💗博主介绍:✌全平台粉丝5W+,高级大厂开发程序员😃,博客之星、掘金/知乎/华为云/阿里云等平台优质作者。
【源码获取】关注并且私信我
【联系方式】👇👇👇最下边👇👇👇
感兴趣的可以先收藏起来,同学门有不懂的毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多同学解决问题

前言
在当今信息化时代,社交媒体已经成为了人们日常生活中不可或缺的一部分。它不仅为用户提供了一个表达自我、分享信息的平台,同时也为企业提供了洞察市场趋势、理解用户需求的重要渠道。随着社交媒体数据量的爆炸式增长,如何有效地收集、存储、处理这些非结构化的大数据,并从中提取有价值的信息,成为了研究者们关注的重点问题。传统的数据处理技术面对海量的数据显得力不从心,因此,开发高效的数据分析系统变得尤为重要。
Hadoop作为一个开源的分布式计算框架,能够支持大规模数据集的存储和处理,非常适合用来构建社交媒体数据分析系统。通过利用Hadoop的MapReduce模型,可以将复杂的数据处理任务分解成多个子任务并行处理,极大地提高了数据处理的速度和效率。此外,Hadoop的HDFS(Hadoop Distributed File System)能够提供强大的数据存储能力,确保了大数据的可靠性和稳定性。
然而,仅仅拥有强大的数据处理能力还不够,对于普通用户而言,更加直观、易于理解的数据展示方式同样至关重要。因此,在本研究中,我们旨在设计并实现一个基于Hadoop的社交媒体数据分析可视化系统。该系统不仅要具备高效的数据处理能力,还需要能够将处理后的结果以图表、仪表盘等形式展现出来,使得非专业的用户也能够轻松地理解和分析数据背后的趋势和规律。这不仅有助于个人更好地管理自己的社交网络活动,同时也能帮助企业或组织更准确地定位目标受众,优化营销策略,提升服务质量。总之,这样的系统将极大地促进信息的传播与交流,为社会的进步和发展做出贡献。
一. 使用技术
- 前端可视化:Vue、Echart
- 后端:SpringBoot/Django
- 数据库:Mysql
- 数据获取(爬虫):Scrapy
- 数据处理:Hadoop
二. 功能介绍
1. 用户管理模块 👤
- 用户注册与登录 🔑:支持用户使用邮箱或手机号码进行注册及安全登录。
- 个人信息维护 📝:允许用户更新个人资料,包括头像、昵称、简介等基本信息。
- 隐私设置 🔒:用户可自定义其信息可见性和数据共享范围。
2. 数据采集模块 📊
- 社交数据抓取 📡:从社交媒体平台获取公开的用户帖子、评论、标签等数据。
- 用户行为追踪 🕵️♀️:记录用户在应用内的操作,如点赞、分享、评论等交互行为。
- 情感分析 😊😢:通过自然语言处理技术识别文本中的情感倾向。
3. 数据处理与分析模块 🧪
- 大数据存储与管理 🗄️:利用Hadoop分布式文件系统高效存储海量数据。
