c++面试-语法糖(一)
1、const关键字的作用?(变量,参数,返回值)
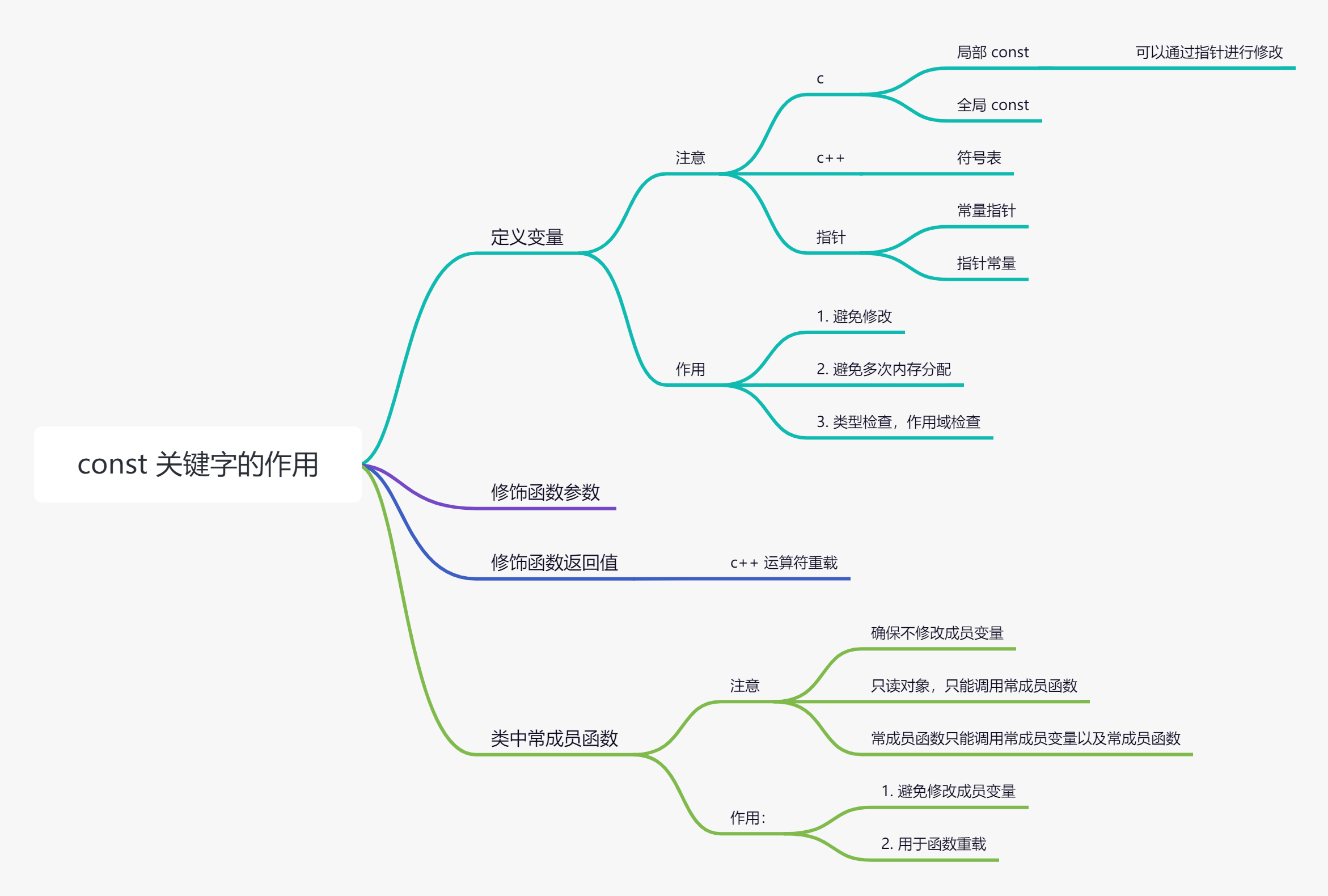
- 定义常量值:const 可以用于定义常量变量,其值在初始化后不能被修改。
const int MAX_SIZE = 100;
- 修饰指针:const 可以修饰指针,表示指针指向的内容是常量,或者指针本身是常量。
- 指向常量的指针:指针指向的内容不能被修改。
const int* p = &some_int;
*p = 5; // 错误,不能修改指向的内容`
- 常量指针:指针本身不能被修改,即不能指向其他地址。
int value = 10;
int* const p = &value;
p = &another_value; // 错误,不能修改指针本身`
- 指向常量的常量指针:指针本身和指向的内容都不能被修改。
const int* const p = &some_int;
*p = 5; // 错误
p = &another_int; // 错误`
- 修饰函数参数:当const 用于修饰函数参数时,它告诉调用者该参数在函数内部不会被修改。
void foo(const int& x) {
// x 不能被修改
}
- 修饰函数返回值:当const 用于修饰函数返回值时,它告诉调用者返回的对象不应被修改(如果返回的是引用或指针)。
const int& getValue() {
static int value = 42;
return value;
}
int main() {
const int& ref = getValue();
ref = 5; // 错误,不能修改返回值
}
- 修饰成员函数:当const 用于修饰成员函数时,它表示该函数不会修改调用它的对象的状态(即不会修改对象的任何非静态成员变量)。
class MyClass {
public:
int value;
int getValue() const {
return value;
}
void setValue(int v) {
value = v;
}
};
int main() {
MyClass obj;
const MyClass& constObj = obj;
int val = constObj.getValue(); // 正确
constObj.setValue(5); // 错误,不能调用非const成员函数
}
通过使用const,你可以提高代码的可读性和安全性,确保某些值或对象状态在程序的某些部分中不被意外修改。
const 和define区别:内存分配不一样
define只是替换,会新生成一个内存
