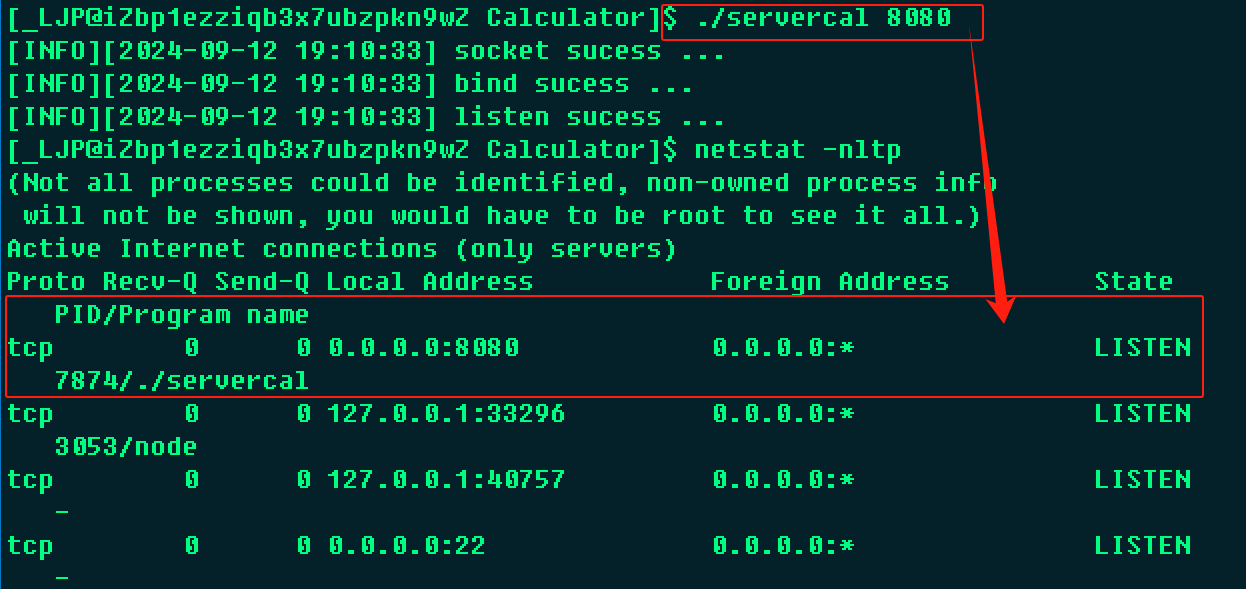
在之前的直播中,我们向大家介绍了🔗,为企业AI应用创新提供更高质量的非结构化数据语料输入和知识库支持,感兴趣的朋友可以点击链接阅读。
随着我们的开源数据仓库产品Cloudberry Database(简称“CloudberryDB”)日渐完善,Directory Table现在已经正式开源。在之前的直播中我们为大家详细讲解了Directory Table 底层逻辑与实现原理,以下内容根据直播文字整理成稿。背景
面对AI应用带来的非结构化数据管理挑战,CloudberryDB 引入了一种专门用来存储管理非结构化数据的新的表类型——Directory Table(目录表)。
通过Directory Table我们可以将各式各样非结构化的数据统一纳管起来,并且可以结合酷克数据自主研发的下一代 In-Database 高级分析和数据科学工具 HashML,对存储在Directory Table中的数据进行挖掘学习,为用户提供更进一步的价值。
CloudberryDB 的Directory Table提供 local 和 remote 两种存储方式,分别基于本地存储与对象存储服务两种形式,以满足用户需求的多样性。
Tablespace
