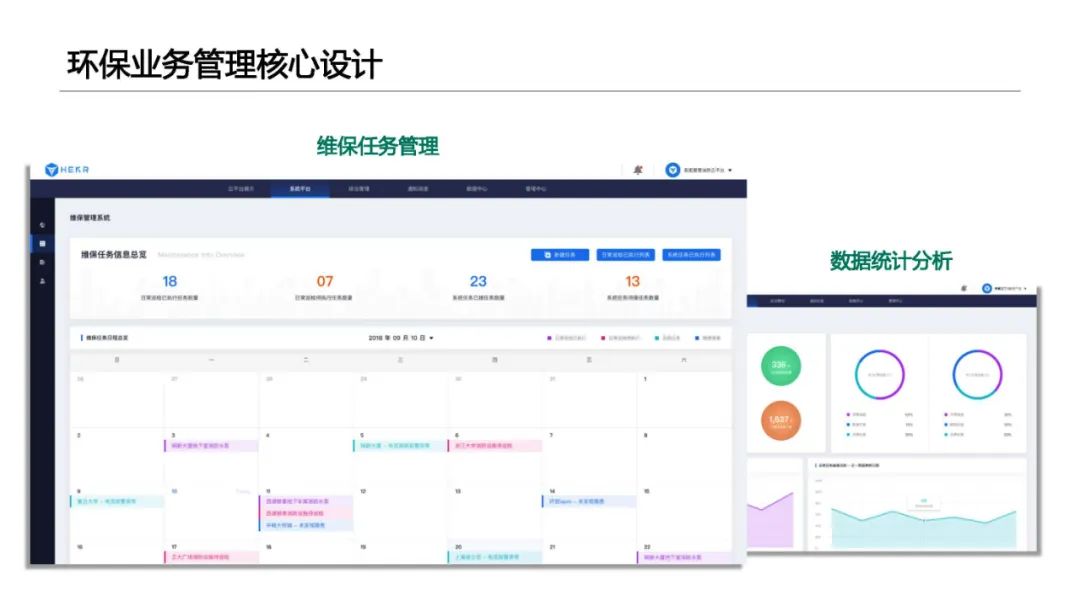
首先,我们使用 treelib 库来显示树结构 :
ps : 如果 treelib 输出一堆乱码, 可以点进Tree修改 tree.py 大概 930 行左右的部分(去掉encode就行了)
if stdout:
print(self._reader) # print(self._reader.encode("utf-8"))
else:
return self._reader
将字典转换为treelib 中可显示的 map的python 函数编写如下:
import copy
from treelib import Tree
def dict2map(dic):
if not isinstance(dic, dict):
raise TypeError("input should be dict")
map = {}
_dict2map_cb(dic if len(dic) <= 1 else {'root':dic}, map, parent = [])
return map
def _dict2map_cb(dic, map, parent=[]):
"""
Create map object in treelib by dict
:param dic: Python dict
:param map: Use {} as map
:param node_name: If None, use the first key of dic as root
but when multiple items in json, pass "root"
:param parent: Parent node array
:return:
"""
for key, val in dic.items():
node_name_new = '-'.join(parent)
root_name = '-'.join(parent + [key])
if isinstance(val, dict):
map[root_name] = node_name_new if parent!=[] else None # when root node,use None
_dict2map_cb(val, map, parent=parent + [key])
else:
map[root_name + " : " + str(val)] = node_name_new if parent!=[] else None
if __name__ == "__main__":
a = {"hello": {"word": 2}}
b = {'decision 0': {'target 1': 256, 'decision 3': {'target 0': 128, 'target 1': 256}, 'decision 2': {'target 0': 256, 'target 1': 128}}}
c = {'hi': {"w": 3}, 'this':{'e':4}}
Tree.from_map(dict2map(a)).show()
Tree.from_map(dict2map(b)).show(line_type="ascii-em")
Tree.from_map(dict2map(c)).show(line_type="ascii-em")
决策树的参考文章是 《机器学习苏娜发原理与编程实践》郑捷著, 具体是分类如下的问题 :
| 计数 | 年龄 | 收入 | 学生 | 信誉 | 是否购买 |
|---|---|---|---|---|---|
| 64 | 青 | 高 | 否 | 良 | 不买 |
| 64 | 青 | 高 | 否 | 优 | 不买 |
| 128 | 中 | 高 | 否 | 良 | 买 |
| 60 | 老 | 中 | 否 | 良 | 买 |
| 64 | 老 | 低 | 是 | 良 | 买 |
| 64 | 老 | 低 | 是 | 优 | 不买 |
| 64 | 中 | 低 | 是 | 优 | 买 |
| 128 | 青 | 中 | 否 | 良 | 不买 |
| 64 | 青 | 低 | 是 | 良 | 买 |
| 132 | 老 | 中 | 是 | 良 | 买 |
| 64 | 青 | 中 | 是 | 优 | 买 |
| 32 | 中 | 中 | 否 | 优 | 买 |
| 32 | 中 | 高 | 是 | 良 | 买 |
| 64 | 老 | 中 | 否 | 优 | 不买 |
显然容易构建出如下的决策树, 但这个决策树不是最优的

决策树的原理在这里不进行讲解, 将上面的表格保存为seals_data.xlsx, 并将转换的脚本保存为 dict_to_map.py, 即可直接运行下面的ID3决策树代码:
import numpy
import numpy as np
import copy
import pandas as pd
from sklearn.preprocessing import LabelEncoder # encoder labels
from treelib import Tree, Node
from sklearn.datasets._base import Bunch
from dict_to_map import dict2map
