用一条SQL实现GPT大模型,简直让人不可思议,但是俄罗斯一位名叫Quassnoi的SQL牛人做到了,Quassnoi每年只写一条SQL,但是每条SQL都非常复杂:
-
2021年,用SQL绘制新冠病毒的3D图片
-
2022年,用SQL模拟量子计算
-
2023年,用SQL解决魔方问题
-
2024年,用SQL模拟GPT大模型算法
2023年我组织了一次数据库编程大赛:一条SQL计算扑克牌24点,
对于数据库开发者来讲已经很有挑战,但是在Quassnoi写的SQL面前,是小巫见大巫了。
直接上SQL实现GPT的源码
这条SQL共500行,使用了PostgreSQL大量的语法特性,模拟了GPT2的逻辑
看不懂是正常的,后面有1万字原理解读,最后还有视频介绍
SELECT SETSEED(0.20231231);WITH RECURSIVEinput AS(SELECT 'Happy New Year! I wish you' AS prompt,10 AS threshold,2 AS temperature,1 AS top_n),clusters AS(SELECT part_position, bpe.*FROM inputCROSS JOIN LATERALREGEXP_MATCHES(prompt, '''s|''t|''re|''ve|''m|''ll|''d| ?\w+| ?\d+| ?[^\s\w\d]+|\s+(?!\S)|\s+', 'g') WITH ORDINALITY AS rm (part, part_position)CROSS JOIN LATERAL(WITH RECURSIVEbpe AS(SELECT (n + 1)::BIGINT AS position, character, TRUE AS continueFROM CONVERT_TO(part[1], 'UTF-8') AS bytesCROSS JOIN LATERALGENERATE_SERIES(0, LENGTH(bytes) - 1) AS nJOIN encoderON byte = GET_BYTE(bytes, n)UNION ALL(WITH RECURSIVEbase AS(SELECT *FROM bpeWHERE continue),bn AS(SELECT ROW_NUMBER() OVER (ORDER BY position) AS position,continue,character,character || LEAD(character) OVER (ORDER BY position) AS clusterFROM base),top_rank AS(SELECT tokenizer.*FROM bnCROSS JOIN LATERAL(SELECT *FROM tokenizerWHERE tokenizer.cluster = bn.clusterLIMIT 1) tokenizerORDER BYtokenLIMIT 1),breaks AS(SELECT 0::BIGINT AS position, 1 AS lengthUNION ALLSELECT bn.position,CASE WHEN token IS NULL THEN 1 ELSE 2 ENDFROM breaksJOIN bnON bn.position = breaks.position + lengthLEFT JOINtop_rankUSING (cluster))SELECT position, character, token IS NOT NULLFROM breaksLEFT JOINtop_rankON 1 = 1CROSS JOIN LATERAL(SELECT STRING_AGG(character, '' ORDER BY position) AS characterFROM bnWHERE bn.position >= breaks.positionAND bn.position < breaks.position + length) bnWHERE position > 0))SELECT position, character AS clusterFROM bpeWHERE NOT continue) bpe),tokens AS(SELECT ARRAY_AGG(token ORDER BY part_position, position) AS inputFROM clustersJOIN tokenizerUSING (cluster)),gpt AS(SELECT input, ARRAY_LENGTH(input, 1) AS original_lengthFROM tokensUNION ALLSELECT input || next_token.token, original_lengthFROM gptCROSS JOINinputCROSS JOIN LATERAL(WITH RECURSIVEhparams AS(SELECT ARRAY_LENGTH(input, 1) AS n_seq,12 AS n_block),embeddings AS(SELECT place, valuesFROM hparamsCROSS JOIN LATERALUNNEST(input) WITH ORDINALITY AS tokens (token, ordinality)CROSS JOIN LATERAL(SELECT ordinality - 1 AS place) oCROSS JOIN LATERAL(SELECT wte.values + wpe.values AS valuesFROM wteCROSS JOINwpeWHERE wte.token = tokens.tokenAND wpe.place = o.place) embedding),transform AS(SELECT 0 AS block, place, valuesFROM embeddingsUNION ALL(WITH previous AS(SELECT *FROM transform)SELECT block + 1 AS block, transformed_layer.*FROM hparamsCROSS JOIN LATERAL(SELECT blockFROM previousWHERE block < 12LIMIT 1) qCROSS JOIN LATERAL(WITH ln_2_b AS(SELECT *FROM ln_2_bWHERE block = q.block),ln_2_g AS(SELECT *FROM ln_2_gWHERE block = q.block),c_proj_w AS(SELECT *FROM c_proj_wWHERE block = q.block),c_proj_b AS(SELECT *FROM c_proj_bWHERE block = q.block),mlp_c_fc_w AS(SELECT *FROM mlp_c_fc_wWHERE block = q.block),mlp_c_fc_b AS(SELECT *FROM mlp_c_fc_bWHERE block = q.block),mlp_c_proj_w AS(SELECT *FROM mlp_c_proj_wWHERE block = q.block),mlp_c_proj_b AS(SELECT *FROM mlp_c_proj_bWHERE