进制数据等。
内部实现
String 类型的底层数据结构在 Redis 中主要由整数(int)和 SDS(Simple Dynamic String)实现。
SDS 与我们熟知的 C 语言字符串有所不同。Redis 选择 SDS 而非 C 语言的字符串实现,主要是因为 SDS 具有以下特点:
-
SDS 不仅可以保存文本数据,还可以保存二进制数据。这是因为 SDS 使用 len 属性来判断字符串的结束位置,而不是依靠空字符 (
\0) 标记结束。同时,SDS 的所有 API 都会将 buf[] 数组中的数据作为二进制来处理。因此,SDS 不仅可以存储文本,还能存储图片、音频、视频、压缩文件等二进制数据。 -
SDS获取字符串长度的时间复杂度为O(1)。由于C语言的字符串没有记录自身的长度,所以获取长度的复杂度为O(n);而SDS结构体中的len属性记录了字符串长度,所以复杂度为O(1)。
-
Redis 的 SDS API 是安全的,拼接字符串不会导致缓冲区溢出。因为 SDS 会在拼接字符串前检查空间是否足够,如果空间不足,会自动扩展,避免缓冲区溢出的问题。
在 Redis 中,字符串对象的内部编码(encoding)有三种:int、raw 和 embstr,关系如下:
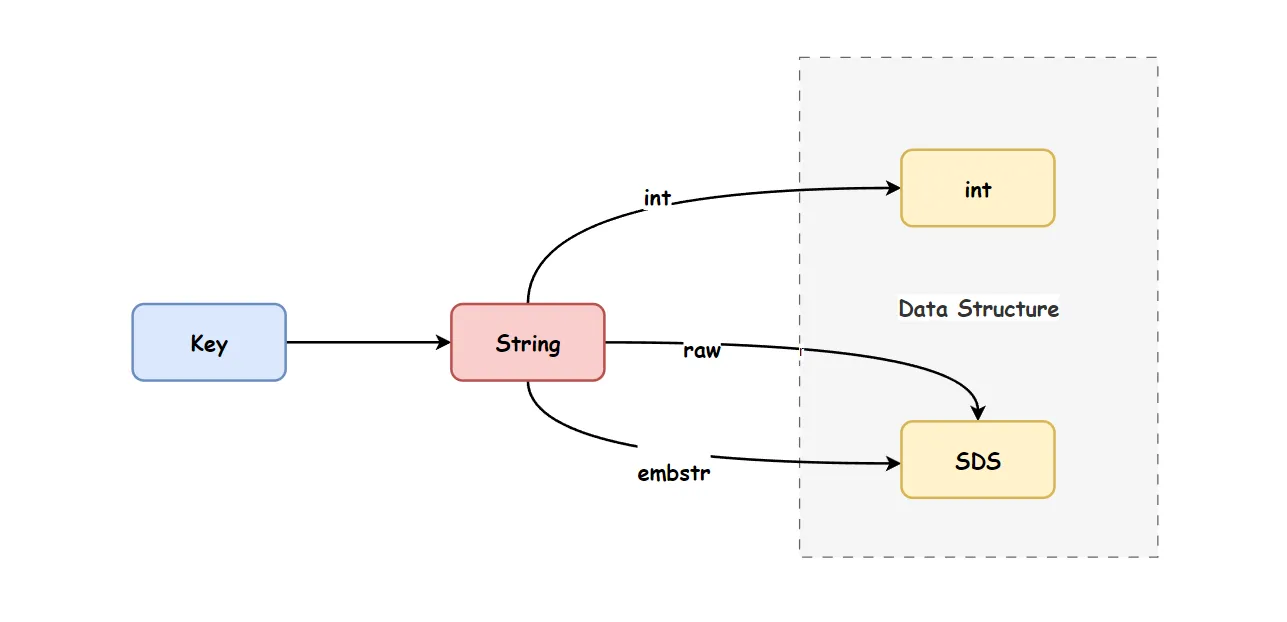
如果字符串对象存储的是一个整数值,并且这个整数值可以用 long 类型表示,那么该字符串对象会将这个整数值存储在RedisObject的 ptr 属性中(将 void* 转换为 long),并将其编码设置为 int。
注意:redisObject是Redis中用于表示数据结构(如字符串、列表、集合、哈希表和群体集合)的一个核心数据结构。通俗来讲,可以把它redisObject想象成一个“包装器”或“容器”,用于封装和管理存储在Redis内存中的数据。后面会有文章详细介绍。

如果字符串对象存储的是一个长度不超过 32 字节的字符串(在 Redis 3.2 版本及以后改成44字节),Redis 会使用简单动态字符串(SDS)来存储这个字符串,并将编码设置为 embstr。
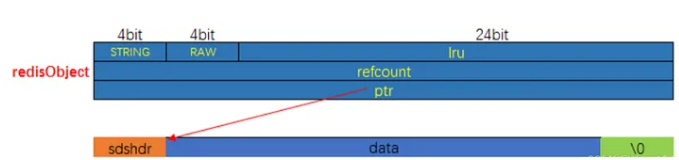
embstr 编码是一种专门为存储短字符串而优化的编码方式,这种编码方式将字符串数据直接嵌入到 redisObject 结构体内部,redisObject 和 SDS 数据都是在同一块内存区域内,这意味着 Redis 只需分配一次内存空间,从而提高了内存管理效率和操作性能。

如果字符串对象存储的是一个长度超过 32 字节的字符串(在 Redis 3.2 版本及以后改成44字节),Redis 会使用简单动态字符串(SDS)来存储这个字符串,并将编码设置为 raw。raw 编码需要分配两次内存空间(分别为redisObject和sds)。
