01
火热的多模态智能
回顾到2024的大型语言模型(LLM)的发展,让人欣喜的一点是scaling law依然奏效,智能随着资源的提高继续提高。但另一个让人担忧的点是高质量的文本语料似乎即将触及上限。为了加入更多的数据喂给模型,人们逐渐将目光转向除了文本之外的其他模态,还有这么多图像,音频,视频等其他模态数据没有像文本数据这样被充分利用起来。拥有了多模态能力的模型会对token在物理世界的原型有着更准确的理解,从而解锁除了纯文本之外的大量应用场景。2024年上半年,OpenAI发布了GPT-4o,Anthropic发布了 Claude 3,谷歌发布了Gemini1.5 Pro,苹果发布了端侧的多模态LLM Ferret-UI不约而同选择加强了其他模态的处理能力,这些产品级的大模型问世意味着“多模态”这个原本只在论文和高校中的时髦名词正变成一次又一次地API调用,促进着人们的生产,创作和学习。

02
组合图像检索(Composed Image Retrieval)
随着多模态大模型的逐渐成熟,多模态检索也开始获得了越来越多的注意力。多模态检索意味着用户的检索意图来自于多种模态的输入,最常见的情况是结合了来自文本端和图像端的输入。从图像搜索的角度来看,检索的相似性已经在大部分场景下满足了用户的需求,而一个更加具有想象力的需求是用户实际的检索意图和参考图片并不完全一致,最方便的表达这种差别的自然就是文字。而从文字检索图片的角度来看,当你的检索目标外观有了一定的限制,比起用冗长,准确的文字来去描述这个目标,不如用一张参考图片来表示这个目标,用剩下的文字进行补充说明。所以组合图像查询的一个典型场景就是用图片表达检索意图中细节最具体的一部分,用最可控的文本来去修正这个检索意图。
03
组合图像的方法简介
我们来介绍一些近两年在这个方向上的一些工作,近两年这个领域的方法逐渐朝着通用性(即zero-shot)的方向发展。因为CLIP带来通用的文图搜索能力,所以在训练数据少的情况下,主要的解决思路是将文本和图片的结合映射到CLIP的空间(从而巧妙地利用到了CLIP的通用性)。而如果资源足够多,那就可以朝着标注更多更准确的数据来去监督训练。此外,回顾历史,我们也可以发现,检索能力的提升,促进着数据标注的效率,数据质量的提升又提高着模型的能力,而模型的提升进一步促进着检索能力的提升,也是数据驱动的人工智能技术浪潮背后一次又一次的循环。

Pic2Word
Google提出的Pic2Word的想法是如果把图片用一个文本token来进行表示,那么图片与文本就可以统一成文本,并很自然地生成CLIP text embedding进行以文搜图查询。当然这种token并不是真正的文本token,而是生成的一个伪符(pesudo token),用来在文本空间中表示图像。
