导读
本文介绍了微调的基本概念,以及如何对语言模型进行微调。
从 GPT3 到 ChatGPT、从GPT4 到 GitHub copilot的过程,微调在其中扮演了重要角色。什么是微调(fine-tuning)?微调能解决什么问题?什么是 LoRA?如何进行微调?
本文将解答以上问题,并通过代码实例展示如何使用 LoRA 进行微调。微调的技术门槛并不高,如果微调的模型规模不大 10B 及 10B 以下所需硬件成本也不高(10B模型并不是玩具,不少生产中会使用10B的模型),即使非专业算法同学,也可动手尝试微调自己的模型。
除了上面提到的 ChatGPT、GitHub copilot产品,微调可以做的事情还非常多。如针对特定任务让模型编排API(论文:GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction)、模拟特定人的说话方式(character.ai 产品,目前估值10亿美元)、让模型支持特定语言,还有B站上各种 stable diffusion 炼丹教程,都用到了微调技术。
微调是利用已经训练好的模型(通常是大型的预训练模型)作为起点,在新的数据集进一步训练模型,从而使其更适合特定的应用场景。本文介绍 fine-tuning 的概念与过程,并对一个微调的过程代码进行分析。
一、什么是 fine-tuning
GPT-3 使用大量互联网上的语料,训练完成后,并不适合对话这个场景。如给到 GPT3 输入“中国的首都是哪里?” GPT3 基于训练后的模型的参数进行推理,结果可能是“美国的首都是哪里?”。
训练数据中,这两句话一起出现的概率非常高,在GPT3的训练预料里面可能也会出现多次。但这种输出明显不满足 ChatGPT 的场景。还需要多阶段的优化过程使 ChatGPT 更擅长处理对话,并且能够更好地理解和回应用户的需求。
CPT3 模型的微调过程包括几个关键步骤:
1.在大规模文本数据集上进行预训练,形成基础的语言能力(GPT3)。
2.通过监督微调,让模型适应对话任务,使其生成的文本更符合人类对话习惯。
3.使用基于人类反馈的强化学习(使用用户反馈数据,如赞踩、评分),进一步优化模型的输出质量,使其在多轮对话中表现得更连贯和有效。
4.通过持续的微调和更新,适应新需求并确保输出的安全性和伦理性。
后续会对上述步骤中的一些概念如监督微调、强化学习做介绍,在开始之前,先分析微调能起到什么作用。
1.1. 为什么要 fine-tuning
1.1.1. 微调可以强化预训练模型在特定任务上的能力
1.特定领域能力增强:微调把处理通用任务的能力,在特定领域上加强。比如情感分类任务,本质上预训练模型是有此能力的,但可以通过微调方式对这一能力进行增强。
2.增加新的信息:通过微调可以让预训练模型学习到新的信息,比如常见的自我认知类的问题:“你是谁?”“你是谁创造的?”,这类问题可通过微调让模型有预期内回答。
1.1.2. 微调可以提高模型性能
1.减少幻觉:通过微调,可以减少或消除模型生成虚假或不相关信息的情况。
2.提高一致性:模型的输出一致性、稳定性更好。给模型一个适度的 temperature ,往往会得出质量高更有创造性的结果,但结果是每次输出内容都不一样。这里的一致性和稳定性,是指虽每次生成内容不同,但质量维持在一个较高的水平,而不是一次很好,一次很差。
3.避免输出不必要的信息:比如让模型对宗教作出评价,模型可以委婉拒绝回复此类问题。在一些安全测试、监管审查测试时,非常有用。
4.降低延迟:可通过优化和微调,使用较小参数的模型达到预期效果,减少模型响应的延迟时间。
1.1.3. 微调自有模型可避免数据泄漏
1.本地或虚拟私有云部署:可以选择在本地服务器或虚拟私有云中运行模型,自主控制性强。
2.防止数据泄漏:这点对于一些公司来说非常重要,不少公司的核心竞争优势是长年积累的领域数据。
3.安全风险自主可控:如果微调使用特别机密的数据,可自定义高级别的安全微调、运行环境。而不是把安全问题都委托给提供模型推理服务的公司。
1.1.4. 使用微调模型,可降低成本
1.从零创造大模型,成本高:对大部分公司而言,也很难负担从零开始训练一个大模型的成本。meta最近开源的 llama3.1 405B模型,24000张H100集群,训练54天。但在开源模型之上进行微调,使用一些量化(减少精度)微调方式,可以大大降低门槛,还可以得到不错的效果。
2.降低每次请求的成本:一般而言,相同的性能表现,使用微调的模型与通用模型比,模型的参数量会更少,成本也就更低。
3.更大的控制权:可以通过模型参数量、使用的资源,自主平衡模型性能、耗时、吞吐量等,为成本优化提供了空间。
1.2. 一些相关概念区分
1.2.1. 基于人类反馈的强化学习(RLHF)与监督微调(SFT)
目前 OpenAI 的公开信息,ChatGPT 的主要改进是通过微调和 RLHF 来实现的。从 GPT3 到 ChatGPT,大概过程如下:预训练 → 微调(SFT) → 强化学习(RLHF) → 模型修剪与优化。强化学习与微调有什么区别?
