- GPU Direct
GPU 网络的情况已经发生了很大变化。每个 GPU 都有自己的内部互联,例如 NVIDIA 的 A100 或 H800,它们内部的 NVLink 互联可以达到 600GB 甚至 900GB。这种内部互联与外部以太网网络集群设计之间存在耦合关系。GPU 是单机多网卡的,单机内的多张网卡之间有高速互联,单个服务器的带宽可以达到 3.2T,与通用 CPU 计算带宽相比至少有 6 到 8 倍的关系。GPU 需要使用 GPU Direct RDMA 来实现显存之间的数据迁移,并且需要超短的 RTT(往返时延)。
- redis实践
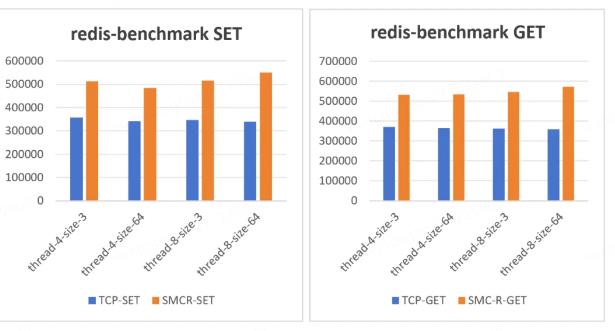
redis-banchmarh 测试中,SET 方法在使用 TCP 协议下,无论线程数或数据包大小场景下均比较稳定,在使用 SMC 协议下,提升幅度较大,达到 40% 以上,在线程数 8、数据包大小 64 情况下提升 60%。GET 方法测试结果与 SET 方法相近,性能提升趋势也基本一致。
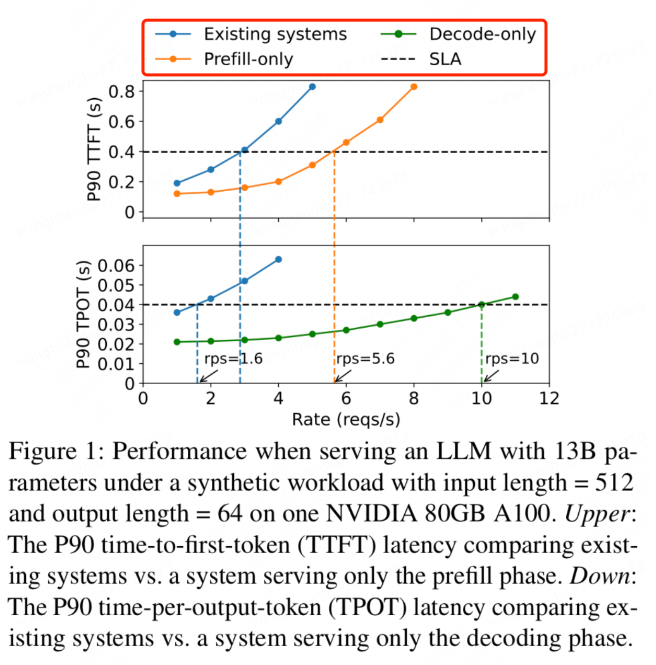
- DistServe实验数据
(分离式架构可以在同等TTFT和TPOT下提升吞吐)
参考文章:https://aijishu.com/a/1060000000472929
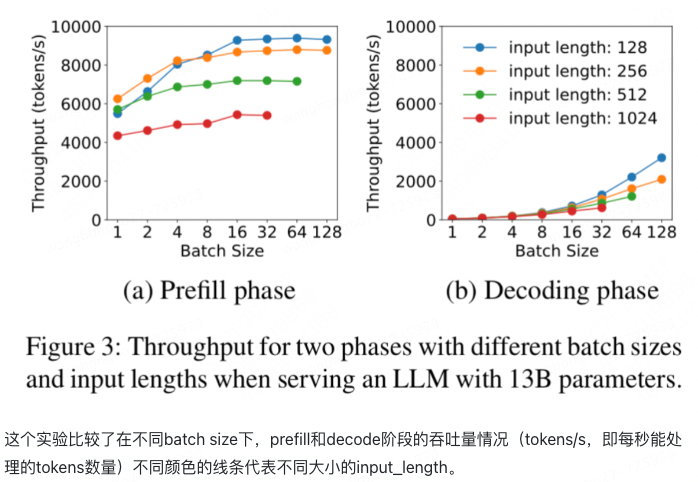
decode场景可以提高batch size (input token数)(右); 但是prefill阶段batch size很容易打到上限(左)
- batch执行方式分析 参考

RDMA优势:吞吐+耗时均可提升
Point
- redis使用后性能提升
- 充分利用GPU机器上的CPU、DRAM、SSD资源实现KVCache
- 分离后更有利于prefill和decode的独立优化
- batch size (prefill和decode的上限不同,后者更高)
- 并行策略优化(DP,TP,PP)
- prefill阶段:在qps较小时,更适合用tp;在qps较大时,更适合用pp
- decode阶段:对于decode阶段,随着gpu数量的增加,如果采用pp的方式,能产生更高的吞吐量;如果用tp,则能产生更低的延迟
- 长prompt效果更加明显
- 优化理论依据(什么场景下,既能省耗时又能提高吞吐)
- 对于每 X byte 的 KVCache,其生成所需的算力正比于 X*hd 再乘以一个较大的常数,这里 hd 对应模型的 hidden dimension。因此只要每卡算力比如 A100 的 220TFLOPS 和每卡通讯带宽比如 CX7 的 100Gbps 的比值小于 hd 乘以这个常数,那么从远端传输 KVCache 相比原地重算不仅仅减少了计算量还减少了 TTFT。 参考
- 分为算力和耗时两个层面
- 算力指生成KVCache的算力一定小于直接从缓存读取KVCache的算力
- 耗时指生成KVCache的耗时 需要大于 直接从缓存读取KVCache的耗时

SMC (共享内存通信)和RDMA的关系? 答:RDMA就是一种远程SMC
- 借助 SMC + ERDMA 可以实现硬件卸载 RDMA 、大规模部署,二者相辅相成。
- 开源:https://gitee.com/anolis/hpn-cloud-kernel 龙蜥社区
