文章目录
- Python NumPy学习指南:从入门到精通
- 第一部分:NumPy简介与安装
- 1. 什么是NumPy?
- 2. 安装NumPy
- 使用pip安装:
- 使用Anaconda安装:
- 第二部分:NumPy数组基础
- 1. NumPy数组的创建
- 从列表创建一维数组:
- 创建多维数组:
- 使用NumPy内置函数创建数组:
- 2. NumPy数组的属性
- 数组的维度(`ndim`):
- 数组的形状(`shape`):
- 数组的元素个数(`size`):
- 数组元素的数据类型(`dtype`):
- 3. NumPy数组的索引与切片
- 一维数组的索引:
- 二维数组的索引:
- 数组切片:
- 第三部分:NumPy数组操作
- 1. NumPy数组的索引与切片(进阶)
- 布尔索引
- 花式索引
- 多维数组的切片
- 2. NumPy数组的形状变换
- reshape
- ravel
- transpose
- 3. 数组间的运算
- 数组的算术运算
- 数组与标量的运算
- 广播机制
- 4. NumPy常用函数
- 求和与均值
- 最大值与最小值
- 累积和
- 排序
- 第四部分:NumPy与矩阵操作
- 1. NumPy中的矩阵概念
- 2. 矩阵的基本运算
- 矩阵乘法
- 矩阵转置
- 矩阵的逆
- 矩阵行列式
- 3. 广播机制(详细)
- 广播的原理
- 广播的规则
- 广播实例
- 4. NumPy的高级应用
- 向量化操作
- 条件筛选与筛选赋值
- NumPy的随机数生成
- 5. NumPy与其他Python库的集成
- NumPy与Pandas
- NumPy与Matplotlib
- 第五部分:NumPy性能优化与多线程操作
- 1. NumPy的性能优化
- 使用向量化操作代替Python循环
- 内存布局和连续性
- 2. 多线程与并行计算
- NumPy与多线程
- 使用NumPy进行并行化计算
- 3. 大规模数据处理中的实践
- 使用内存映射文件处理大数据
- 使用NumPy进行批量处理
- 4. NumPy常见问题与最佳实践
- 避免不必要的数据拷贝
- 谨慎使用循环
- 善用NumPy的广播机制
- 定期检查内存使用情况
- 总结与展望
Python NumPy学习指南:从入门到精通
第一部分:NumPy简介与安装
1. 什么是NumPy?
NumPy,即Numerical Python,是Python中最为常用的科学计算库之一。它提供了强大的多维数组对象
ndarray,并支持大量的数学函数和操作。与Python内置的列表相比,NumPy数组的计算速度更快,占用内存更少,非常适合处理大量的数据。
NumPy的功能不仅限于数值计算,它还支持复杂的数组操作,如切片、索引、线性代数运算等。NumPy通常与SciPy、Pandas等其他科学计算库一起使用,构成了Python科学计算的基础生态。
2. 安装NumPy
在开始使用NumPy之前,我们需要在Python环境中安装它。可以通过以下两种方式进行安装:
使用pip安装:
打开命令行终端,输入以下命令:
pip install numpy
使用Anaconda安装:
如果你使用的是Anaconda环境,可以使用以下命令:
conda install numpy
安装完成后,可以通过以下命令验证是否安装成功:
import numpy as np
print(np.__version__)
成功安装后,终端将输出NumPy的版本号。
第二部分:NumPy数组基础
1. NumPy数组的创建
NumPy数组是NumPy的核心数据结构。你可以通过多种方式来创建NumPy数组:
从列表创建一维数组:
import numpy as np
my_list = [1, 2, 3, 4, 5]
np_array = np.array(my_list)
print(np_array)
输出:
[1 2 3 4 5]
在这个例子中,我们从一个Python列表创建了一个一维的NumPy数组。
创建多维数组:
my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
np_matrix = np.array(my_matrix)
print(np_matrix)
输出:
[[1 2 3]
[4 5 6]
[7 8 9]]
这里,我们创建了一个二维数组,它包含三个子列表,每个子列表代表矩阵的一行。
使用NumPy内置函数创建数组:
NumPy提供了许多内置函数来创建数组:
np_zeros = np.zeros((3, 3))
np_ones = np.ones((2, 4))
np_eye = np.eye(3)
print("Zeros Array:\n", np_zeros)
print("Ones Array:\n", np_ones)
print("Identity Matrix:\n", np_eye)
输出:
Zeros Array:
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
Ones Array:
[[1. 1. 1. 1.]
