本实物模块从实物外观、模块组成、API申请及功能说明四部分来介绍这款基于ESP32S3的大语言模型对话模块。
1、实物外观

2、模块介绍
本硬件平台主要由三个模块组成,包括MAX9814录音模块、MAX98357音频功放模块和ESP32S3模块。如下图所示。
MAX9814录音模块:

MAX98357音频功放模块:

ESP32S3模块:

3、API申请
本硬件平台需要用户自己申请3个API,分别是语音识别API、大语言模型API和语音合成API,本硬件平台用的语音识别API是百度智能云,大语言模型API是阿里通义千问,语音合成API是讯飞平台。因此,这里介绍上述三种API的申请方式,用户仅需在代码中更改API基础信息即可完成配置。
首先是百度语音识别API的申请:
搜索百度智能云并进入官网:
 在官网中选择产品--语音技术--短语音识别标准版:
在官网中选择产品--语音技术--短语音识别标准版:
 点立即使用,并登录百度账号:
点立即使用,并登录百度账号:
- 第一次用可以使用免费尝鲜获取一部分体验额度:
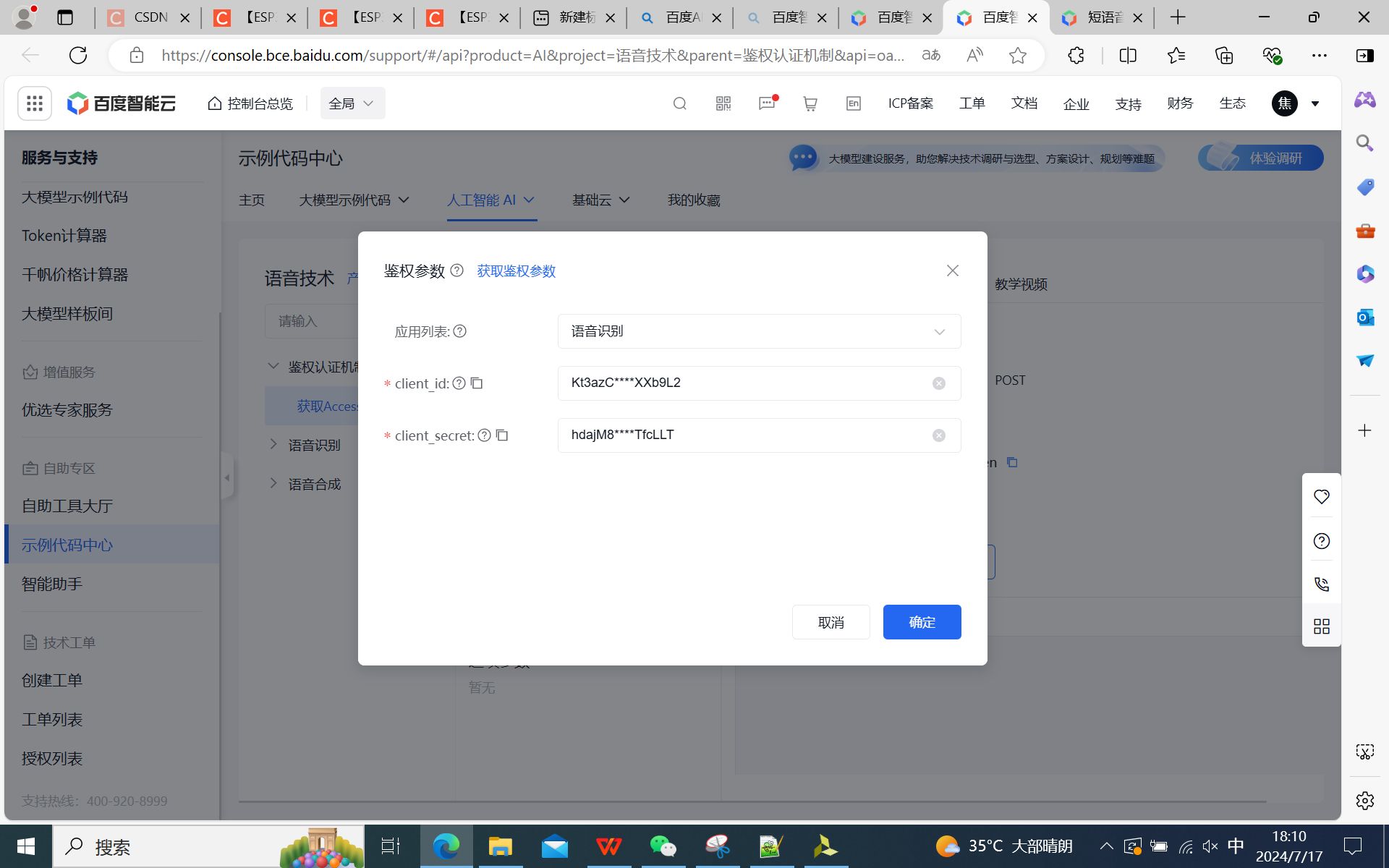
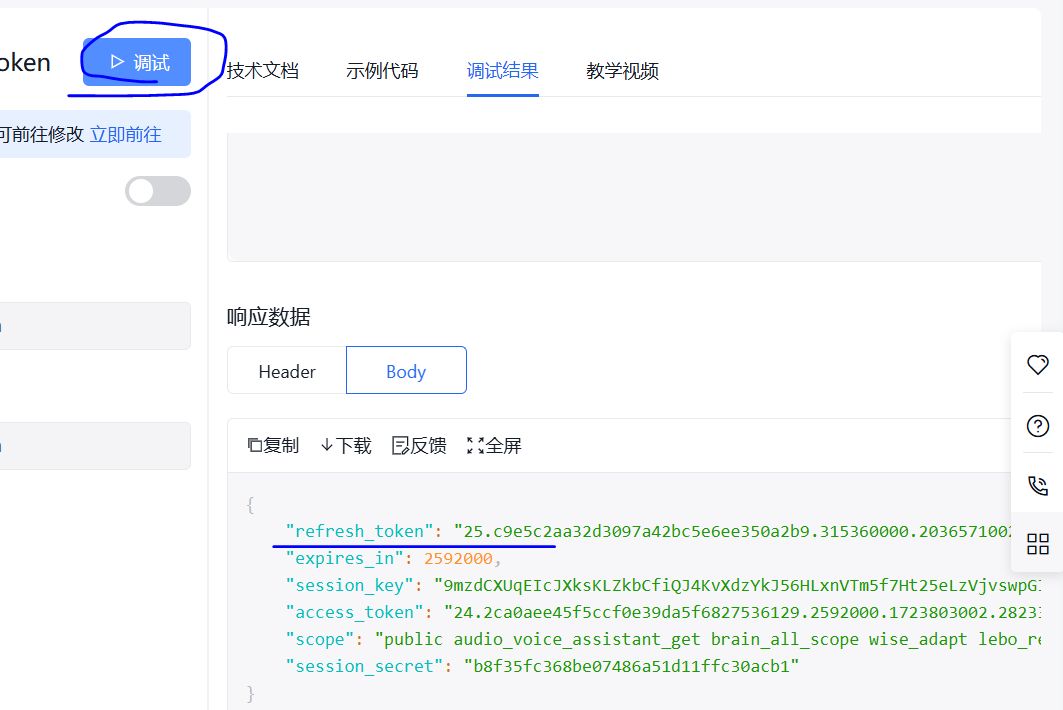