class ID3_Tree():
""" ID3 decision Tree Algorithm """
def __init__(self, counts = None, data = None, target = None, label_encoder = None):
if (counts == None or data == None or target == None):
self.load_data()
else:
self.train_data = Bunch(counts = counts, data = data, target = target)
self.label_encoder = label_encoder()
self.__Init_Tree(self.train_data.counts, self.train_data.data, self.train_data.target)
self.build_Tree()
def to_dict(self, *args, **kwargs):
return self.tree
def load_data (self):
""" arrange the data into the correct shapes """
data_raw = pd.DataFrame(pd.read_excel("seals_data.xlsx"))
label_encoder = LabelEncoder()
# eliminate all the white space
data_raw = data_raw.map(func=lambda x:x.strip() if isinstance(x, str) else x)
data_proceed = pd.DataFrame()
data_proceed['计数'] = data_raw.iloc[:, 0]
for column in data_raw.columns[1:]:
data_proceed[str(column).strip()] = label_encoder.fit_transform(data_raw[column])
""" split data into 3 part : counts, data and target """
counts = np.array(copy.deepcopy(data_proceed.iloc[:,0]))
data = np.array(copy.deepcopy(data_proceed.iloc[:,1:-1]))
target = np.array(copy.deepcopy(data_proceed.iloc[:,-1]))
labels = [str(column).strip() for column in data_raw.columns]
self.data_raw = data_raw
self.train_data = Bunch(counts = counts, data = data, target = target ,labels = labels) # target = data_raw.iloc[:, 0])
self.label_encoder = label_encoder
def __Init_Tree(self, counts:np.ndarray, data:np.ndarray, target:np.ndarray):
self.__check_param(counts, data, target)
self.nums = counts.shape[0] # number of the type of the samples
self.target_num = len(np.unique(target)) # the number of classes (C_i) , i = 1... m
self.decision_num = data.shape[1] # number of decision attributes (D)
self.total_num = counts.sum() # total number of samples (N)
self.tree = {} # init the tree node
# calculate the infomation entropy of the entire dataset
targets = np.unique(target)
cls_cnt = np.array([counts[target == targets[i]].sum() for i in range(targets.size)])
cls_prop= cls_cnt/cls_cnt.sum()
self.base_entropy = -np.sum(cls_prop * np.log2(np.where(cls_prop == 0,1e-10, cls_prop)))
def build_Tree(self):
if (self.target_num <= 1):
# only 1 class, stop split and return the empty tree
self.tree["root"] = self.train_data.target[0]
