作者:翟天保Steven
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
实现原理
中值滤波是一种常用的图像处理方法,特别适用于去除图像中的脉冲噪声(如椒盐噪声)。与均值滤波不同的是,中值滤波通过选择像素邻域中的中值来替代中心像素的值,从而保留图像边缘的细节。中值滤波的原理如下:
-
定义滤波器大小:选择一个窗口大小,通常是一个固定的矩形区域,比如3x3、5x5或7x7。这个窗口决定了要参与计算的邻域像素范围。
-
遍历图像:对于图像中的每一个像素,将其邻域范围内的所有像素值取出并排列成一个集合。
-
计算中值:将邻域中的像素值从小到大排序,取出中间位置的值作为中值。如果邻域的像素数是奇数,则中值为排序后正中间的像素值;如果是偶数,则通常取中间两个值的平均值作为中值。
-
更新像素值:将中值替代原像素的值,完成对当前像素的处理。
-
重复步骤:对图像中的所有像素都重复上述过程,从而对整幅图像进行中值滤波处理。
中值滤波的一个显著优势是它能够在去除噪声的同时,较好地保留图像中的边缘信息,这是由于中值操作不会将像素邻域的极值(如噪声点)引入新的像素值中。相比于均值滤波,中值滤波在处理图像中的脉冲噪声时效果更为显著。
中值滤波的缺点在于其计算复杂度相对较高,尤其是在处理大尺寸图像时,计算时间较长。此外,如果邻域内噪声比例较大,中值滤波的效果可能不如其他更复杂的滤波方法。
本文主要目的在于展示CUDA版本的性能提升效果,采用常规思路实现,CPU版本应用了并行提速,与GPU并行客观对比。
功能函数代码
// 中值滤波核函数
__global__ void medianFilter_CUDA(uchar* inputImage, uchar* outputImage, int width, int height, int windowSize)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < height && col < width)
{
// 参数预设
uchar datas[25];
int r = windowSize / 2;
int ms = max(row - r, 0);
int me = min(row + r, height - 1);
int ns = max(col - r, 0);
int ne = min(col + r, width - 1);
// 赋值
int count = 0;
for (int m = ms; m <= me; ++m)
{
for (int n = ns; n <= ne; ++n)
{
datas[count++] = inputImage[m * width + n];
}
}
// 选择排序
for (int i = 0; i < count - 1; i++)
{
int minIndex = i;
for (int j = i + 1; j < count; j++)
{
if (datas[j] < datas[minIndex])
{
minIndex = j;
}
}
uchar temp = datas[i];
datas[i] = datas[minIndex];
datas[minIndex] = temp;
}
outputImage[row * width + col] = datas[count / 2];
}
}C++测试代码
Filter.h
#pragma once
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <device_launch_parameters.h>
using namespace cv;
using namespace std;
// 预准备过程
void warmupCUDA();
// 中值滤波-CPU
cv::Mat filterMedian_CPU(cv::Mat input, int FilterWindowSize);
// 中值滤波-GPU
cv::Mat filterMedian_GPU(cv::Mat input, int FilterWindowSize);
Filter.cu
#include "Filter.h"
// 预准备过程
void warmupCUDA()
{
float* dummy_data;
cudaMalloc((void**)&dummy_data, sizeof(float));