简单来说,开发 ChatGPT 过程中,微调使模型能够生成更自然、更相关的对话,而强化学习强化学习帮助模型通过人类反馈来提升对话质量。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是一种强化学习(Reinforcement Learning)的具体方式。
强化学习(Reinforcement Learning, RL)是一种机器学习方法,模型通过与环境的交互来学习决策策略。模型在每一步的选择中会得到奖励或惩罚,目标是最大化长期的累积奖励。在自然语言处理(NLP)中,强化学习可以用于优化模型的输出,使其更符合期望的目标。
SFT(Supervised Fine-Tuning,监督微调)是一种微调的类型。如果按照是否有监督,还有无监督微调(Unsupervised Fine-Tuning,在没有明确标签的情况下,对预训练模型进行微调)、自监督微调(Self-Supervised Fine-Tuning,模型通过从输入数据中生成伪标签(如通过数据的部分遮掩、上下文预测等方式),然后利用这些伪标签进行微调。)
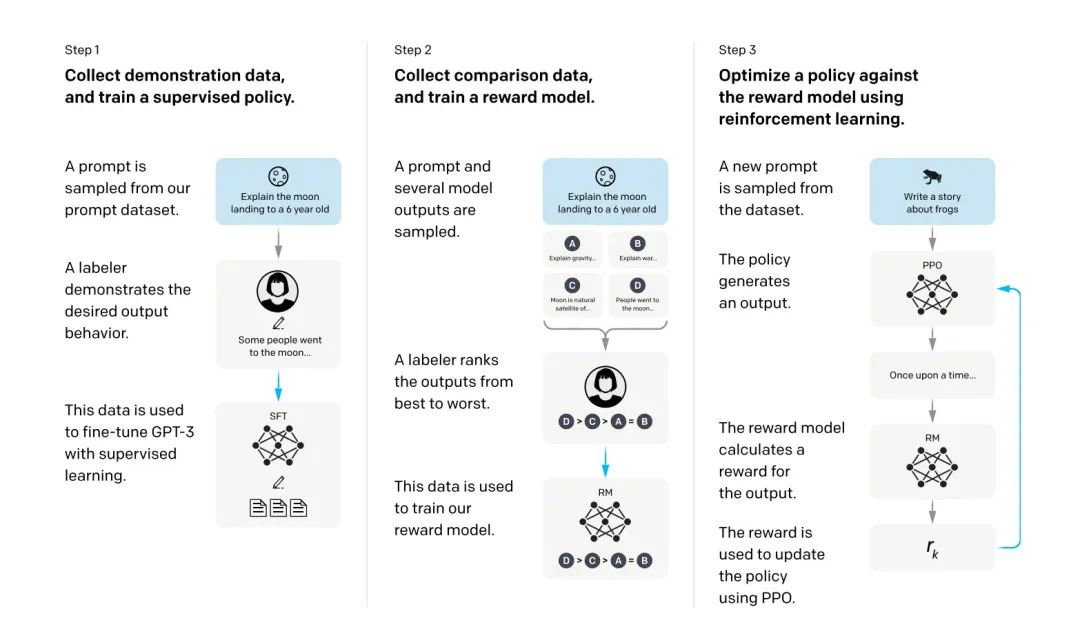
图片来自OpenAI 论文:Training language models to follow instructions with human feedback
在ChatGPT的训练中,OpenAI使用了一种称为通过人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)的方法。RLHF流程通常包括以下几个步骤:
1.初始模型生成:使用监督学习训练初始语言模型(Step1的过程),它已经能够生成合理的对话内容。
2.人类反馈:人类评审者与模型进行互动,对模型的回答进行评价,标注出哪些回答更好。Step2中的 A labeler ranks the outputs 的过程为标注员反馈的过程。
3.奖励模型训练:基于人类反馈的数据,训练一个奖励模型(Step2 中的 reward model),该模型能够根据输入的内容对模型输出进行评分。
4.策略优化:使用强化学习技术,让模型生成更高评分的输出,Step3的过程。
强化学习与微调相比,不论技术门槛、构造数据的成本、训练成本、训练时间、最终效果的不确定性,强化学习与微调都要高很多。强化学习需要使用大量人工标注的数据先训练一个奖励模型,然后需要通过大量尝试与迭代在优化语言模型。
在生产实践中,虽然强化学习也可提升具体任务表现,但对特定任务采用 SFT 的方式,往往能取得不错的效果。而强化学习成本高,非常依赖标注的数据,相对于 SFT 使用不多。
1.2.2. 继续预训练与微调
ChatGPT 的定位是一个通用场景的对话产品,在具体行业或领域内,类似 ChatGPT 的产品定位会更加细分。比如经常听到的医疗大模型、法律大模型、资金安全大模型。这种“行业大模型”不少是通过对基座继续预训练方式得到的。