return self.tree
# initialize the node decision range and target range, we use whole data set to calculate the entropy of root at first
dec_range = np.arange(self.decision_num) # decision attributes
tar_range = np.arange(self.nums) # targets on data
# recursive call the calc_entropy_mat function until the class is purely classified.
self.tree = self.__build_tree_node(dec_range, tar_range)
def __check_param(self, counts, data, target):
if len(counts.shape)!=1 or len(data.shape)!=2 or len(target.shape)!=1:
raise ValueError("The input data is not in the correct shape")
elif counts.shape[0]!= data.shape[0] or counts.shape[0] != target.shape[0]:
raise ValueError("The input data is not in the correct shape")
def show(self):
map = dict2map(self.tree)
tree = Tree.from_map(map)
tree.show(line_type="ascii-em", sorting=False)
def __build_tree_node(self, dec_range, tar_range) -> dict:
"""
recursive function,
counts, data, target, node_dec_range, node_tar_range
:param dec_range : decision range (in direction 1 or y)
:param tar_range : target range (in direction 0 or x)
:return: root (name of the root node is defined by decision)
"""
counts = self.train_data.counts[tar_range]
data = self.train_data.data[tar_range][:, dec_range]
target = self.train_data.target[tar_range]
self.__check_param(counts, data, target)
gain_list = [self.__get_node_info_gain(counts, data[:, i], target) for i in range(dec_range.size)]
best_dec_idx = np.argmax(gain_list) # best decision (note : relevant to dec_range, not self.train_data)
best_decision = data[:, best_dec_idx]
features = np.unique(best_decision)
cnt_mat = self.__get_count_matrix(counts, best_decision, target)
# use best decision as root node -> delete it from dec_range
root_name = "decision" + str(dec_range[best_dec_idx]) # get the location of best decision
root = {}
d2 = numpy.delete(dec_range, best_dec_idx) # create new dec_range object
for i in range(len(features)):
feature = features[i]
cnt_arr = np.array(cnt_mat[:, i]).squeeze(1) # change to array and squeeeze to 1 dim
# record the classification result:
left_tar_idx = np.nonzero(cnt_arr)[0] # choice leave in this feature
if (len(left_tar_idx) == 0):
raise ValueError("left choices is not zero here!")
if left_tar_idx.size == 1:
# left number can be calculated by cnt_arr[left_choices], t2 = []
root["target" + str(left_tar_idx[0]) ] = np.sum(cnt_arr[left_tar_idx])
elif d2.size == 0 : # no available decision left
root["dummy"] = np.sum(cnt_arr[left_tar_idx]) # create dummy node
else:
t2 = tar_range[best_decision == feature]
sub_tree = self.__build_tree_node(d2, t2);
sub_rootname, sub_root = next(iter(sub_tree.items()))
root[sub_rootname] = sub_root
return {root_name : root}
def __get_node_info_gain(self,counts_arr, decision_arr, target_arr):
"""
:param counts_arr: the counts array of the current node
:param decision_arr: the decision attributes of the current node
:param target_arr: target array to be classified of the current node
:return: gain : scalar, infomation gain of the current node
"""
cnt_mat = self.__get_count_matrix(counts_arr, decision_arr, target_arr)
# calculate the information gain of the current node by cnt_mat
prob_mat = np.mat(cnt_mat / np.sum(cnt_mat, axis=0)) # calculate probability matrix
prob_mat = np.where(prob_mat == 0, 1e-10, prob_mat) # substitute 0 with 1e-10 to avoid log calculation error
node_entropy = -np.sum(np.multiply(prob_mat, np.log2(prob_mat)), axis=0)
node_wt = cnt_mat.sum(axis=0) / np.sum(cnt_mat)