在介绍Directory Table之前,我们首先需要理解数据库中的一个经典概念:Tablespace,它指的是数据库文件存储的本地目录地址,例如/code/base/。
在PostgreSQL中,其默认的Tablespace是pg_default,对应的数据目录是base目录,可以通过default_tablespace的guc来修改默认tablespace。
- 以对象存储为例:/bucket_name/tablespace-1/;
- 以HDFS为例 :/usr/warehouse/tablespace-1/;
在创建表时,我们可以指定该表使用的Tablespace。如果不指定,它将使用默认的Tablespace。而本期我们要讲解的Directory Table,实际上就是依赖于Tablespace来实现的。接下来,我们将通过实际操作来演示Tablespace的使用。
Directory Table实现原理
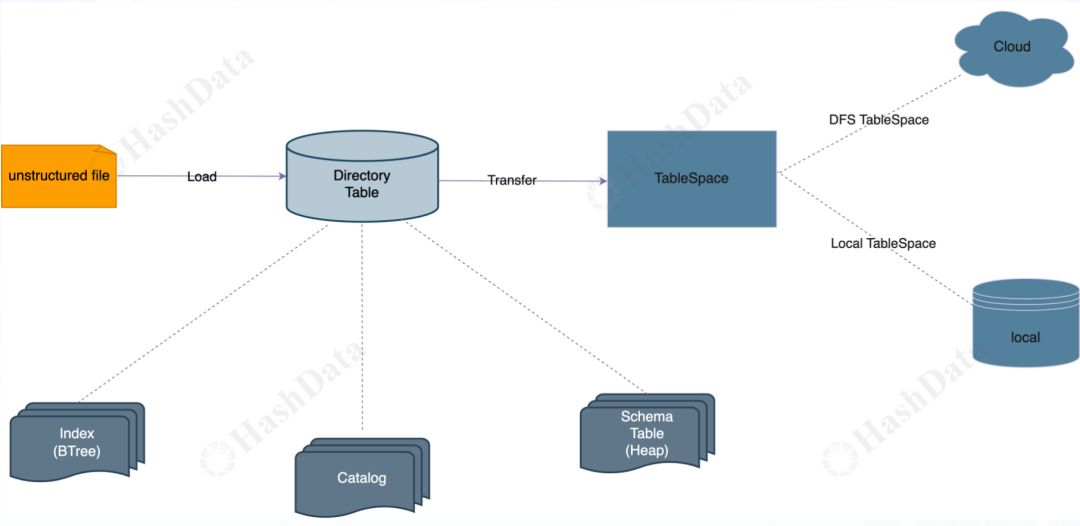
图1 Directory Table存储架构
上图是一张关于Directory Table存储架构的图。从图中可以看出,这里提供了两种Directory Table:Local Directory Table和Remote Directory Table。