block = q.block),c_attn_w AS(SELECT *FROM c_attn_wWHERE block = q.block),c_attn_b AS(SELECT *FROM c_attn_bWHERE block = q.block),ln_1_g AS(SELECT *FROM ln_1_gWHERE block = q.block),ln_1_b AS(SELECT *FROM ln_1_bWHERE block = q.block),mha_norm AS(SELECT place, mm.values + c_attn_b.values AS valuesFROM (SELECT place, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS valuesFROM (SELECT place, agg.values * ln_1_g.values + ln_1_b.values AS valuesFROM (SELECT place, norm.valuesFROM previousCROSS JOIN LATERAL(SELECT AVG(value) AS mean,VAR_POP(value) AS varianceFROM UNNEST(values::REAL[]) value) aggCROSS JOIN LATERAL(SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS valuesFROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)) norm) aggCROSS JOINln_1_bCROSS JOINln_1_g) layer_normCROSS JOINc_attn_wGROUP BYplace) mmCROSS JOINc_attn_b),heads AS(SELECT place, head,(values::REAL[])[(head * 64 + 1):(head * 64 + 64)]::VECTOR(64) AS q,(values::REAL[])[(head * 64 + 1 + 768):(head * 64 + 64 + 768)]::VECTOR(64) AS k,(values::REAL[])[(head * 64 + 1 + 1536):(head * 64 + 64 + 1536)]::VECTOR(64) AS vFROM mha_normCROSS JOINGENERATE_SERIES(0, 11) head),sm_input AS(SELECT head, h1.place AS x, h2.place AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.place > h1.place THEN -1E10 ELSE 0 END AS valueFROM heads h1JOIN heads h2USING (head)),sm_diff AS(SELECT head, x, y, value - MAX(value) OVER (PARTITION BY head, x) AS diffFROM sm_input),sm_exp AS(SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS eFROM sm_diff),softmax AS(SELECT head, x, y AS place, e / SUM(e) OVER (PARTITION BY head, x) AS valueFROM sm_exp),attention AS(SELECT place, ARRAY_AGG(value ORDER BY head * 64 + ordinality)::VECTOR(768) AS valuesFROM (SELECT head, x AS place, SUM(ARRAY_FILL(softmax.value, ARRAY[64])::VECTOR(64) * heads.v) AS valuesFROM softmaxJOIN headsUSING (head, place)GROUP BYhead, x) qCROSS JOIN LATERALUNNEST(values::REAL[]) WITH ORDINALITY v (value, ordinality)GROUP BYplace),mha AS(SELECT place, w.values + c_proj_b.values + previous.values AS valuesFROM (SELECT attention.place, ARRAY_AGG(INNER_PRODUCT(attention.values, c_proj_w.values) ORDER BY c_proj_w.place)::VECTOR(768) AS valuesFROM attentionCROSS JOINc_proj_wGROUP BYattention.place) wCROSS JOINc_proj_bJOIN previousUSING (place)),ffn_norm AS(SELECT place, agg.values * ln_2_g.values + ln_2_b.values AS valuesFROM (SELECT place, norm.valuesFROM mhaCROSS JOIN LATERAL(SELECT AVG(value) AS mean,VAR_POP(value) AS varianceFROM UNNEST(values::REAL[]) value) aggCROSS JOIN LATERAL(SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS valuesFROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)) norm) aggCROSS JOINln_2_bCROSS JOINln_2_g),ffn_a AS(SELECT gelu.place, gelu.valuesFROM (SELECT place, w.values + mlp_c_fc_b.values AS valuesFROM (SELECT ffn_norm.place, ARRAY_AGG(INNER_PRODUCT(ffn_norm.values, mlp_c_fc_w.values) ORDER BY mlp_c_fc_w.place)::VECTOR(3072) AS valuesFROM ffn_normCROSS JOINmlp_c_fc_wGROUP BYffn_norm.place) wCROSS JOINmlp_c_fc_b) vCROSS JOIN LATERAL(SELECT place, ARRAY_AGG(0.5 * value * (1 + TANH(0.797884560802 * (value + 0.044715 * value*value*value))) ORDER BY ordinality)::VECTOR(3072) AS valuesFROM UNNEST(values::REAL[]) WITH ORDINALITY n (value, ordinality)GROUP