const定义的变量再赋值给其他变量时,不会再生成一个内存
2、static关键字作用?(修改作用域范围)
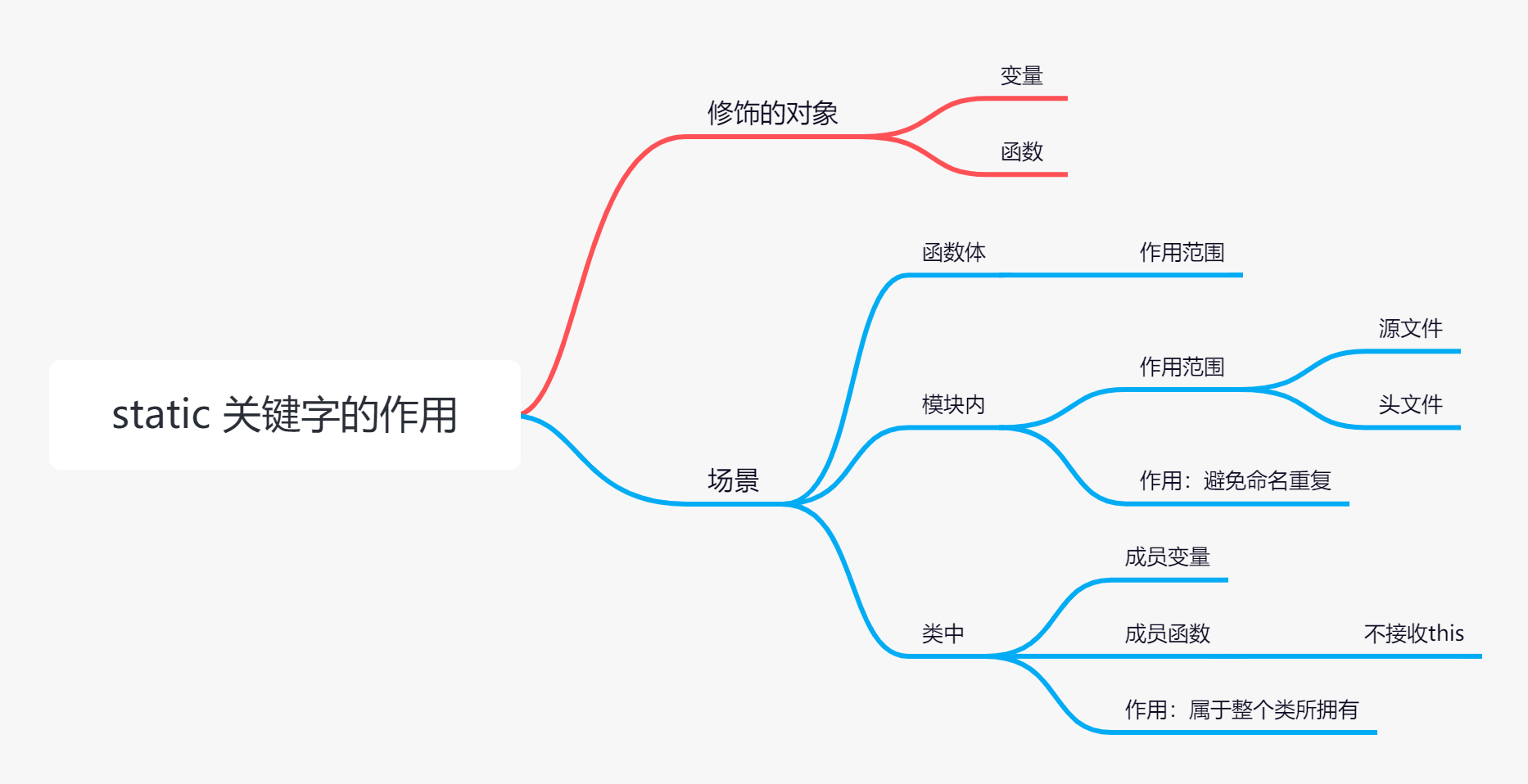
static修饰局部变量,局部变量的生命周期变长,函数执行结束不会立即释放内存
- static修饰全局变量,则该变量作用域变小,只能在当前文件使用,其它文件禁止用
- static修饰函数,函数作用域变小,只能在当前文件使用
- 修饰类的成员,成为静态成员,静态成员为所有类对象共享,属于类,不属于具体的某个对象,可以使用类名+作用域限定符访问
- 修饰类的成员变量:在类外初始化,没有初始化的话编译器会自动将其初始化为0。
- 修饰类的成员函数
- 注意:普通成员函数能调用静态成员函数,静态成员函数不能调用普通成员函数
3、什么是死锁?造成死锁的必要条件?如何避免死锁?
同步,互斥?
在C++(以及许多其他并发编程环境中)中,死锁是一个严重的问题,它发生在两个或更多的进程或线程无限期地等待一个资源,而该资源又被另一个等待其他资源的进程或线程所持有。这导致了一个循环等待条件,使得所有涉及的进程或线程都无法继续执行。
以下是死锁发生的四个必要条件(也称为死锁的四个C’s):
- 互斥条件(Mutual Exclusion):至少有一个资源必须处于非共享模式,即一次只有一个进程可以使用。如果其他进程请求该资源,则请求者只能等待,直到当前占有者释放该资源。
- 持有和等待条件(Hold and Wait):至少有一个进程必须持有至少一个资源,并等待获取一个当前被其他进程持有的资源。
- 非抢占条件(No Preemption):资源只能被持有它的进程自愿地释放。系统不能强制进程释放资源。
- 循环等待条件(Circular Wait):必须存在一个进程-资源的循环链,其中每个进程都在等待下一个进程所持有的资源。
- 要解决死锁问题,可以设计算法来预防或避免死锁,或者可以在死锁发生时进行检测并恢复。一些预防策略包括:
- 资源顺序分配法:给每个资源编号,并要求所有进程按照编号顺序请求资源。
- 一次性分配:在进程开始前,为其所需的所有资源一次性分配完毕。
- 线程死锁等待超时则自动放弃请求并且释放自己占有的资源
检测策略则是定期检查系统状态,以判断是否存在死锁。如果存在,则采取措施来打破死锁,如撤销某些进程并释放其资源。
在C++中,使用多线程编程时,开发者需要特别注意避免死锁,尤其是在使用互斥锁(如std::mutex)、条件变量(如std::condition_variable)或其他同步原语时。正确的同步和互斥策略是避免死锁的关键。
4、c/c++中内存可以划分为几个部分?