- 数据清洗与整合 🗑️:去除重复数据,纠正错误信息,并将多源数据融合处理。
- 热点话题挖掘 🔍:通过算法识别社交媒体上的热门话题和发展趋势。
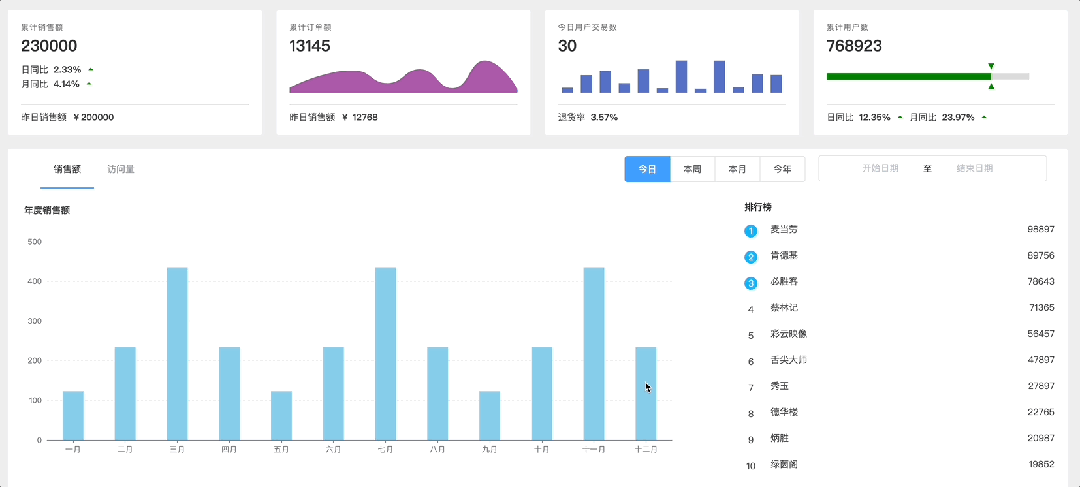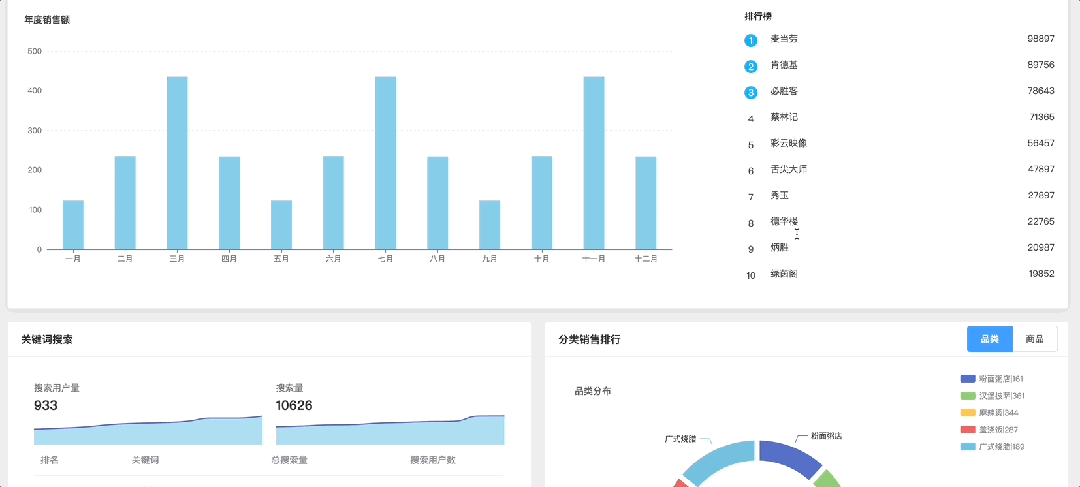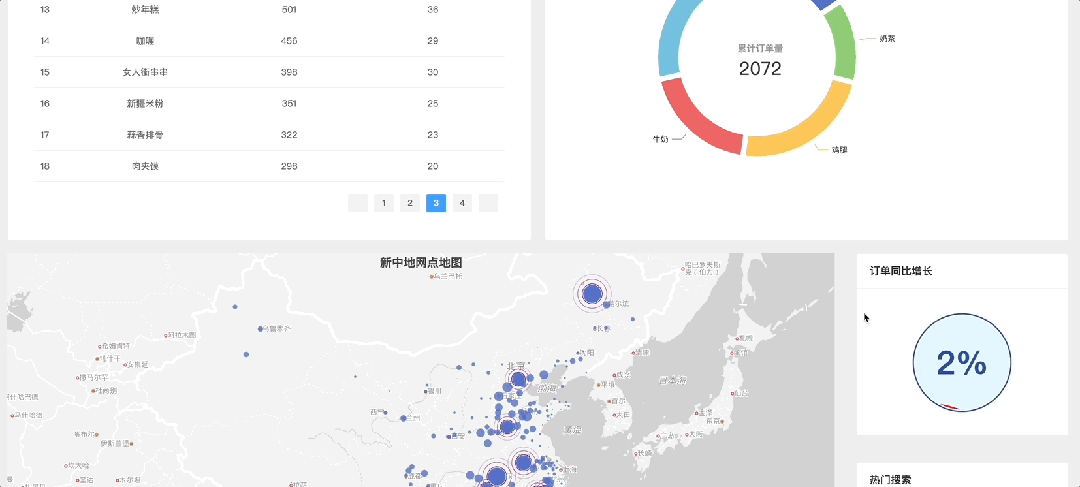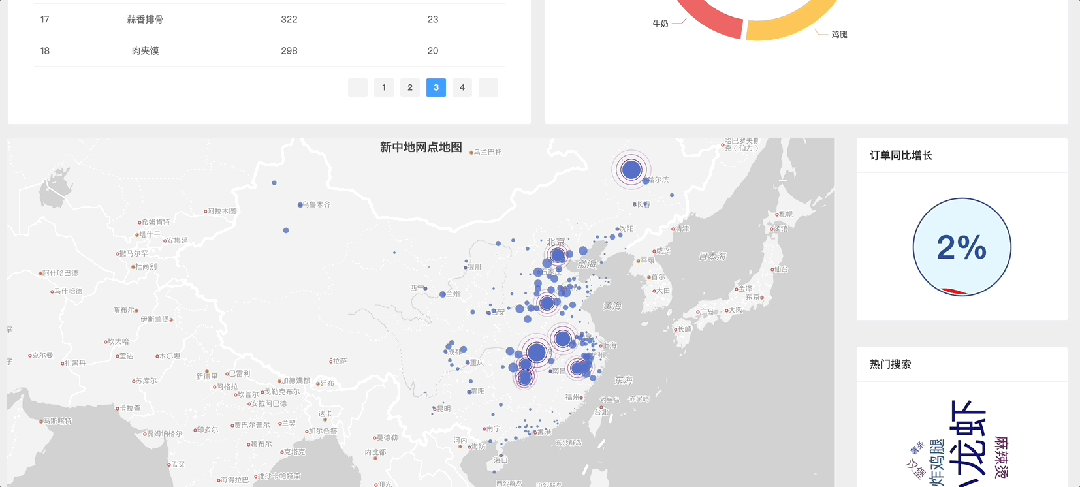
4. 可视化展示模块 📈
- 动态图表生成 🔄:根据分析结果实时生成图表,如柱状图、饼图、热力图等。
- 地理信息映射 🗺️:将数据与地理位置相结合,显示特定区域内的用户活跃度。
- 交互式仪表盘 🛠️:创建可交互的仪表板,让用户能更直观地探索数据。
5. 情感与趋势分析模块 🔍
- 情绪波动监测 📖:监控特定事件前后公众情绪的变化情况。
- 舆情预警 ⚠️:当检测到负面情绪或异常趋势时,自动发出预警通知。
- 主题建模 📑:采用机器学习方法识别出主要讨论主题及其演变过程。
6. 报告生成与导出模块 📄
- 自动化报告编写 🤖:根据分析结果自动生成详细的数据分析报告。
- 定制化报告模板 🎨:提供多种报告样式供用户选择,满足不同场景下的需求。
- 报告导出与分享 📩:支持将报告导出为PDF或其他格式,并通过邮件或链接分享。
7. 安全与合规模块 🔒
- 数据加密传输 🔐:确保所有数据在网络中传输时均经过加密保护。
- 访问控制 ⚖️:实施严格的权限管理机制,防止未授权访问。
- 合规性检查 📜:确保系统设计和数据处理流程符合相关法律法规的要求。
三. 项目可视化页面截图

四. 源码展示
4.1 Scrapy爬虫代码
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['example.com']
start_urls = [
'http://example.com',
]
def parse(self, response):
# 解析响应并提取数据
for item in response.css('div.some_class'): # 假设你想抓取的是在some_class下的信息
yield {
'title': item.css('h2.title::text').get(),
'link': item.css('a::attr(href)').get(),
'description': item.css('p.description::text').get(),
}
# 如果有分页链接,可以继续跟进
next_page = response.css('div.pagination a.next::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