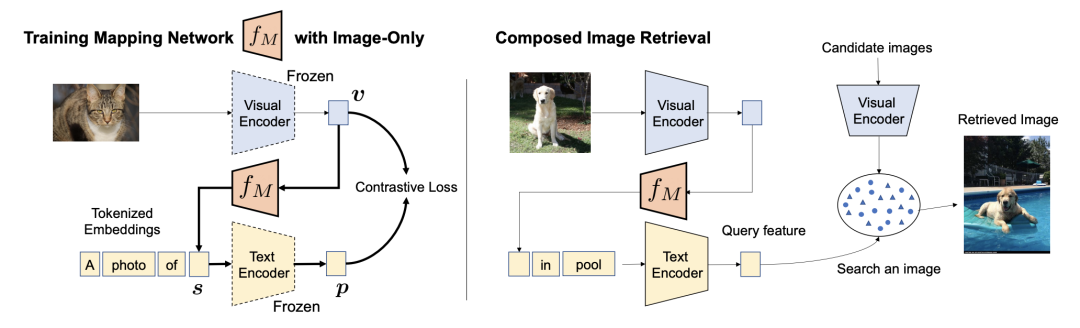
图源:Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval
这里的关键就在于训练一个图像embedding到pesudo token embedding的映射网络 ,这里的Visual 和Text Encoder是训练好的CLIP编码器,图像生成一个CLIP visual embedding,它被这个映射网络映射到成了pesudo token 的token embedding,然后放入预先定义的 prompt "A photo of [s]"中的占位符, 由固定住参数的CLIP网络转换成了CLIP text embedding,而这个网络训练的目标就是让这两个图文embedding相近,从而网络 拥有了正确将图像映射成pesudo token的能力,训练好后,你就可以编辑文本,并且在文本中使用来指代原始图像了,例如 "a image of [s] in pool", 加上一张狗的图片得到的CLIP Embedding,从而建模出小狗在游泳池中的语义。
CompoDiff
Compodiff利用了扩散模型(diffusion models)的技术来进行组合图像搜索,扩散模型技术是一种目前文生图的主流技术,极大的增强了图片生成的可编辑性。这一类模型一方面能够参照文字信息,另一方面又可以使得生成的内容符合训练图像的分布。而Compodiff的就是将现有的图像扩散模型技术应用到了embedding生成上,希望将输入的文本,参考图片,掩膜Mask等组合共同生成出一个符合CLIP visual embedding分布的向量,从而可以进行组合图像查询。
我们先来简单地理解一下扩散模型:
扩散现象可以理解为墨水滴在清水中的扩散一样,原本的清水随着墨水分子的逐步运动,最后整瓶水变成浑浊。扩散模型的正向过程就好比这样,将清晰图像逐步加入高斯噪音,随着若干步后,图像的信噪比越来越低,图像最终完全变为均值方差固定的高斯噪声图像。而我们更加感兴趣的是这一过程的逆过程,通过一个高斯噪声图像加入特定的高斯噪声(经过学习后的网络就是用来产生这个特定噪声)进行去噪,将图像一步一步变清晰,这就意味着网络能将噪声转换为符合训练分布的自然图像,使用CFG技术加入文本后就可以做条件生成,需要符合文本描述,而不是生成无条件的随机图像。