在C/C++中,内存可以大致划分为以下几个部分:
- 栈区(Stack):栈区由编译器自动分配和释放,主要存放函数的参数值、局部变量的值等。函数的调用过程也是通过栈来完成的。其操作方式类似于数据结构中的栈,由高地址向低地址增长。
- 堆区(Heap):堆区一般由程序员手动申请以及释放,若程序员不释放,程序结束时可能由操作系统(OS)回收。堆区的内存分配类似于链表,由低地址向高地址增长。
- 全局/静态存储区:全局变量和静态变量的存储被放在同一块内存中。初始化的全局变量和静态变量存储在一个区域,而未初始化的全局变量和未初始化的静态变量存储在另一个相邻的区域。程序结束后,这些变量所占用的空间由系统释放。
- 文字常量区:常量字符串就是存储在这个区域中。程序结束后,这部分内存也由系统释放。
- 程序代码区:存放函数体的二进制代码。
此外,在某些描述中,还提到了自由存储区,这是由malloc等函数分配的内存块,与堆十分相似,但释放方式是通过free函数。
另外,从虚拟内存的角度来看,程序的内存分布可以进一步细分为预留内存地址(不可访问)、程序代码区(只读,存放代码和其他内容)、data段(存放初始化的全局变量和静态变量以及文字常量区)、bss段(存放未初始化的全局变量和静态变量)、堆、共享库文件(调用的库文件,位于堆和栈之间)、栈,以及操作系统和内核调用的内存地址。
需要注意的是,不同的操作系统和编译器可能对内存的管理和划分有所不同,但上述划分方式是比较常见和基础的。同时,程序员在编写代码时应当注意内存的管理,避免内存泄漏和野指针等问题。
5、new和malloc的区别

1.属性:
new属于c++运算符,编译器支持就可以,malloc是c的标准库函数,需要引用头文件才可以调用。
2.参数和返回值
malloc分配内存时需要指定内存大小,返回值是void*的指针,需要强制转换
new根据类型自动计算所需的空间大小,返回的是对象类型的指针。
3.安全性:
new操作符在分配内存失败时会抛出一个std::bad_alloc异常。这使得你可以更优雅地处理内存分配失败的情况。
malloc在内存分配失败时返回NULL。如果你忘记检查malloc的返回值,这可能会导致程序崩溃。
4.构造函数和析构函数
new操作符在分配内存后会调用对象的构造函数。这确保了对象在创建时就被正确地初始化。同样地,当使用delete释放内存时,对象的析构函数也会被调用。
malloc和free则不会调用构造函数或析构函数。因此,如果你正在分配一个类的实例,并且该类有构造函数或析构函数,那么你应该使用new和delete而不是malloc和free。
5.内存使用差异
malloc是从堆上动态分配内存。堆是操作系统中维护的一块特殊内存,用于程序的内存动态分配。
new则是从自由存储区上为对象动态地分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请的内存,都称为自由存储区。自由存储区不仅可以是堆,还可以是静态存储区,这取决于operator new在哪里为对象分配内存。
6、vector,list,map
在选择使用哪种容器时,应根据具体需求进行权衡。
如果需要频繁访问元素且内存分配不是问题,vector可能是一个好选择;
如果需要频繁插入和删除元素,list可能更适合;
而如果需要存储键值对并高效查找、插入和删除元素,那么map将是最佳选择。
1.底层实现和内存分配:
- vector的底层实现是一块连续的内存空间,因此支持通过下标快速访问元素。然而,当vector需要扩展容量时,它可能会申请一块更大的连续内存空间,并将原有元素复制到新空间中,然后释放原空间。这个过程可能导致性能开销,尤其是当在头部或中间位置插入元素时。
- list通过双向链表实现,其元素在内存中不一定连续。list的插入和删除操作只需调整相关节点的指针,无需移动大量数据,因此在频繁插入和删除的场景下性能更优。
- map的底层实现通常采用平衡二叉树(如红黑树),它存储的是键值对(key-value)。这种结构使得map在查找、插入和删除元素时都能保持相对稳定的性能,时间复杂度通常接近O(log n)。然而,由于平衡二叉树的特性,map不支持通过下标直接访问元素。
2.访问效率:
- vector和list都支持通过迭代器访问元素,但vector还支持通过下标直接访问,这在需要频繁访问元素时具有优势。
- 然而,list由于是通过链表实现的,访问任意位置的元素可能需要遍历链表,因此访问效率相对较低。
- map的访问效率取决于其底层实现(平衡二叉树)。虽然不如vector通过下标访问那样直接,但map的查找效率通常也很高,尤其是在数据量较大时。
3.用途和使用场景:
- vector适用于需要频繁访问元素且内存分配不是主要问题的场景,如数组或类似数组的数据结构。
- list适用于需要频繁插入和删除元素的场景,如链表数据结构。
- map则适用于需要存储键值对并高效查找、插入和删除元素的场景,如字典或哈希表。
7、c++代码如何调用c语言的代码?
在C++中调用C语言代码是完全可能的,并且这在混合编程中是非常常见的做法。以下是如何在C++代码中调用C语言代码的基本步骤:
- 在C语言代码中,确保你的函数使用extern “C”声明:
这是因为C++支持函数重载,它使用函数名修饰(也称为名称重整或名称修饰)来区分具有相同名称但不同参数类型的函数。而C语言不支持函数重载,因此不会进行这样的名称修饰。使用extern “C”告诉C++编译器这个函数是用C语言链接规范来编译的,这样就不会进行名称修饰。
例如:
// file: my_c_code.c
#include <stdio.h>
extern "C" {
void my_c_function() {
printf("Hello from C!\n");
}
}
- 在C++代码中,包含C语言代码的头文件,并直接调用该函数:
你不需要在C++代码中再次声明extern “C”,只需直接调用函数即可。
例如:
// file: my_cpp_code.cpp
extern "C" void my_c_function(); // Declare the function, but do not define it here.
int main() {
my_c_function(); // Call the function
return 0;
}
- 编译和链接:
你需要将C和C++代码一起编译和链接。具体的编译和链接命令取决于你使用的编译器和构建系统。一般来说,你可能需要分别编译C和C++文件,然后将它们链接在一起。
例如,使用g++(GNU编译器集合的C++编译器)可以这样操作:
g++ -c my_c_code.c -o my_c_code.o # Compile the C code
g++ my_cpp_code.cpp my_c_code.o -o my_program # Link the C++ code with the compiled C code
然后,你就可以运行生成的程序了:
./my_program
这应该会输出 “Hello from C!”。
8、sizeof 和 strlen 的区别?
1.sizeof 是一个操作符,strlen 是库函数。
2.sizeof 的参数可以是数据的类型,也可以是变量,而 strlen 只能以结尾为‘\0‘的字符串作参数。
3.编译器在编译时就计算出了 sizeof 的结果。而 strlen 函数必须在运行时才能计算出来。并且 sizeof 计算的是数据类型占内存的大小,而 strlen 计算的是字符串实际的长度。
4.数组做 sizeof 的参数不退化,传递给 strlen 就退化为指针了。
注意:有些是操作符看起来像是函数,而有些函数名看起来又像操作符,这类容易混淆的名称一定要加以区分,否则遇到数组名这类特殊数据类型作参数时就很容易出错。最容易混淆为函数的操作符就是sizeof。
9、指针和引用的区别

10、空指针,野指针
空指针(Null Pointer)和野指针(Dangling Pointer)是编程中两种不同的指针状态:
- 空指针(Null Pointer):
- 空指针是一个指针变量,它被初始化为NULL或者nullptr(在C++11及以后的版本中)。
- 空指针不指向任何对象,也就是说它不指向内存中的任何地址。
- 使用空指针是安全的,因为它不指向任何有效的内存地址,所以试图通过它访问内存是不允许的,这可以防止访问无效的内存。
- 在C++中,空指针可以用于初始化指针,表示指针不指向任何对象。
- 野指针(Dangling Pointer):
- 野指针是一个指向曾经有效但现在已经不再有效的内存地址的指针。
- 这种内存地址可能是由于对象生命周期结束而被释放,或者由于某种原因变得不可访问。
- 野指针是危险的,因为它们可能指向已经被操作系统回收的内存区域,或者指向其他进程的内存空间,通过野指针访问这些内存区域可能会导致程序崩溃或安全漏洞。
- 野指针通常发生在动态内存分配后,如果分配的内存被释放,而指针没有被设置为NULL或nullptr,那么这个指针就变成了野指针。
总结来说,空指针是一个没有指向任何地址的指针,而野指针是一个指向了曾经有效但现在无效的内存地址的指针。在使用指针时,应该避免野指针的出现,确保在释放内存后将指针设置为NULL或nullptr,以防止潜在的错误和安全问题。
如何避免野指针?