BYplace) gelu),ffn AS(SELECT place, w.values + mlp_c_proj_b.values + mha.values AS valuesFROM (SELECT ffn_a.place, ARRAY_AGG(INNER_PRODUCT(ffn_a.values, mlp_c_proj_w.values) ORDER BY mlp_c_proj_w.place)::VECTOR(768) AS valuesFROM ffn_aCROSS JOINmlp_c_proj_wGROUP BYffn_a.place) wCROSS JOINmlp_c_proj_bJOIN mhaUSING (place))SELECT *FROM ffn) transformed_layer)),block_output AS(SELECT *FROM hparamsJOIN transformON transform.block = n_block),ln_f AS(SELECT place, norm.values * ln_f_g.values + ln_f_b.values AS valuesFROM block_outputCROSS JOIN LATERAL(SELECT AVG(value) AS mean,VAR_POP(value) AS varianceFROM UNNEST(values::REAL[]) AS n(value)) aggCROSS JOIN LATERAL(SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS valuesFROM UNNEST(values::REAL[]) WITH ORDINALITY AS n (value, ordinality)) normCROSS JOINln_f_bCROSS JOINln_f_g),logits AS(SELECT token, INNER_PRODUCT(ln_f.values, wte.values) AS valueFROM hparamsJOIN ln_fON ln_f.place = n_seq - 1CROSS JOINwteORDER BYvalue DESCLIMIT (top_n)),tokens AS(SELECT token,high - softmax AS low,highFROM (SELECT *,SUM(softmax) OVER (ORDER BY softmax) AS highFROM (SELECT *, (e / SUM(e) OVER ()) AS softmaxFROM (SELECT *,(value - MAX(value) OVER ()) / temperature AS diffFROM logits) exp_xCROSS JOIN LATERAL(SELECT CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e) exp) q) q),next_token AS(SELECT *FROM (SELECT RANDOM() AS rnd) rCROSS JOIN LATERAL(SELECT *FROM tokensWHERE rnd >= lowAND rnd < high) nt)SELECT *FROM next_token) next_tokenWHERE ARRAY_LENGTH(input, 1) < original_length + thresholdAND next_token.token <> 50256),output AS(SELECT CONVERT_FROM(STRING_AGG(SET_BYTE('\x00', 0, byte), '' ORDER BY position), 'UTF8') AS responseFROM (SELECT STRING_AGG(cluster, '' ORDER BY ordinality) AS responseFROM inputJOIN gptON ARRAY_LENGTH(input, 1) = original_length + thresholdCROSS JOIN LATERALUNNEST(input) WITH ORDINALITY n (token, ordinality)JOIN tokenizerUSING (token)) qCROSS JOIN LATERALSTRING_TO_TABLE(response, NULL) WITH ORDINALITY n (character, position)JOIN encoderUSING (character))SELECT *FROM output
看源码非常难理解,作者还写了一篇文章做详细的介绍,以下文章来自原文翻译与整理,
这部分也非常复杂,文章最后还有视频介绍
原文地址:
https://explainextended.com/2023/12/31/happy-new-year-15/
-----------------------
基础理论
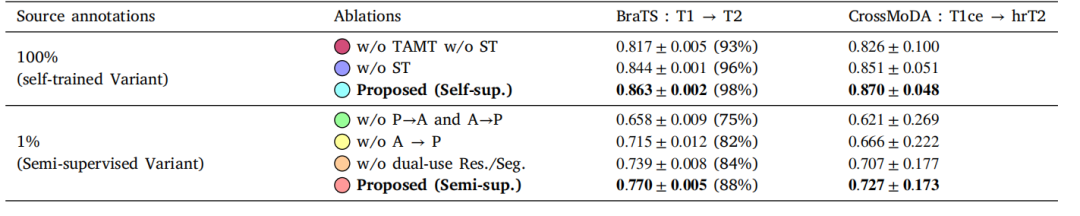
在写这篇文章时,我使用了 Jay Mody 的精彩文章 GPT in 60 Lines of NumPy。本文对 GPT 模型的内部工作原理的解释比我所希望的要好得多。不过,我们还是需要稍微回顾一下。
从技术角度来看,什么是生成式大型语言模型?
生成式 LLM 是一个函数。它采用文本字符串作为输入(在 AI 术语中称为“prompt”),并返回字符串和数字数组。此函数的签名如下所示:
llm(prompt: str) -> list[tuple[str, float]]
此函数是确定性的。它在后台做了很多数学运算,但所有这些数学运算都是硬性的。如果你使用相同的 input 重复调用它,它将始终返回相同的输出。
任何一直在使用 ChatGPT 和类似产品的人都可能会感到惊讶,因为它们可以对同一个问题给出不同的答案。然而,这是真的。我们很快就会看到它是如何工作的。
此函数返回哪些值?
像这样:
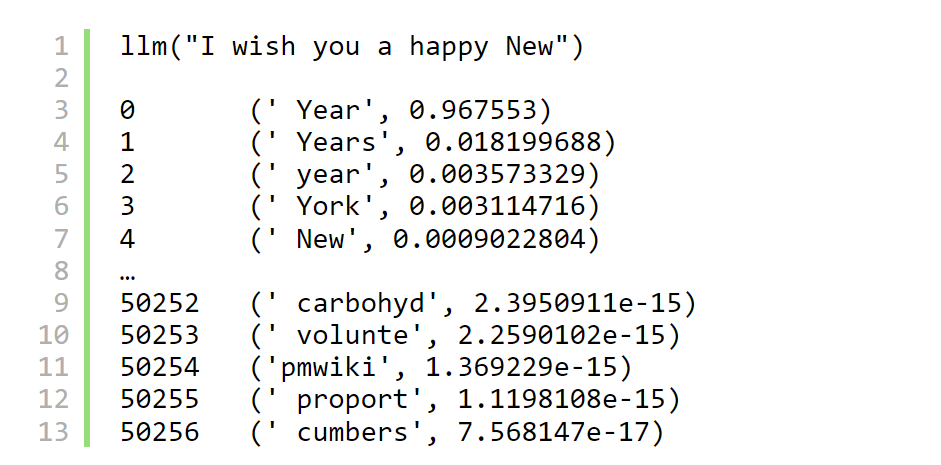
它返回一个元组数组。每个 Tuples 由一个单词(或者更确切地说,一个字符串)和一个数字组成。该数字是此单词继续提示的概率。模型“思考”短语“I wish you a happy New”后面会跟着字符序列“Year”,概率为 96.7%,“Years”概率为 1.8%,依此类推。
上面引用了“思考”这个词,因为当然,这个模型并没有真正思考。它根据一些硬连线的内部逻辑机械地返回单词和数字数组。
如果它是那么愚蠢和确定性,它怎么能生成不同的文本呢?
大型语言模型用于文本应用程序(聊天机器人、内容生成器、代码助手等)。这些应用程序反复调用模型并选择它建议的单词(具有一定程度的随机性)。下一个建议的单词将添加到提示符中,并再次调用模型。这将在循环中继续,直到生成足够的单词。
累积的单词序列将看起来像人类语言的文本,包括语法、句法,甚至似乎是智力和推理。在这方面,它与马尔可夫链的工作原理相同。
大型语言模型的内部结构是相互关联的,因此下一个建议的单词将是提示的自然延续,包括其语法、语义和情感。通过一系列科学突破(码农辛勤付出)为函数配备这种逻辑成为可能,这导致了被称为 GPT 或生成式预训练转换器的算法系列的发展。
“Generative Pre-trained Transformer”是什么意思?