而Embedding模型自然就可以理解成根据文本,将一个高斯噪声embedding一步一步去噪,逐渐增大embedding的信噪比变为符合CLIP embedding分布的visual embedding,并且将文本和图像进行生成过程的控制,另外,mask也为这个条件提供额外的信息指示希望修改哪部分图像。
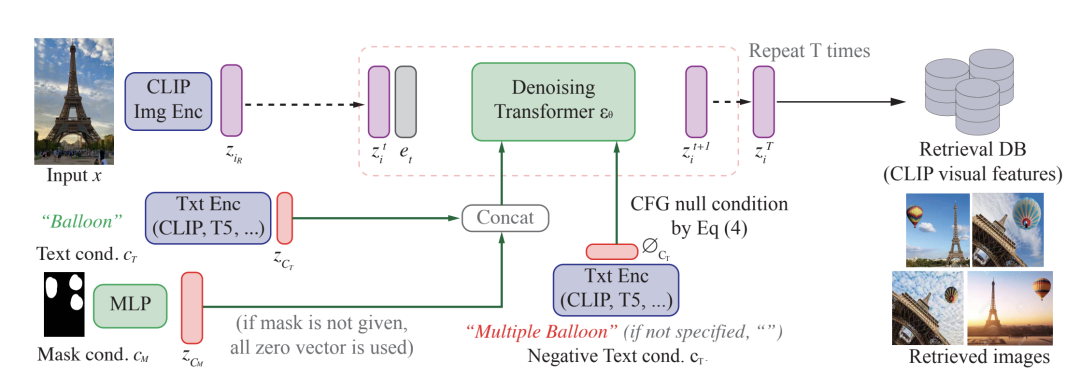
图源:CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
这张图描述了Compodiff在推理阶段生成检索向量的过程,将埃菲尔铁塔图像编码为CLIP embedding ,经过正向扩散过程变成噪声 ,再经过去噪transformer的逐步去噪中,并且通过注意力机制引入mask条件 (指示修改哪些区域),和文本条件embedding “Balloon”,逐渐去噪为带有单个气球的埃菲尔图像的CLIP visual embedding。(同时利用文本生图中的技术,在去噪过程中使用CFG引入了负向embedding“multiple balloon”避免生成多个气球)。
为了达到这个条件生成的目的,作者们构建了一个数据集SynthTriplets18M,由 这样的三元组构成,为参考图像, 为条件描述,为目标图像,他们首先由构造出原始的三元组文本(通过从原始文本中检测出关键字,再替换为一个语义上近似的词产生目标文本),然后再使用先进的文生图模型比如StableDiffusion (SD) 来进行图像的生成。
图源:CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
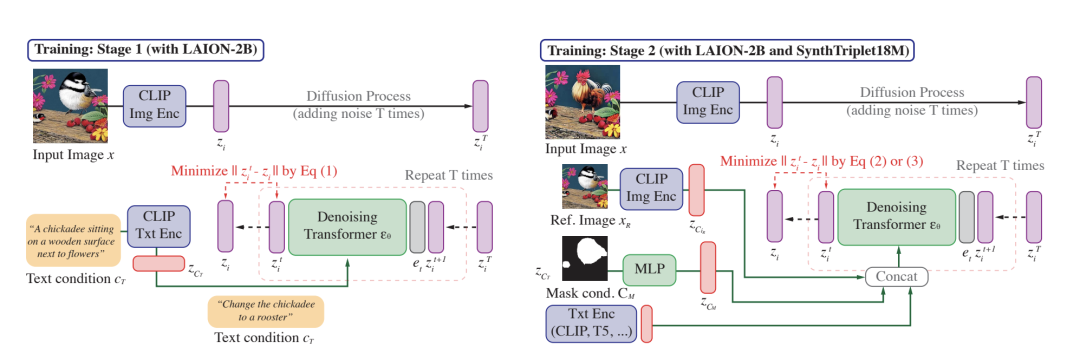
我们接下来来看一下CompoDiff的训练过程,整个模型分为两个阶段,第一阶段是在海量的图文匹配数据(LAION-2B)上训练扩散模型,让模型具有根据文本描述从CLIP text embedding从噪声生成CLIP visual embedding模型的能力,第二阶段则是在SynthTriplets18M上进行微调,拥有根据条件来生成特定CLIP visual embedding的能力。
Stage 1:
由图像先生成CLIP embedding , 并逐渐加入噪声成为高斯噪声 ,同时将该图片对应的文本生成CLIP text embedding ,通过注意力机制注入到去噪transformer,训练目标为去噪网络最终得到的embedding与对应的visual embedding接近,通过这样获得了根据文本从噪声向量中恢复出CLIP visual embedding的能力。