- 系列解读 SMC-R (二):融合 TCP 与 RDMA 的 SMC-R 通信 | 龙蜥技术
- 性能透明提升 50%!SMC + ERDMA 云上超大规模高性能网络协议栈
名词
- TOE(TCP Offload Engine)是指TCP卸载引擎。它是一种网络技术,通过将TCP/IP协议栈的一部分处理任务从主机的CPU卸载到网卡; 也就是RDMA
- NVLink :在单台服务器内 8 块 GPU 卡通过 NVLink 连接。不同服务器之间的 GPU 卡通过 RDMA 网络连接。
- SLO(Service Level Objective) 服务水平目标
- TTFT(Time To First Token) prefill首token耗时
- TPOT(Time Per Output Token) decode 每token耗时
- TBT (Time Between Tokens) 两个 token 生成间的延迟
- DP 数据并行
- TP 张量并行
- PP 流水线并行
- MFU(Model FLOPs Utilization):即模型算力利用率
- VRAM (video Ram) : 显存
模型推理提效的其他方式 参考
- vLLM 提出了 Paged Attention 算法,将 attention 算法产生的连续的 key value 向量按照 block 进行组织和管理,以减少显存碎片。vLLM 还借鉴操作系统当中的虚拟内存和分页思想优化 Transformer 模型推理中产生的 KeyValue Cache,大大提高了显存当中 KV Cache 的利用效率。但 vLLM 是基于单机层面上设计,只能将 GPU 中的 block swap 到单机的内存当中。
- SplitWise(微软)、DistServe 和 TetriInfer 将 prefill 和 decode 分离到不同的 GPU 组中以避免干扰,但它们的静态并行性和分区策略并不灵活,无法处理动态工作负载。
- Infinite-LLM 针对 long context 场景提出分布式 DistAttention,将 KV Cache 分割成 rblock,一个 node 可以借用别的 node 上的空闲显存。但它没有做 prefill/decode 分离,并且仍然需要周期性的 KV Cache 迁移来维持局部性,并且没有考虑不同请求之间或不同阶段之间的弹性资源需求。
文章参考
- 大模型合并及分离架构对比 https://juejin.cn/post/7408775736796872738
- cpu_bound memory_bound及gpu计算方式讲解 https://mp.weixin.qq.com/s?__biz=Mzg2NjcwNjcxNQ==&mid=2247485453&idx=1&sn=beb642f06f3501bd235a8f42973e39fb&chksm=ce47fc79f930756f991d93f69cad36409e3dcb58e517f41f583d29609b360e9b46f6777a42b4&scene=21&poc_token=HNlC4GajIEkUH4b-GWWVXmEgS4TiLmElCs4-jRUa
- 大模型优化方式讲解:DP、TP、PPhttps://zhuanlan.zhihu.com/p/618865052