cudaFree(dummy_data);
}
// 中值滤波-CPU
cv::Mat filterMedian_CPU(cv::Mat input, int FilterWindowSize)
{
int row = input.rows;
int col = input.cols;
// 预设输出
cv::Mat output = input.clone();
// 中值滤波
int r = FilterWindowSize / 2;
#pragma omp parallel for
for (int i = 0; i < row; ++i)
{
vector<uchar> datas;
for (int j = 0; j < col; ++j)
{
// 卷积窗口边界限制,防止越界
int ms = ((i - r) > 0) ? (i - r) : 0;
int me = ((i + r) < (row - 1)) ? (i + r) : (row - 1);
int ns = ((j - r) > 0) ? (j - r) : 0;
int ne = ((j + r) < (col - 1)) ? (j + r) : (col - 1);
// 求窗口内有效数据的中值
datas.clear();
for (int m = ms; m <= me; ++m)
{
for (int n = ns; n <= ne; ++n)
{
datas.push_back(input.at<uchar>(m, n));
}
}
sort(datas.begin(), datas.end());
output.at<uchar>(i, j) = datas[datas.size() / 2];
}
}
return output;
}
// 中值滤波核函数
__global__ void medianFilter_CUDA(uchar* inputImage, uchar* outputImage, int width, int height, int windowSize)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < height && col < width)
{
// 参数预设
uchar datas[25];
int r = windowSize / 2;
int ms = max(row - r, 0);
int me = min(row + r, height - 1);
int ns = max(col - r, 0);
int ne = min(col + r, width - 1);
// 赋值
int count = 0;
for (int m = ms; m <= me; ++m)
{
for (int n = ns; n <= ne; ++n)
{
datas[count++] = inputImage[m * width + n];
}
}
// 选择排序
for (int i = 0; i < count - 1; i++)
{
int minIndex = i;
for (int j = i + 1; j < count; j++)
{
if (datas[j] < datas[minIndex])
{
minIndex = j;
}
}
uchar temp = datas[i];
datas[i] = datas[minIndex];
datas[minIndex] = temp;
}
outputImage[row * width + col] = datas[count / 2];
}
}
// 中值滤波-GPU
cv::Mat filterMedian_GPU(cv::Mat input, int FilterWindowSize)
{
int row = input.rows;
int col = input.cols;
// 分配GPU内存
uchar* d_inputImage, *d_outputImage;
cudaMalloc(&d_inputImage, row * col * sizeof(uchar));
cudaMalloc(&d_outputImage, row * col * sizeof(uchar));
// 将输入图像数据从主机内存复制到GPU内存