“Generative” 意味着它生成文本(通过递归地向提示添加 continuations,正如我们之前看到的)。
“Transformer” 是指它使用一种特定类型的神经网络,该网络最初由 Google 开发,并在本文中进行了描述。
“预训练”有历史演进。最初,模型文本接词的能力被认为是更专业任务的先决条件:推理(查找短语之间的逻辑联系)、分类(例如,从评论文本中猜测酒店评级中的星级数量)、机器翻译等。人们认为这两个部分应该分开训练,语言部分只是为接下来的“真实”任务进行预训练。
正如最初的 GPT 论文所说:
我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行判别性微调,可以实现这些任务的巨大收益。
直到后来,人们才意识到,如果模型足够大,第二步往往是不必要的。Transformer 模型经过训练,除了生成文本之外什么都不做,事实证明它能够遵循这些文本中包含的人类语言指令,而无需额外的训练(用 AI 的话说是“微调”)。
好了,说完这些,让我们专注于实现。
生成(Genaration)
以下是我们尝试使用 GPT2 从提示符生成文本时发生的情况:
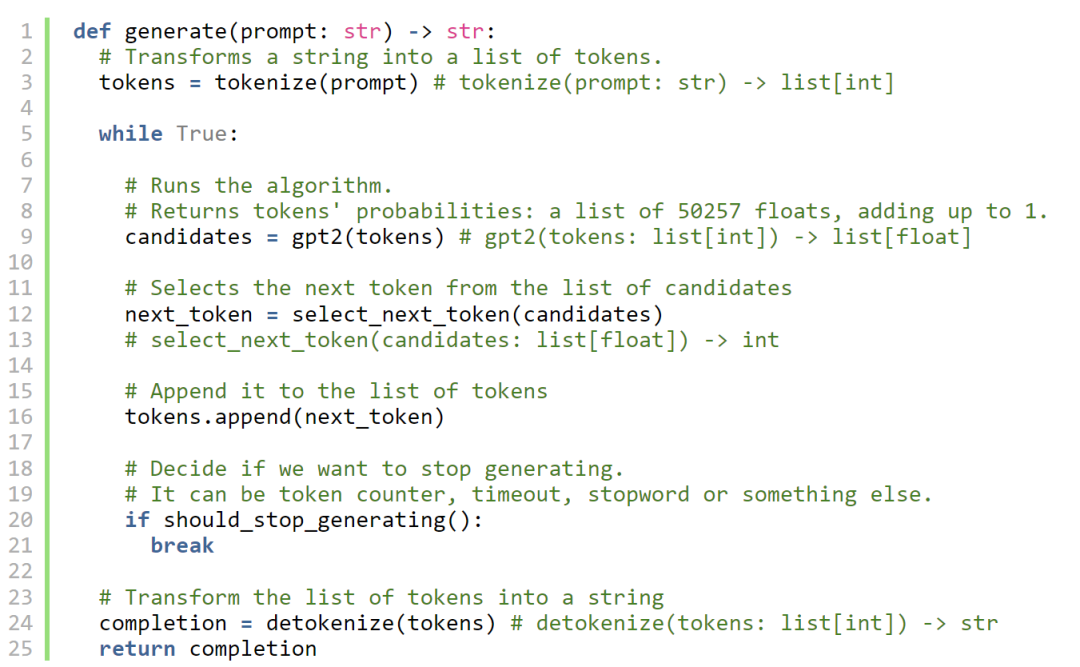
让我们在 SQL 中一一实现所有的能力。
分词器(Tokenizer)
在将文本发送到神经网络之前,需要将其转换为数字列表。当然,这几乎不是什么新闻:这就是像 Unicode 这样的文本编码的作用。然而,普通 Unicode 并不能很好地与神经网络配合使用。
神经网络的核心是进行大量的矩阵乘法,并捕获它们在这些矩阵的系数中具有的任何预测能力。其中一些矩阵在 “alphabet” 中的每个可能值都有一行;其他每个 “character” 有一行。
在这里,单词 “alphabet” 和 “character” 没有通常的含义。在 Unicode 中,“alphabet”长为 149186 个字符(这是在撰写本文时有多少个不同的 Unicode 点),“character”可以是这样的:﷽(是的,这是一个 Unicode 点号 65021,编码了对穆斯林来说特别重要的阿拉伯语整个短语)。请注意,同一个短语可能是用通常的阿拉伯字母写的。这意味着同一文本可以有多种编码。
为了说明这一点,我们以 “PostgreSQL” 这个词为例。如果我们使用 Unicode 对其进行编码(转换为数字数组),我们将得到 10 个数字,这些数字可能是从 1 到 149186。这意味着我们的神经网络需要存储一个包含 149186 行的矩阵,并对该矩阵中的 10 行执行大量计算。其中一些行(对应于英文字母表的字母)会被广泛使用并包含大量信息;其他的,比如便便表情符号和来自死语言的晦涩符号,几乎不会被使用,但仍然会占用空间。
当然,我们希望将 “alphabet” 长度和 “character” 这两个数字的数量保持在尽可能低的水平。理想情况下,我们字母表中的所有 “字符” 都应该均匀分布,我们仍然希望我们的编码与 Unicode 一样强大。
直观地来说,我们可以做到这一点的方法是为我们处理的文本中经常出现的单词序列分配唯一的数字。在 Unicode 中,阿拉伯语中的相同宗教短语可以使用单个码位或逐个字母进行编码。由于我们正在滚动自己的编码,因此我们可以对对模型很重要的单词和短语(即经常出现在文本中)执行相同的操作。
例如,我们可以为 “Post”、“greSQL” 和 “ing” 设置单独的数字。这样,在我们的表示中,单词 “PostgreSQL” 和 “Posting” 的长度都将为 2。当然,我们仍然会为较短的序列和单个字节维护单独的代码点。即使我们遇到乱码或外语文本,它仍然是可编码的,尽管时间更长。
GPT2 使用一种称为字节对编码的算法变体来做到这一点。它的分词器使用一个包含 50257 个代码点(用 AI 的话说是“token”)的字典,这些代码点对应于 UTF-8 中的不同字节序列(加上“文本结尾”作为单独的token)。
此字典是通过统计分析构建的,如下所示:
-
从 256 个token的简单编码开始:每个字节一个token。
-
取一大堆文本(最好是模型将要训练的文本)。
-
对其进行编码。
-
计算哪对token最频繁。假设它是 0x20 0x74(空格后跟小写的 “t”)。
-
将下一个可用值 (257) 分配给这对字节。
-