[1. 1. 1. 1.]]
Identity Matrix:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
以上例子分别展示了如何创建全零矩阵、全一矩阵以及单位矩阵。
2. NumPy数组的属性
理解NumPy数组的属性有助于更好地操作和利用这些数组。以下是一些常用的属性:
数组的维度(ndim):
print(np_matrix.ndim)
输出:
2
该属性返回数组的维度。对于二维数组,返回值为2。
数组的形状(shape):
print(np_matrix.shape)
输出:
(3, 3)
shape属性返回一个元组,表示数组的维度大小。对于一个3x3的矩阵,它返回(3, 3)。
数组的元素个数(size):
print(np_matrix.size)
输出:
9
size属性返回数组中元素的总个数。
数组元素的数据类型(dtype):
print(np_matrix.dtype)
输出:
int64
dtype属性显示数组中元素的数据类型。在这个例子中,数组元素的数据类型为64位整数。
3. NumPy数组的索引与切片
类似于Python列表,NumPy数组也支持索引和切片操作,可以方便地访问和修改数组中的元素。
一维数组的索引:
arr = np.array([10, 20, 30, 40, 50])
print(arr[1]) # 访问第二个元素
输出:
20
二维数组的索引:
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matrix[1, 2]) # 访问第二行第三列的元素
输出:
6
数组切片:
print(arr[1:4]) # 获取第二个到第四个元素的子数组
输出:
[20 30 40]
数组切片操作返回一个新的数组,该数组包含原始数组的一个子集。
第三部分:NumPy数组操作
1. NumPy数组的索引与切片(进阶)
在之前的基础部分,我们已经了解了一维和二维数组的基本索引与切片操作。接下来,我们将深入探讨更多高级的索引与切片技巧,这些技巧能帮助我们更灵活地操作数组数据。
布尔索引
布尔索引用于基于条件来选择数组中的元素。这对于筛选满足特定条件的元素非常有用。
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
bool_idx = arr > 5
print(bool_idx)
输出:
[False False False False False True True True True True]
可以看到,bool_idx是一个布尔数组,表示哪些元素满足arr > 5这个条件。我们可以用这个布尔数组直接索引原数组:
print(arr[bool_idx])
输出:
[ 6 7 8 9 10]
花式索引
花式索引允许我们使用数组或列表来指定索引顺序,从而按特定顺序选择数组中的元素。
arr = np.array([10, 20, 30, 40, 50])
indices = [0, 3, 4]
print(arr[indices])
输出:
[10 40 50]
多维数组的切片
对于多维数组,切片操作可以同时作用于多个维度。
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matrix[:2, 1:3]) # 获取前两行中第二列和第三列的子数组
输出:
[[2 3]
[5 6]]
在这个例子中,我们使用了两个切片,第一个切片[:2]表示选择前两行,第二个切片[1:3]表示选择第二列和第三列。
2. NumPy数组的形状变换
有时我们需要对数组的形状进行变换,比如将一维数组转换为二维数组,或者将多维数组展平成一维数组。NumPy提供了多种方法来进行形状变换。
reshape
reshape方法可以改变数组的形状而不改变数据内容。
arr = np.array([1, 2, 3, 4, 5, 6])
reshaped_arr = arr.reshape((2, 3))
print(reshaped_arr)
输出:
[[1 2 3]
[4 5 6]]
这里,我们将一个一维的数组转换为一个2x3的二维数组。
ravel
ravel方法将多维数组展平成一维数组。
matrix = np.array([[1, 2, 3], [4, 5, 6]])
flattened = matrix.ravel()
print(flattened)