继续预训练是在已经预训练的模型基础上,进一步在特定领域的数据上进行训练,以提高模型对该领域的理解和适应能力。数据集通常是未标注的,并且规模较大。
微调一般的目的在于优化模型在特定任务上的表现。微调通常是在一个小规模的任务数据集上进行的,目的是让模型在该特定任务上达到最佳表现。
两者可以结合使用,比如在安全领域内,一个特定的任务如对欺诈手法打一些具体的标签,模型使用的方式大概如下:
通用预训练(例如在大规模互联网数据上,公司级别进行训练) → 继续预训练(在特定领域数据上,公司内不同的行业/部门) → 微调(基于特定任务数据,部门/行业负责具体业务的小组各自微调)。
1.3. 小结
通过微调可以提升模型在特定任务上的表现。相对于预训练、强化学习,在生产过程中,使用到微调技术的场景更多,了解基本概念后,非技术人员也可进行微调,下一章节主要围绕如何微调进行展开。
二、如何 Fine-tuning
2.1. 微调的基本原理
微调是基于一个已经训练好的神经网络模型,通过对其参数进行细微调整,使其更好地适应特定的任务或数据。通过在新的小规模数据集上继续训练模型的部分或全部层,模型能够在保留原有知识的基础上,针对新任务进行优化,从而提升在特定领域的表现。
根据微调的范围,可以分为全模型微调和部分微调。
全模型微调(Full Model Fine-Tuning)更新模型的所有参数,适用于目标任务与预训练任务差异较大或需要最大化模型性能的场景。虽然这种方法能获得最佳性能,但它需要大量计算资源和存储空间,并且在数据较少的情况下容易导致过拟合。相比之下,部分微调(Partial Fine-Tuning)仅更新模型的部分参数,其他参数保持冻结。这种方法减少了计算和存储成本,同时降低了过拟合的风险,适合数据较少的任务,但在任务复杂度较高时可能无法充分发挥模型的潜力。
生产中,使用较多的是部分微调的方式,由于大模型的参数量级较大,即使对于部分参数调整也需要非常多的计算资源,目前使用比较多的一种方式的是参数高效微调(Parameter-Efficient Fine-Tuning, PEFT), PEFT 通过引入额外的低秩矩阵(如 LoRA)或适配层(如 Adapters),减少计算资源的需求。
LoRA 是一种高效的微调技术,能显著降低了微调的参数量和计算资源需求。它在保持模型原有能力的同时,实现了任务特定的高效适应,是一种特别适合大模型微调的技术。下一小节,注重介绍下 LoRA 这种微调方式。
2.2. 什么是 LoRA
2.2.1. LoRA 基本概念
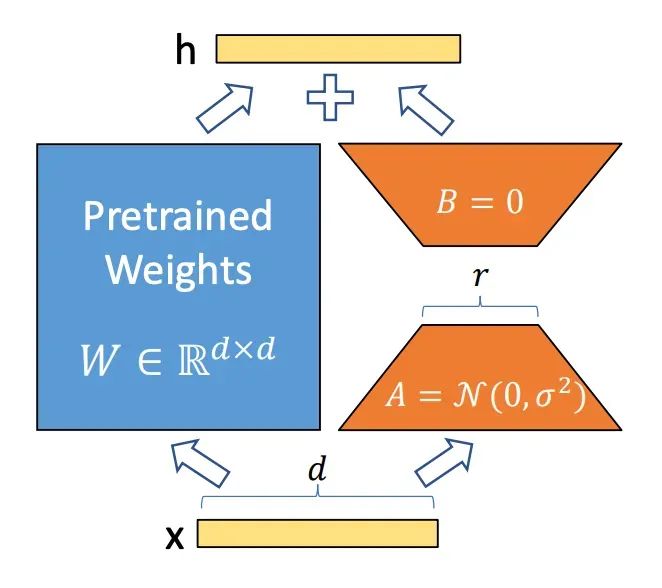
LoRA 原理(来源 LoRA 论文:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)