野指针:没有初始化指针,系统随机分配一个地址,使用野指针容易造成内存泄漏。
如何避免?
①.指针初始化为空
②.使用指针操作指针对象时,需要检查是否为指针对象分配内存
③.new,malloc分配空间后,需要检查指针是否为空,如果为空,需要分配内存
④.释放内存后,需要将指针置空
⑤使用智能指针
11.extern关键字的作用
原理:引用还没有声明的变量或者函数,这个变量或函数在其他地方声明。
使用场景:
①.都是c或者都是c++,声明外部变量或者函数
②.c++调用c
12.strcpy,sprinft,memcpy区别

13、什么是内存泄漏?采用哪些方法来避免和减少这类错误?
用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元即为内存泄露。
(1). 使用的时候要记得指针的长度
(2). malloc的时候得确定在哪里free
(3). 对指针赋值的时候应该注意被赋值指针需要不需要释放
(4). 动态分配内存的指针最好不要再次赋值
(5). 在C++中应该优先考虑使用智能指针
(6). 析构函数尽量使用虚函数
如何定位内存泄漏问题?
Valgrind工具辅助定位
14.封装,继承,多态

多态

15.重写和和重载
静态多态:函数重载
重载是指在同一个作用域内,允许有多个同名函数存在,但这些函数的参数列表必须不同。参数列表不同可以是参数的类型不同、参数的数量不同,或者两者都不同。重载是编译时多态性的一种形式。
class Example {
public:
void print(int a); // 第一个print函数,接受一个int参数
void print(double a); // 第二个print函数,接受一个double参数
void print(int a, double b); // 第三个print函数,接受一个int和一个double参数
};
允许在同一个作用域中声明多个功能类似的同名函数(参数个数或者顺序不一样)
动态多态:虚函数重写
重写是指在派生类中重新定义基类中的虚函数(virtual function)。这是运行时多态性的一种形式,它允许派生类提供与基类不同的实现。为了实现重写,基类中的函数必须被声明为 <font style="color:rgb(6, 6, 7);">virtual</font>。
class Base {
public:
virtual void show() { // 基类中的虚函数
cout << "Base class show()" << endl;
}
};
class Derived : public Base {
public:
void show() override { // 派生类中的重写函数
cout << "Derived class show()" << endl;
}
};
在上面的例子中,Base 类有一个虚函数 show。Derived 类重写了这个函数。当通过基类指针或引用调用 show 函数时,如果指向的是派生类的对象,就会调用派生类中的 show 函数。
注意:
- 重写要求基类中的函数必须是
virtual。 - 派生类中的函数原型必须与基类中的虚函数完全匹配(除了
const和override修饰符)。 override关键字是C++11引入的,用于明确指出函数是重写的,它有助于编译器检查重写是否正确。
重载和重写都是C++中强大的特性,它们使得函数调用更加灵活,并且支持多态性。重载主要关注于同一类中不同函数的区分,而重写则关注于基类和派生类之间函数的多态性。
16.override,final
在C++中,<font style="color:rgb(6, 6, 7);">final</font> 关键字用于防止继承和重写。当你在类定义中使用 <font style="color:rgb(6, 6, 7);">final</font> 关键字时,你告诉编译器这个类不能被继承,或者当你在成员函数定义中使用 <font style="color:rgb(6, 6, 7);">final</font> 关键字时,你告诉编译器这个函数不能被派生类重写。
类定义中的 final
当你将一个类声明为 final 类时,你阻止了其他类从这个类继承。这可以用于表示某个类是设计为最终的、不可扩展的,或者是为了优化性能,因为编译器知道这个类不会被继承,可以做出一些优化。
class FinalClass final {
// ...
};
// 错误:试图从final类继承
class DerivedFromFinal : public FinalClass {
// ...
};
在上面的例子中,<font style="color:rgb(6, 6, 7);">FinalClass</font> 被声明为 <font style="color:rgb(6, 6, 7);">final</font>,因此你不能创建一个从 <font style="color:rgb(6, 6, 7);">FinalClass</font> 继承的 <font style="color:rgb(6, 6, 7);">DerivedFromFinal</font> 类。
成员函数定义中的 final
当你在成员函数中使用 final 关键字时,你告诉编译器这个函数在派生类中不能被重写。这可以用来防止派生类改变基类的行为。
class Base {
public:
virtual void func() {
// ...
}
};
class Derived : public Base {
public:
void func() final {
// ...
}
};
// 错误:试图重写被声明为final的函数
class MoreDerived : public Derived {
public:
void func() override {
// ...
}
};
在上面的例子中,Derived 类中的 func 函数被声明为 final,这意味着 MoreDerived 类不能再重写 func 函数。
使用 final 的好处
- 设计意图:明确表示某个类或函数不应该被继承或重写,有助于代码的可读性和维护性。
- 性能优化:编译器可以对
final类或函数进行优化,因为它们不会被继承或重写。 - 避免错误:防止开发者无意中重写或继承不应该被修改的类或函数。
final 关键字是C++11标准引入的,它为C++的面向对象编程提供了更多的控制和明确性。