假设现在有一份非结构化数据,我们可以通过CopyFrom命令或者通过gpdirtablelaod工具将其导入到Directory Table中。这份非结构化数据会被存放在Tablespace下。如果是Local Directory Table,它会存储在Local Tablespace下;如果是远端的Remote Directory Table,则会存储在DFS Tablespace。
Directory Table主要涉及三部分与元数据相关的操作,分别是:Index、Catalog以及Schema table。
Catalog如下图所示,我们在其中添加了一张名为pg_directory_table的系统表,这张系统表包含三个关键字段:DT_OID,代表Directory Table的唯一标识符(OID);Tablespace的OID,用于标识表空间;以及Directory Table具体的文件路径。
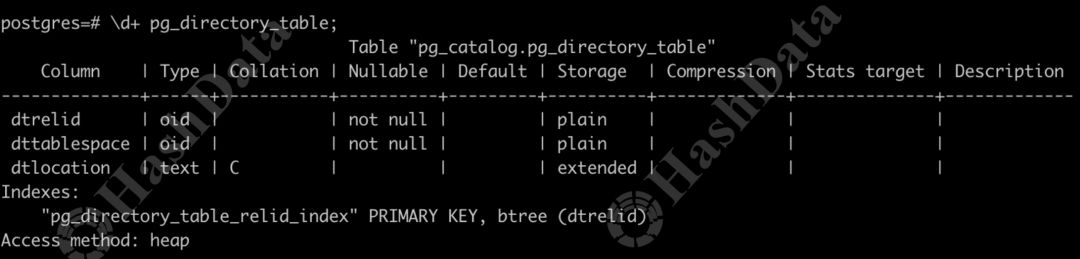
图2 Catalog表结构图
- Schema table可以理解为一张普通Heap表,专门用于记录Directory Table中的层级信息,从而管理Directory Table中存储的所有非结构化数据。Schema table主要包含五个字段:
- relative_path,即文件的相对路径,也可以理解为文件在Directory Table中的名称;