注意,不同版本的 Redis 中,embstr 编码与 raw 编码的界限长度有所不同:
- 在 Redis 2.x 版本中,界限为 32 字节。
- 在 Redis 3.0 到 4.0 版本中,界限为 39 字节。
- 在 Redis 5.0 版本中,界限为 44 字节。
这里再总结一下,embstr 编码和 raw 编码都使用 SDS来保存字符串值,但它们在内存分配和数据存储方式上有所不同:
1. 内存分配
- “raw”编码:需要进行两次内存分配,分别为Redis对象(“redisObject”)和SDS(Simple Dynamic String)分配内存空间。
- “embstr”编码:只进行一次内存分配,同时为Redis对象和SDS分配连续的内存空间。
2. 数据存储
- “raw”编码:Redis对象和SDS分别存储在不同的内存区域。
- “embstr”编码:Redis对象和SDS存储在连续的内存区域中。
3. 修改操作
- “embstr”编码的字符串是只读的,一旦需要修改字符串,就会转换为“raw”编码。
- 可以直接修改“raw”编码的字符串。
4. 性能影响
- “embstr“ 编码:在创建和释放内存时的开销较小,因为只需要进行一次内存操作。
- “raw“ 编码:在修改字符串时性能更好,因为不需要进行编码转换。
选择使用哪种编码取决于具体的应用场景和需求。如果字符串长度较短且不经常修改,embstr 编码可能更为适合;而如果字符串较长或需要频繁修改,则 raw 编码可能是更好的选择。
常用命令
基本操作
# 设置value
> SET name Sea
OK
# 根据key获取对应的value。
> GET name
"Sea"
# 判断某个key是否存在。
> EXISTS name
( integer ) 1
# 返回key存储的字符串值的长度。
> STRLEN name
( integer ) 3
# 删除某个key对应的value。
> DEL name
( integer ) 1
#不存在则设置
>SETNX key value
(integer) 1
批量操作
# 批量设置key-value类型的值
> MSET k1 v1 k2 v2 k3 v3
OK
# 批量获取多个key对应的值
> MGET k1 k2
1) "v1"
2) "v2"
计数器操作(当字符串内容为整数时可使用)
# 设置键值类型的值。
> SET number 0
OK
# 将键中存储的数字值增加一。
> INCR number
( integer ) 1
# 将键中存储的数字值加 100。
> INCRBY number 100
( integer ) 101
