一.什么是Scrapy?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
二.scrapy安装
Linux:
pip3 install scrapy
Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
强调:如果windows10安装pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl失败,请自行换成32位的即可解决,网上乱七八槽的答案请绕过,本人以亲测没什么卵用!!!
提示:如果在pycharm中安装scrapy失败,两种解决办法:
1、把pycharm中的虚拟环境模式改成直接指向现在的python安装环境!
2、把python环境中的scrapy,twisted等直接复制到pycharm工程所在的虚拟环境中去!
三.基础使用
1.创建项目(cmd):scrapy startproject 项目名称
项目结构:
project_name/
scrapy.cfg:
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据持久化处理
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫解析规则
2.创建爬虫应用程序(cmd):
cd project_name(进入项目目录)
scrapy genspider 应用名称 爬取网页的起始url (例如:scrapy genspider qiubai www.qiushibaike.com)
3.编写爬虫文件:在步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件,文件源码如下:
应用名.py
# -*- coding: utf-8 -*-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai' #应用名称
#允许爬取的域名(如果遇到非该域名的url则爬取不到数据)
allowed_domains = ['https://www.qiushibaike.com/']
#起始爬取的url
start_urls = ['https://www.qiushibaike.com/']
#访问起始URL并获取结果后的回调函数,该函数的response参数就是向起始的url发送请求后,获取的响应对象.该函数返回值必须为可迭代对象或者NUll
def parse(self, response):
print(response.text) #获取字符串类型的响应内容
print(response.body)#获取字节类型的相应内容
4.设置修改settings.py配置文件相关配置:
#修改内容及其结果如下: 19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份 22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议
5.执行爬虫程序(cmd):scrapy crawl 应用名称
在cmd中执行爬虫程序时要先将目录切换到我们创建的scrapy项目目录下,否则就会报:Unknown command: crawl错误!!!!!!!
小试牛刀:将糗百首页中段子的内容和标题进行爬取
# -*- coding: utf-8 -*-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai' #应用名称
allowed_domains = ['https://www.qiushibaike.com/']
start_urls = ['https://www.qiushibaike.com/']
def parse(self, response):
#xpath为response中的方法,可以将xpath表达式直接作用于该函数中
odiv = response.xpath('//div[@id="content-left"]/div')
content_list = [] #用于存储解析到的数据
for div in odiv:
#xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]/a/h2/text()')[0].extract()
content=div.xpath('.//div[@class="content"]/span/text()')[0].extract()
#将解析到的内容封装到字典中
dic={
'作者':author,
'内容':content
}
#将数据存储到content_list这个列表中
content_list.append(dic)
return content_list
执行爬虫程序:
执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储
scrapy crawl qiubai -o qiubai.json
scrapy crawl qiubai -o qiubai.xml
scrapy crawl qiubai -o qiubai.csv
四.scrapy持久化操作:将爬取到糗百数据存储写入到文本文件中进行存储
# -*- coding: utf-8 -*-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
allowed_domains = ['https://www.qiushibaike.com/']
start_urls = ['https://www.qiushibaike.com/']
def parse(self, response):
#xpath为response中的方法,可以将xpath表达式直接作用于该函数中
odiv = response.xpath('//div[@id="content-left"]/div')
with open('./data.txt', 'w') as fp:
for div in odiv:
#xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]/a/h2/text()')[0].extract()
content=div.xpath('.//div[@class="content"]/span/text()')[0].extract()
#持久化存储爬取到的内容
fp.write(author + ':' + content + '\n')
注意:上述代码表示的持久化操作是我们自己通过IO操作将数据进行的文件存储。在scrapy框架中已经为我们专门集成好了高效、便捷的持久化操作功能,我们直接使用即可。要想使用scrapy的持久化操作功能,我们首先来认识如下两个文件:
items.py:数据结构模板文件。定义数据属性。
pipelines.py:管道文件。接收数据(items),进行持久化操作。
持久化流程:
1.爬虫文件爬取到数据后,需要将数据封装到items对象中。
2.使用yield关键字将items对象提交给pipelines管道进行持久化操作。
3.settings.py配置文件中开启管道
小试牛刀:将糗事百科首页中的段子和作者数据爬取下来,然后进行持久化存储
爬虫文件:qiubaiDemo.py
# -*- coding: utf-8 -*-
import scrapy
from secondblood.items import SecondbloodItem
class QiubaidemoSpider(scrapy.Spider):
name = 'qiubaiDemo'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['http://www.qiushibaike.com/']
def parse(self, response):
