论文标题:iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
下载地址:https://arxiv.org/abs/2310.06625
开源代码:https://github.com/thuml/iTransformer
前言
ITransformer这篇文章我很早之前就留意到并阅读过,但是一直没有做解读,是因为我看到不少人在知乎上说论文的结果与PatchTST相比要弱一些。
ICLR24放榜之后,我看这篇论文是被收录了,这说明论文思路,还是有值得借鉴之处的。本文就借此解读ITransformer论文,另一半也结合这篇文章,谈一谈时序方面可以进一步做的工作。
为什么transformer直接应用到时序预测效果不好?
-
transformer的一个时间步内具有不同物理意义的时间序列,被切分成小段,然后把这些变量映射到一个token,间接摧毁了变量间的联系。
-
因为第一条的做法,导致直接应用注意力机制实际很难学到不同变量间的关系,或者说学到的变量间关系是过拟合的关系。
本文工作
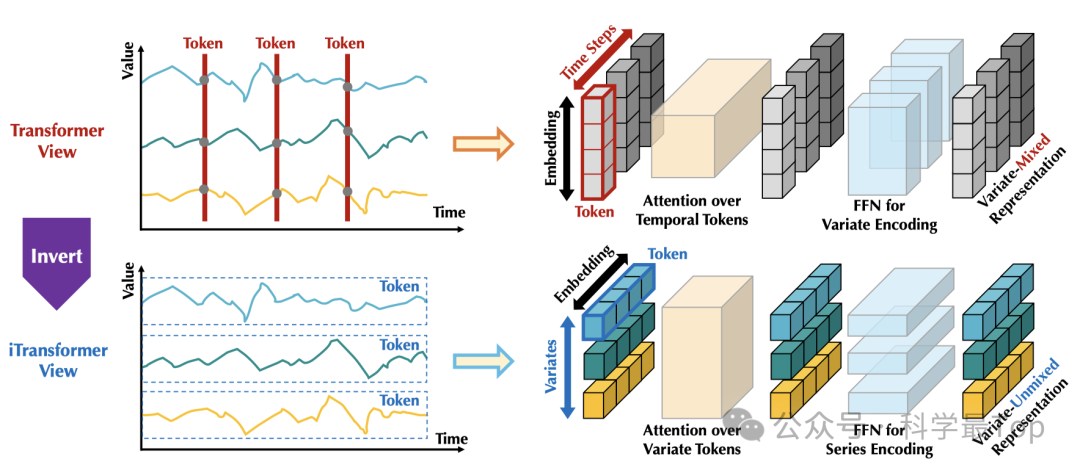
如图所示,本文采取了一种倒置时间序列的做法。具体是将每个变量的整个时间序列独立地嵌入为token,作者称这是 Patch TST的极端情况(关于Patch TST我单独写给解读文章,可参考阅读patch)。
相较于已有的基于Transformer的时序工作,本文工作扩大了局部感受视野。通过倒置,每个变量最终嵌入的token聚合了序列的全局特征表示,这可以更加以变量为中心,并且更好地利用注意力机制来进行多变量相关分析。
模型结构
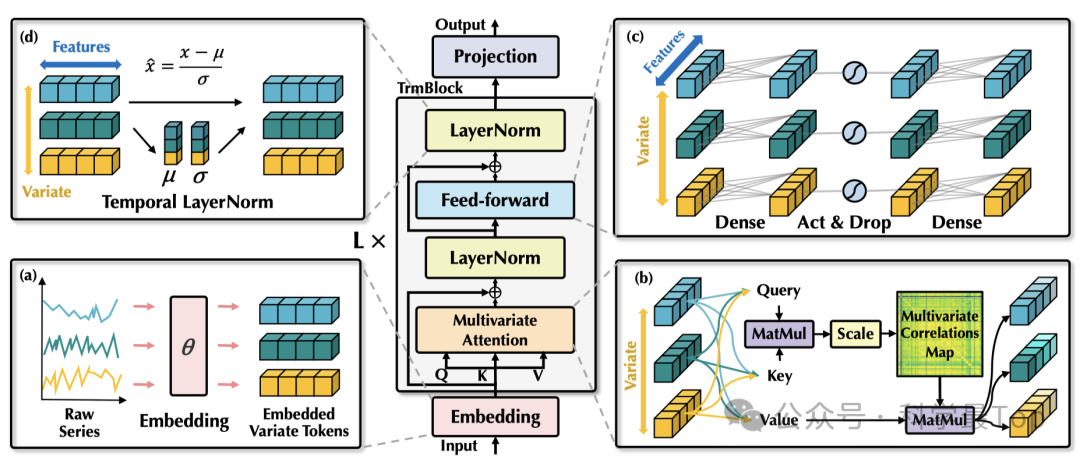
模型结构非常简单,只用了transformer的encoder部分,并且基本没有改变。