LoRA(Low-Rank Adaptation)通过引入低秩矩阵来减少微调过程中需要更新的参数数量(矩阵A和矩阵B),从而显著降低计算资源需求(降低为之前1/3,论文中数据)。
LoRA 另外一个非常重要的特性是:可重用性。由于LoRA不改变原模型的参数,它在多任务或多场景的应用中具有很高的可重用性。不同任务的低秩矩阵可以分别存储和加载,灵活应用于不同任务中。
比如在手机终端上,要跑应用的终端大模型。一个应用的模型会处理不同的任务,可以针对不同的任务,训练不同的 LoRA 参数,运行时基于不同任务,使用相同的基座模型,动态加载需要的 LoRA 参数。相对于一个任务一个模型,可以大大降低存储、运行需要的空间。
2.2.2. LoRA 原理分析
在机器学习中,通常会使用非常复杂的矩阵来让模型处理数据。这些结构通常都很“全能”,它们可以处理非常多种类的信息。但研究表明,让模型去适应特定任务时,模型其实并不需要用到所有这些复杂的能力。相反,模型只需要利用其中一部分就能很好地完成任务。
打个比方,这就像你有一把瑞士军刀,里面有很多工具(像剪刀、螺丝刀等等),但是在解决特定任务时,通常只需要用到其中的几个工具就可以完成大多数工作。在这个例子中,模型的矩阵就像瑞士军刀,虽然它很复杂(全秩),但实际上你只需要用到一些简单的工具(低秩)就足够了。
也就是说微调的时候,只调整那些对特定任务有影响的参数就可以了。原始矩阵维度较高,假设为 dk 维矩阵W0,要想进行矩阵调整,并且保持矩阵的数据(为了重用),最简单方式是使用矩阵加法,增加一个 dk 维度的矩阵ΔW。但如果微调的数据,还是一个d*k维度的矩阵,参数量就很多。LoRA 通过将后者表示为低秩分解,来减少参数的量级。
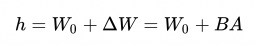
其中:
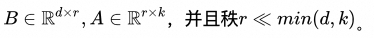
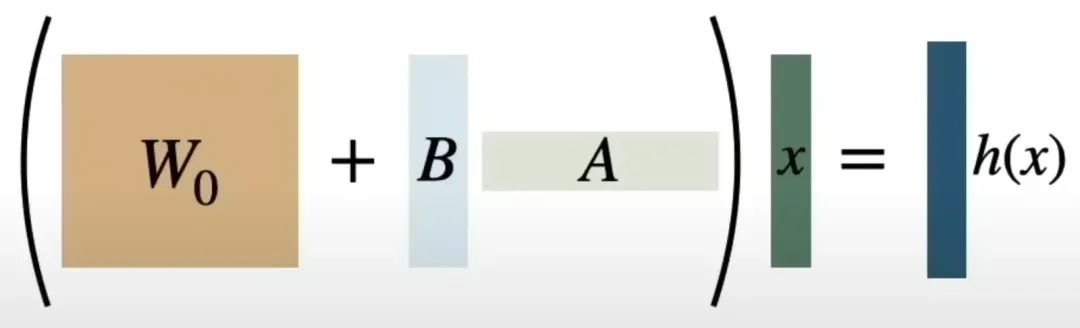
上图是矩阵分解后的示意图,可以直观的从矩阵的面积感知参数的多少,W0 为原始权重矩阵,如果需要进行全参数微调,W0 面积对应的参数都需要进行调整,而 LoRA 的方式只调整矩阵B、和矩阵A对应的参数面积的矩阵,比W0要少很多。
举例计算,d 为 1000,k为 1000,本来需要计算ΔW 10001000 = 100w 个参数,但通过矩阵分解,如果 r = 4,那么只需要计算 1000 * 4(矩阵B) + 41000(矩阵A) = 8000 个参数。
这里的 r = 4 并不是为了参数量级的减少而特意选的小的值,实际微调时很多情况使用的值就是4,论文中中实验数据表明,在调整 Transformer 中的权重矩阵时,在 r = 1 时对特定任务就有非常好的效果。
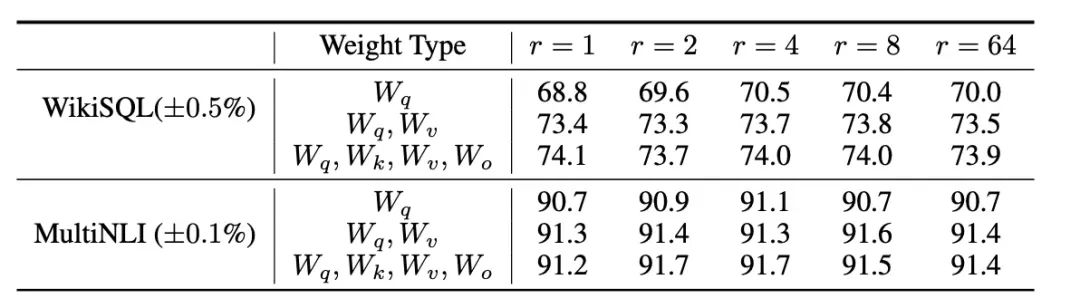
