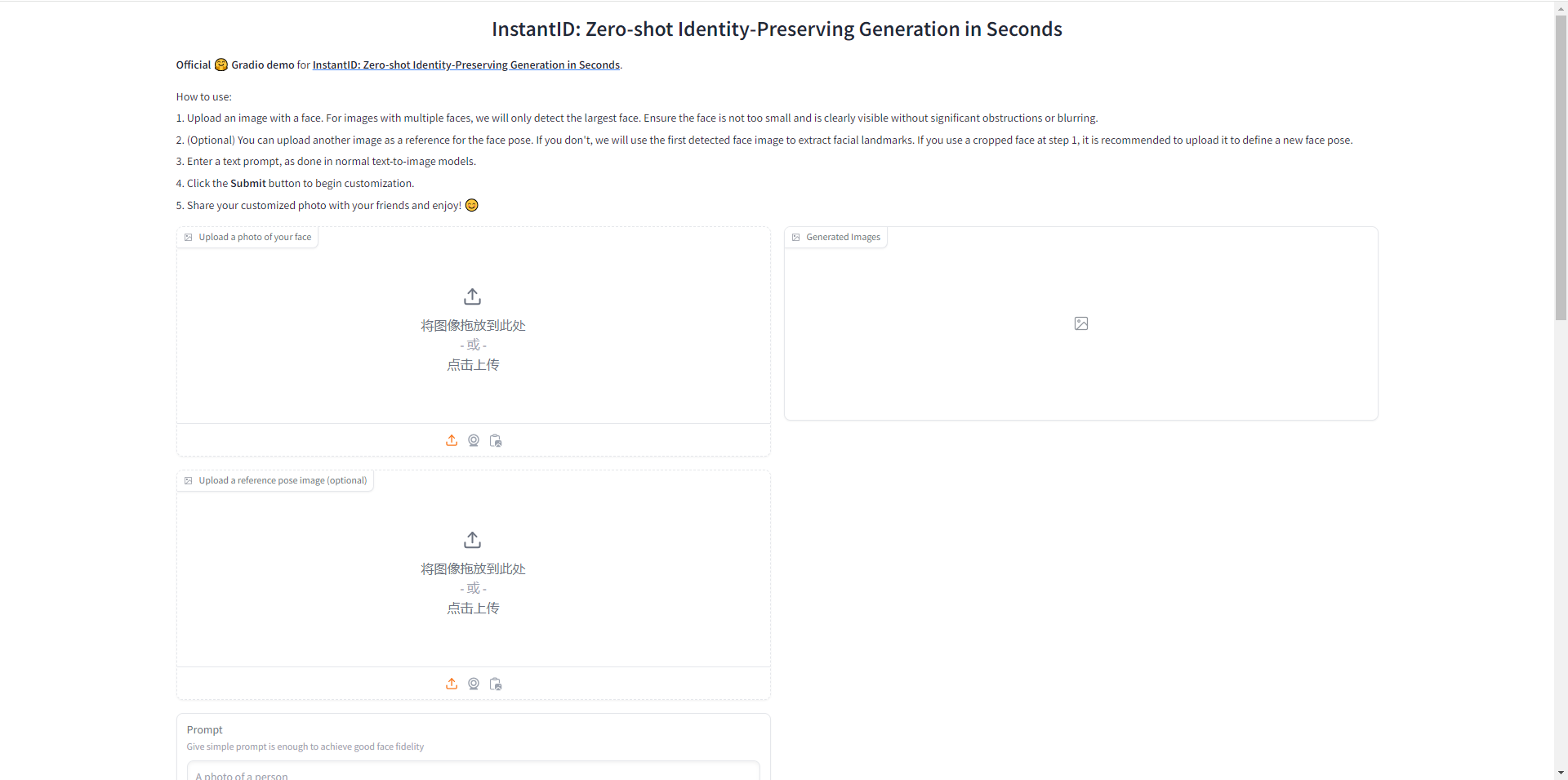
思维树 (ToT)
对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。最近,Yao et el. (2023)(opens in a new tab) 提出了思维树(Tree of Thoughts,ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT 维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LM 能够自己对严谨推理过程的中间思维进行评估。LM 将生成及评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,在系统性探索思维的时候可以向前验证和回溯。
ToT 框架原理如下:
图片援引自:Yao et el. (2023)(opens in a new tab)
ToT 需要针对不同的任务定义思维/步骤的数量以及每步的候选项数量。例如,论文中的“算 24 游戏”是一种数学推理任务,需要分成 3 个思维步骤,每一步都需要一个中间方程。而每个步骤保留最优的(best) 5 个候选项。
ToT 完成算 24 的游戏任务要执行广度优先搜索(BFS),每步思维的候选项都要求 LM 给出能否得到 24 的评估:“sure/maybe/impossible”(一定能/可能/不可能) 。作者讲到:“目的是得到经过少量向前尝试就可以验证正确(sure)的局部解,基于‘太大/太小’的常识消除那些不可能(impossible)的局部解,其余的局部解作为‘maybe’保留。”每步思维都要抽样得到 3 个评估结果。整个过程如下图所示:
图片援引自:Yao et el. (2023)(opens in a new tab)
从下图中报告的结果来看,ToT 的表现大大超过了其他提示方法:
图片援引自:Yao et el. (2023)(opens in a new tab)
这里(opens in a new tab)还有这里(opens in a new tab)可以找到代码例子。
从大方向上来看,Yao et el. (2023)(opens in a new tab) 和 Long (2023)(opens in a new tab) 的核心思路是类似的。两种方法都是以多轮对话搜索树的形式来增强 LLM 解决复杂问题的能力。主要区别在于 Yao et el. (2023)(opens in a new tab) 采用了深度优先(DFS)/广度优先(BFS)/集束(beam)搜索,而 Long (2023)(opens in a new tab) 则提出由强化学习(Reinforcement Learning)训练出的 “ToT 控制器”(ToT Controller)来驱动树的搜索策略(包括什么时候回退和搜索到哪一级回退等等)。深度优先/广度优先/集束搜索是通用搜索策略,并不针对具体问题。相比之下,由强化学习训练出的 ToT 控制器有可能从新的数据集学习,或是在自对弈(AlphaGo vs. 蛮力搜索)的过程中学习。因此,即使采用的是冻结的 LLM,基于强化学习构建的 ToT 系统仍然可以不断进化,学习新的知识。