重复步骤 3-5,现在注意字节序列。如果可以使用复杂token对字节序列进行编码,请使用复杂token。如果存在歧义(例如,“abc”在某些时候可以编码为 “a” + “bc” 或 “ab” + “c”),请使用数字最小的那个(因为它是较早添加的,因此更频繁)。递归地执行此操作,直到所有可以合并为单个token的序列都合并为单个token。
-
执行此合并 50000 次。
数字 50000 或多或少是开发人员任意选择的。其他模型将token数量保持在类似的范围内(从 30k 到 100k)。
在此算法的每次迭代中,将向字典中添加一个新token,该token是前两个token的串联。最终,我们最终将得到 50256 个token。为 “end-of-text” 添加一个固定数字token,我们就完成了。
GPT2 版本的 BTE 有另一层编码:token字典将token映射到字符串,而不是字节数组。此函数定义了从字节到字符串字符的映射。我们将它生成的字典保存在encoder表中。
让我们看看如何在 SQL 中实现分词器。
分词器是 GPT2 不可或缺的一部分,token 字典可以从 OpenAI 的网站以及模型的其余部分下载。我们需要将其导入到 tokenizer 表中 .在这篇文章的底部,你会找到一个指向代码仓库的链接。它的代码将自动填充模型所需的数据库表。
在递归 CTE 中,我们会将此单词拆分为token(从单个字节开始)并合并最好的相邻对,直到没有要合并的内容。合并本身发生在嵌套递归 CTE 中。
对于演示,我将使用“Mississippilessly”一词。结果集中的每条记录都显示到目前为止找到的要折叠的最佳对,以及查询的进度。
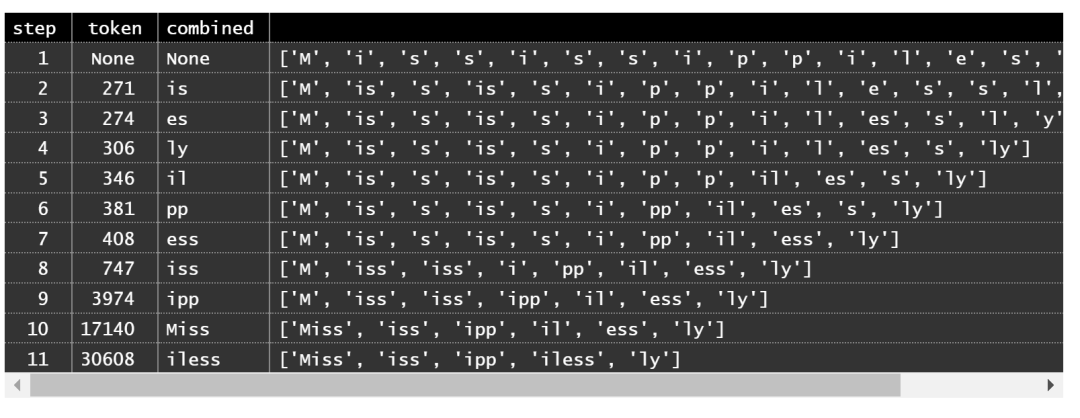
在每个步骤中,BPE 算法都会找到要合并的最佳token对并合并它们(您可以在输出中看到合并的token对及其排名)。此过程将token空间大小从 Unicode 的 150k 降低到 50k,并将token数量(在这个特定单词中)从 17 减少到 5。两者都是很大的改进。
当使用多个单词时,分词器首先使用此正则表达式将文本拆分为单独的单词,然后分别合并每个单词内的分词。不幸的是,PostgreSQL 不支持 regexp 中的 Unicode 字符属性,因此我不得不对其进行一些调整(可能会在此过程中扼杀适当的 Unicode 支持)。

奇怪的字符 Ġ 是空格。
此查询对提示进行token并将其转换为数字数组。这样,提示就可以在模型的各个层中完成。
嵌入(Embeddings)
token代表人类语言的各个部分(通常每个token大约 0.75 个单词),因此任何试图成功完成文本完成的模型都应该以某种方式对这些部分之间的关系进行编码。即使在孤立的情况下,语言的各个部分也具有一组正交属性。
让我们以“subpoena”这个词为例(在 GPT2 分词器中,它本身恰好有一个完整的token)。它是名词吗?是的,非常是。它是动词吗?嗯,算是吧。它是形容词吗?不太是,但如果你眯着眼睛看也可以是。它是法律术语吗?绝对是。等等。
所有这些属性都是正交的,即彼此独立。单词可以是合法名词,但不能是形容词或动词。在英语中,它们的任何组合都可以发生。
具有正交属性的事物最好使用 vector 进行编码。我们可以拥有多个属性(如token编号),而不是单个属性。如果我们能随心所欲地摆动它们,那会有所帮助。例如,要让一个词继续短语“A court decision cited by the lawyer mentions the …”我们可能想要一些既注重法律维度,又注重名词的东西。我们并不真正关心它的副业是形容词、动词还是花。
在数学中,将较窄的值映射到较宽的空格(例如将token ID 映射到向量)称为嵌入(embedding)。这正是我们在这里所做的。
我们如何确定这些向量代表哪些属性?我们没有。我们只是为每个token提供足够的向量空间,并希望模型在训练阶段用有意义的东西填充这些维度。GPT2 对其向量使用 768 个维度。事先(实际上,甚至在回顾中)没有知道这个词的什么属性,比如说,维度 247 编码。它肯定会编码一些东西,但要分辨它是什么并不容易。
我们想在向量空间中嵌入每个token的哪些属性?任何与下一个token是什么有关的东西。
token id?答案是肯定的。不同的token意味着不同的事物。
token在文本中的位置?是的,“Blue violet” 和 “violet blue” 不是一回事。
token之间的关系?当然!这可能是这项工作中最重要的部分,而 Transformer 架构的 Attention 块是第一个把它做好的。
token和位置很容易嵌入。假设我们有短语 “PostgreSQL is great”,正如我们已经知道的,它映射到四个token:[6307, 47701, 318, 1049]