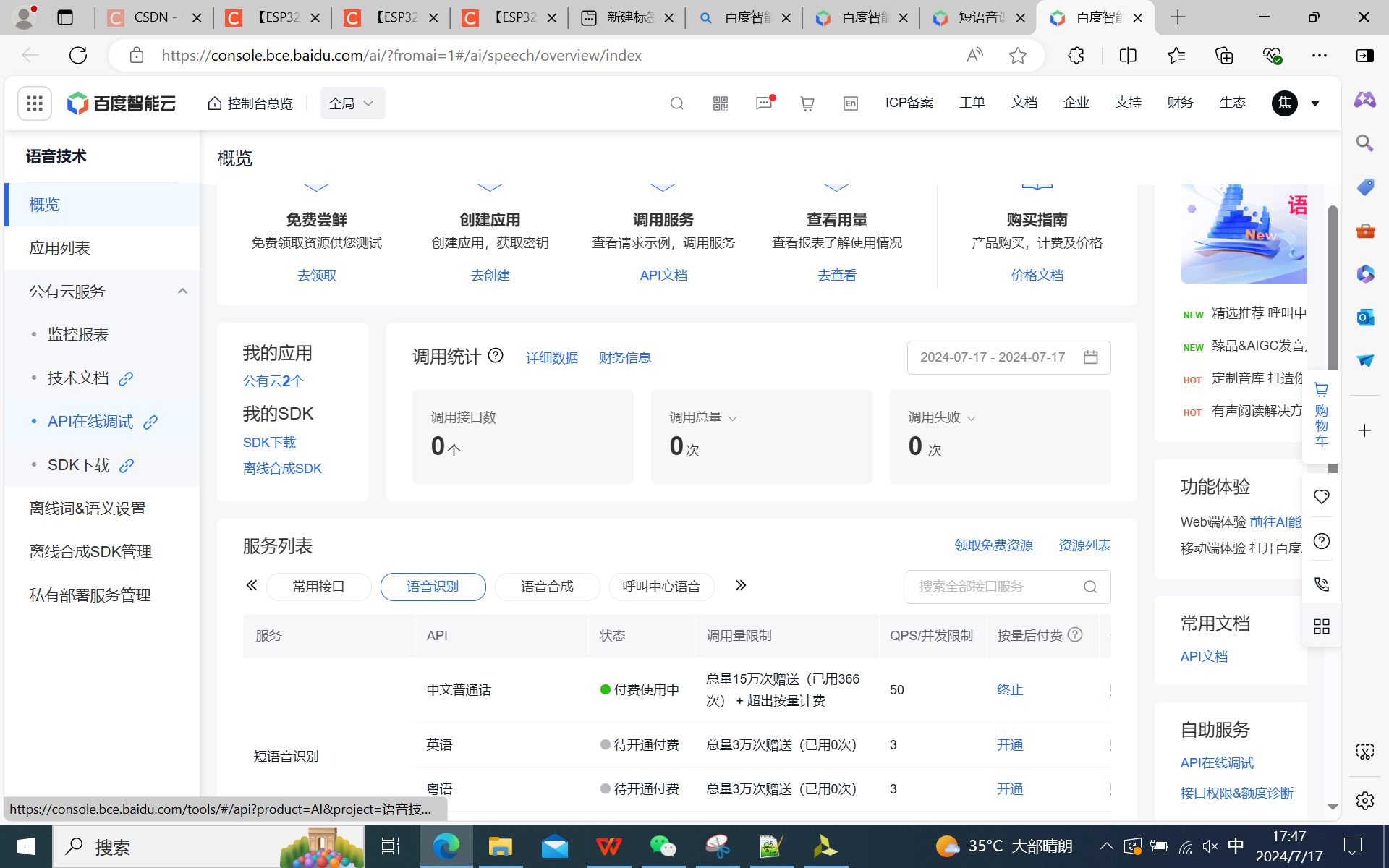 创建短语音识别应用,并获取API Key、Secret Key,以及通过调试获取token:
创建短语音识别应用,并获取API Key、Secret Key,以及通过调试获取token:
然后是阿里通义千问API的申请:
搜索阿里云并进入官网,扫码登录:
 搜索Dashscope进入灵积服务模型:
搜索Dashscope进入灵积服务模型:
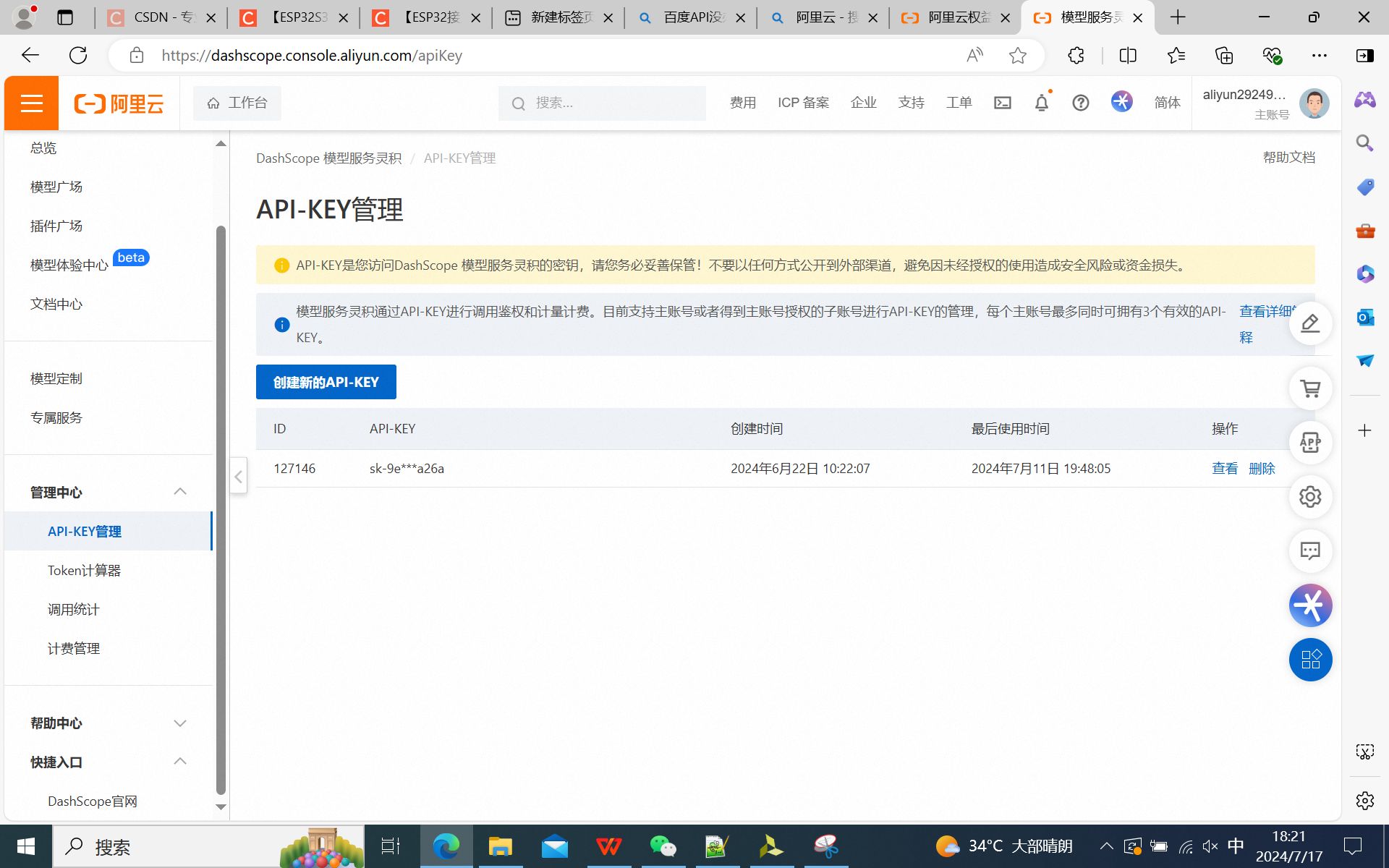
 进入API-KEY管理,创建新的API-Key:
进入API-KEY管理,创建新的API-Key:
最后是讯飞语音合成API的申请:
首先搜索讯飞语音合成APi,并进入官网:
 第一次使用有免费额度,直接领取个人免费套餐,进入登录界面:
第一次使用有免费额度,直接领取个人免费套餐,进入登录界面:
 进入官网后领取完在线语音合成额度:
进入官网后领取完在线语音合成额度:
 领取完额度后进入控制台创建新应用:
领取完额度后进入控制台创建新应用:
 创建完之后就能获取APPID、APISecret、APIKey:
创建完之后就能获取APPID、APISecret、APIKey:
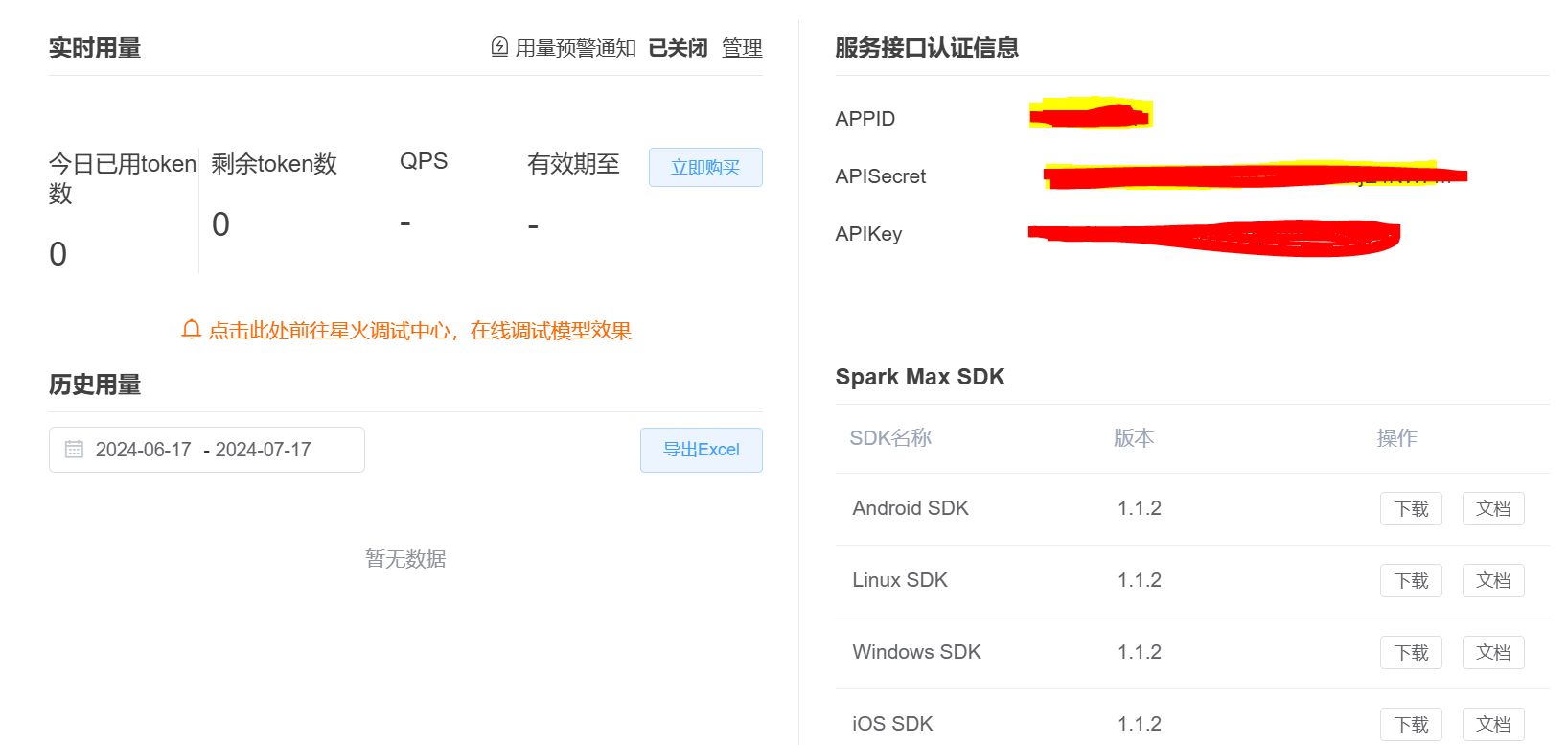
以上就是所有API的申请教程。
4、功能介绍
本硬件平台可以实现链接开源大语言对话模型,并与其实时对话的功能。具体操作步骤如下:
第一步是上电,此时系统会介绍一下自己,上下两个LED都不亮;

第二步是按下录音按钮,上面的LED开始常亮。此时可以与系统对话,录音时间为5s,上面LED灭后,表示录音结束。

等待2-3s之后,系统输出大语言模型反馈结果,并通过喇叭发声的方式输出,此时下面的LED会亮,输出结束之后下面的LED会灭。

本文大部分内容都属于原创,如需转载,请附上本文网站,
如果需要相关的仿真图、程序代码等资料可以直接私信我,我会及时回复。