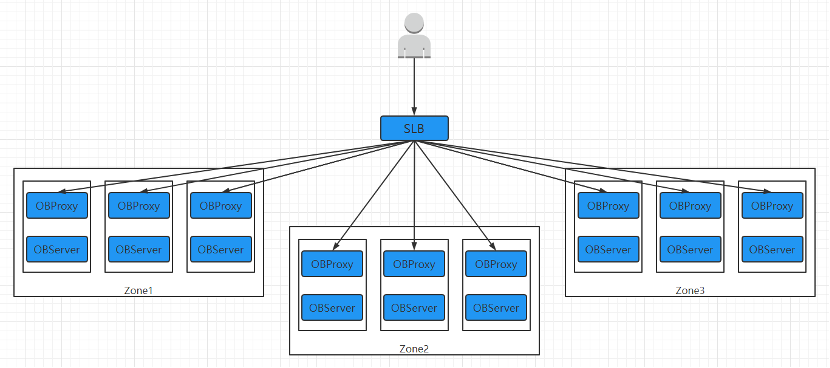
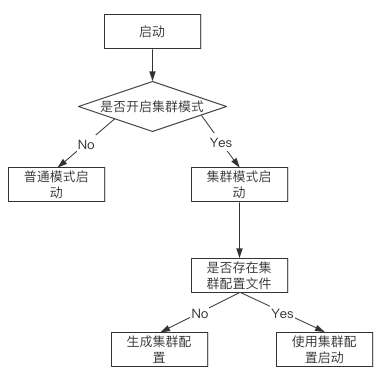
要想从零开始部署一个**大语言模型(LLM)**到本地,不仅仅是硬件上安装软件包,还需要对模型选择、优化和应用搭建有一定的理解。下面是一份完整教程,手把手带你走过如何在本地环境中部署LLM。
1. 了解部署需求与硬件准备
硬件需求:大语言模型一般需要强大的硬件支持,尤其是显卡。推荐使用NVIDIA GPU,如果是高端模型(如LLaMA-2 70B参数模型),需要至少24GB显存。对于轻量级模型如LLaMA-2 7B,8GB显存也可以应付。
软件需求:你需要一个Linux或者Windows系统,配置好Python环境(推荐Python 3.8+)。此外,还需安装深度学习库如PyTorch或TensorFlow。
2. 环境搭建与安装
安装基本依赖
首先,更新系统并安装Python虚拟环境:
sudo apt update
sudo apt install python3-pip python3-venv -y接着,创建并激活虚拟环境:
python3 -m venv llm-env
source llm-env/bin/activate安装PyTorch
PyTorch是大多数语言模型运行的核心库,确保你的机器有CUDA支持:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1173. 下载大语言模型
这里,我们以Hugging Face上的开源模型为例,推荐使用Hugging Face的Transformers库来下载和运行模型。你可以根据自己的需求选择不同的模型,比如GPT-2或者LLaMA-2系列模型:
pip install transformers下载并运行GPT-2模型的示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
# 示例对话
inputs = tokenizer("Hello, how are you?", return_tensors="pt")
outputs = model.generate(inputs["input_ids"], max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))这段代码会自动下载GPT-2模型,并生成响应。你也可以尝试类似的LLaMA模型或其他开源模型 。
4. 优化本地运行性能
由于大语言模型可能占用大量资源,你需要根据硬件调整运行效率。例如,使用模型量化技术,可以将模型的浮点精度降低,从而减少内存使用。LLaMA模型有一些GGUF格式文件,支持量化模型的轻量级部署 。
另一种优化方法是通过框架如Llama.cpp,这是一个为LLaMA模型优化的C++推理引擎,特别适用于Apple Silicon 。你可以通过以下步骤来运行LLaMA模型:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
./main -m /path/to/model.gguf -p "Hello, world!"5. 部署在本地服务器
对于生产环境中的应用,你可以通过API方式部署。以Ollama为例,它提供了简单的命令行工具和API接口,可以快速调用模型并获取结果 。
你可以使用以下命令启动一个本地会话:
ollama run llama2或者,通过CURL接口请求模型:
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "What is the capital of France?",
"stream": false
}'6. 实战案例:LLaMA模型部署
假设你要部署LLaMA-2 13B模型,首先通过Hugging Face下载该模型,并配置相关环境:
pip install llama-cpp-python接着,编写简单的Python代码,加载并运行LLaMA-2 13B模型:
from llama_cpp import Llama
llm = Llama(model_path="./llama-13b.gguf")
output = llm("What is the meaning of life?")
print(output)7. 应用场景与拓展
一旦你的模型部署完成,你可以用它做很多事情,比如自然语言处理任务、文本生成、对话机器人、甚至为你的网站提供智能助手。通过与前端框架(如Flask或FastAPI)结合,你可以将这些模型嵌入到应用程序中 。
总结
本地部署大语言模型的过程需要硬件和软件的配合。通过选择合适的模型、优化推理引擎,以及通过API与应用结合,你可以灵活地使用这些强大的AI工具。