在 GPT2 的其他参数中,有两个矩阵称为 WTE(word token embedding)和 WPE(word position embedding)。顾名思义,前者存储token的嵌入,后者存储位置的嵌入。这些嵌入的实际值已在 GPT2 训练期间填充(“学习”)。就我们而言,它们是存在于数据库表 WTE和WPE 中的常量。
WTE 为 50257×768,WPE 为 1024×768。后者意味着我们可以在 GPT2 的提示中使用的最大token数为 1024。如果我们在 prompt 中提供更多token,我们将无法为它们提取位置嵌入。它是模型的体系结构方面(AI 用语中的“超参数”),在设计时设置,无法通过训练进行更改。当人们谈论 LLM 的 “上下文窗口” 时,他们指的是这个数字。
我们在第 0 位有token 6307,第 1 位有 47701,第 2 位是 318,第 3 位是 1049。对于这些token和位置中的每一个,我们有两个向量:一个来自 WTE,另一个来自 WPE。我们需要将它们加在一起。四个结果向量将是算法下一部分的输入:具有注意力机制的前馈神经网络。
对于 SQL 部分,我们将使用 pgvector,一个 PostgreSQL 扩展插件。
一个小小的免责声明:通常,我用普通 SQL 为我的新年帖子编写代码,有时使用纯 SQL 函数作为辅助函数。在这篇文章中,也可以通过在数组上定义向量运算来做到这一点,但代价是性能会有所下降(它在版本 1 中完成并且有效,尽管速度很慢)。随着 AI 的出现和矢量数据库的日益重要,pgvector 或其等效物肯定会在两三个版本中成为 PostgreSQL 的核心。我只是决定驾驭未来的浪潮。
以下是我们在 SQL 中是如何做到这一点的:
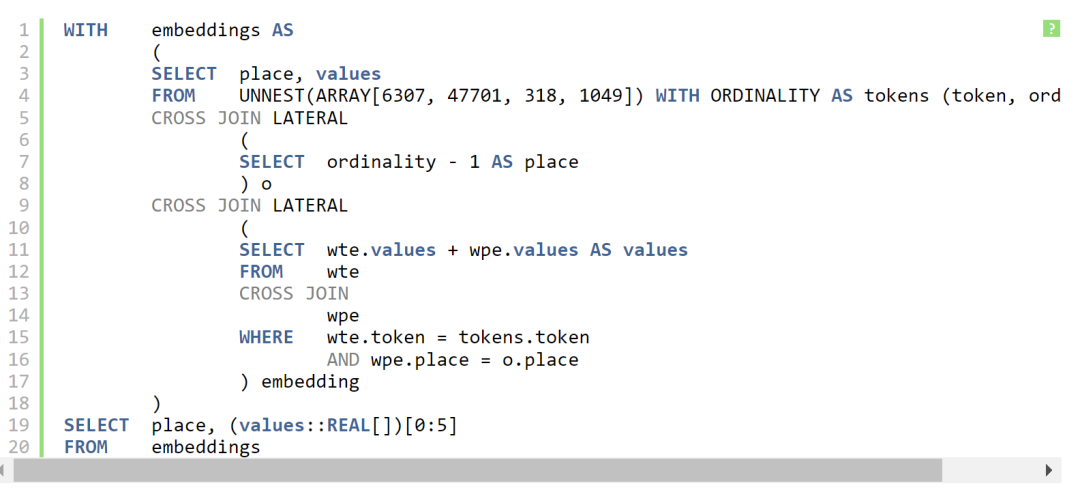

(为了保持输出简短,此查询仅显示每个向量的前 5 个维度)
注意力(Attention)
真正使 Transformer 架构发挥作用的部分是自注意机制(self-attention)。它首次在 2017 年 Vasmani 等人的论文“Attention is all you need”中进行了描述,这可能是最著名的 AI 论文,其标题已成为命名其他论文的snowclone(一种陈词滥调)。
到目前为止,我们有几个向量,希望它们能对 Prompt 中单词的一些句法和语义属性进行编码。我们需要这些属性以某种方式转移到最后一个向量。稍微剧透一下:最终,最后一个向量将存储用于延续词的嵌入。
在像 “I looking at the violet and saw that it was not the usual...”这样的短语中,省略号必须是你看到的东西(这个概念必须从“saw”跳出来),是紫罗兰的一个属性(从“violet”跳到“it”,然后跳到省略号),以及 “unusual” 的东西(从“not”和“usual”跳出来,并在负责 usualness 的维度中翻转符号)。在现实世界中,这个类比是一个人用一门外语读书,他们有点基本掌握,但不是很了解。他们需要有意识地从一个词追溯到另一个词,如果他们不注意短语的关键部分,他们的理解就会出错。
为了实现这种从一个词元到另一个词元的意义转移,我们需要允许所有词元的向量相互影响。如果我们想用一些具体的语义填充单词 “it”,那么有多少语义应该来自提示中的前面向量,有多少应该来自单词 “it” 本身?
为了解决这个问题,模型使用12组矩阵称为Q(查询)、K(键)和V(值)。每组都有64列。它们是通过768×2304的线性变换c_attn从向量嵌入中获得的,其权重和偏差存储在表c_attn_w和c_attn_b中。
c_attn的结果是具有n_token行和2304列(3×12×64)的矩阵。它由12个Q矩阵、12个K矩阵和12个V矩阵按顺序水平堆叠而成。
每组 Q、K 和 V 称为“头”(head)。它们用于通过计算注意力函数来执行称为 “多头因果自我注意” 的步骤。
以下是 attention 函数的公式:
![]()
,
其中 softmax 是权重归一化函数。它的定义如下:
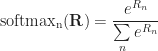
![]()
是一个称为“因果掩码”的常数矩阵。它的定义如下:
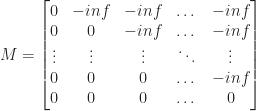
Softmax 将负无穷大转换为 0。
为什么我们需要掩码(Masking)?