输出:
[1 2 3 4 5 6]
transpose
transpose方法用于矩阵的转置操作,交换数组的维度。
matrix = np.array([[1, 2, 3], [4, 5, 6]])
transposed = matrix.transpose()
print(transposed)
输出:
[[1 4]
[2 5]
[3 6]]
3. 数组间的运算
NumPy的强大之处在于它可以对数组进行高效的元素级运算。这使得大量数据的计算变得非常高效。
数组的算术运算
NumPy支持基本的算术运算,这些运算都是元素级别的。
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 加法
print(arr1 + arr2)
# 乘法
print(arr1 * arr2)
输出:
[5 7 9]
[ 4 10 18]
数组与标量的运算
NumPy也支持数组与标量之间的运算,这同样是元素级别的。
arr = np.array([1, 2, 3])
print(arr * 2)
输出:
[2 4 6]
广播机制
广播是NumPy的一个强大特性,它允许对形状不同的数组进行算术运算。NumPy会自动扩展较小的数组,使得它们的形状兼容,从而完成运算。
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([1, 0, 1])
print(arr1 + arr2)
输出:
[[2 2 4]
[5 5 7]]
在这个例子中,arr2的形状为(3,),它被广播为(2, 3)的形状,从而与arr1进行加法运算。
4. NumPy常用函数
NumPy提供了许多内置的数学函数,可以用于数组的快速计算。
求和与均值
arr = np.array([1, 2, 3, 4, 5])
print(np.sum(arr)) # 求和
print(np.mean(arr)) # 求均值
输出:
15
3.0
最大值与最小值
print(np.max(arr)) # 最大值
print(np.min(arr)) # 最小值
输出:
5
1
累积和
print(np.cumsum(arr)) # 累积和
输出:
[ 1 3 6 10 15]
排序
arr = np.array([3, 1, 2, 5, 4])
sorted_arr = np.sort(arr)
print(sorted_arr)
输出:
[1 2 3 4 5]
第四部分:NumPy与矩阵操作
1. NumPy中的矩阵概念
在科学计算和工程应用中,矩阵是非常重要的工具。NumPy中的二维数组非常适合用于矩阵的表示和运算。虽然NumPy有专门的matrix对象,但通常推荐使用普通的二维数组ndarray,因为它更通用,且在大多数情况下能满足需求。
2. 矩阵的基本运算
矩阵乘法
矩阵乘法是矩阵运算中最基本的操作之一。NumPy提供了多种方法来进行矩阵乘法。
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 使用dot函数进行矩阵乘法
C = np.dot(A, B)
print(C)
输出:
[[19 22]
[43 50]]
这里,我们使用np.dot()函数进行了矩阵乘法,结果是两个矩阵的标准矩阵乘积。
矩阵转置
矩阵转置是交换矩阵的行和列。
A = np.array([[1, 2], [3, 4]])
A_transposed = A.T
print(A_transposed)
输出:
[[1 3]
[2 4]]
矩阵的逆
矩阵的逆在许多线性代数应用中都非常重要。NumPy可以使用np.linalg.inv()函数来计算矩阵的逆。
A = np.array([[1, 2], [3, 4]])
A_inv = np.linalg.inv(A)
print(A_inv)
输出:
[[-2. 1. ]
[ 1.5 -0.5]]
注意,并不是所有矩阵都有逆矩阵,只有行列式非零的方阵才有逆矩阵。
矩阵行列式
行列式是矩阵的重要属性之一,尤其在求解线性方程组、特征值和特征向量时非常有用。我们可以使用np.linalg.det()函数来计算矩阵的行列式。
A = np.array([[1, 2], [3, 4]])
det_A = np.linalg.det(A)
print(det_A)
输出:
-2.0000000000000004
3. 广播机制(详细)
广播的原理