- size,表示文件的大小;
- upload_time,记录文件上传的时间;
- MD5,用于文件的完整性校验;
- 以及tag,允许用户在上传文件后添加标签,以便更方便地管理和检索这些非结构化数据。
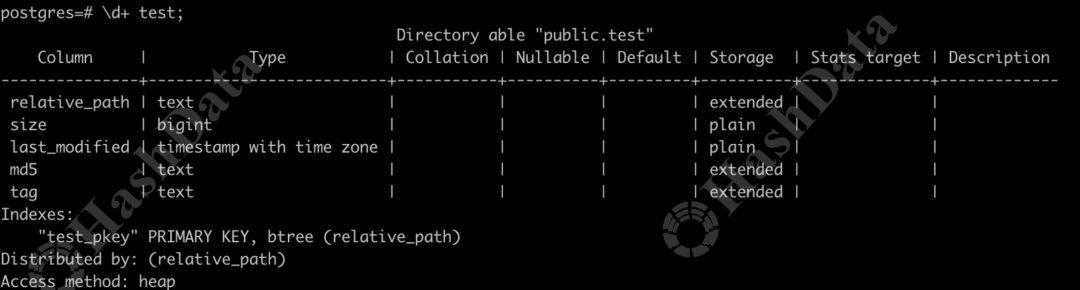
图3 Schema table结构图
创建 Directory Table
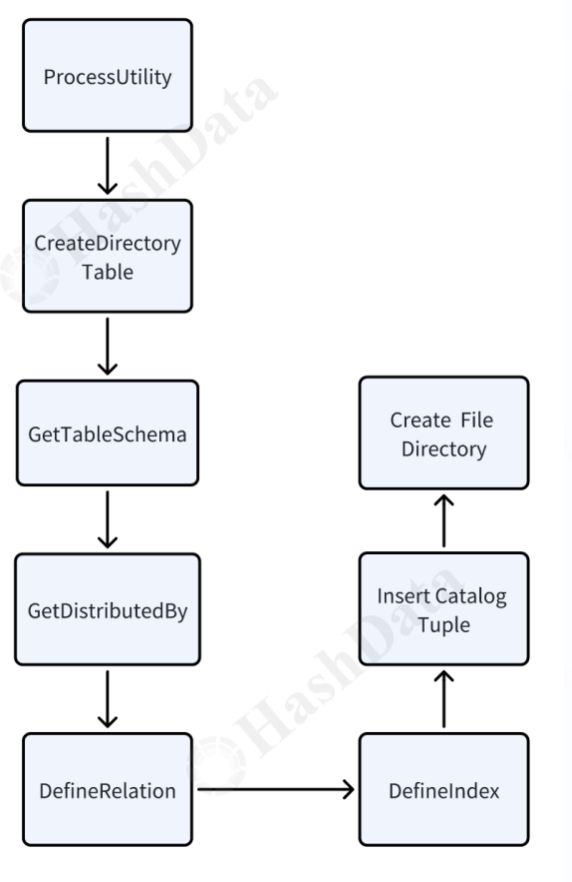
图4 创建Directory Table流程图
- Directory Table的Schema表按照relative path列进行分布,上传的非结构化数据文件,会基于分布列将数据分布存储到segment中。
- 主键为relative path,在插入非结构化数据时,relative path相同的拒绝插入。同时可以加速Schema表的查询效率。
- Directory Table的权限检查基于Schema表。
- 创建成功后,会在pg_directory_table系统表中插入一条对应tuple,同时会在对应的Tablespace下生成对应目录。
Schema表禁止除Update tag列外的一切DML操作。
导入数据