# 将键中存储的数字值减少一。
> DECR number
( integer ) 100
# 将键中存储的数字值减少 50。
> DECRBY number 50
( integer ) 50
# 设置key的 过期时间为30秒(此命令是 为已经存在的key设置 过期时间)
> EXPIRE name 30
(integer) 1
# # 检查数据还有多长时间过期
> TTL name
(integer) 23
# 设置key- value的同时设置过期时间
> SET key value EX 30
OK
> SETEX key 30 value
OK
应用场景
1. 统计计数
由于 Redis 是单线程处理命令的,执行命令的过程是原子的,因此 String 数据类型非常适合用于计数场景,如计算访问次数、点赞次数等。等等。
例如,我们可以使用 Redis 的 INCR 命令来计算一篇文章的访问次数:每当用户访问这篇文章时,我们就调用 INCR 命令增加该文章的访问次数。由于 Redis 的 INCR 命令是原子的,这保证了每次访问都会正确地更新计数值,而不会出现并发冲突的问题。
# 初始化文章访问次数为 0
> SET aritcle:visit:count:1000001 0
OK
# 访问量 +1
> INCR aritcle:readcount:1000001
( integer ) 1
# 访问量 +1
> INCR aritcle:readcount:1000001
( integer ) 2
# 获取相应文章的访问量
> GET aritcle:readcount:1000001
"2"
2. 缓存对象
使用 String 缓存对象的常见方式有两种:
1. 直接缓存整个对象的 JSON
将对象转换为 JSON 字符串,然后将这个 JSON 字符串作为值存储在 Redis 的 String 类型中。这种方式简单直观,但当需要修改对象的某个字段时,就必须将整个 JSON 字符串取出,进行反序列化,修改字段后再重新序列化存储。
这可能会导致较大的性能开销,因为每次修改都涉及到整个对象的序列化和反序列化过程。
SET user:1 '{"name":"Bob", "age":18}'
2. 将对象的属性分开存储
将对象的各个属性分别存储在不同的 key 中,每个 key 对应一个属性的值。这种方式提供了更大的灵活性,允许你单独访问和修改对象的某个属性,而不需要处理整个对象。然而,这也意味着需要对多个 key 进行操作,从而可能增加操作的复杂性和开销。
MSET user:1:name Bob user:1:age 18 user:2:name Jerry user:2:age 20
3. 分布式锁