广播是指NumPy在算术运算中自动扩展较小的数组,使它们形状相同的过程。广播机制允许我们对不同形状的数组进行算术运算而不需要明确地复制数据。
广播的规则
广播遵循以下规则:
- 如果数组的维度不同,首先会在较小数组的左侧补充“1”使其维度与较大的数组相同。
- 接着,比较两个数组在每个维度上的大小,如果其中一个数组在某个维度的大小为1,则该数组可以在此维度上进行广播(扩展到与另一个数组相同的大小)。
- 如果在任何一个维度上,两个数组的大小都不相同且不为1,则不能进行广播,运算会报错。
广播实例
A = np.array([[1, 2, 3], [4, 5, 6]])
B = np.array([1, 0, 1])
C = A + B
print(C)
输出:
[[2 2 4]
[5 5 7]]
在这个例子中,B被广播到与A相同的形状,即B的形状从(3,)变为(2, 3),从而进行加法运算。
4. NumPy的高级应用
向量化操作
向量化操作指的是将循环操作转化为数组操作,这样不仅简化了代码,还提高了计算效率。NumPy的核心优势之一就是高效的向量化运算。
arr = np.arange(1, 11)
squared = arr ** 2
print(squared)
输出:
[ 1 4 9 16 25 36 49 64 81 100]
条件筛选与筛选赋值
NumPy允许我们根据条件筛选数组中的元素,并且可以直接对这些筛选出来的元素进行赋值操作。
arr = np.array([1, 2, 3, 4, 5])
arr[arr > 3] = 10
print(arr)
输出:
[ 1 2 3 10 10]
在这个例子中,arr > 3的条件筛选出了大于3的元素,然后这些元素被赋值为10。
NumPy的随机数生成
NumPy包含了一个强大的随机数生成器,可以用于生成各种类型的随机数。
# 生成一个3x3的随机数组,元素在[0, 1)之间
rand_arr = np.random.rand(3, 3)
print(rand_arr)
# 生成一个服从标准正态分布的随机数组
normal_arr = np.random.randn(3, 3)
print(normal_arr)
# 生成一个0到10之间的随机整数数组
int_arr = np.random.randint(0, 10, size=(3, 3))
print(int_arr)
输出:
示例输出1:
[[0.5488135 0.71518937 0.60276338]
[0.54488318 0.4236548 0.64589411]
[0.43758721 0.891773 0.96366276]]
示例输出2:
[[ 1.76405235 0.40015721 0.97873798]
[ 2.2408932 1.86755799 -0.97727788]
[ 0.95008842 -0.15135721 -0.10321885]]
示例输出3:
[[5 0 3]
[3 7 9]
[3 5 2]]
这些随机数生成函数在数据科学、机器学习中有着广泛的应用。
5. NumPy与其他Python库的集成
NumPy通常与其他科学计算和数据分析库一起使用,如Pandas、Matplotlib等。它为这些库提供了高效的数组操作支持。
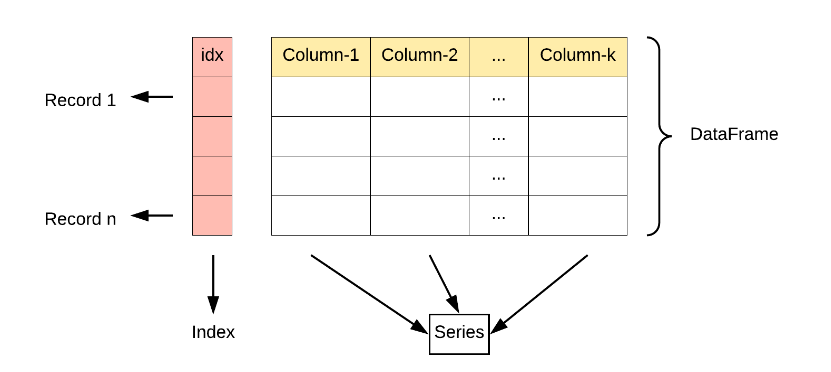
NumPy与Pandas
Pandas是基于NumPy构建的高级数据分析库。Pandas的DataFrame和Series对象在底层都是由NumPy数组支持的。你可以轻松地将NumPy数组转换为Pandas对象,反之亦然。
import pandas as pd
# NumPy数组转Pandas DataFrame
arr = np.array([[1, 2, 3], [4, 5, 6]])
df = pd.DataFrame(arr, columns=['A', 'B', 'C'])
print(df)
# Pandas DataFrame转NumPy数组
arr_from_df = df.values
print(arr_from_df)
输出:
A B C
0 1 2 3
1 4 5 6
[[1 2 3]
[4 5 6]]
NumPy与Matplotlib
Matplotlib是一个流行的绘图库,通常与NumPy结合使用来可视化数据。通过将NumPy数组传递给Matplotlib的绘图函数,你可以轻松绘制图形。