接下来我们一起看下Copy导入非结构化数据文件到Directory Table的数据流向图,以及具体演示。
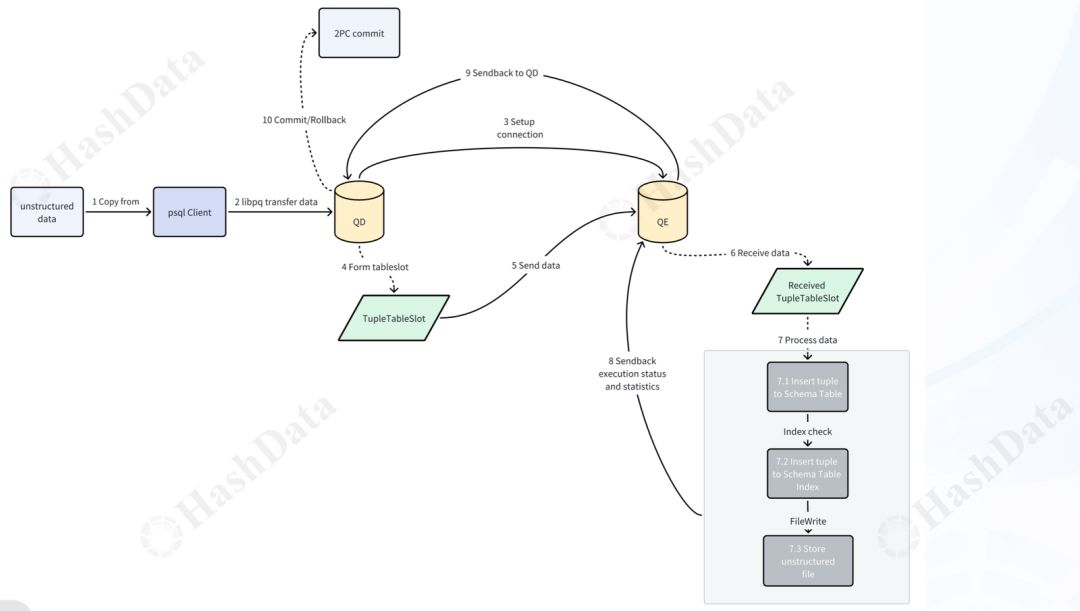
图5 Copy导入非结构化数据流向图
下图是关于Copy代码的一个流程:首先,系统会判断操作是否通过CopyFrom接口发起,并检查所操作的表是否为Directory Table,若不是Directory Table,则执行常规的Copy table逻辑;若是,则进一步判断其类型为QD还是QE,分别执行发送数据或接收数据的流程。最后,无论执行了哪种类型的操作,都会进行必要的清理工作,以确保资源得到正确释放和状态得到更新。
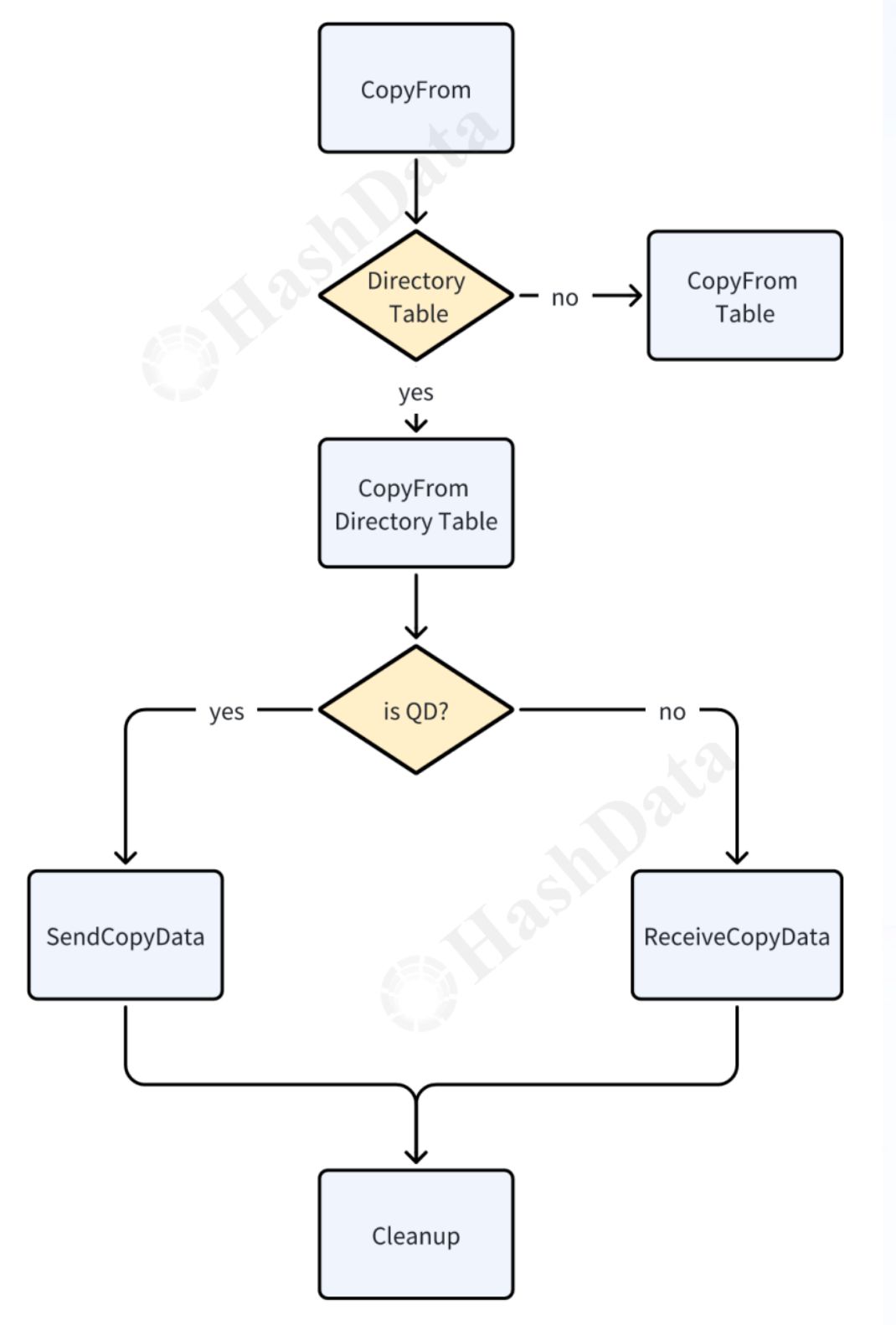
图6 Copy代码流程
QD具体的执行流程如下:
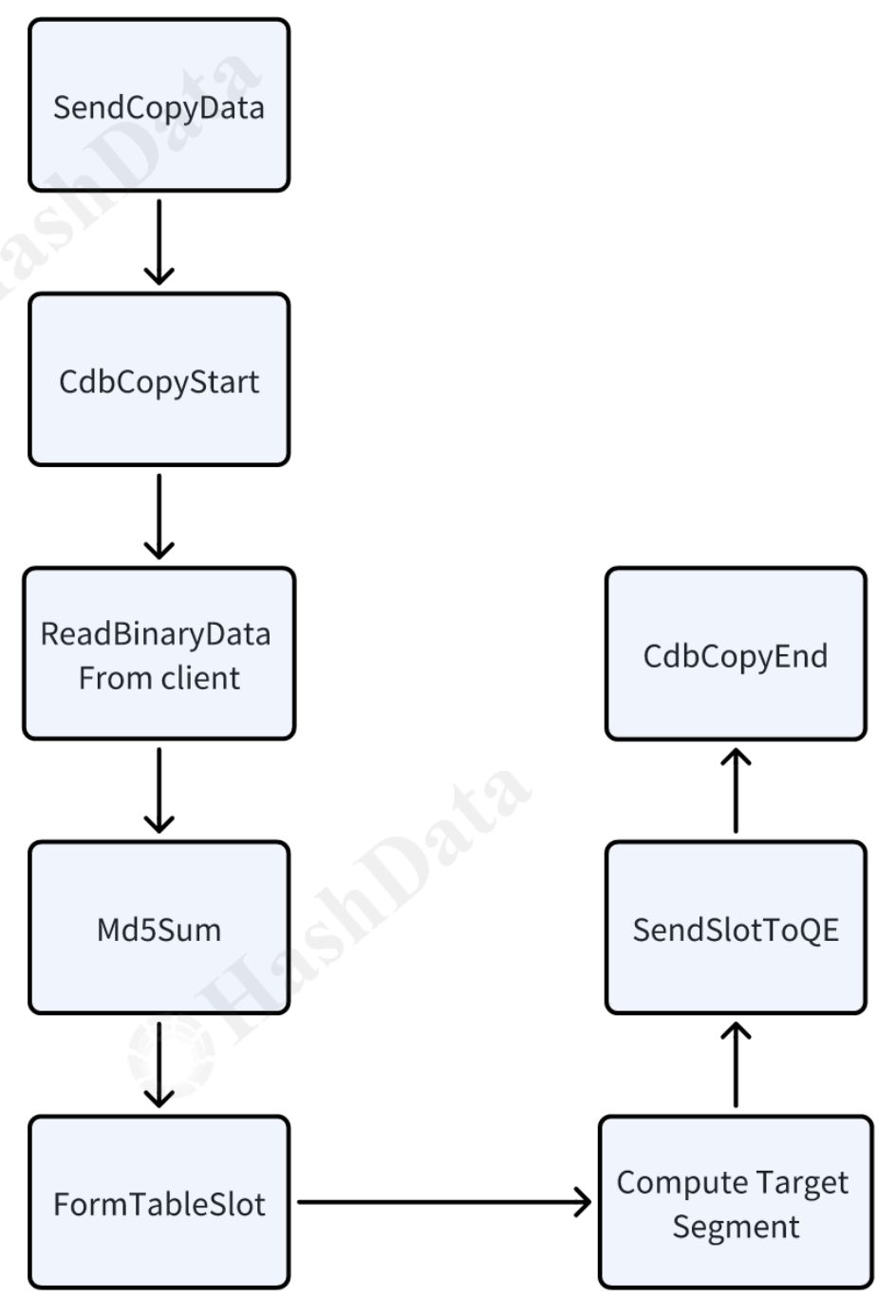
图7 Copy导入-QD流程
- CdbCopyStart会执行buildGang,建立QD→QE之间的connection,通过pg中的libpq来传输数据。
- ReadBinaryData会从libpq中读取二进制数据流。
- Md5Sum会动态计算md5,直至文件传输完成得到整个文件的md5。
- ComputeTargetSeg会基于relative path分布键计算tuple需要发送的QE。