cudaMemcpy(d_inputImage, input.data, row * col * sizeof(uchar), cudaMemcpyHostToDevice);
// 计算块和线程的大小
dim3 blockSize(TILE_WIDTH, TILE_WIDTH);
dim3 gridSize((col + blockSize.x - 1) / blockSize.x, (row + blockSize.y - 1) / blockSize.y);
// 调用CUDA内核
medianFilter_CUDA << <gridSize, blockSize >> > (d_inputImage, d_outputImage, col, row, FilterWindowSize);
// 将处理后的图像数据从GPU内存复制回主机内存
cv::Mat output(row, col, CV_8UC1);
cudaMemcpy(output.data, d_outputImage, row * col * sizeof(uchar), cudaMemcpyDeviceToHost);
// 清理GPU内存
cudaFree(d_inputImage);
cudaFree(d_outputImage);
return output;
}main.cpp
#include "Filter.h"
void main()
{
// 预准备
warmupCUDA();
cout << "medianFilter test begin." << endl;
// 加载
cv::Mat src = imread("test pic/test1.jpg", 0);
int winSize = 5;
cout << "filterWindowSize:" << winSize << endl;
cout << "size: " << src.cols << " * " << src.rows << endl;
// CPU版本
clock_t s1, e1;
s1 = clock();
cv::Mat output1 = filterMedian_CPU(src, winSize);
e1 = clock();
cout << "CPU time:" << double(e1 - s1) / 1000 << endl;
// GPU版本
clock_t s2, e2;
s2 = clock();
cv::Mat output2 = filterMedian_GPU(src, winSize);
e2 = clock();
cout << "GPU time:" << double(e2 - s2) / 1000 << endl;
// 检查
int row = src.rows;
int col = src.cols;
bool flag = true;
for (int i = 0; i < row; ++i)
{
for (int j = 0; j < col; ++j)
{
if (output1.at<uchar>(i, j) != output2.at<uchar>(i, j))
{
cout << "i:" << i << " j:" << j << endl;
flag = false;
break;
}
}
if (!flag)
{
break;
}
}
if (flag)
{
cout << "ok!" << endl;
}
else
{
cout << "error!" << endl;
}
// 查看输出
cv::Mat test1 = output1.clone();
cv::Mat test2 = output2.clone();
cout << "medianFilter test end." << endl;
}测试效果




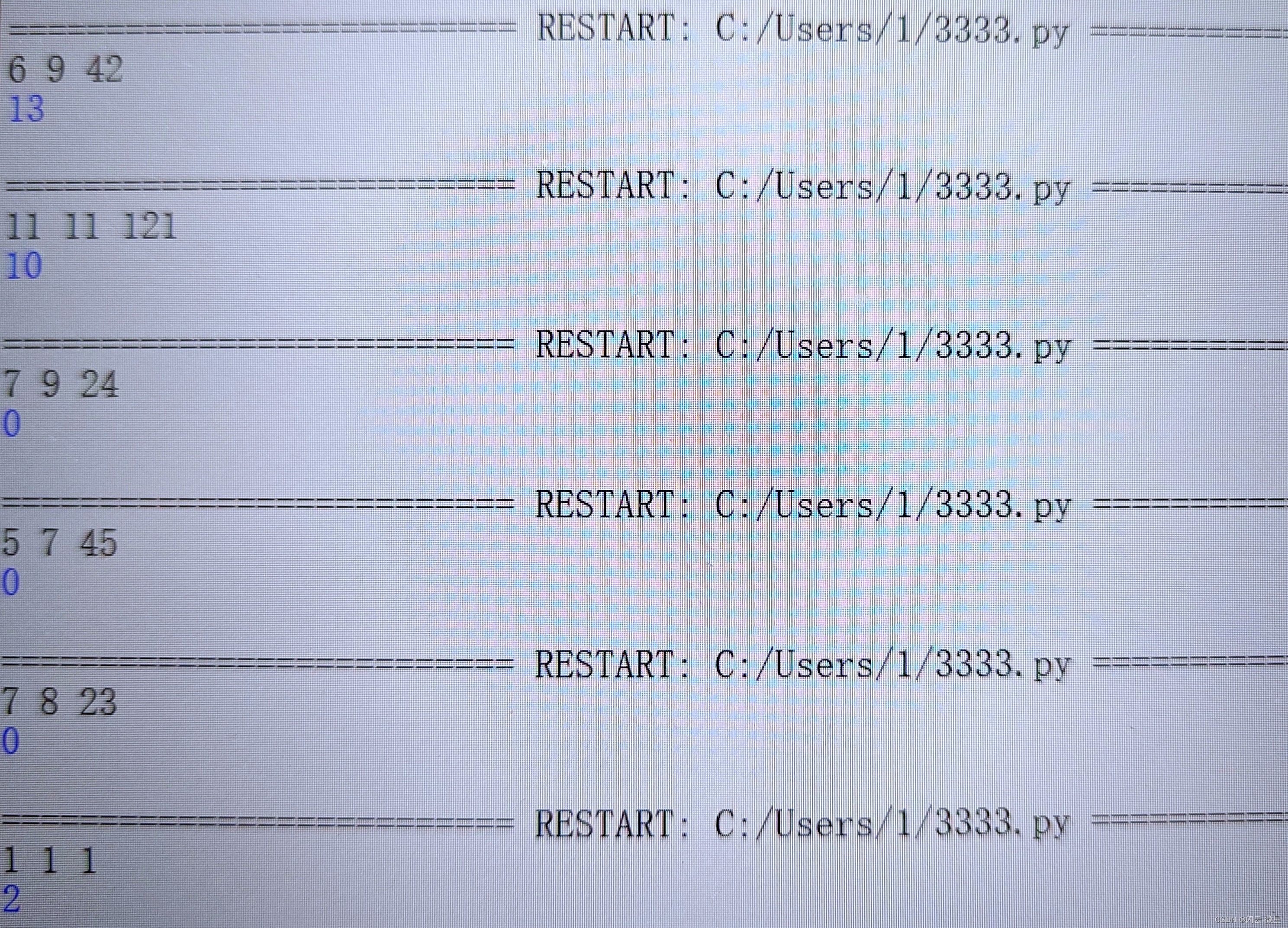
如上图所示,分别是原图、CPU结果和GPU结果,在速度方面,对1920*1080的图像,在窗口尺寸为5*5时,我的电脑运行速度分别是0.526s和0.018s。
将滤波窗尺寸增加到9*9,注意核函数里申请空间也要增加,如下所示。速度差距依然很大。当滤波窗尺寸继续增加时,GPU和CPU的速度差异会越来越小,主要原因就是CUDA核函数中进行了过多申请空间的操作,这个开销不容小觑。


如果函数有什么可以改进完善的地方,非常欢迎大家指出,一同进步何乐而不为呢~
如果文章帮助到你了,可以点个赞让我知道,我会很快乐~加油!