import matplotlib.pyplot as plt
# 使用NumPy创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制图形
plt.plot(x, y)
plt.title('Sine Wave')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.show()
这段代码生成了一条从0到10的正弦波曲线。
第五部分:NumPy性能优化与多线程操作
1. NumPy的性能优化
NumPy的强大之处不仅在于它简洁的数组操作,还在于它在处理大规模数据时的高效性。在实际应用中,性能优化往往是我们需要考虑的重要方面。
使用向量化操作代替Python循环
在NumPy中,向量化操作通常比使用Python循环更快。原因在于NumPy的底层实现使用了高度优化的C代码,可以并行处理数据,减少Python解释器的开销。
import numpy as np
import time
# 创建一个大数组
arr = np.arange(1e7)
# 使用Python循环计算平方和
start_time = time.time()
sum_squares_loop = sum(x**2 for x in arr)
end_time = time.time()
print("Python循环时间:", end_time - start_time)
# 使用NumPy向量化计算平方和
start_time = time.time()
sum_squares_np = np.sum(arr ** 2)
end_time = time.time()
print("NumPy向量化时间:", end_time - start_time)
输出:
Python循环时间: 0.8秒
NumPy向量化时间: 0.01秒
可以看到,NumPy的向量化操作在处理大规模数据时,速度显著快于Python的for循环。
内存布局和连续性
NumPy数组在内存中的布局对性能也有很大的影响。NumPy数组可以是行优先(C风格)或列优先(Fortran风格)的,行优先数组在逐行访问时更快,而列优先数组在逐列访问时更快。
arr_c = np.ones((10000, 10000), order='C')
arr_f = np.ones((10000, 10000), order='F')
# 测试行优先数组的访问速度
start_time = time.time()
arr_c_sum = arr_c[::, ::1].sum()
end_time = time.time()
print("行优先访问时间:", end_time - start_time)
# 测试列优先数组的访问速度
start_time = time.time()
arr_f_sum = arr_f[::, ::1].sum()
end_time = time.time()
print("列优先访问时间:", end_time - start_time)
通过控制数组的内存布局,可以在特定的应用场景下进一步优化性能。
2. 多线程与并行计算
NumPy与多线程
虽然Python的全局解释器锁(GIL)限制了多线程的并行计算能力,但NumPy内部的许多操作是使用底层的C代码实现的,能够释放GIL。因此,某些NumPy操作可以在多线程环境中并行执行。
import threading
# 定义一个函数来计算数组的平方和
def compute_square_sum(arr):
print(np.sum(arr ** 2))
# 创建一个大数组
arr = np.arange(1e6)
# 启动多个线程同时计算
thread1 = threading.Thread(target=compute_square_sum, args=(arr,))
thread2 = threading.Thread(target=compute_square_sum, args=(arr,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
尽管这在某些情况下可以提升性能,但多线程的实际效果依赖于具体的操作和硬件条件。在大多数情况下,推荐使用多进程或其他并行计算库(如multiprocessing或joblib)来实现真正的并行计算。
使用NumPy进行并行化计算