- CdbCopyEnd会等待Copy到QE过程的结束,并收集QE返回的状态和统计信息。
接下来是QE的执行流程:
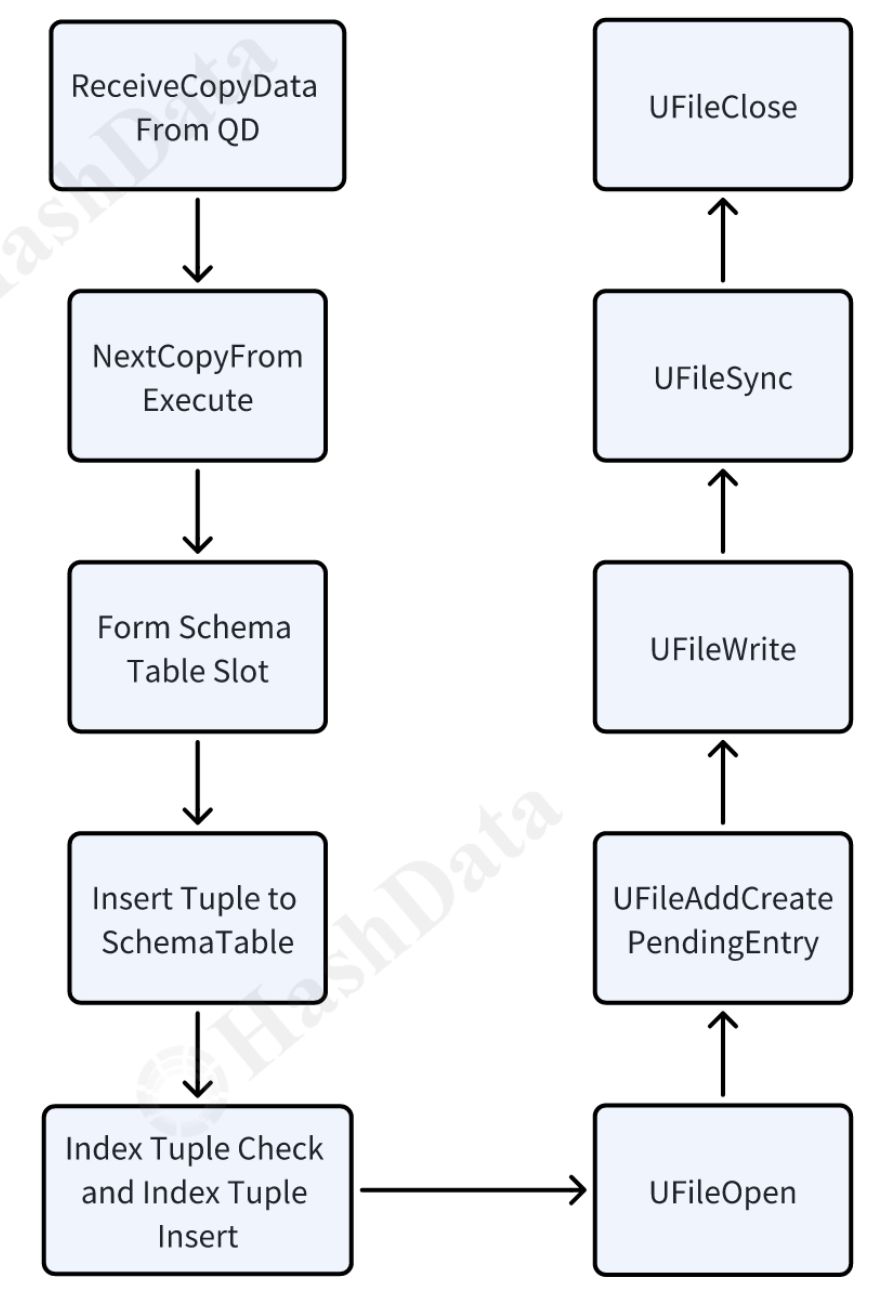
图8 Copy导入-QE流程
- NextCopyFromExecute会从libpq中读取QD发送的数据并存到TupleTableSlot中。
- Index Tuple Check会基于主键检查当前tuple是否已经在index中存在,这里主键为relative_path,可以避免相同文件名覆盖。
- UFileAddCreatePendingEntry会添加一个PendingDelete对象到链表中,类似于pg中pending delete的机制,该链表会在事务提交将数据文件落盘,在事务回滚时删除数据文件,保证了数据文件的事务性。
- UFileOpen/UFileWrite/UFileSync/UFileClose是数据文件操作的统一接口,通过这些接口可以实现对底层存储介质的透明,如本地存储或者远端对象存储。
查询数据
那么如何在Directory Table中查询数据呢?如下图所示,我们提供了一些UDF(用户定义函数)来进行查询。
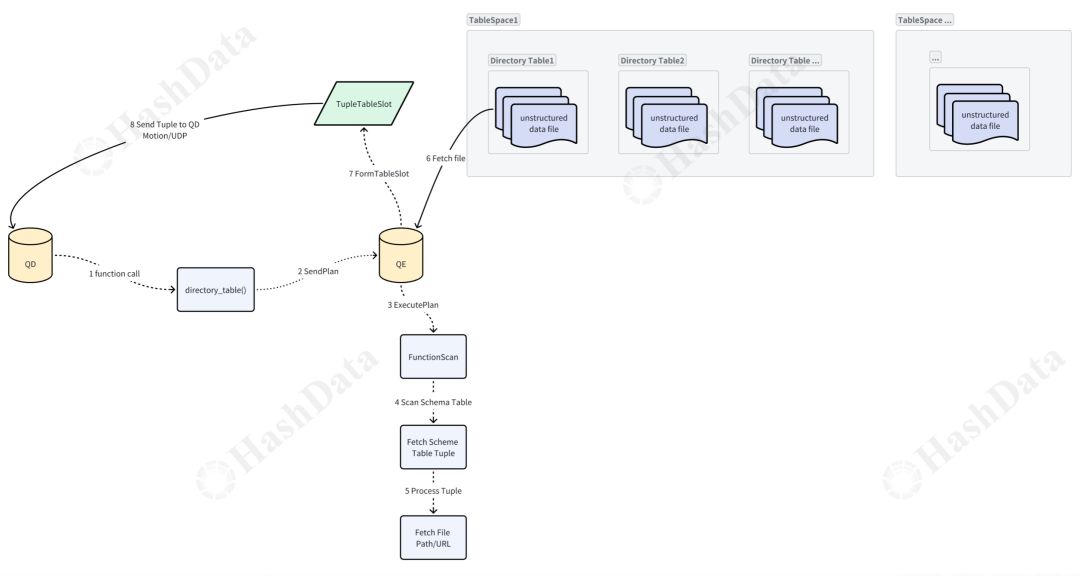