Hulbert (2023)(opens in a new tab) 提出了思维树(ToT)提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
假设三位不同的专家来回答这个问题。所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。然后,所有专家都写下他们思考的下一个步骤并分享。以此类推,直到所有专家写完他们思考的所有步骤。只要大家发现有专家的步骤出错了,就让这位专家离开。请问...检索增强生成 (RAG)
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)(opens in a new tab)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。这种方法工作原理概况如下:
图片援引自: Lewis et el. (2021)(opens in a new tab)
RAG 在 Natural Questions(opens in a new tab)、WebQuestions(opens in a new tab) 和 CuratedTrec 等基准测试中表现抢眼。用 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更符合事实、更具体、更多样。FEVER 事实验证使用 RAG 后也得到了更好的结果。
这说明 RAG 是一种可行的方案,能在知识密集型任务中增强语言模型的输出。
最近,基于检索器的方法越来越流行,经常与 ChatGPT 等流行 LLM 结合使用来提高其能力和事实一致性。
LangChain 文档中可以找到一个使用检索器和 LLM 回答问题并给出知识来源的简单例子(opens in a new tab)。
自动推理并使用工具 (ART)
使用 LLM 完成任务时,交替运用 CoT 提示和工具已经被证明是一种即强大又稳健的方法。这类方法通常需要针对特定任务手写示范,还需要精心编写交替使用生成模型和工具的脚本。Paranjape et al., (2023)(opens in a new tab)提出了一个新框架,该框架使用冻结的 LLM 来自动生成包含中间推理步骤的程序。
ART(Automatic Reasoning and Tool-use)的工作原理如下:
- 接到一个新任务的时候,从任务库中选择多步推理和使用工具的示范。
- 在测试中,调用外部工具时,先暂停生成,将工具输出整合后继续接着生成。
ART 引导模型总结示范,将新任务进行拆分并在恰当的地方使用工具。ART 采用的是零样本形式。ART 还可以手动扩展,只要简单地更新任务和工具库就可以修正推理步骤中的错误或是添加新的工具。这个过程如下:
图片援引自: Paranjape et al., (2023)(opens in a new tab)
在 BigBench 和 MMLU 基准测试中,ART 在未见任务上的表现大大超过了少样本提示和自动 CoT;配合人类反馈后,其表现超过了手写的 CoT 提示。
下面这张表格展示了 ART 在 BigBench 和 MMLU 任务上的表现:
图片援引自: Paranjape et al., (2023)