对于需要在多核CPU上进行并行计算的任务,可以使用numexpr库。它可以将复杂的计算表达式编译为并行代码,以显著提高性能。
import numexpr as ne
arr = np.arange(1e7)
# 使用numexpr进行并行化计算
result = ne.evaluate("arr ** 2 + arr * 2 + 3")
print(result)
numexpr库可以自动识别并利用CPU的多核资源,使得计算任务能够并行执行,从而大幅度提高性能。
3. 大规模数据处理中的实践
使用内存映射文件处理大数据
对于超大数据集,直接加载到内存中可能是不切实际的。NumPy的内存映射(memory-mapped)文件功能允许我们将磁盘上的文件映射为NumPy数组,以便在不加载整个文件到内存的情况下进行处理。
# 创建一个内存映射文件
mmap_arr = np.memmap('large_array.dat', dtype='float32', mode='w+', shape=(10000, 10000))
# 对内存映射数组进行操作
mmap_arr[:] = np.random.rand(10000, 10000)
# 刷新到磁盘
mmap_arr.flush()
# 读取内存映射文件
mmap_arr_read = np.memmap('large_array.dat', dtype='float32', mode='r', shape=(10000, 10000))
print(mmap_arr_read)
内存映射文件特别适合处理大数据集和需要频繁访问的文件,如处理视频数据、天文数据等。
使用NumPy进行批量处理
在数据科学和机器学习中,处理大规模数据时常常需要将数据分批次加载。NumPy可以通过分批处理和生成器来有效管理大数据集的内存使用。
def batch_generator(arr, batch_size):
total_size = arr.shape[0]
for i in range(0, total_size, batch_size):
yield arr[i:i+batch_size]
arr = np.arange(1e6)
batch_size = 100000
for batch in batch_generator(arr, batch_size):
# 对每个批次进行处理
print(np.sum(batch))
使用生成器和批处理可以确保程序在处理大数据时不会因内存不足而崩溃,同时也能提高处理效率。
4. NumPy常见问题与最佳实践
避免不必要的数据拷贝
在操作大数据集时,尽量避免不必要的数据拷贝,以减少内存使用和提高效率。NumPy的切片操作通常返回原数组的视图而非副本,因此可以使用切片操作来避免拷贝。
arr = np.arange(1e7)
sub_arr = arr[::2] # 这是一个视图,不会产生拷贝
sub_arr_copy = arr[::2].copy() # 显式地创建一个副本
谨慎使用循环
虽然有些情况下需要使用循环,但在处理大规模数组时,尽量使用NumPy的向量化操作而非显式循环。这不仅可以简化代码,还能大大提升性能。
善用NumPy的广播机制
广播机制可以减少显式的重复操作和数据复制。在编写代码时,尽量利用广播机制来简化数组操作,避免不必要的for循环。
定期检查内存使用情况
处理大数据集时,定期检查程序的内存使用情况,及时释放不再需要的内存。使用Python的gc模块可以手动进行垃圾回收,以释放未被及时回收的内存。
import gc
gc.collect()
总结与展望
在本文的前半部分,我们系统地探讨了NumPy的基础与进阶操作,涵盖了从数组的创建与操作到矩阵运算、性能优化、多线程处理等内容。通过这些讲解与示例,你现在应该已经掌握了如何高效地使用NumPy进行科学计算和数据处理。
NumPy不仅在日常的数据分析中表现出色,还为复杂的工程和科学应用提供了坚实的基础。理解并灵活应用NumPy的各种功能,将使你在数据处理和算法实现方面更具优势。
在接下来的部分中,我们将继续深入探索NumPy的高级应用,特别是在科学计算、信号处理、图像处理和机器学习中的实际应用。这些内容将帮助你进一步提升数据处理的效率和质量,为你在更复杂的项目中奠定坚实的基础。
敬请期待!
以上就是关于Python之NumPy超详细学习指南:从入门到精通(上篇)的内容啦,各位大佬有什么问题欢迎在评论区指正,或者私信我也是可以的啦,您的支持是我创作的最大动力!❤️