上面表格为在 WikiSQL 和 MultiNLI 上使用不同秩r的 LoRA 验证准确率。适配 Wq 和 Wv时,只有1的秩就足够了,而仅训练Wq则需要更大的r。Wq, Wk, Wv, Wo为 Transformer架构中自注意力模块中的权重矩阵。
2.3. 微调过程
微调基本过程,大概如下:
1.准备数据: 收集与目标任务相关的标注数据,将数据分为训练集、验证集,进行Tokenization处理。
2.微调参数设: 配置LoRA参数、微调参数如学习率,确保模型收敛。
3.微调模型: 在训练集上训练模型,并调整超参数以防止过拟合。
4.评估模型: 在验证集上评估模型性能。
其中需要特别注意的是微调过程中使用的数据,要求如下:
1.高质量:非常重要,再强调也不过分:Garbage in garbage out、Textbooks Are All You Need,都在强调数据质量重要性。
2.多样性:就像写代码的测试用例一样,尽量使用差异较大数据,能覆盖的场景更多的数据。
3.尽量人工生成:语言模型生成的文本,有一种隐含的“模式”。在看一些文字的时候,经常能识别出来“这是语言模型生成的”。
4.数量不少太少:通过LoRA论文看,100条开始有明显的改善,1000条左右,有不错的效果。
关于微调的数据量,OpenAI 微调至少 10 就可以。一般经验而言 50 到 100条数据,有非常明显的微调效果。建议是从 50 条开始,有明显效果逐步增加数量。
Example count recommendations
To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples with gpt-3.5-turbo but the right number varies greatly based on the exact use case.
We recommend starting with 50 well-crafted demonstrations and seeing if the model shows signs of improvement after fine-tuning. In some cases that may be sufficient, but even if the model is not yet production quality, clear improvements are a good sign that providing more data will continue to improve the model. No improvement suggests that you may need to rethink how to set up the task for the model or restructure the data before scaling beyond a limited example set.