gain = self.base_entropy - np.multiply(node_wt, node_entropy).sum()
return gain
def __get_count_matrix(self, counts_arr, decision_arr, target_arr):
"""
calculate the count matrix of the node
:param counts_arr: the counts array of the current node
:param decision_arr: the decision attributes of the current node
:param target_arr: target array to be classified of the current node
:return: cnt_mat : np.matrix
"""
features = np.unique(decision_arr)
targets = np.unique(target_arr)
cnt_mat = np.array([
[np.sum(counts_arr[(decision_arr == dec) & (target_arr == tar)]) for dec in features]
for tar in targets
])
return np.matrix(cnt_mat)
if __name__ == "__main__":
tree = ID3_Tree()
print(tree.to_dict())
tree.show()
需要说明的是, 上述的代码没有按参考原文的代码, 算法的主要思路是一致的, 代码中将不同的选择称为 decision , 而每个选择的不同分支 称为 feature, 便于编程, 最终通过概率矩阵 prep_mat 计算出对应的节点熵。选取最适合用于分类的节点。

上面程序的运行结果如下 :
{'decision0': {'target1': 256, 'decision3': {'target0': 128, 'target1': 256}, 'decision2': {'target0': 256, 'target1': 128}}}
decision0
╠══ decision0-target1 : 256
╠══ decision0-decision3
║ ╠══ decision0-decision3-target0 : 128
║ ╚══ decision0-decision3-target1 : 256
╚══ decision0-decision2
╠══ decision0-decision2-target0 : 256
╚══ decision0-decision2-target1 : 128
上述树按照 feature 的先后顺序划分 (例如decision0(年龄)-feature0(中年)) 对应的是 decision0下的第一条, 以此类推。同时为了防止treelib自动排序,需要设置参数 tree.show(line_type="ascii-em", sorting=False)
需要说明的是, decision0-decision3 分别对应的是年龄 , 收入, 学生, 信誉, 具体可以拿这个具体去看:
printf(self.data_raw)
printf(self.train_data.counts)
printf(self.train_data.data)
printf(self.train_data.target)
即最终成功建立了如下的决策树:

另外, 利用 可以方便地采用 c4.5 算法很方便地建立这个决策树:
库下载: pip install c45-decision-tree
建立该树只需采用如下代码 :
from C45 import C45Classifier
import pandas as pd
import graphviz
data_raw = pd.DataFrame(pd.read_excel("seals_data.xlsx"))
data_raw = data_raw.map(func=lambda x:x.strip() if isinstance(x, str) else x)
counts = data_raw.iloc[:,0]
data = data_raw.iloc[:,1:-1]
target = data_raw.iloc[:,-1]
data_new = []
target_new = []
for i in range(counts.size):
for j in range(counts[i]):
data_new.append(list(data.iloc[i]))
target_new.append(target.iloc[i])
model = C45Classifier()
model.fit(data_new, target_new)
tree_diagram = model.generate_tree_diagram(graphviz, "tree_diagram")
graphviz.view(tree_diagram)
另外, 如果出现中文显示乱码问题, 可以跳转到 generate_tree_diagram 源码中, 添加 dot.attr(encoding='utf-8') # Ensure UTF-8 encoding 部分和 fontname="SimHei" 三个部分 :
def generate_tree_diagram(self, graphviz, filename):
# Menghasilkan diagram pohon keputusan menggunakan modul graphviz
dot = graphviz.Digraph()
def build_tree(node, parent_node=None, edge_label=None):
if isinstance(node, _DecisionNode):
current_node_label = str(node.attribute)
dot.node(str(id(node)), label=current_node_label)
if parent_node:
dot.edge(str(id(parent_node)), str(id(node)), label=edge_label, fontname="SimHei")
for value, child_node in node.children.items():
build_tree(child_node, node, value)
elif isinstance(node, _LeafNode):
current_node_label = f"Class: {node.label}, Weight: {node.weight}"
dot.node(str(id(node)), label=current_node_label, shape="box", fontname="SimHei")
if parent_node:
dot.edge(str(id(parent_node)), str(id(node)), label=edge_label, fontname="SimHei")
build_tree(self.tree)
dot.format = 'png'
dot.attr(encoding='utf-8') # Ensure UTF-8 encoding
return dot.render(filename, view=False)
绘制出的决策树如图所示:

附注 : 由于本人水平所限,上面的代码部分也可能有一些错误, 如果读者发现也希望能在评论区指正。










![洛谷 P4683 [IOI2008] Type Printer](https://i-blog.csdnimg.cn/direct/3724f16f6e9143cfa398492550b0d0c0.png)