我们前面示例中的提示有 4 个token,模型做的第一件事是计算这 4 个token的 4 个embedding。随着模型的进行,这些向量将进行大量计算,但在大多数情况下,它们将是独立且并行的。一个向量的更改不会影响其他向量,就像它们不存在一样。self-attention 块是整个模型中向量相互影响的唯一位置。
一旦模型完成了数学运算,下一个 token 的候选者将仅根据最后一个 embedding 来决定。所有的信息流都应该指向最后一个向量,而不是来自它。在模型的正向传递期间,最后一个嵌入的 瞬时值不应影响先前嵌入的瞬时值。
这就是为什么我们 “mask” 后面的 embeddings,这样它们就不会通过这个特定的通道影响前面的 embeddings。因此有了"多头因果自注意力"中的"因果"一词。
为什么矩阵叫 “query”、“key” 和 “value”?
老实说,我不确定这是否是一个好类比。但我还是会给出我对它背后的直觉的看法。
在机器学习中,计算通常不应涉及可变长度循环或语句分支。一切都应该通过简单的解析函数(加法、乘法、幂、对数和三角函数)的组合来完成。它允许依赖于自动微分等技术的反向传播高效工作。
键值存储的数学模型是表达式
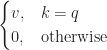
但它不是一个平滑的、可微的函数,它与反向传播配合不好。要使其工作,我们需要将其转换为一个平滑的函数,当 kk 接近 qq 时接近1,否则接近0。
高斯分布(“钟形曲线”),缩放为
![]()
,期望
![]()
值和足够小的标准差将完美地实现此目的:
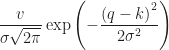
,其中
![]()
是一个任意参数,用于定义钟形曲线的尖锐程度。
在一个维度足够多的向量空间中,如果我们取一个固定向量
![]()
和几个在每个维度上随机均匀地偏离
![]()
的向量
![]()
,它们的点积自然会形成钟形曲线。因此,在向量空间中,“可微键值存储”的概念可以通过表达式
![]()
来建模,这就是我们在注意力函数中使用的。
再次强调,这个类比有些牵强。最好不要过多关注这些关于注意力、含义流、哈希表等的概念。只把它们想象成一个经过测试并被证明非常有效的数学技巧的灵感。
让我们来说明这一步的结果:

以下是我们所做的:
-
在计算注意力函数之前,我们通过应用线性变换
对向量进行了归一化。矩阵
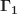
和向量
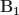
相应地称为 "缩放"和"偏移"。它们是模型的学习参数,存储在表
ln_1_g和ln_1_b中 -
我们只展示了算法的第一层的第一头。在我们用
c_attn_w和c_attn_b中的学习系数乘以向量后("权重"和"偏差"),我们切分了结果的2304个向量,取出了从位置0、768和1536开始的64个向量。它们对应于第一头的Q、K和V向量。 -
PostgreSQL中的
EXP函数在非常小的数字上失败,这就是为什么如果EXP的参数小于-745.13,我们会将其截断为零。 -
我们只显示每个向量的前三个元素。我们完整展示的注意力矩阵。
正如我们所看到的,第一个值向量被按原样复制到输出中(就像在算法的所有其他层中所做的那样)。这意味着,一旦模型经过训练,第一个token的输出嵌入将仅由第一个token的值定义。一般来说,在递归推理阶段,只将token添加到提示符中,与上一次迭代相比,只有输出中的最后一次嵌入会发生变化。这就是因果掩码的作用。
向前看:注意力块是整个算法中唯一一个 token 可以在正向传递期间相互影响的地方。由于我们在此步骤中禁用了后面的token影响前一个token的能力,因此在前面的token上所做的所有计算都可以在模型的正向传递之间重用。
请记住,该模型通过将token附加到提示符来运行。如果我们的原始提示是 “Post greSQL Ġis Ġgreat”,而下一个提示将是(例如)“Post greSQL Ġis Ġgreat Ġfor”,则对前四个token所做的所有计算结果都可以重新用于新提示;无论附加什么,它们都不会改变。
Jay Mody 的说明性文章没有利用这一事实(为了简单起见,我们也没有),但最初的 GPT2 实现使用了。
一旦所有的头都完成了,我们最终会得到 12 个矩阵,每个矩阵宽 64 列和n_tokens行高。要将其映射回嵌入向量的维度 (768),我们只需要水平堆叠这些矩阵。
多头注意力的最后步骤涉及通过相同维度的学习线性变换对值进行投影。其权重和偏差存储在表 c_proj_w 和 c_proj_b 中。
以下是第一层中完整的多头注意力步骤的代码结果:

在将多头注意力的结果传递到下一步之前,原始输入被添加到其中。这个技巧在最初的 transformer 论文中有所描述。它应该有助于解决消失和爆炸梯度的问题。
这是训练过程中的一个常见问题:有时参数的梯度会变得太大或太小。在训练迭代中更改它们要么对损失函数的影响很小(因此模型收敛得非常缓慢),要么相反,影响如此之大,以至于即使是很小的更改也会使损失函数远离其局部最小值,从而抵消训练工作。
前馈(Feedback)
这就是深度神经网络的作用。在此步骤中,实际上使用了大部分模型参数。
此步骤是一个具有三层(768、3072、768)的多层感知器,使用高斯误差线性单元 (GELU) 作为激活函数:
![]()
![]()
已观察到此函数在深度神经网络中产生良好的结果。它可以像这样进行分析近似:
![]()
学习层连接的线性变换参数称为 c_fc(768 → 3072)和 c_proj(3072 → 768)。第一层的值首先使用学习参数 ln_2 中的系数进行规范化。前馈步骤完成后,再次将其输入加到输出上。这也是原始transformer设计的一部分。
整个前馈步骤如下所示:
![]()

此输出是 GPT2 的第一个块的结果。