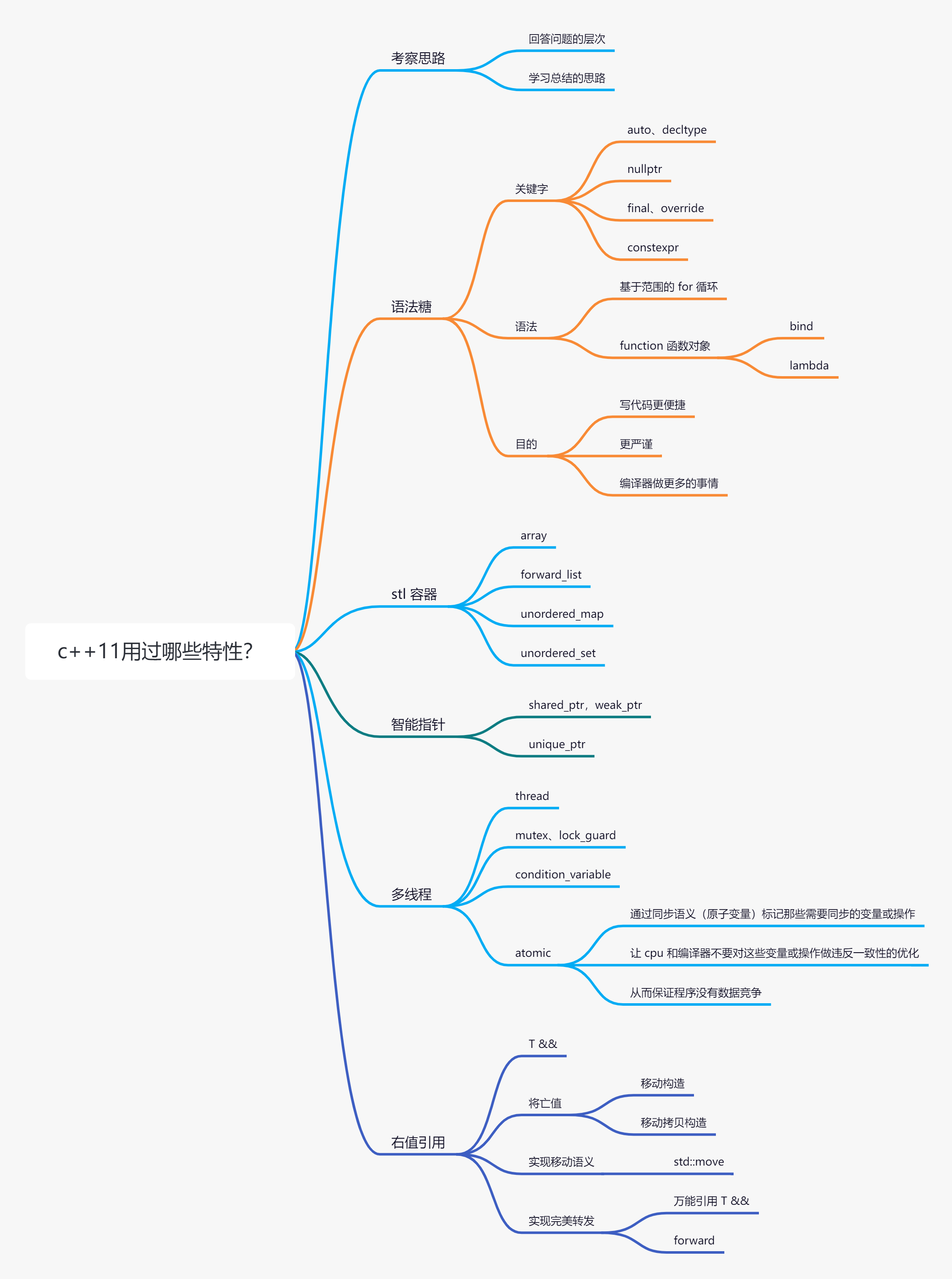
17.c++ 11特性
语法,使代码更便捷,编译器可以做更多事情
stl容器
智能指针
多线程
右值引用
18.动态库和静态库区别
静态库空间占用小,执行速度块,动态库空间占用大,执行速度慢
库发生变更,
静态库和调用的地方都需要重新编译
但是动态库只需要替换编译的动态库即可,调用处不需要重新编译

19.继承下的构造函数和析构函数执行顺序
继承下,构造函数按照依赖性,由强到弱进行构造,析构函数按照依赖链,由若到强进行析构

20.虚析构函数的作用(在析构函数前加virtual)
作用:为了使子类析构函数能够得到正常的调用

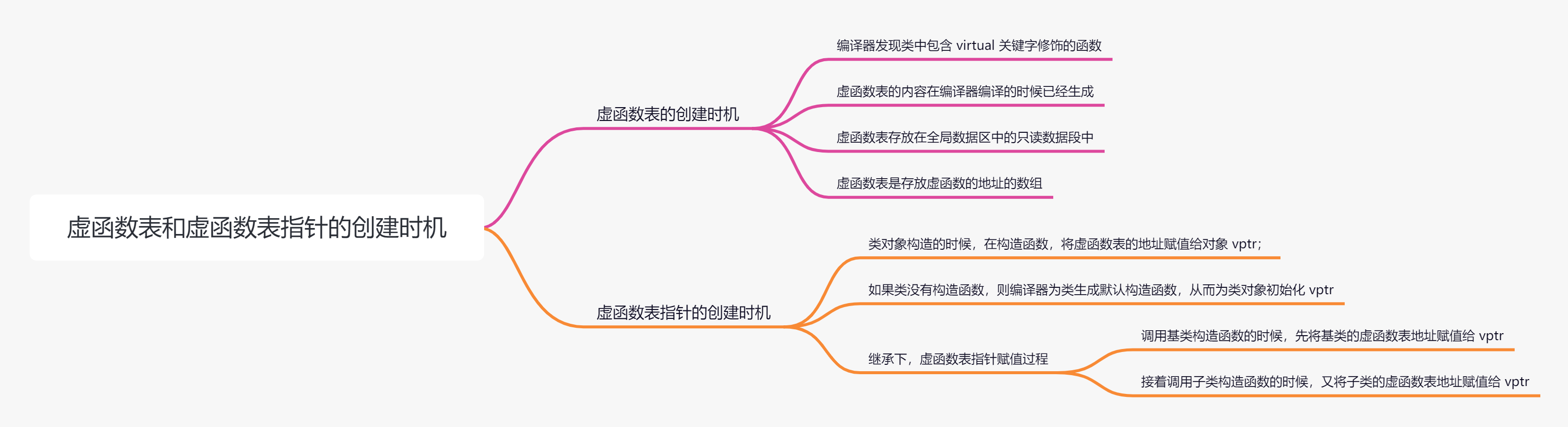
21.虚函数表和虚函数表指针
在C++中,虚函数表(Virtual Table,简称v-table)和虚函数表指针(Virtual Table Pointer,简称vptr)是实现运行时多态的关键机制。它们允许程序在运行时动态地调用正确的函数,即使这些函数是在派生类中定义的。
虚函数表(v-table)
- 定义:虚函数表是一个函数指针数组,每个指针指向一个虚函数的实现。
- 目的:存储指向虚函数的指针,使得在运行时能够调用正确的函数版本。
- 创建:编译器为每个包含虚函数的类生成一个虚函数表。
虚函数表指针(vptr)
- 定义:虚函数表指针是一个指向虚函数表的指针。
- 存储位置:通常存储在对象的内存布局的最前面。
- 目的:允许对象在运行时通过虚函数表指针找到并调用正确的虚函数。
工作原理
- 定义虚函数:在基类中声明虚函数。
- 生成虚函数表:编译器为每个包含虚函数的类生成一个虚函数表,表中包含指向这些虚函数实现的指针。
- 创建虚函数表指针:编译器在每个对象的内存布局的最前面添加一个指向该类虚函数表的指针。
- 调用虚函数:当通过基类指针或引用调用虚函数时,程序首先访问对象的虚函数表指针,然后通过虚函数表找到正确的函数实现并调用。
示例
假设我们有以下类定义和对象:
class Base {
public:
virtual void func() { std::cout << "Base::func" << std::endl; }
virtual void func2() { std::cout << "Base::func2" << std::endl; }
};
class Derived : public Base {
public:
void func() override { std::cout << "Derived::func" << std::endl; }
void func2() override { std::cout << "Derived::func2" << std::endl; }
};
int main() {
Base* b = new Derived();
b->func(); // 输出 "Derived::func"
b->func2(); // 输出 "Derived::func2"
delete b;
return 0;
}
在这个例子中:
- Base类定义了两个虚函数
func和func2。 - Derived类重写了这两个虚函数。
- main函数中创建了一个
Derived对象的指针,类型为Base*。 - 当调用
b->func()时,程序首先访问b指向的对象的虚函数表指针,然后通过虚函数表找到Derived::func的地址,并调用它。
注意事项
- 对象切片:如果将派生类对象赋值给基类对象,会丢失派生类特有的部分,但虚函数表指针仍然指向正确的虚函数表,因此虚函数调用仍然正确。
- 虚析构函数:通常在基类中定义虚析构函数,以确保删除派生类对象时能够正确调用派生类的析构函数。
虚函数表和虚函数表指针是C++实现多态性的关键技术,它们使得C++能够有效地支持面向对象编程中的动态绑定。
22.虚函数,纯虚函数
23.介绍一下c++的封装继承多态
C++是一种支持面向对象编程(OOP)的语言,它提供了封装、继承和多态这三大特性,使得代码更加模块化、可重用和易于维护。下面我将分别介绍这三大特性:
1. 封装(Encapsulation)
封装是将数据(属性)和操作这些数据的代码(方法)捆绑在一起的过程,并对外部隐藏内部实现的细节。在C++中,封装通过类(class)来实现。
- 访问控制:C++提供了三种访问修饰符来控制成员的访问权限:
public:公开的,可以被任何对象访问。protected:受保护的,只能被本类和派生类访问。private:私有的,只能被本类访问。
- 构造函数和析构函数:构造函数用于初始化对象,析构函数用于销毁对象。
- 友元函数:可以访问类的私有成员,但不是类的成员函数。
2. 继承(Inheritance)
继承是一种机制,允许一个类(派生类或子类)继承另一个类(基类或父类)的属性和方法。这有助于代码重用和建立层次结构。
- 单继承:一个派生类只能继承一个基类。
- 多继承:一个派生类可以继承多个基类。
- 虚继承:解决多继承中的菱形继承问题(钻石问题)。
- 访问修饰符:基类的访问修饰符会影响派生类对基类成员的访问权限。
3. 多态(Polymorphism)
多态性是指允许不同类的对象对同一消息做出响应的能力,即同一个接口,可以有多种不同的实现。C++中的多态主要有两种形式:编译时多态(通过函数重载实现)和运行时多态(通过虚函数实现)。
- 运行时多态:
- 虚函数:在基类中声明为
virtual的函数,可以在派生类中重写。 - 纯虚函数:在基类中声明为
virtual且没有实现的函数,使得基类成为抽象类,不能被实例化。
- 虚函数:在基类中声明为
- 动态绑定:在运行时确定调用哪个函数的过程,通常与虚函数一起使用。
示例代码
下面是一个简单的示例,展示了封装、继承和多态的使用:
#include <iostream>
// 封装
class Animal {
private:
int age;
public:
Animal(int a) : age(a) {}
void speak() const {
std::cout << "Animal makes a sound." << std::endl;
}
};
// 继承
class Dog : public Animal {
public:
Dog(int a) : Animal(a) {}
void speak() override {
