Prometheus 是一个强大的开源监控系统,它被广泛应用于云原生环境中,特别是在 Kubernetes 和其他容器化基础设施中。然而,随着监控数据量的增长,系统本身的性能可能会成为瓶颈。如果不进行优化,最终将影响到整体系统的可用性。
本文将从多个维度介绍如何优化 Prometheus 以提升系统性能。
一. 优化数据存储
Prometheus 使用一个本地的时序数据库(TSDB)来存储所有的监控数据。优化数据存储可以帮助减少存储的开销并提高查询效率。
1. 配置数据保留策略
Prometheus 默认会保留15天的监控数据,但并不是所有环境都需要如此长的保留时间。根据监控需求,可以适当缩短数据保留时间。
--storage.tsdb.retention.time=7d
通过将数据保留时间从15天缩短到7天,可以显著减少存储的占用。对于长期数据存储,可以考虑将数据转储到远程存储系统,如 Thanos 或 Cortex,它们能够提供更高效的数据存储和压缩机制。
2. 调整块大小
Prometheus 的时序数据库通过块(blocks)来存储数据,默认每个块持续2小时的数据。可以根据具体环境调整块的大小,以平衡查询性能和存储效率。
--storage.tsdb.min-block-duration=2h
如果块的持续时间过短,Prometheus 会频繁地创建新块,增加 CPU 和 I/O 负载。相反,如果持续时间过长,查询可能变得缓慢。通常保持默认的2小时是比较合理的选择,但可以根据具体的查询和存储需求进行调整。
二. 降低采集频率
在监控环境中,并不是所有的指标都需要高频率的采集。通过合理地调整采集频率,能够减少系统负载并降低存储开销。
1. 调整抓取间隔
抓取间隔是指 Prometheus 拉取数据的频率。默认情况下,Prometheus 每 15 秒抓取一次指标。对于不需要频繁监控的指标,可以适当增加抓取间隔。
scrape_interval: 30s
适当延长 scrape_interval 可以降低对 Prometheus 服务和被监控服务的压力。
2. 配置 job-specific 抓取策略
并非所有的服务都需要相同的抓取频率。可以为不同的 job 配置不同的抓取间隔。
scrape_configs:
- job_name: 'service_A'
scrape_interval: 10s
- job_name: 'service_B'
scrape_interval: 1m
为重要服务设置较短的抓取间隔(例如10秒),而对于较少变动的服务,可以设置较长的抓取间隔(如1分钟)。
三. 精简标签和指标
Prometheus 中的标签和指标数量对性能影响很大。过多的标签和高维度的数据可能导致指标爆炸,进而影响系统性能。
1. 控制标签数量
在配置监控时,尽量减少标签的数量。过多的标签会导致 Prometheus 需要存储更多的时序数据,增加存储和查询的负担。
2. 避免高基数标签
高基数标签(例如 user_id 或 session_id)会显著增加指标的基数。尽量避免将这些高基数的标签加入监控数据中。
例如,不要将用户ID这样的动态值直接作为标签:
request_count{user_id="12345"} # 避免此类标签
可以使用其他方式统计用户行为,而不是直接通过标签记录每个用户的ID。
四. 优化查询性能
Prometheus 支持强大的查询语言 PromQL,用于检索和聚合时序数据。然而,复杂的查询可能会消耗大量的资源,导致 Prometheus 响应变慢。
1. 使用时间范围限制查询
Prometheus 的查询语言支持设置时间范围。为了提高查询性能,尽量避免查询无边界的时间段。明确指定查询时间范围可以减少Prometheus需要扫描的数据量。
rate(http_requests_total[5m]) # 使用指定时间范围的查询
尽量避免使用像 rate(http_requests_total) 这样的无时间范围的查询,这会导致 Prometheus 必须扫描所有数据。
2. 避免重复的子查询
PromQL 支持子查询功能,但过多或复杂的子查询可能显著影响性能。尽量简化查询逻辑,避免嵌套太深的子查询。
sum(rate(http_requests_total[1m])) by (job)
尽量使用简单的聚合函数,而不是多层的查询嵌套。
3. 使用远程查询
对于一些历史数据的查询,可以考虑使用远程存储后端,如 Thanos 或 Cortex。这些系统支持分布式查询和存储,并且能够处理大规模的查询请求,而不会过载 Prometheus 实例。
五. 分片和高可用
在大规模集群中,单个 Prometheus 实例可能无法应对所有监控需求。此时可以考虑使用分片和高可用机制来提升性能。
1. Prometheus 分片
可以通过分片的方式,将不同的监控目标分配给不同的 Prometheus 实例。这样可以有效地分担监控负载,减少单个 Prometheus 实例的压力。
sum(rate(http_requests_total[1m])) by (job)scrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- /etc/prometheus/node/*.yml
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keepscrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- /etc/prometheus/node/*.yml
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
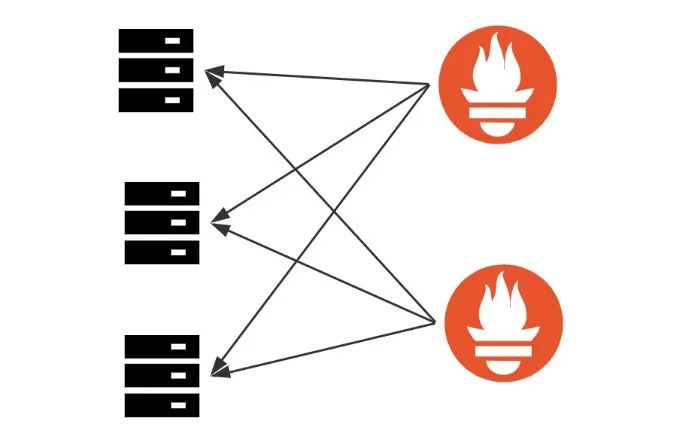
2. 高可用 Prometheus
高可用模式下,可以运行多个 Prometheus 实例同时采集相同的数据,并通过负载均衡来分担查询压力。这不仅提升了系统的健壮性,还能分担查询负载。
六. 优化告警规则
告警模块是 Prometheus 中的关键组件,但大量复杂的告警规则也会对性能造成影响。
1. 减少告警规则的复杂性
避免过于复杂的告警表达式和不必要的告警。复杂的告警规则会导致 Prometheus 在每次评估时都要进行大量计算,影响性能。
2. 使用外部告警系统
对于大规模集群,可以考虑将告警部分外包给外部告警系统,如 Cortex、Thanos 或 Alertmanager。这样可以减少 Prometheus 自身的告警负担。