Stage 2:
作者在这里希望同时引入绘制mask来指示修改区域的能力,但由于没有mask的标注数据,所以作者交替进行两种训练,希望达成两个目标(1)将目标图像的所有名词区域遮住,由这个遮盖图像经过扩散过程的噪声embedding在加入文本描述以及mask后,反向生成的visual embedding 将与目标visual embedding接近 (2)由参考图像扩散生成的噪声embedding加入文本描述后以及mask后,生成的visual embedding将与目标visual embedding接近。从概念上理解(1)的目标是一个让模型学习图像文本匹配关系的“预训练”过程,(2)则是让参考图片信息,mask,文本学习出到目标图像信息的“微调”过程。
CIReVL
大部分组合查询的方法都需标注的三元组数据集进行标注,一方面这样的标注昂贵,另一方面这样的数据难免会过拟合到特定分布(在这种情况下输入不是训练集类似的图片效果就骤然下降),而随着大模型(LLM, VLM)的兴起,zero-shot这种范式收到了越来越多的关注,CIReVL就是这样一种无需训练并且能获得强大性能的方法。
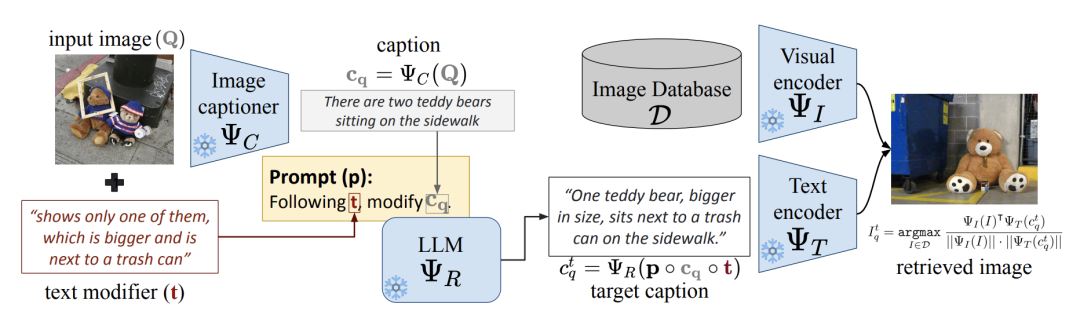 图源:Vision-by-Language for Training-Free Compositional Image Retrieval
图源:Vision-by-Language for Training-Free Compositional Image Retrieval
在这里使用了三个具有很强泛化能力的模型,一个用于进行为图像生成描述的VLM(例如BLIP2),一个用于修改文本对描述文本进行修改的LLM(例如gpt-3.5, gpt-4),一个图文编码器(CLIP),原理也非常简单,将图像变成文本,再使用prompt工程结合修改文本转为目标文本,最后生成目标文本的embedding,进行查询,当然作者也为这个prompt模版做了很精细的设置从而达到一个好的效果。
MagicLens
回顾之前的方法,我们可以发现CIR的难点是来自于如何进行真实数据的收集与标注,这样才能训练出一个泛化性高,理解能力强的模型,来自Deepmind和俄亥俄州立大学的作者们选择解决这个硬核难题。
图源:Self-Supervised Image Retrieval with Open-Ended Instructions
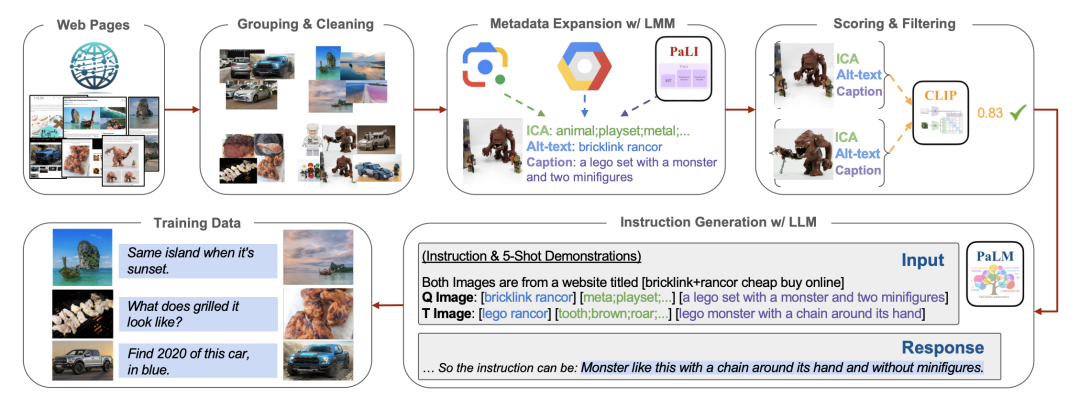