std::cout << "Dog barks." << std::endl;
}
};
// 多态
class Cat : public Animal {
public:
Cat(int a) : Animal(a) {}
void speak() override {
std::cout << "Cat meows." << std::endl;
}
};
int main() {
Animal* pet1 = new Dog(5);
Animal* pet2 = new Cat(3);
pet1->speak(); // 运行时多态:Dog barks.
pet2->speak(); // 运行时多态:Cat meows.
delete pet1;
delete pet2;
return 0;
}
24.智能指针
在C++中,智能指针是一种自动管理内存分配和释放的类模板,它们帮助程序员避免内存泄漏和其他与动态内存分配相关的问题。C++11标准引入了几种智能指针类型,主要包含在头文件<memory>中。以下是C++中常用的几种智能指针:
1. std::unique_ptr
- 特点:独占所有权模型,一个
std::unique_ptr对象在任何时候只能拥有一个对象的所有权。它不允许复制(Copy),但可以移动(Move)。 - 用途:当你需要确保某个资源在特定作用域内被唯一管理时使用。
- 用法示例:
#include <memory>
#include <iostream>
class Widget {
public:
void doSomething() { std::cout << "Widget doing something." << std::endl; }
};
int main() {
std::unique_ptr<Widget> widget = std::make_unique<Widget>();
widget->doSomething();
// widget = nullptr; // 释放资源
}
2. std::shared_ptr
- 特点:共享所有权模型,多个
std::shared_ptr可以同时拥有同一个对象的所有权。使用引用计数机制来管理对象的生命周期,当最后一个std::shared_ptr被销毁或被重新赋值时,对象会被删除。 - 用途:当你需要多个指针同时管理同一个资源时使用。
- 用法示例:
#include <memory>
#include <iostream>
class Widget {
public:
void doSomething() { std::cout << "Widget doing something." << std::endl; }
};
int main() {
std::shared_ptr<Widget> widget1 = std::make_shared<Widget>();
std::shared_ptr<Widget> widget2 = widget1; // widget1 和 widget2 共享同一个对象
widget1->doSomething();
// 当widget1和widget2离开作用域时,对象会被自动删除
}
3. std::weak_ptr
- 特点:是一种不控制对象生命周期的智能指针,通常与
std::shared_ptr配合使用,用于解决强引用循环的问题。 - 用途:当你需要一个不增加引用计数的引用,或者需要打破引用循环时使用。
- 用法示例:
#include <memory>
#include <iostream>
class Node {
public:
std::weak_ptr<Node> next;
void setNext(std::shared_ptr<Node> n) { next = n; }
};
int main() {
std::shared_ptr<Node> node1 = std::make_shared<Node>();
std::shared_ptr<Node> node2 = std::make_shared<Node>();
node1->next = node2; // 通过weak_ptr避免循环引用
// 当node1和node2离开作用域时,两个Node对象都会被自动删除
}
注意事项
- 内存管理:智能指针自动管理内存,但它们本身也占用内存,且
std::shared_ptr的引用计数机制会带来额外的性能开销。 - 异常安全:智能指针通常不保证异常安全,如果构造过程中发生异常,可能会导致资源泄漏。
- 自定义删除器:可以通过模板参数为智能指针提供自定义删除器,例如使用
std::default_delete或自定义删除器类。
智能指针是现代C++编程中管理动态内存的强大工具,它们简化了资源管理,减少了内存泄漏的风险。

25.拷贝构造函数
拷贝构造函数是C++中的一个特殊成员函数,它用于创建一个对象的新实例,该实例是另一个同类型对象的副本。拷贝构造函数通常在以下情况下被调用:
- 当一个对象以值的方式传递给函数时。
- 当一个对象从函数返回时。
- 当一个对象需要通过另一个对象进行初始化时。
拷贝构造函数的一般形式如下:
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数的声明
// 其他成员函数和数据成员
};
// 拷贝构造函数的定义
ClassName::ClassName(const ClassName& other) {
// 拷贝other对象的数据成员到新对象
// 具体的拷贝逻辑取决于类的设计
}
在上述代码中,ClassName 是类名,other 是一个对另一个 ClassName 类型对象的引用,它用于初始化新创建的对象。
如果用户没有定义自己的拷贝构造函数,编译器会提供一个默认的拷贝构造函数,它逐个成员地进行浅拷贝。但是,如果类中包含指针成员或者需要深拷贝,通常需要用户自定义拷贝构造函数。
例如,如果一个类包含指向动态分配内存的指针,那么默认的拷贝构造函数可能会导致内存泄漏或双重释放,因为两个对象可能会尝试释放同一块内存。在这种情况下,自定义拷贝构造函数可以确保每个对象都有自己的内存副本。
自定义拷贝构造函数的一个例子:
class MyClass {
public:
int* data;
MyClass(int value) {
data = new int(value);
}
// 自定义拷贝构造函数
