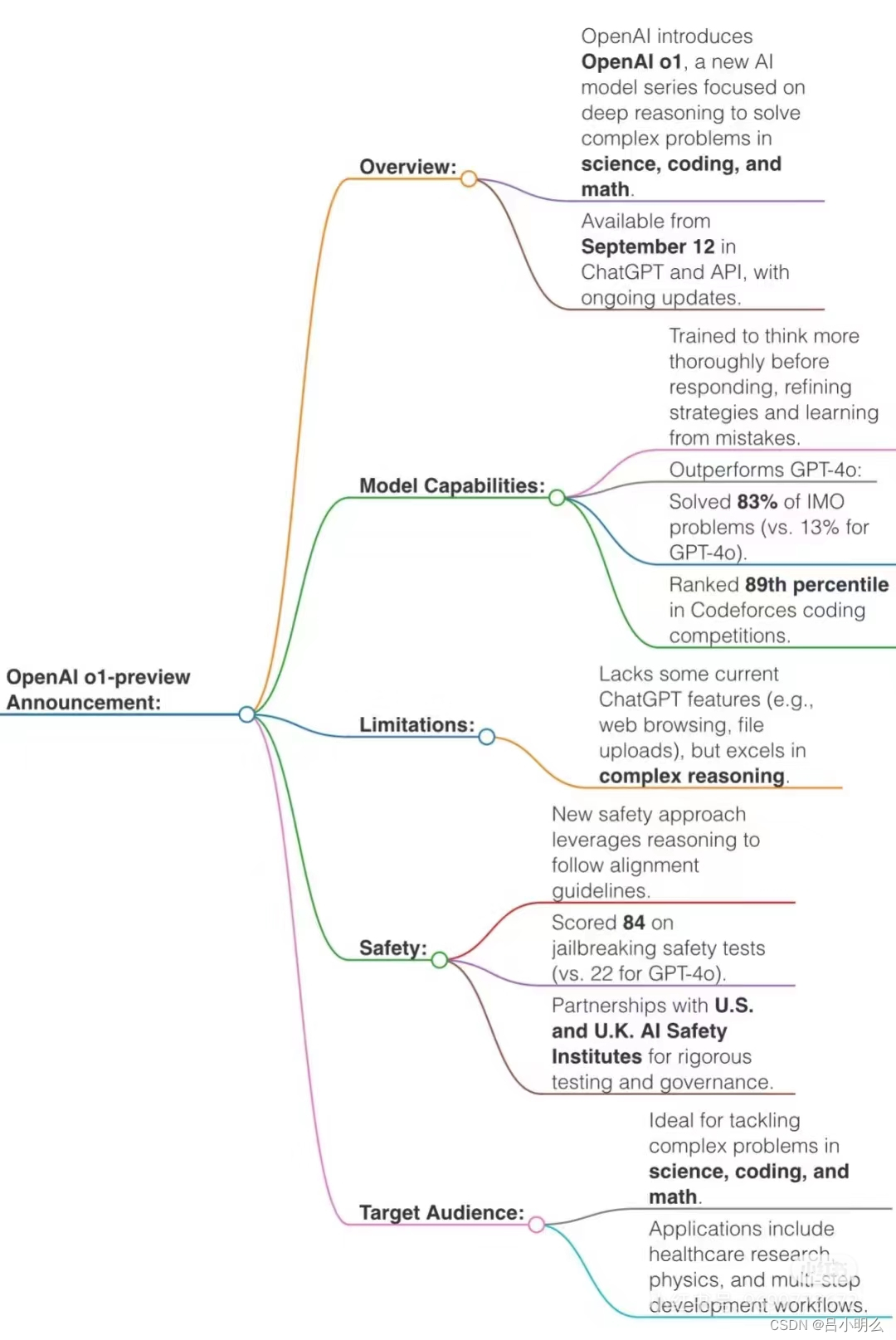
北京时间昨天凌晨,OpenAI正式发布了o1,这次来是来了,但...结合前一阵的思考和环境,说一下自己的感想吧:
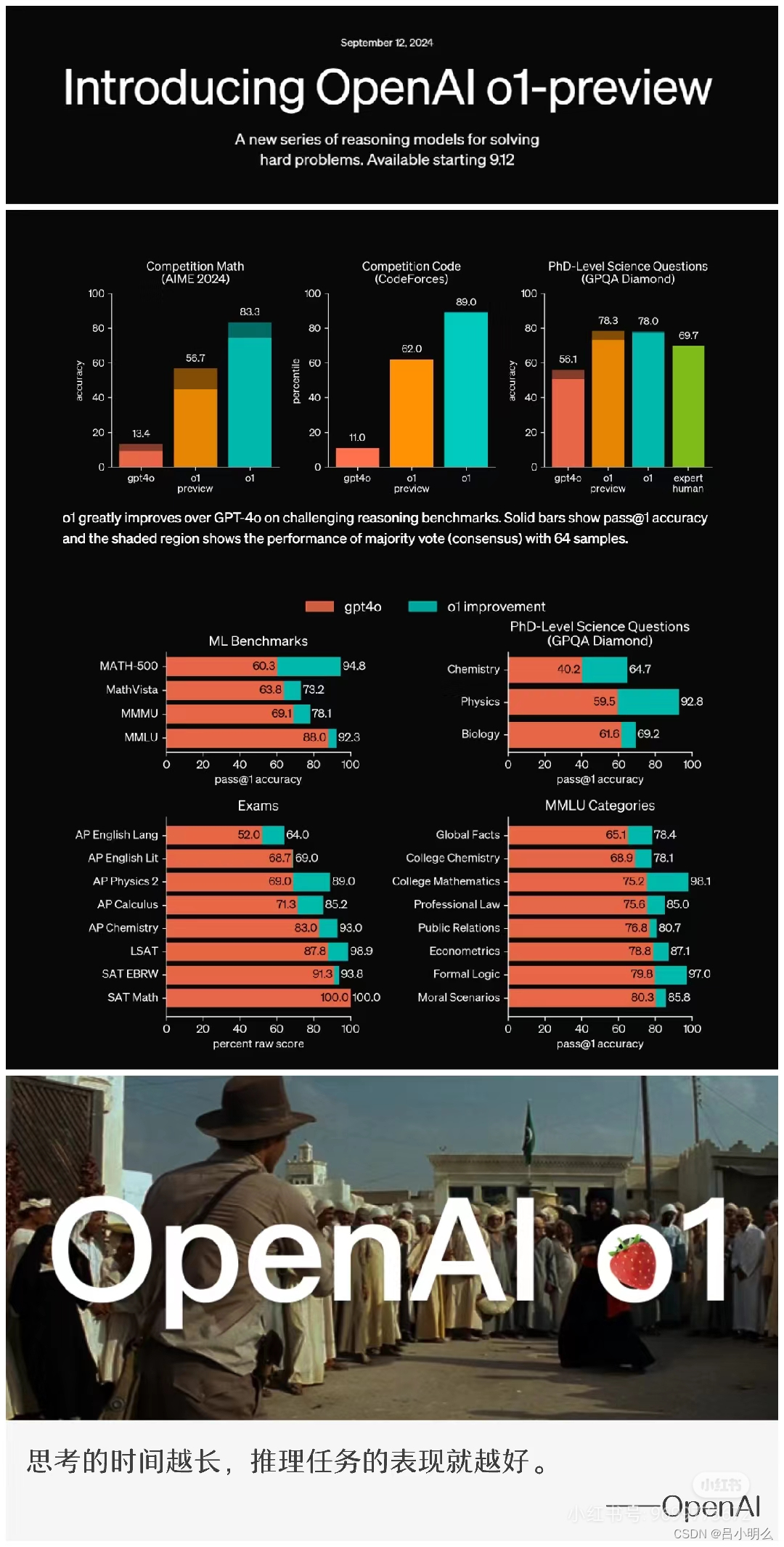
Ⅰ. 感觉OpenAI要有朝着Close一条道走到黑的趋势了..且看起来Close的很蹩脚(原因见下),在这种Close下,也许会为整个业界树立一个非常糟糕的榜样...
Ⅱ. 之所以说Close的很蹩脚,可以想象的这次o1背后的几条可能的技术路线,如:
学习范式下的RL+HF/AIF/self play F...
或者在模型架构上的LLM+RL创新...
或目标与任务设计上的AR与diffusion融合(这次应该没用)...
再到所运用的CoT、Agent、system2等思想在从训练(加入RL)与推理整个链条过程上的平衡与转化(如训练阶段采用RL的reflect与research,推理阶段的截断)…
这些技术在当前来看也不算新颖且已被业界所熟知,可能其中在模型训练过程中对于跨领域模式与跨token空间在泛化的表征、能力迁移及分布平衡的处理是核心关键,当然目前来看,OAI没有也不太可能有去公开这部分内容了...
回忆起自己在一年半前曾进行过RL与LLM间的深入思考,并于半年前完成了那篇长篇文章《融合RL与LLM思想,探寻世界模型以迈向AGI》,其中对RL与LLM融合下的Self play与数据合成等方面结合认知流形长链分布进行了观点阐释,感兴趣的大伙也可以关注联系我,或参考之前多篇笔记内容观点,也可访问置顶🔝笔记文章寻出处。
Ⅲ. 在这种Close之下,我想也会带来对技术未来的发展带来相当程度的局限或限制..包括对于数据、算法及相关背后理论与工程技术要素将变得更加不透明,未来各家的技术路线也相对独立割裂,担心这种情况会快速蔓延到其它技术领域,甚至对非技术等其它领域带来较深远的影响,如几十年前的..时代,大家懂的...
引用一句我手动点赞的AI界好朋友的评论观点,我觉得很有神深意:“不去思考 不去拆解 不理解原理,不搞清楚智能的本质,把一切交给所谓的智能,是对自己生命的一种放弃。”
回到o1的技术报告,我感觉这一段是核心:
…People have discovered a while ago that prompting the model to “think step by step” boosts performance. But training the model to do this, end to end with trial and error, is far more reliable and — as we’ve seem with games like Go or Dota — can generate extremely impressive results…
#人工智能 #AGI #LLM #openai #openaio1 #reasoning #强化学习 #selfplay