MagicLens这篇论文的亮点在于提出了一个数据管线,来收集这样真实的三元组数据,我们来结合示意图介绍一下这个管线中的每个阶段。Web pages:作者认为来属于同一URL的图像很有可能是相关的,从而根据这个认知来去大规模收集数据。
Grouping&Cleaning:作者从Common Crawl中收集同一URL下的图像,过滤掉低分辨率,重复,广告图后进行分组,后续的图像对就来自于这样的分组。
Metadata Expansion: 为图像生成元信息,其中ICA是使用Google vision API得到的较粗略的信息。Alt-text是网页中带有的图像替代文本(当无法显示图像时展示这个文本),Caption则是使用Google的PaLI大模型生成的图像描述。
Scoring & Filtering:进一步进行过滤,使用CLIP图像到图像的评分来评估视觉相关性,并使用文本到文本的评分来评估非视觉相关性。对于在这两方面得分低的图像会被排除。
Instruction Generation:利用生成的metadata信息,用Google的LLM(PaLM 2)来生成从参考图像的元信息到目标图像元信息的文本指令。
通过这样的一个数据处理的管线,最终产生了36.7M的三元组(参考图像,文本,目标图像),接下来就是进行模型的训练。
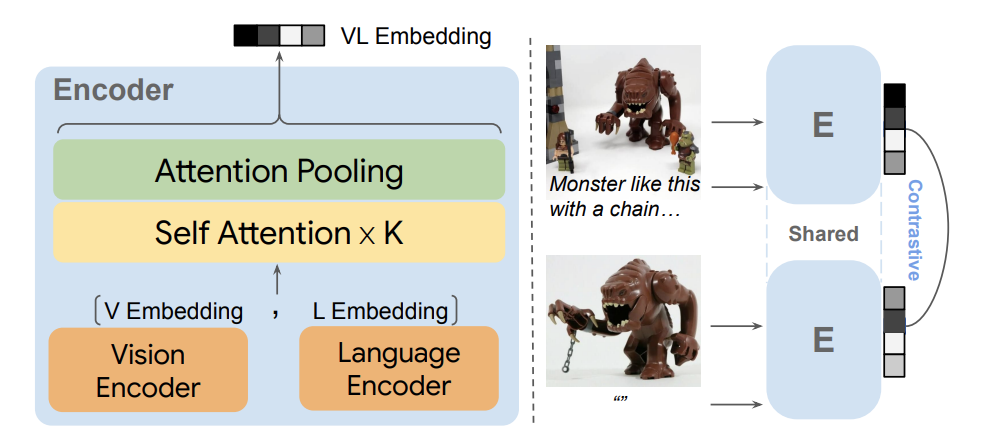
图源:Self-Supervised Image Retrieval with Open-Ended Instructions
有了大规模的高质量数据,MagicLens在模型方面就采取了较为简单的设计,使用编码器(CLIP或CoCa)分别将图像和文本编码为Embedding,再经过多个自注意力层,生成了一个多模态表征向量。因为检索的图像都没有文本,可以使用空文本“”来替代描述文本,从而生成图像的Embedding。
评测
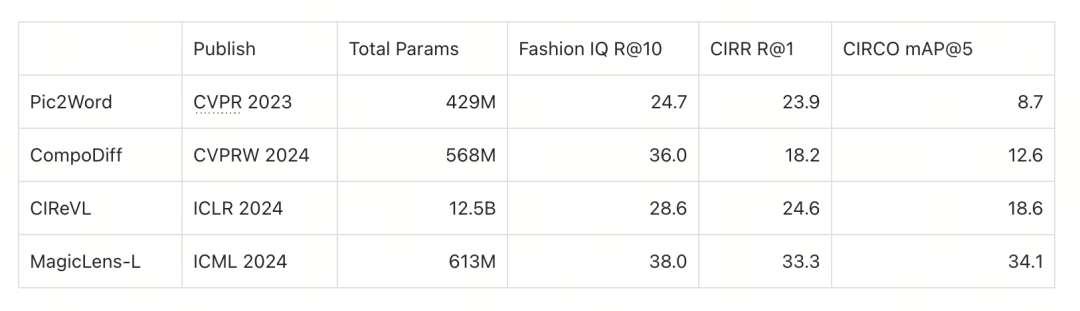
目前广泛所使用的用于CIR评测的数据集为FashionIQ, CIRR以及CIRCO。

图源:Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval
Fashion IQ:FIQ (Fashion Image Query) 是一个时尚领域的基准数据集,由Wu等人在2021年提出。该数据集包含三个不相交的检索子任务:连衣裙、衬衫和上衣。每个子任务都涉及从时尚图片库中检索特定类型的服装图片。它有2005个查询,和5179个索引图像。