MyClass(const MyClass& other) {
data = new int(*(other.data));
}
~MyClass() {
delete data;
}
};
在这个例子中,拷贝构造函数确保了每个 <font style="color:rgb(6, 6, 7);">MyClass</font> 对象都有自己的 <font style="color:rgb(6, 6, 7);">data</font> 指针副本,指向不同的内存地址。这样可以避免多个对象共享同一块内存的问题。
26.堆和栈的区别
堆(Heap)和栈(Stack)是程序运行时用于存储数据的两种不同的内存区域,它们在内存管理、分配方式和用途上有着明显的区别:
- 存储内容:
- 栈:主要用于存储局部变量和函数调用时的上下文信息,如参数、返回地址和局部变量等。
- 堆:用于动态内存分配,程序员可以根据需要申请任意大小的内存块,并在不再需要时手动释放。
- 内存分配:
- 栈:由操作系统自动管理,以先进后出(LIFO, Last In First Out)的方式分配和释放内存。函数调用时,栈会自动分配内存给局部变量,函数返回时,这些内存会被自动释放。
- 堆:由程序员手动管理,可以使用如
malloc、new等函数分配内存,使用完毕后需要显式地使用free或delete来释放。
- 内存大小:
- 栈:通常有大小限制,不同系统和编译器栈的大小不同,一般在几百KB到几MB之间。
- 堆:理论上可以非常大,受限于进程的可用虚拟内存大小。
- 访问速度:
- 栈:访问速度较快,因为栈内存分配和回收的机制较为简单,且通常位于CPU缓存中。
- 堆:访问速度相对较慢,因为堆内存的分配和回收可能涉及到内存碎片整理和垃圾回收等复杂操作。
- 生命周期:
- 栈:栈上的内存生命周期与创建它的函数或代码块的执行周期一致,当函数执行结束或代码块退出时,栈内存自动释放。
- 堆:堆内存的生命周期由程序员控制,需要手动分配和释放,如果忘记释放,可能会导致内存泄漏。
- 用途:
- 栈:主要用于函数调用和局部变量的存储,适合生命周期短、大小固定的数据。
- 堆:用于存储需要动态分配大小的数据,如大型数据结构、对象等。
理解堆和栈的区别对于编写高效、稳定的程序非常重要,可以帮助程序员更好地管理内存资源。
27.内存碎片
在C++中,内存碎片(Memory Fragmentation)指的是由于内存分配和释放的不连续性,导致内存中出现许多无法使用的小块空间。内存碎片主要有两种类型:外部碎片和内部碎片。
- 外部碎片(External Fragmentation):
- 外部碎片发生在堆内存中,当程序频繁地分配和释放不同大小的内存块时,可能会在堆中留下许多小的空闲区域,这些区域太小,无法满足新的内存分配请求,即使总的空闲内存量足够。
- 外部碎片会导致可用内存减少,即使物理内存还有很多剩余,程序也可能因为找不到足够大的连续内存块而无法继续分配内存。
- 内部碎片(Internal Fragmentation):
- 内部碎片发生在内存分配时,分配器(如操作系统或内存管理库)为了管理内存,可能会分配比请求的稍微多一点的内存。例如,分配器可能会按照某个固定的大小(如4字节、8字节等)来分配内存,即使请求的内存大小不是这个固定大小的整数倍。
- 内部碎片是不可避免的,因为内存分配通常需要对齐,以满足特定硬件或操作系统的要求。
内存碎片可能导致的问题包括:
- 性能下降:内存分配器需要花费更多的时间来寻找足够大的连续内存块,这可能导致内存分配变慢。
- 内存利用率降低:由于碎片的存在,实际可用的内存量可能远低于总的空闲内存量。
- 内存泄漏:如果内存碎片导致无法找到足够大的内存块,程序可能会错误地认为没有足够的内存,而实际上内存是被碎片化的。
为了减少内存碎片,可以采取以下措施:
- 使用内存池:预先分配一大块内存,并在其中管理小块内存的分配和释放,可以减少外部碎片。
- 避免频繁的内存分配和释放:减少动态内存分配的频率,可以降低内存碎片的产生。
- 使用合适的内存分配策略:例如,使用按需增长的内存分配策略,可以减少内部碎片。
- 定期整理内存:在程序运行过程中,定期执行内存整理操作,合并小的空闲内存块,减少外部碎片。
在C++中,标准库提供了一些工具来帮助管理内存,如智能指针(std::unique_ptr、std::shared_ptr)和容器(如std::vector),这些工具可以自动管理内存,减少内存泄漏和碎片的风险。
28.进程间通讯
典型的进程间通信机制,具体包括管道,System V中的消息队列、信号量、共享内存,Linux信号机制,以及套接字机制(socket)。

29.SendMessage和 PostMessage
SendMessage 和 PostMessage 是 Windows 编程中用于发送消息给窗口的两个函数,它们在如何处理消息方面有以下主要区别:
- 同步与异步:
SendMessage是同步的:它将消息发送给窗口过程,并等待窗口过程处理完消息后才返回。这意味着在消息被处理之前,调用SendMessage的线程会被阻塞。PostMessage是异步的:它将消息放入目标窗口的消息队列中,然后立即返回。调用PostMessage的线程不会被阻塞,可以继续执行其他任务。
- 返回值:
SendMessage返回消息处理函数的结果,因此你可以从这个函数获取消息处理后的结果。PostMessage返回一个布尔值,指示消息是否成功加入到消息队列中,但不提供消息处理的结果。
- 使用场景:
SendMessage适用于需要立即处理消息并获取处理结果的情况,如在对话框中更新控件状态。PostMessage适用于不需要立即处理消息或者不需要获取处理结果的情况,如在不同线程之间发送通知消息。
- 死锁风险:
SendMessage可能会导致死锁,尤其是在涉及跨线程操作时。例如,如果两个线程互相等待对方通过SendMessage发送的消息,可能会导致双方都无法继续执行。PostMessage由于不等待消息处理,通常不会导致死锁。
- 消息处理顺序:
SendMessage不会进入消息队列,因此它的处理顺序是确定的,即按照发送的顺序立即处理。PostMessage将消息放入消息队列,消息的处理顺序可能会受到其他因素的影响,如消息的优先级和其他消息的插入。
- 跨线程行为:
- 当
SendMessage用于跨线程发送消息时,发送线程会等待接收线程处理完消息后才继续执行。 PostMessage在跨线程发送消息时,发送线程不会等待,消息会在接收线程的下一个消息循环中被处理。