图9 查询数据流程
QD调用Directory Table的函数。函数执行时,QD会向QE发送查询计划。QE收到计划后执行它,并调用FunctionScan来扫描schema表,找到要查询的那条tuple,并获取具体的文件路径或URL(本地文件为路径,远端文件为URL)。
QE拿到这个路径或URL后,会到Tablespace找到对应的Directory Table,然后找到对应的非结构化数据,紧接着给QD返回一个TupleTableSlot,而返回的数据通过Motion的UDP传输方式,保证了传输的可靠性。
删除数据
既然存在数据的传输,那么也必然涉及到数据的删除操作。我们主要关注的是删除操作的交互流程,这一流程通过remove_file()的函数来实现的。如下图所示:
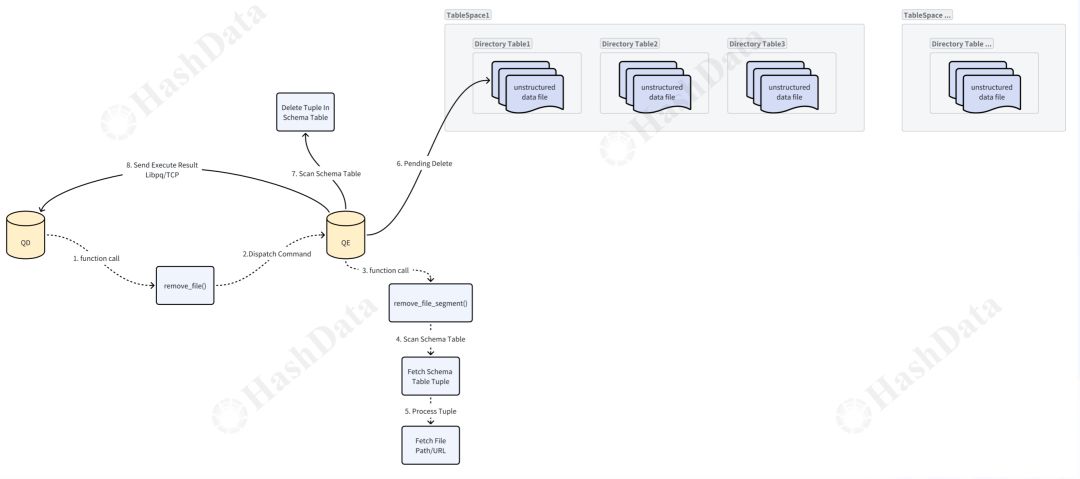
图10 删除数据流程
当QD调用这个函数时,它会将删除命令发送给QE。QE收到命令后,会调用remove_file segment函数,执行一个顺序扫描,扫描schema表以找到要删除的tuple,并获取对应的路径或URL。
随后,QE会构造一个pending delete对象,并将其添加到pending delete链表中,同时在schema表中删除对应的tuple。这个pending delete机制在commit或rollback时决定文件的最终状态。