odiv = response.xpath('//div[@id="content-left"]/div')
for div in odiv:
# xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author = author.strip('\n')#过滤空行
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
content = content.strip('\n')#过滤空行
#将解析到的数据封装至items对象中
item = SecondbloodItem()
item['author'] = author
item['content'] = content
yield item#提交item到管道文件(pipelines.py)
items文件:items.py
import scrapy
class SecondbloodItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field() #存储作者
content = scrapy.Field() #存储段子内容
管道文件:pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class SecondbloodPipeline(object):
#构造方法
def __init__(self):
self.fp = None #定义一个文件描述符属性
#下列都是在重写父类的方法:
#开始爬虫时,执行一次
def open_spider(self,spider):
print('爬虫开始')
self.fp = open('./data.txt', 'w')
#因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。
def process_item(self, item, spider):
#将爬虫程序提交的item进行持久化存储
self.fp.write(item['author'] + ':' + item['content'] + '\n')
return item
#结束爬虫时,执行一次
def close_spider(self,spider):
self.fp.close()
print('爬虫结束')
配置文件:settings.py
#开启管道
ITEM_PIPELINES = {
'secondblood.pipelines.SecondbloodPipeline': 300, #300表示为优先级,值越小优先级越高
}
Scrapy递归爬取多页数据:
需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储
# -*- coding: utf-8 -*-
import scrapy
from qiushibaike.items import QiushibaikeItem
# scrapy.http import Request
class QiushiSpider(scrapy.Spider):
name = 'qiushi'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']
#爬取多页
pageNum = 1 #起始页码
url = 'https://www.qiushibaike.com/text/page/%s/' #每页的url
def parse(self, response):
div_list=response.xpath('//*[@id="content-left"]/div')
for div in div_list:
#//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2
author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author=author.strip('\n')
content=div.xpath('.//div[@class="content"]/span/text()').extract_first()
content=content.strip('\n')
item=QiushibaikeItem()
item['author']=author
item['content']=content
yield item #提交item到管道进行持久化
#爬取所有页码数据
if self.pageNum <= 13: #一共爬取13页(共13页)
self.pageNum += 1
url = format(self.url % self.pageNum)
#递归爬取数据:callback参数的值为回调函数(将url请求后,得到的相应数据继续进行parse解析),递归调用parse函数
yield scrapy.Request(url=url,callback=self.parse)
Scrapy组件:
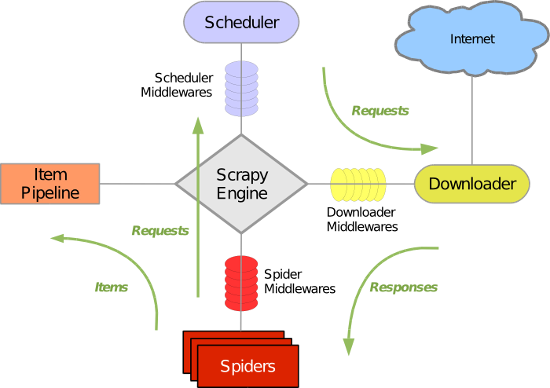
-
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 引擎(Scrapy)
* 解释:引擎首先会将爬虫文件中的起始url获取,并且提交到调度器中。如果需要从url中下载数据,则调度器会将url通过引擎提交给下载器,下载器根据url去下载指定内容(响应体)。下载好的数据会通过引擎移交给爬虫文件,爬虫文件可以将下载的数据进行指定格式的解析。如果解析出的数据需要进行持久化存储,则爬虫文件会将解析好的数据通过引擎移交给管道进行持久化存储。
面试题:如果最终需要将爬取到的数据值一份存储到磁盘文件,一份存储到数据库中,则应该如何操作scrapy?
答:
管道文件中的代码为:
#该类为管道类,该类中的process_item方法是用来实现持久化存储操作的。
class DoublekillPipeline(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入磁盘文件)
return item
#如果想实现另一种形式的持久化操作,则可以再定制一个管道类:
class DoublekillPipeline_db(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入数据库)
return item
在settings.py开启管道操作代码为:
#下列结构为字典,字典中的键值表示的是即将被启用执行的管道文件和其执行的优先级。
ITEM_PIPELINES = {
'doublekill.pipelines.DoublekillPipeline': 300,
'doublekill.pipelines.DoublekillPipeline_db': 200,
}
#上述代码中,字典中的两组键值分别表示会执行管道文件中对应的两个管道类中的process_item方法,实现两种不同形式的持久化操作。
五.Scrapy发起post请求:
- 问题:在之前代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢?
- 解答:其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(url=u,callback=self.parse)
【注意】该方法默认的实现,是对起始的url发起get请求,如果想发起post请求,则需要子类重写该方法。
- 重写start_requests方法,让其发起post请求:
def start_requests(self):
#请求的url
post_url = 'http://fanyi.baidu.com/sug'
# 表单数据
formdata = {
'kw': 'wolf',
}
# 发送post请求
yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)