- 当
在实际编程中,选择使用 SendMessage 还是 PostMessage 应根据具体需求和上下文来决定。如果需要确保消息按顺序处理并需要返回值,SendMessage 是更好的选择。如果希望消息发送后立即继续执行,不关心消息何时被处理,那么 PostMessage 更合适。
30.进程,线程,协程
进程、线程和协程是计算机科学中并发执行的三种不同抽象,它们在操作系统和程序设计中扮演着重要的角色。
- 进程 (Process):
- 进程是操作系统进行资源分配和调度的基本单位。
- 每个进程都有自己的独立内存空间,这意味着进程间的信息必须通过进程间通信(IPC)机制来交换,如管道、消息队列、共享内存等。
- 进程的创建和销毁成本相对较高,因为涉及到系统资源的分配和回收。
- 线程 (Thread):
- 线程是进程中的一个执行流,是CPU调度和执行的基本单位。
- 同一进程内的线程共享进程的资源,包括内存地址空间、文件描述符等,这使得线程间的通信更加容易,但也需要同步机制来避免竞态条件和数据不一致。
- 线程的创建和切换的开销比进程小,因为它们共享进程的资源。
- 多线程编程可以提高程序的并行性和性能,但也引入了线程安全和死锁等复杂问题。
- 协程 (Coroutine):
- 协程是一种程序组件,它允许挂起和恢复执行,通常用于非抢占式多任务处理。
- 协程通常由程序员或程序逻辑显式控制,而不是由操作系统内核控制。
- 协程在用户态管理,它们的创建、销毁和切换的开销比线程更小,因为它们不涉及操作系统内核的上下文切换。
- 协程通常用于处理大量的、协作的并发任务,如I/O操作、网络通信等,它们可以在等待I/O操作完成时挂起,让出CPU给其他协程。
- 协程可以通过语言支持(如C++20的协程、Python的asyncio库)或者库(如Boost.Coroutine、libco)来实现。
在现代编程中,协程越来越受到重视,因为它们提供了一种更轻量级的并发编程模型,可以在不牺牲性能的情况下简化并发编程的复杂性。协程通常与异步编程模型结合使用,以提高程序的可伸缩性和响应性。
在C++中,协程的支持是从C++20标准开始引入的,而在C++11及以后的版本中,通过线程库(如std::thread)和异步编程库(如std::async、std::future)提供了对多线程和异步操作的支持。其他语言,如Python、Go和Kotlin,也有各自对协程和异步编程的支持。
31.多线程
- 多线程 (Multithreading):
- 多线程是指在单个进程中并行运行两个或多个线程的技术。
- 每个线程可以看作是程序执行的独立路径,它们可以同时运行,共享进程的资源,如内存和文件句柄。
- 多线程可以提高程序的响应性和吞吐量,特别是在多核处理器上。
- 多线程编程需要处理同步问题,如死锁、竞态条件和线程安全,这通常通过使用互斥锁、信号量、条件变量等同步机制来实现。
- 线程池 (Thread Pool):
- 线程池是一种管理线程的技术,它维护多个线程的集合,用于执行任务而不需要频繁地创建和销毁线程。
- 线程池中的线程可以被复用,当一个任务执行完毕后,线程不会销毁,而是可以被分配去执行其他任务。
- 线程池可以减少创建和销毁线程的开销,提高系统的性能和响应速度。
- 线程池通常提供任务队列,任务被提交到队列中,由线程池中的线程异步执行。
- 线程池的大小可以根据系统的资源和需求进行配置,包括最大线程数、最小线程数、最大任务队列长度等。
线程池的优点包括:
- 资源管理:通过限制线程数量,避免过多的线程消耗系统资源。
- 性能提升:减少了线程创建和销毁的开销,线程可以被快速分配到新的任务。
- 任务调度:线程池可以提供任务调度功能,如优先级队列、任务分组等。
- 错误处理:线程池可以集中处理线程执行中的错误,简化编程模型。
在C++中,标准库提供了std::thread来支持多线程编程,但直到C++20之前,没有直接提供线程池的实现。C++20引入了std::jthread,它是一个管理线程生命周期的线程包装器,可以简化线程的管理和异常处理。对于线程池,通常需要使用第三方库,如Boost线程库,或者自己实现线程池。
32.tcp,udp
TCP(传输控制协议)和UDP(用户数据报协议)是两种常用的网络通信协议,它们都位于传输层,用于在网络中的设备之间传输数据。它们在功能和用途上有一些关键的区别:
- TCP (Transmission Control Protocol):
- 连接导向:TCP是一种面向连接的协议,这意味着在数据传输开始之前,必须在两端建立一个连接。
- 可靠性:TCP提供可靠的数据传输服务,确保数据包正确无误地到达目的地。如果数据包在传输过程中丢失,TCP会重新发送丢失的数据。
- 流量控制:TCP使用窗口机制来控制发送方的发送速率,以避免接收方处理不过来。
- 拥塞控制:TCP能够根据网络的拥塞程度调整数据传输速率,以避免网络过载。
- 顺序保证:TCP保证数据包按发送顺序到达,如果顺序错误,接收方会要求重新发送。
- 适用于:需要可靠传输的应用,如网页浏览(HTTP/HTTPS)、文件传输(FTP)、邮件传输(SMTP)等。
- UDP (User Datagram Protocol):
- 无连接:UDP是无连接的协议,数据传输前不需要建立连接,直接发送数据包。
- 不可靠性:UDP不保证数据包的可靠传输,不会尝试重新发送丢失的数据包,也不会保证数据包的顺序。
- 低延迟:由于没有建立连接和额外的控制机制,UDP通常具有较低的延迟。
- 小开销:UDP头部开销较小,只有8个字节,而TCP头部可能需要20个字节或更多。
- 适用于:对实时性要求高的应用,如视频会议、在线游戏、实时数据传输等,这些应用可以容忍一定程度的数据丢失,但对延迟敏感。
TCP和UDP的比较:
- 连接性:TCP需要建立连接,UDP不需要。
- 可靠性:TCP可靠,提供数据包确认和重传机制;UDP不可靠,不提供这些机制。
- 顺序:TCP保证数据顺序,UDP不保证。
- 速度:TCP由于其可靠性机制,速度可能较慢;UDP速度快,但可能丢失数据。
- 头部开销:TCP头部较大,UDP头部较小。
- 用途:TCP适用于需要可靠传输的应用,UDP适用于对实时性要求高的应用。
在实际应用中,选择TCP还是UDP取决于应用程序的需求。如果数据的完整性和准确性至关重要,TCP是更好的选择。如果应用程序能够处理偶尔的数据丢失,并且对延迟敏感,那么UDP可能更合适。