块(Block)
我们在前面的步骤中看到的内容是分层重复的(称为 “块”)。这些块在管道中设置,以便前一个块的输出直接进入下一个块。每个块都有自己的一组学习参数。
在 SQL 中,我们需要使用递归 CTE 连接块。
一旦最后一个块产生值,我们就需要使用学习的参数 ln_f 对其进行归一化。
以下是模型的最终的样子:
![]()
![]()
![]()
![]()

这是模型的输出。
第四个向量是模型预测的下一个token的实际嵌入。我们只需要将其映射回 token。
令牌(Tokens)
我们有一个嵌入向量( 768维向量),根据模型,它捕获了最有可能的提示延续的语义和语法。现在我们需要将其映射回token。
模型所做的第一步是将 Tokens 映射到它们的嵌入。它是通过 50257×768 wte矩阵完成的。我们需要使用相同的矩阵将嵌入映射回token。
问题是不可能进行精确的反向映射:嵌入可能不会(很可能)等于矩阵中的任何行。因此,我们需要找到 “最接近” 嵌入的 token。
由于 embedding 的维度捕获了(正如我们希望的那样)token的一些语义和语法方面,因此我们需要它们尽可能紧密地匹配。巩固每个维度的接近度的一种方法是只计算两个嵌入的点积。点积越高,token越接近预测值。
为此,我们将嵌入向量乘以wte矩阵 。结果将是一个 50257 行高的单列矩阵。此结果中的每个值都将是预测嵌入和token嵌入的点积。此数字越高,token继续提示的可能性就越大。
要选择下一个token,我们需要将相似性转换为概率。为此,我们将使用我们的好朋友 softmax(我们用来标准化注意力权重的相同函数)。
为什么使用 softmax 进行概率计算?
Softmax 具有满足 Luce 的选择公理的好特性。这意味着两个选项的相对概率不取决于其他选项的存在或概率。如果 A 的概率是 B 的两倍,则其他选项的存在与否不会改变这个比率(尽管它当然可以改变绝对值)。
点积向量(AI 用语中的“logit”)包含没有内在刻度的任意分数。如果 A 的分数大于 B,我们知道它的可能性更大,但仅此而已。我们可以根据需要调整 softmax 的输入,只要它们保持自己的顺序(即较大的分数保持较大)。
一种常见的方法是通过从集合中减去最大值来规范化分数(这样最大分数变为 0,其余分数变为负数)。然后我们取一些固定的数字(比如 5 或 10 个)最高分。最后,我们将每个分数乘以一个常数,然后再将其提供给 softmax。
我们获得的最高分的数量通常称为
![]()
,乘法常数(或者更确切地说,它的倒数)称为“温度”(
![]()
)。温度越高,概率就越平滑,下一个选择的token不仅仅是第一个token的可能性就越大。
token概率的公式是
![]()
,其中
![]()
是
![]()
分数集。
为什么叫“温度”?(temperature)
softmax 函数有另一个名称:玻尔兹曼分布。它广泛用于物理学。除其他外,它还可以作为气压公式的基础,该公式表示密度或空气如何随高度变化。
直观地说,热空气上升。它传播得离地球更远。当空气很热时,空气分子更有可能从其相邻分子身上反弹并跳到原本不可能的高度。与较冷的温度相比,空气密度在高海拔地区增加,在海平面下降。
以此类推,较大的 “temperature” 会增加选择 second-choice tokens 的概率(当然,这是以牺牲 first-choice tokens 为代价的)。推论变得难以预测,但更具“创造性”。
让我们把这些都放到 SQL 中。提示是“PostgreSQL is great”。以下是根据模型最有可能延续这个短语的前 5 个token,以及它们在不同温度下的概率:

推理(Inference)
最后,我们准备进行一些真正的推理:运行模型,根据其概率选择一个 token,将其添加到提示符中并重复,直到生成足够的 token。
正如我们之前看到的,LLM 本身是确定性的:它只是对预定义常量的一系列矩阵乘法和其他数学运算。只要提示符和超参数(如 temperature 和 top_n)相同,输出也将相同。
唯一的非确定性过程是token选择。它涉及随机性(程度不同)。这就是为什么基于 GPT 的聊天机器人可以对同一个提示给出不同的答案。
我们将使用短语“Happy New Year! I wish“作为提示符,并让模型为此提示符生成 10 个新 Token。温度将设置为 2,top_n将设置为 5。
查询在我的计算机上运行 2 分 44 秒。这是它的输出:

您可以在 GitHub 存储库中找到查询和安装代码:quassnoi/explain-extended-2024
Quassnoi写的SQL实现GPT大模型逻辑非常复杂,这条SQL代码有497行,在视频号【大圣聊数据库】录制了一个短视频简单介绍:
大圣聊数据库
,赞22
参考文档
https://github.com/openai/gpt-2
https://github.com/quassnoi/explain-extended-2024
https://explainextended.com/2023/12/31/happy-new-year-15/
https://arxiv.org/abs/1706.03762
https://www.ninedata.cloud/sql_poker24
https://jaykmody.com/blog/gpt-from-scratch/
https://www.cnblogs.com/zhongzhaoxie/p/13064404.html
整理人
叶正盛,NineData 创始人 &CEO,资深数据库专家,原阿里云数据库产品管理与解决方案部总经理。NineData(www.ninedata.cloud)是云原生数据管理平台,提供数据库 DevOps(SQL IDE、SQL 审核与发布、性能优化、数据安全管控)、数据复制(迁移、同步、ETL)、备份等功能,可以帮助用户更安全、高效使用数据。