2.4. 使用 LoRA 微调代码分析
本节使用 LoRA 微调了一个 67M 的 Bert的蒸馏模型,distilbert/distilbert-base-uncased,实现对电影的评论进行分类的功能,用于是正面还是负面的评论,微调使用的数据为 stanfordnlp/imdb,相关资源地址:
初始模型:https://huggingface.co/distilbert/distilbert-base-uncased
微调数据:https://huggingface.co/datasets/stanfordnlp/imdb
完整代码地址:https://github.com/wangzhenyagit/myColab/blob/main/fine-tuning.ipynb
使用的 colab 免费的T4 GPU(跑代码一定记得设置,CPU慢不止10倍)进行微调的,1000条微调数据,10个Epoch,大概6分钟跑完,稍大参数量的模型,应该也可以免费微调。如果微调10B的模型,估计需要付费买些计算资源,充值10美元估计差不多。
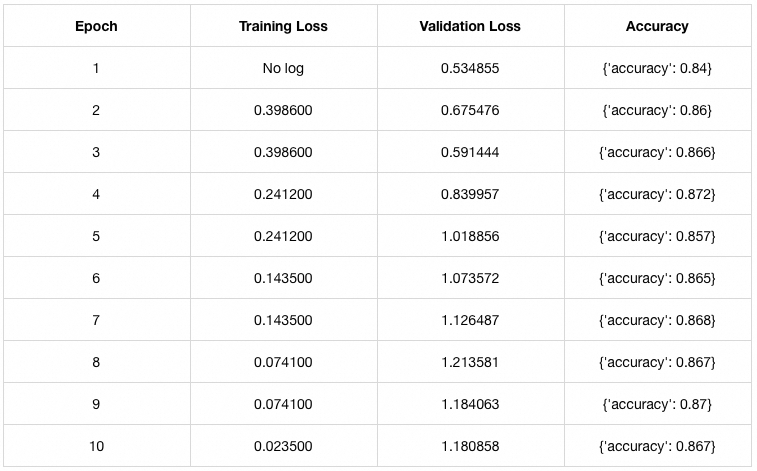
最终实现效果,从微调前50%的正确率(基本瞎猜)微调后为87%。只微调 Wq 权重矩阵。
r = 4 数据如下:
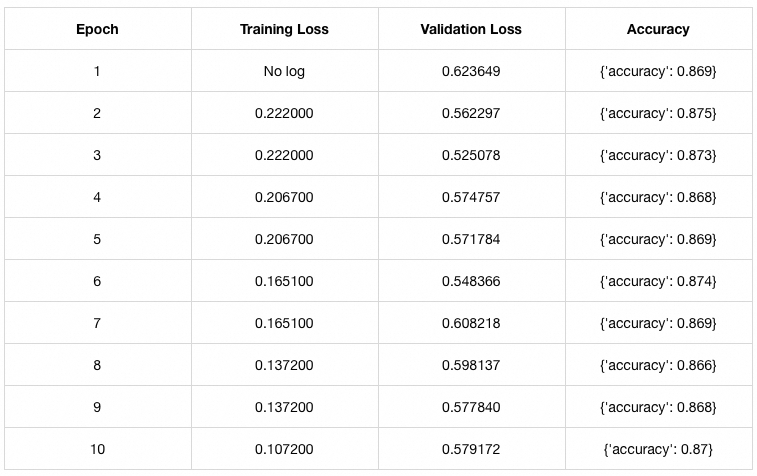
r = 1 数据如下:
可见和 LoRA 论文中的结论差不多,在微调Wq的情况下 r = 1 就已经足够了(相差不到 0.01,可忽略)。
代码分析如下。
2.4.1. 基本库安装与包引入

2.4.2. 微调数据构造
# # load imdb data
imdb_dataset = load_dataset("stanfordnlp/imdb")
# # define subsample size
N = 1000
# # generate indexes for random subsample
rand_idx = np.random.randint(24999, size=N)
# # extract train and test data
x_train = imdb_dataset['train'][rand_idx]['text']
y_train = imdb_dataset['train'][rand_idx]['label']
x_test = imdb_dataset['test'][rand_idx]['text']
y_test = imdb_dataset['test'][rand_idx]['label']
# # create new dataset
dataset = DatasetDict({'train':Dataset.from_dict({'label':y_train,'text':x_train}),
'validation':Dataset.from_dict({'label':y_test,'text':x_test})})
import numpy as np # Import the NumPy library
np.array(dataset['train']['label']).sum()/len(dataset['train']['label']) # 0.508
imdb 中数据格式例子如下:

分别使用1000条数据作为微调数据与验证数据。训练数据中,正向与负向的评价各自50%。
2.4.3. 加载初始模型
from transformers import AutoModelForSequenceClassification
model_checkpoint = 'distilbert-base-uncased'
# model_checkpoint = 'roberta-base' # you can alternatively use roberta-base but this model is bigger thus training will take longer
# define label maps
id2label = {0: "Negative", 1: "Positive"}
label2id = {"Negative":0, "Positive":1}
# generate classification model from model_checkpoint
model = AutoModelForSequenceClassification.from_pretrained(
model_checkpoint, num_labels=2, id2label=id2label, label2id=label2id)
# display architecture
model
模型架构:
DistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0-5): 6 x TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(activation): GELUActivation()
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
一个6层的 Transformer 模型,LoRA 影响的是:
(q_lin):Linear(in_features=768, out_features=768, bias=True)
这一层的权重,是个768*768 矩阵的权重向量。
2.4.4. tokenize 与 pad 预处理
# create tokenizer
from transformers import AutoTokenizer # Import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)
# add pad token if none exists
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model.resize_token_embeddings(len(tokenizer))
# create tokenize function
def tokenize_function(examples):
# extract text
text = examples["text"]
#tokenize and truncate text
tokenizer.truncation_side = "left"
tokenized_inputs = tokenizer(
text,
return_tensors="np",
truncation=True,
max_length=512, # Change max_length to 512 to match model's expected input length
padding='max_length' # Pad shorter sequences to the maximum length
)
return tokenized_inputs
# tokenize training and validation datasets
tokenized_dataset = dataset.map(tokenize_function, batched=True)
from transformers import DataCollatorWithPadding # Import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_dataset
对于 Tokenize 和 pad,几点说明:
1.数字化表示,与模型对齐:语言模型无法直接理解原始的文本数据。这些模型处理的对象是数字化的表示形式,Tokenize 的过程将文本转化为模型可以处理的整数序列,这些整数对应于词汇表中的特定单词或子词。不同模型使用不同的 Tokenize 方式,这也要求微调的时候,需要与模型中的一致。
2.减少词汇量:Tokenize 过程根据词汇表将文本切分为模型可识别的最小单位(如单词、子词、字符)。这不仅减少了词汇量,降低了模型的复杂性,还提高了模型处理罕见词或新词的能力。
3.并行计算需要: 通过 tokenization,可以将输入文本统一为模型预期的固定长度。对于较长的文本,Tokenize 过程可以将其截断;对于较短的文本,可以通过填充(padding)来补足长度。这样模型输入具有一致性,便于并行计算。
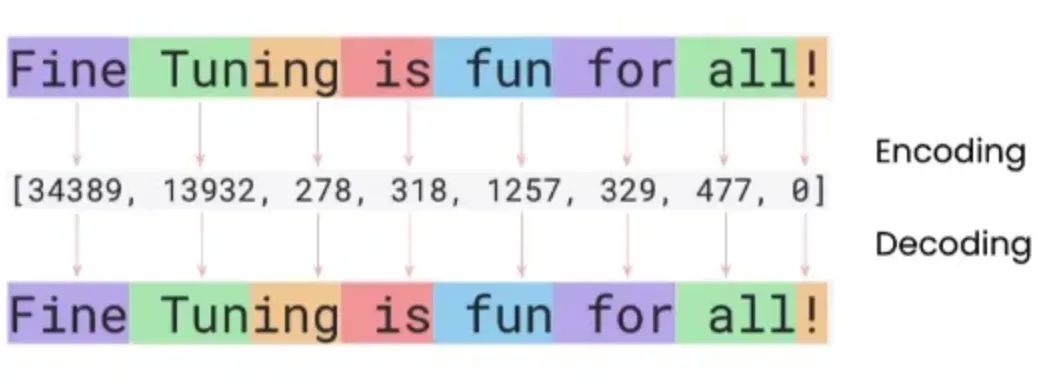
上面是文本进行 Tokenize 的过程,其中 Tuning 被拆成了两个小的token,这样就可以用有限的 token 来表示所有的单词。这也是有些时候大语言模型会“造词”的原因,错误的生成,Decode后的词可能是没有的单词。
2.4.5. 微调配置
微调前数据:
import torch # Import PyTorch
model_untrained = AutoModelForSequenceClassification.from_pretrained(
model_checkpoint, num_labels=2, id2label=id2label, label2id=label2id)
# define list of examples
text_list = ["It was good.", "Not a fan, don't recommed.", "Better than the first one.", "This is not worth watching even once.", "This one is a pass."]