首先,做变量embedding,把每条时序变量整个嵌入为token,即不同变量的原始系列被独立地嵌入为token。
然后,采用自注意力机制对嵌入的变量token进行处理,增强可解释性,揭示多变量之间的相关性。
最后,通过前馈网络提取每个token的特征表示,并应用层归一化(Layer normalization)来减少变量之间的差异。
这样看来,其实这篇文章实际做了一个最大号的patch,然后在模型结构上基本没有改变。
实验结果
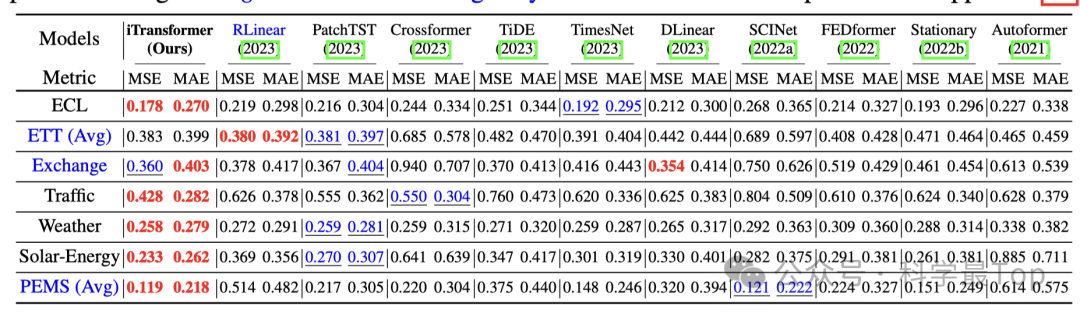
我这里只截取了一部分对比实验结果,论文中作者实验和分析篇幅很大,除了对比实验之外,还进行了消融实验、多变量间关系分析、特征表示能力分析。实验结果显示,iTransformer实现了最先进的性能,并展示了较好的框架通用性。
时序工作未来展望
业余阅读时序论文有几个月了,跟进下来感觉时序研究现在基本围绕着两个大方向转。一、模型结构创新。以informer这类论文为代表,主要工作在于改进注意力机制的运算。二、数据输入创新。以patch TST、ITranformer为代表,对模型结构改变不大,但改变了数据输入方式。
私以为未来可能出创新点的地方在于以上两个方面的结合,比如:
一、简单模型与patch尝试结合。我觉得现在强的是patch对数据的打包处理能力,而不是transformer本身的模型能力。所以把简单模型与patch结合、并有针对性的在模型结构和注意力机制做一些小改进可能有搞头。
二、patch操作之后的注意力机制改进。patch之后,获取特征表示,然后在此基础上考虑如何改进注意力机制、模型结构降低运算量、增强数据平稳性等。
欢迎大家关注我的公众号【科学最top】,专注于时序高水平论文解读,回复‘论文2024’可获取,2024年ICLR、ICML、KDD、WWW、IJCAI五个顶会的时间序列论文整理列表和原文。