删除Directory Table
最后,展示最删除Directory Table的流程图,这里需要注意:
aclcheck会对权限进行检查,只有超级用户或者是directory table的owner才有权限执行删除。
heap_drop_with_catalog会在pg_class元数据的tuple进行删除。
RemoveDirectoryTableEntry会将pg_directory_table系统表中对应的tuple删除。
UFileAddDeletePendingEntry类似于UFileAddCreatePendingEntry,在执行删除时会添加一个PendingDelete对象到链表中,该链表会在事务提交将数据文件删除,在事务回滚时不做处理。
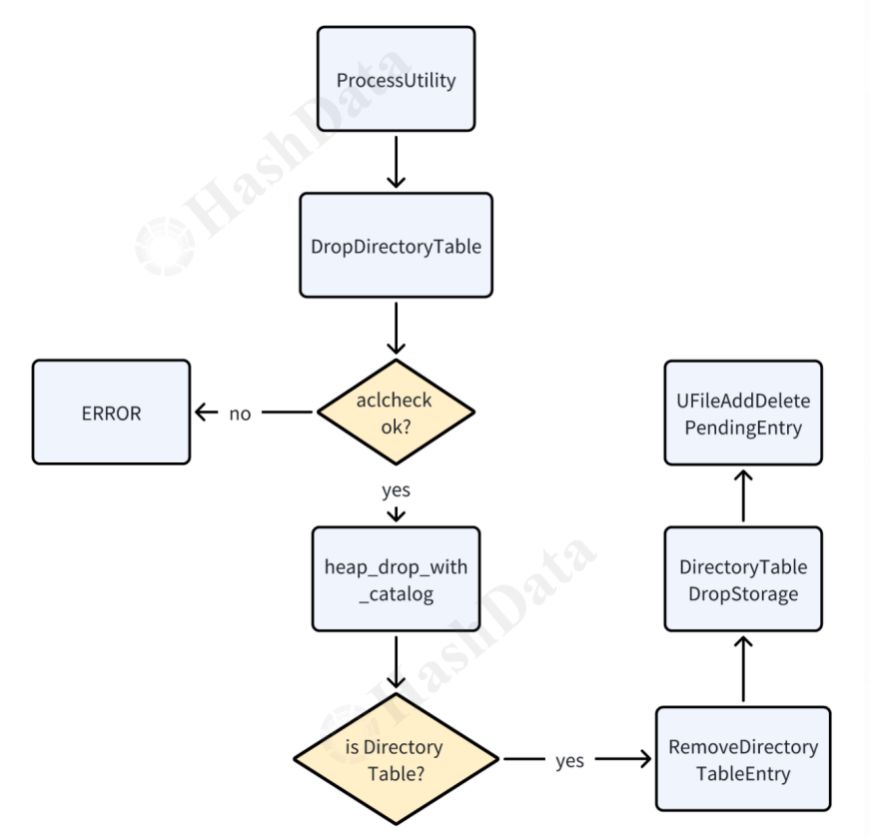
图11 删除Directory Table的流程
结 语
本次分享,我们为大家深入讲解了Directory Table的实现原理、创建流程、数据导入、查询与删除操作等核心内容,希望帮助开发者朋友们更全面、更深入地理解CloudberryDB的Directory Table,并能够在实践中灵活运用,为企业的AI应用创新提供更高质量的非结构化数据语料输入和知识库支持。