print("Untrained model predictions:")
print("----------------------------")
for text in text_list:
# tokenize text
inputs = tokenizer.encode(text, return_tensors="pt")
# compute logits
logits = model_untrained(inputs).logits
# convert logits to label
predictions = torch.argmax(logits)
print(text + " - " + id2label[predictions.tolist()])
输出基本是随机输出。
Untrained model predictions:
----------------------------
It was good. - Positive
Not a fan, don’t recommed. - Positive
Better than the first one. - Positive
This is not worth watching even once. - Positive
This one is a pass. - Positive
import evaluate # Import the evaluate module
# import accuracy evaluation metric
accuracy = evaluate.load("accuracy")
# define an evaluation function to pass into trainer later
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy.compute(predictions=predictions, references=labels)}
from peft import LoraConfig, get_peft_model # Import the missing function
peft_config = LoraConfig(task_type="SEQ_CLS",
r=1,
lora_alpha=32,
lora_dropout=0.01,
target_modules = ['q_lin'])
peft_config:
LoraConfig(peft_type=<PeftType.LORA: ‘LORA’>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=‘SEQ_CLS’, inference_mode=False, r=1, target_modules={‘q_lin’}, lora_alpha=32, lora_dropout=0.01, fan_in_fan_out=False, bias=‘none’, use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core=‘megatron.core’, loftq_config={}, use_dora=False, layer_replication=None, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=False))
几点说明:
1.task_type=“SEQ_CLS”,说明任务的类型为分类任务。
2.r=1,LoRA 的 rank,在论文 7.2 WHAT IS THE OPTIMAL RANK r FOR LORA? 有分析此参数影响,一般为1~8,通常可设置为4。
3.lora_alpha=32, lora_alpha 参数是一个缩放因子,BA的权重系数,h = W0 + lora_alphaB*A。用于控制 LoRA 适应矩阵对原始权重的影响程度。经验法则是在开始时尝试一个较大的值(如 32)。
4.lora_dropout=0.01,防止模型过拟合的配置,训练过程中随机“丢弃”一部分神经元来防止模型过拟合,通常从一个较小的值开始。
5.target_modules = [‘q_lin’],前面提到的,影响的权重矩阵,这里只影响 model 中 q_lin。
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
trainable params: 601,346 || all params: 67,556,356 || trainable%: 0.8901
训练的数量不到参数量的百分之一。参数量越大的模型,这个训练的参数比越小。
# hyperparameters
lr = 1e-3
batch_size = 4
num_epochs = 10
from transformers import TrainingArguments
# Import Trainer# define training arguments
training_args = TrainingArguments(
output_dir= model_checkpoint + "-lora-text-classification",
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
from transformers import Trainer
# creater trainer object
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
data_collator=data_collator, # this will dynamically pad examples in each batch to be equal length
compute_metrics=compute_metrics,
)
# train model
trainer.train()
输结果为开头表格数据。
再次运行开始的的测试数据,输出:
Trained model predictions:
--------------------------
It was good. - Positive
Not a fan, don’t recommed. - Negative
Better than the first one. - Positive
This is not worth watching even once. - Negative
This one is a pass. - Positive
微调后分类正确。
以上为 LoRA 微调的代码示例。篇幅原因一些参数没有具体讲解,推荐使用Colab,目前Google也集成了免费的Gemini,参数意思有些模糊可以直接提问,试用下来和GPT-4o效果差不多。而且有报错一键点击,Gemini 就能提供改进建议,基本一次就能解决问题。
三、结语
本文介绍了微调的基本概念,以及如何对语言模型进行微调。微调虽成本低于大模型的预训练,但对于大量参数的模型微调成本仍非常之高。好在有摩尔定律,相信随着算力增长,微调的成本门槛会越来越低,微调技术应用的场景也会越来越多。
“Textbooks Are All You Need” 这篇论文中强调了数据质量对预训练的重要性,deep learning的课程中,也强调了训练数据的 Quality。想起 AngelList 创始人 Naval 的一句话,“Read the Best 100 Books Over and Over Again ” ,微调之于模型,类似于人去学习技能/特定领域知识。高质量的输入非常重要,正确方式可能是:阅读经典,反复阅读。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。