CIRR:CIRR是由Liu等人在2021年构建的第一个基于真实自然图像的数据集。该数据集定义了九种查询图像和目标图像之间的关系类型,它拥有4148个查询,和2316个索引图像。
CIRCO:CIRCO 是一个大型自然图像检索数据集,包含超过12万张自然图像作为索引集,由Lin等人在2014年提出。与CIRR不同,CIRCO为每个查询注释了多个正确答案,因此每个查询都有多个目标图像,它拥有800个查询,和123403个索引图像。
04
总结
在本文中,我们探讨了近年来兴起的多模态检索方式。相比于传统的图像检索或文本检索,多模态检索结合了两者的优势,既具备高表达能力,又能提供细致入微的描述能力。我们还介绍了一些关键方法。由于算力和资源的限制,多数方法倾向于将文本信息和图像信息融合到一个 CLIP 向量空间中。然而,随着大规模视觉语言模型(VLM)的出现,使得对复杂数据进行经济高效的大规模标注成为可能。像 Google 这样的科技巨头已经开始训练原生模型,而提出广受欢迎的 BGE 嵌入模型的智源研究院也发布了他们的 Visualized-BGE 模型。在生成式 AI 技术推动内容爆发的背景下,这种新兴的检索范式有助于人们更准确地表达自己的检索意图,从海量数据中找到所需信息。这正是多模态技术为当前各项技术带来的创新动力和无限可能。
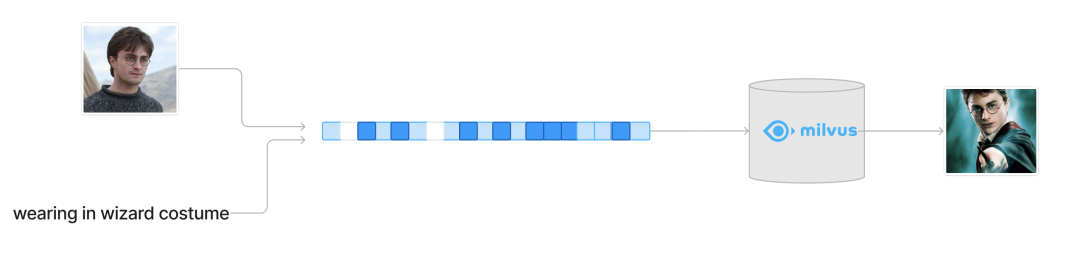
此外,我们还利用 Milvus 构建了一个在线 demo,用于体验多模态搜索。这一 demo 采用了 MagicLens 作为嵌入模型,并结合了基于 GPT-4o 的结果重排功能,可以根据用户的检索意图对查询结果进行优化排序。这一探索展示了多模态模型在提升新一代多模态检索系统中的潜力。欢迎感兴趣的朋友前来体验。
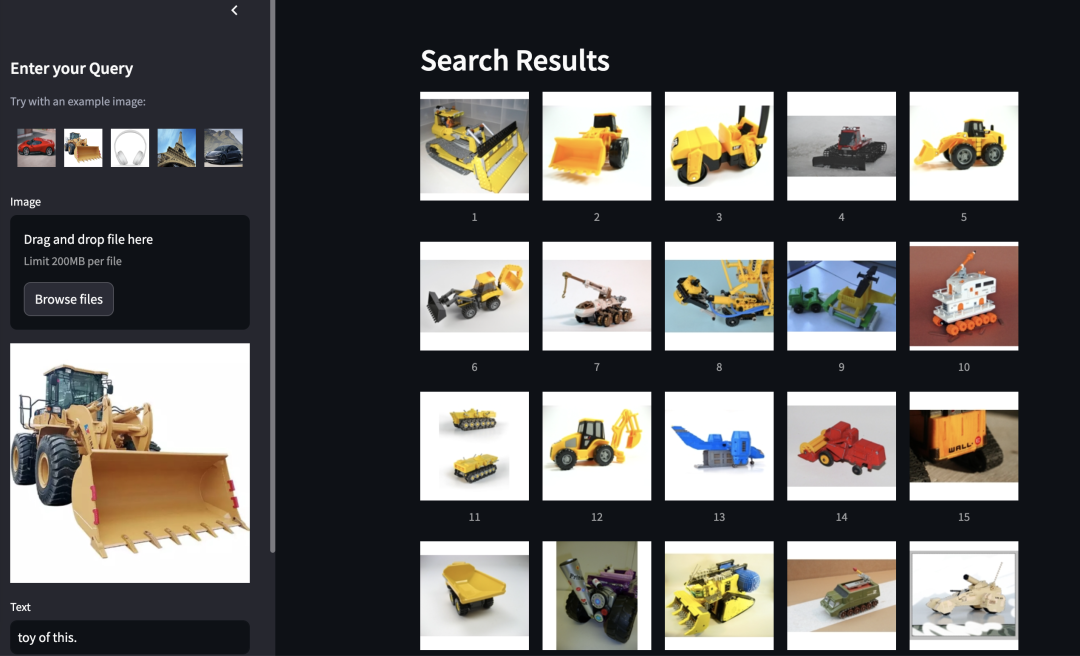
图源:https://milvus.io/milvus-demos
Resource:
MagicLens: https://open-vision-language.github.io/MagicLens/
SEARLE: https://github.com/miccunifi/SEARLE
CIReVL: https://github.com/ExplainableML/Vision_by_Language
CompoDiff: https://github.com/navervision/CompoDiff
Milvus demo: https://milvus.io/milvus-demos
本文作者

推荐阅读