在 Redis 中,可以使用 String 数据结构来实现分布式锁。利用 SET 命令的 NX 参数,可以实现“仅当 key 不存在时才插入”的功能,从而用来实现分布式锁:
- 如果 key 不存在,Redis 会插入 key 并返回成功,这表示锁获取成功。
- 如果 key 已经存在,Redis 会插入失败,表示锁获取失败。
通常,为了确保锁不会因异常情况而长时间占用,还会给分布式锁设置一个过期时间。分布式锁的命令如下:
SET lock_key unique_value NX PX 10000
- lock_key 是锁对应的key;
- unique_value 是客户端生成的唯一标识,用于标识锁的拥有者;
- NX 表示仅在 lock_key 不存在时才设置;
- PX 10000 表示将 lock_key 的过期时间设置为 10 秒,以防客户端异常无法释放锁。
在解锁时,操作的步骤是删除 lock_key 键。但是,为了确保只有持有锁的客户端才能删除 lock_key,需要先验证 unique_value 是否匹配。如果匹配,则可以删除该键。
由于解锁过程涉及两个操作(验证和删除),需要确保这两个操作是原子的。这可以通过使用 Lua 脚本来实现,因为 Redis 在执行 Lua 脚本时,会以原子方式执行整个脚本,从而保证了解锁操作的原子性。
# 释放锁时,先比较unique_value是否相等,避免错误释放锁。
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样就通过SET命令结合Lua脚本完成了单个Redis节点上分布式锁的加锁与解锁。
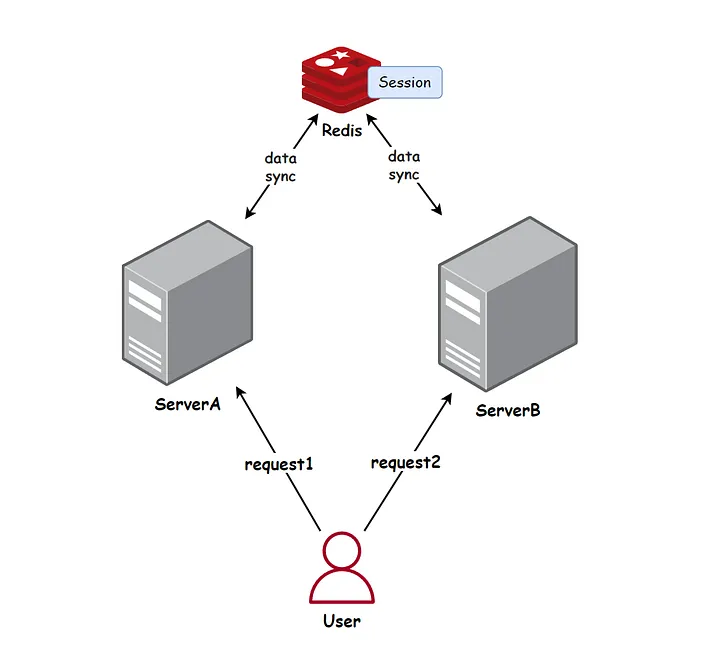
4. 共享会话信息
通常我们在开发登录模块的时候,都会使用Session来保存用户的登录状态,这些Session信息会保存在服务器端,但是这只适用于单系统应用。
在分布式系统中,这种模式就不再适用了。由于用户的请求可能会被分配到不同的服务器上,这会导致 Session 信息丢失,导致用户需要频繁重新登录。
例如,假设用户1第一次的登录请求是落到服务器A上,因此其 Session 信息保存在服务器A上。但是当用户1第二次访问的时候,可能会被分配到了服务器B上,而服务器B没有用户1的Session信息,那么就会提示用户1需要登录,这样的用户体验是极度不友好的。
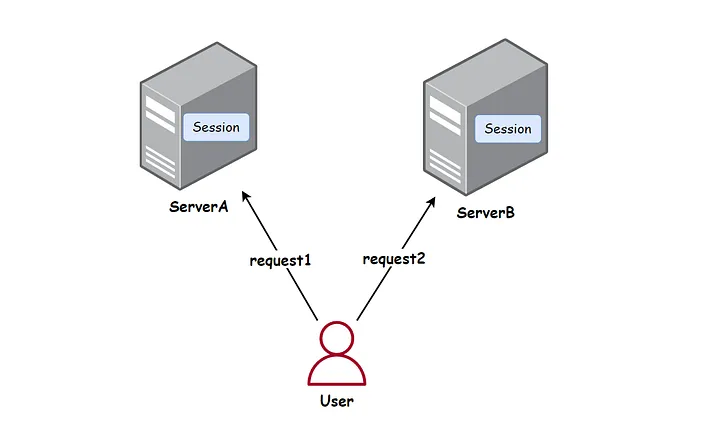
为了解决这个问题,通常需要采用集中式的 Session 存储方案,例如使用 Redis 来存储 Session 信息,这样无论用户的请求被分配到哪台服务器,服务器都会去同一个Redis中获取相关的Session信息,样就解决了分布式系统中Session存储的问题。