4.2 Django框架代码
# models.py
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.CharField(max_length=100)
publication_date = models.DateField()
def __str__(self):
return self.title
# views.py
from django.http import JsonResponse
from .models import Book
def book_search(request):
if request.method == 'GET':
query = request.GET.get('query', '') # 获取查询参数
books = Book.objects.filter(title__icontains=query) # 模糊搜索书名
results = [
{'title': book.title, 'author': book.author, 'publication_date': book.publication_date.strftime('%Y-%m-%d')}
for book in books
]
return JsonResponse(results, safe=False) # 返回JSON响应
else:
return JsonResponse({'error': 'Invalid request method.'}, status=405)
4.3 Hadoop 数据处理代码
// Mapper.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将每行文本分割成单词
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
// Reducer.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
👇🏻👇🏻👇🏻文章下方名片联系我即可👇🏻👇🏻👇🏻
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
【获取源码】点击名片,微信扫码关注公众号
![[ComfyUI]Flux:写真新篇章!字节PuLID率先开启一致性风格迁移,无损画手和优质画面保持](https://img-blog.csdnimg.cn/5111b7615a994761bf8beebed63fab9b.png)



![[网络]TCP/IP五层协议之应用层,传输层(1)](https://i-blog.csdnimg.cn/direct/472770d51dc5412fb7e2767e50ec336e.png)